[논문리뷰] Epona: Autoregressive Diffusion World Model for Autonomous Driving
ICCV 2025. [Paper] [Page] [Github]
Kaiwen Zhang, Zhenyu Tang, Xiaotao Hu, Xingang Pan, Xiaoyang Guo, Yuan Liu, Jingwei Huang, Li Yuan, Qian Zhang, Xiao-Xiao Long, Xun Cao, Wei Yin
Horizon Robotics | Tsinghua University | Peking University | Nanjing University | HKUST | Nanyang Technological University | Tencent Hunyuan
30 Jun 2025

Introduction
본 논문에서는 고해상도의 긴 동영상 생성 및 정확한 궤적 planning을 구현하는 autoregressive diffusion world model인 Epona를 소개한다. Epona의 핵심 혁신은 세 가지 주요 설계에서 비롯된다.
- 시공간 분리: 기존 동영상 diffusion model들은 과거 및 미래 프레임의 시공간적 분포를 함께 모델링하지만, 이러한 모델링 방식은 명시적인 인과관계 제약이 부족하여 긴 시퀀스에서 오차가 누적되는 문제가 있다. Epona는 시공간 분리를 통해 이 문제를 해결하였다. Causal attention을 적용한 GPT 스타일의 transformer가 압축된 latent space에서 시간적 동역학을 처리하는 반면, 두 개의 DiT는 각각 공간 렌더링과 궤적 생성을 독립적으로 처리한다.
- 비동기 멀티모달 생성: 병렬적인 denoising process를 통해 궤적 planning과 동영상 생성을 분리하였다. 두 개의 DiT가 3초 분량의 차량 궤적과 다음 미래 프레임 하나를 비동기적으로 생성한다. 두 스트림 모두 동일한 시간적 latent에 기반한 flow matching loss를 공유하여, 모달리티별 최적화를 유지하면서 정렬을 보장한다.
- Chain-of-Forward 학습 전략: Autoregressive 루프에서 오차 누적 및 콘텐츠 드리프트를 해결한다.
Epona는 다음과 같은 몇 가지 추가적인 장점을 제공한다.
- 긴 동영상 생성: 본 논문의 autoregressive diffusion model은 최대 2분 길이의 동영상 생성이 가능하여 기존 world model보다 훨씬 뛰어난 성능을 보여준다.
- 실시간 궤적 planning: 분리된 멀티모달 생성 아키텍처를 통해 동영상 예측을 비활성화한 상태에서 궤적 planning만 수행할 수 있어 추론 FLOPS를 크게 줄였다. 이를 통해 고품질의 실시간 궤적 planning이 가능하며, 최대 20Hz의 속도를 달성하였다.
- 시각적 디테일 보존: 본 논문의 autoregressive 공식은 discrete tokenizer 대신 continuous tokenizer를 채택하여 풍부한 장면 디테일을 보존한다.
Method
1. Reformulation of World Model Designs
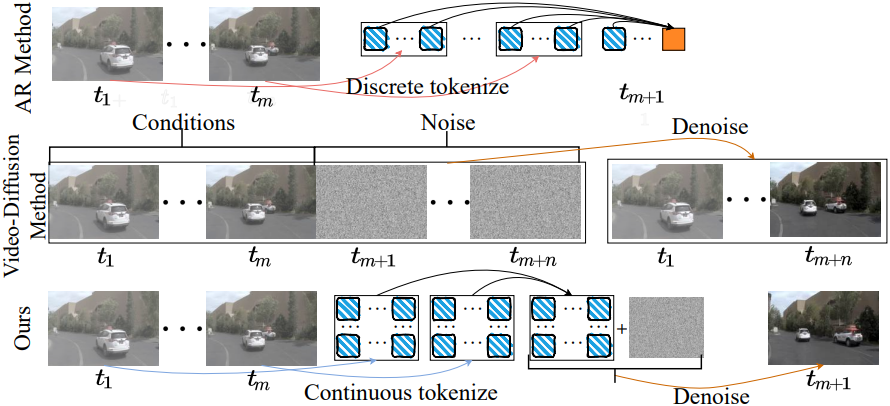
주어진 이전 전방 카메라 관측값 시퀀스 \(\{\textbf{O}_t\}_{t=1}^T\)와 이에 상응하는 주행 궤적 \(\{\textbf{a}_{t-1 \rightarrow t}\}_{t=1}^T\)에 대해, world model의 목표는 과거 컨텍스트를 기반으로 미래의 주행 역학을 예측하는 것이다. 여기서 각 주행 action \(\textbf{a}_{t_1 \rightarrow t_2} = (\Delta \theta_{t_1 \rightarrow t_2}, \Delta x_{t_1 \rightarrow t_2}, \Delta y_{t_1 \rightarrow t_2}) \in \mathbb{R}^3\)는 차량의 $t_1$에서 $t_2$까지의 움직임을 나타내며, \(\Delta \theta\)는 방향 변화를, \((\Delta x, \Delta y)\)는 자기 좌표계에서의 상대적인 변위를 나타낸다. 일관성을 위해 \(\textbf{a}_{0 \rightarrow 1} = (0, 0, 0)\)으로 정의한다. 기존 방법들은 다음과 같은 두 가지 방식의 world model로 이 문제를 해결하였다.
Vista와 같은 주행 시뮬레이션 모델은 과거와 고정된 길이의 미래에 대한 글로벌한 시공간적 분포를 동시에 포착하는 video diffusion model 형태로 world model을 구현하였다.
\[\begin{equation} p(\{\textbf{O}_{T+i}\}_{i=1}^n, \{\textbf{O}_t, \textbf{a}_t\}_{t=1}^T) \end{equation}\]이러한 모델링은 과거 관측값과 미래 예측 사이의 인과적 시간 구조를 왜곡하여 실제 세계의 역학을 모델링하고 유연한 길이의 긴 동영상을 생성하는 능력을 제한한다.
Autoregressive transformer 기반 world model들은 이미지 관측값을 토큰 시퀀스 \(\textbf{O}_t = [\textbf{t}_1, \ldots, \textbf{t}_L]\)로 discretize하고 조건부 이미지 분포를 토큰별 예측으로 모델링한다.
\[\begin{equation} \prod_{i=1}^L p (\textbf{t}_i \; \vert \; \textbf{t}_{<i}, \{\textbf{O}_t, \textbf{a}_t\}_{t=1}^T) \end{equation}\]하지만 이러한 독립적인 토큰 모델링은 공간적 상관관계를 약화시키고 quantization 과정에서 고주파 디테일이 왜곡되어 생성 품질이 저하된다.
이와 대조적으로, 본 논문은 world model을 시간 도메인에서 순차적인 미래 예측 과정으로 모델링하였다. 구체적으로, 과거 주행 관측값 \(\{\textbf{O}_t\}_{t=1}^T\)와 주행 궤적 \(\{\textbf{a}_{t-1 \rightarrow t}\}_{t=1}^T\)이 주어졌을 때, 본 논문의 world model은 미래 궤적 planning을 위한 policy와 다음 프레임 카메라 관측값에 대한 조건부 분포를 모두 예측한다.
\[\begin{equation} \pi (\{\textbf{a}_{T \rightarrow T+i}\}_{i=1}^n \; \vert \; \{\textbf{O}_t, \textbf{a}_{t-1 \rightarrow t}\}_{t=1}^T) \\ p (\textbf{O}_{T+1} \; \vert \; \{\textbf{O}_t, \textbf{a}_{t-1 \rightarrow t}\}_{t=1}^T, \textbf{a}_{T \rightarrow T+1}) \end{equation}\]다음 프레임 예측은 모델이 예측한 action 또는 외부에서 제공된 action \(\textbf{a}_{T \rightarrow T+1}\)에 따라 결정된다. 인과적인 시간 모델링과 세밀한 미래 예측을 분리함으로써, 본 모델은 continuous한 표현으로 autoregressive 방식으로 유연한 길이의 긴 동영상을 생성할 수 있다. 또한, 궤적 planning과 시각적 생성을 분리함으로써, 본 모델은 실시간 motion planner로서 원활하게 기능하여 현재의 주행 환경 모델과 end-to-end motion planner 사이의 격차를 해소할 수 있다.
2. Epona: Autoregressive Diffusion World Model
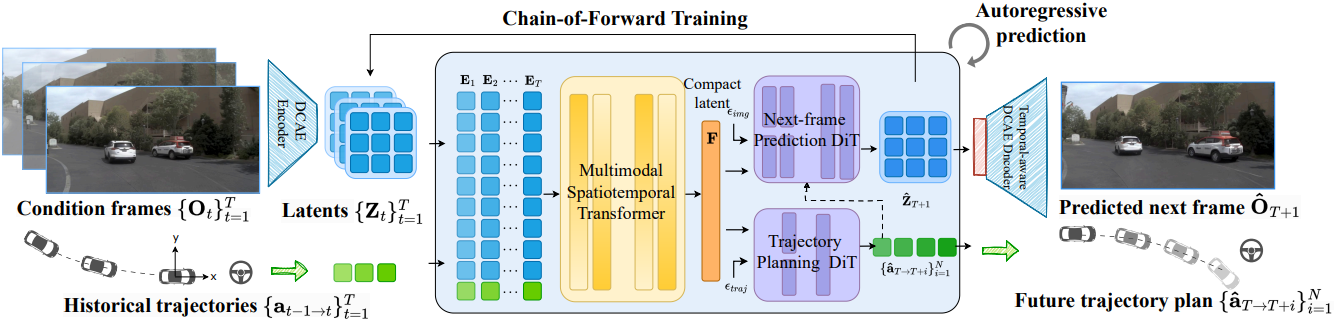
본 논문은 이 world model 디자인을 기반으로 자율 주행을 위한 autoregressive diffusion world model인 Epona를 제안하였다. 본 프레임워크는 세 가지 핵심 요소로 이루어져 있다.
먼저, MST는 과거 컨텍스트 \(\{\textbf{O}_t, \textbf{a}_t\}_{t=1}^T\)를 간결한 latent 표현으로 인코딩하여 환경 컨텍스트와 주행 역학을 효과적으로 포착한다. 그런 다음, 과거 latent들을 기반으로 TrajDiT는 궤적 planning을 위한 policy $\pi$를 모델링하고, VisDiT는 미래 이미지 생성을 위한 시각적 분포 $p$를 모델링한다.
이러한 모듈식 설계는 다양한 자율 주행 애플리케이션에 적용 가능하다. 예를 들어, MST와 VisDiT는 제어 가능한 주행 시뮬레이션에 독립적으로 사용할 수 있으며, MST와 TrajDiT는 실시간 motion planning을 지원한다.
Multimodal Spatiotemporal Transformer (MST)
인코딩된 과거 주행 장면 \(\{\textbf{Z}_t\}_{t=1}^T\)과 궤적 \(\{\textbf{a}_{t-1 \rightarrow t}\}_{t=1}^T\)가 주어졌을 때, 본 논문에서는 과거 컨텍스트에서 얻은 시간적 역동성과 멀티모달 정보를 효과적으로 통합하여 미래를 예측하는 MST를 제안하였다. 본 접근 방식은 멀티모달 spatial attention layer와 causal temporal attention layer를 교차 배치하여 사용한다. 이러한 디자인은 과거 정보를 점진적으로 압축된 latent 표현에 통합하는 동시에 full-sequence attention에 비해 메모리 사용량을 크게 줄인다. 또한, 이 디자인은 가변 길이의 과거 컨텍스트를 자연스럽게 지원한다.
구체적으로, 먼저 flatten된 latent 패치 $\textbf{Z} \in \mathbb{R}^{B \times T \times L \times C}$와 action 시퀀스 $\textbf{a} \in \mathbb{R}^{B \times T \times 3}$을 임베딩 공간으로 projection시킨다 ($B$는 batch size, $T$는 컨디셔닝 프레임 수, $L = H \times W$은 flatten된 latent 수, $C$는 latent 차원). 그런 다음, 이들을 공간 차원을 따라 concat하고 시간에 대한 위치 임베딩을 추가하여 latent 임베딩 시퀀스 \(\mathbf{E} \in \mathbb{R}^{B \times T \times (L+3) \times D}\)를 얻는다 ($D$는 임베딩 차원). 이 시퀀스는 다음과 같이 인터리브된 멀티모달 시공간 레이어를 통해 처리된다 (einops notation 사용).
\[\begin{aligned} \mathbf{E} &\leftarrow \textrm{rearrange} (\mathbf{E}, \texttt{(b t) l c} \rightarrow \texttt{(b l) t c}) \\ \mathbf{E} &\leftarrow \textrm{CausalTemporalLayer} (\mathbf{E}, \textrm{CausalMask}) \\ \mathbf{E} &\leftarrow \textrm{rearrange} (\mathbf{E}, \texttt{(b l) t c} \; \rightarrow \texttt{(b t) l c}) \\ \mathbf{E} &\leftarrow \textrm{MultimodalSpatialLayer} (\mathbf{E}) \end{aligned}\]($\textrm{CausalMask}$는 삼각형 causal attention mask)
마지막으로, 마지막 프레임의 latent 임베딩 \(\mathbb{F} \in \mathbb{R}^{B \times (L+3) \times D}\)를 다음 단계 예측을 위한 압축된 latent 표현으로 사용한다. 학습 후, 이 임베딩은 과거 컨텍스트 \(\{\textbf{O}_t, \textbf{a}_{t-1 \rightarrow t}\}_{t=1}^T\)을 캡슐화한다.
Trajectory Planning Diffusion Transformer (TrajDiT)
TrajDiT는 작은 DiT를 사용하여 미래 궤적을 예측하며, 기존 방법들에서 사용한 Dual-Single-Stream 아키텍처를 채택했다. Dual-stream 단계에서는 과거 latent 표현 $\textbf{F}$와 궤적 데이터가 transformer block을 통해 독립적으로 처리되며, attention 연산만을 통해 연결된다. Single-stream 단계에서는 이들을 concat하여 transformer block을 통과시킴으로써 효과적으로 정보를 융합한다.
학습 과정에서는 궤적 \(\bar{\textbf{a}} \in \mathbb{R}^{B \times N \times 3}\)에 noise를 추가한다. 그러면 모델은 $\mathbb{F}$를 조건으로 속도 \(v_\textrm{traj}\)를 예측한다. Rectified flow loss을 사용하여 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{traj} = \mathbb{E}_{\bar{\textbf{a}}, \epsilon, t} [\| v_\textrm{traj} (\bar{\textbf{a}}_{(t)}, t) - (\bar{\textbf{a}} - \epsilon) \|^2] \end{equation}\]Inference의 경우, $\textbf{F}$를 조건으로 랜덤 Gaussian noise를 반복적으로 denoising되어 미래 궤적 계획을 생성한다.
Next-frame Prediction Diffusion Transformer (VisDiT)
VisDiT는 TrajDiT와 유사한 아키텍처를 가지고 있으며, action 제어 \(\textbf{a}_{T \rightarrow T+1}\)를 위한 추가적인 modulation branch가 있다. Rectified flow loss를 사용하여 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{vis} = \mathbb{E}_{\textbf{Z}_{T+1}, \epsilon, t} [\| v_\textrm{vis} (\textbf{Z}_{T+1 (t)}, t) - (\textbf{Z}_{T+1} - \epsilon) \|^2] \end{equation}\]총 loss는 전체 world model을 공동으로 최적화한다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{traj} + \mathcal{L}_\textrm{vis} \end{equation}\]Inference 시에 VisDiT는 $\textbf{F}$와 TrajDiT가 예측했거나 사용자가 제공한 action를 조건으로 \(\hat{\textbf{Z}}_{T+1}\)의 noise를 제거한다. 그런 다음 DCAE 디코더를 사용하여 latent들을 디코딩하여 다음 프레임 이미지 \(\hat{\mathcal{O}}_{T+1}\)을 생성한다.
3. Chain-of-Forward Training
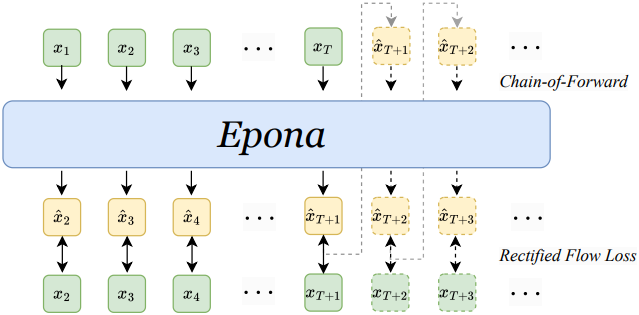
본 논문에서 제안하는 world model을 이용하면 미래 동영상을 프레임 단위로 autoregressive하게 생성할 수 있다. 그러나 긴 동영상 생성에는 드리프트 문제가 존재한다. 학습 단계에서는 모델이 GT 과거 컨텍스트를 사용하여 다음 프레임을 예측하는 반면, inference 단계에서는 자체적인 과거 예측에 의존한다. 이러한 도메인 격차는 오차 누적과 동영상 품질 저하를 초래한다.
본 논문에서는 이를 완화하기 위해 Chain-of-Forward 학습 전략을 도입하였다. 주기적으로 자체 예측 프레임을 사용하여 여러 번의 forward pass를 수행함으로써 inference noise에 대한 모델의 robustness를 향상시켰다. 특히, 학습 효율성을 보장하기 위해 순수한 noise에서 다음 프레임의 latent를 샘플링하는 대신, 모델이 예측한 속도 \(v_\Theta\)를 활용하여 one step으로 denoising된 latent를 추정한다.
\[\begin{equation} \hat{x}_{(0)} = x_{(t)} + t v_\Theta (x_{(t)}, t) \end{equation}\]추정된 \(\hat{x}_{(0)}\)은 이전의 컨디셔닝된 프레임과 함께 다음 forward pass에서 사용되어 후속 프레임을 autoregressive하게 생성한다. 이 프로세스는 예측 noise를 시뮬레이션하여 모델이 편차에 적응하고 긴 동영상 생성 품질을 향상시키는 데 도움이 된다.
4. Temporal-aware DCAE Decoder
기존 오토인코더는 이미지를 1/8로 다운샘플링하는 반면, DCAE는 1/32까지 점진적으로 다운샘플링시켜 latent 토큰 수를 16배 줄였다. 본 논문에서는 world model에 DCAE를 적용하여 학습 효율성을 높이고 메모리 사용량을 줄임으로써 더 긴 과거 데이터를 기반으로 학습할 수 있도록 했다.
하지만 이미지 오토인코더인 DCAE는 시간적 상호작용이 부족하여 동영상 프레임을 디코딩할 때 깜빡임 현상이 발생하고, 이는 동영상 품질을 저하시킨다. 이러한 문제를 해결하기 위해, 본 논문에서는 프레임 간 일관성을 향상시키는 Temporal-aware DCAE를 제안하였다. 구체적으로, 아키텍처 변경을 최소화하면서 사전 학습된 파라미터를 최대화하기 위해, fine-tuning 과정에서 인코더는 고정된 상태로 유지하면서 DCAE 디코더 앞에 spatiotemporal self-attention layer를 도입하였다. 이를 통해 여러 프레임 간의 상호작용이 가능해지고, 생성된 동영상의 시간적 일관성이 크게 향상된다.
Experiments
- 데이터셋: NuPlan, NuScenes (512$\times$1024)
- 구현 디테일
- 모델 구성 (총 2.5B)
- MST: 12 layer, 1.3B
- TrajDiT: 2 layer, 50M
- VisDiT: 12 layer, 1.2B
- iteration: 60만
- batch size: 96
- 10 step 마다 Chain-of-Forward 적용 (forward pass 3번)
- optimizer: AdamW
- learning rate: $1 \times 10^{-4}$
- weight decay: $5 \times 10^{-2}$
- GPU: NVIDIA A100 48개로 약 2주 학습
- 모델 구성 (총 2.5B)
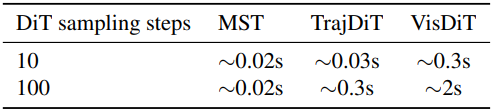
1. Evaluation of Video Generation
다음은 NuScenes validation set에 대하여 생성된 동영상 품질을 비교한 결과이다.

다음은 Vista와 생성된 동영상을 비교한 결과이다.

다음은 궤적을 조건으로 한 동영상 생성 결과들이다.

2. Evaluation of Trajectory Planning
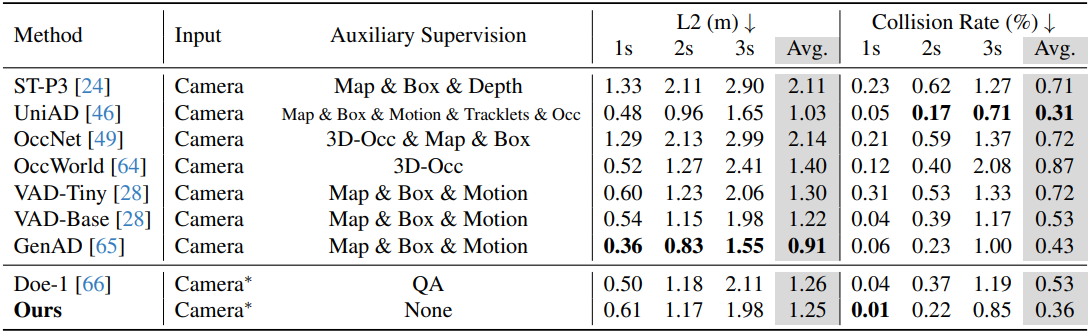
다음은 NuScenes에 대한 end-to-end motion planning 성능을 비교한 결과이다.
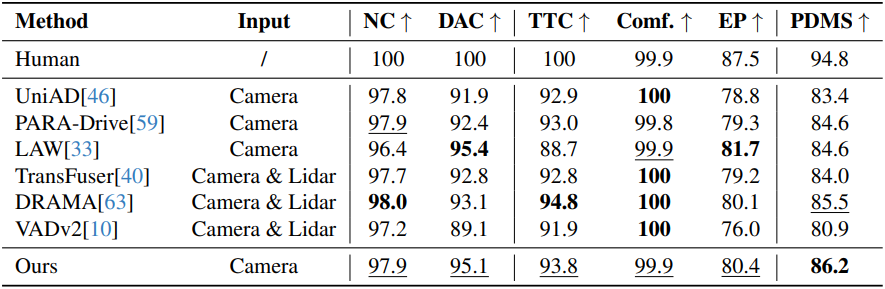
다음은 NAVSIM test set에 대한 end-to-end motion planning 성능을 비교한 결과이다.
3. Ablation Study
다음은 공동 학습에 대한 ablation study 결과이다. (NAVSIM test set)

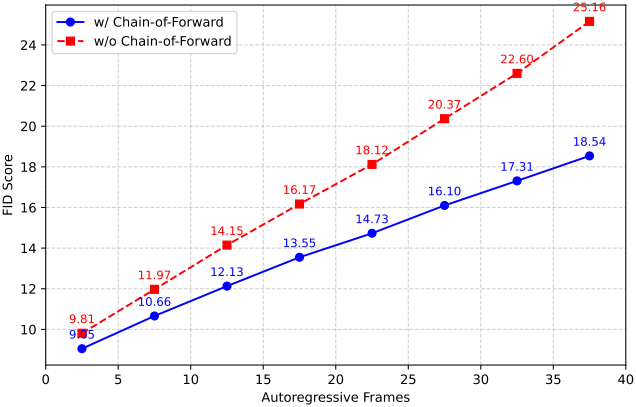
다음은 Chain-of-Forward에 대한 ablation study 결과이다.

다음은 Temporal-aware DCAE 디코더에 대한 ablation study 결과이다. (NuPlan test set)

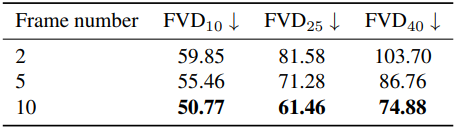
다음은 조건 프레임 수에 따른 성능을 비교한 결과이다. (NuPlan test set)