[논문리뷰] Subobject-level Image Tokenization
ICML 2025. [Paper] [Github]
Delong Chen, Samuel Cahyawijaya, Jianfeng Liu, Baoyuan Wang, Pascale Fung
Meta FAIR Paris | HKUST | Alibaba Group | Zillow
22 Feb 2024
Introduction
Subobject segmentation의 경우, Segment Anything Model (SAM)의 “segment anything” 모드가 유망한 방법이지만, 계산 비효율성과 분할되지 않은 영역이 존재한다는 단점이 있다. 본 논문에서는 이러한 두 가지 주요 한계점을 해결하기 위해 EPOC을 제안하였다. EPOC은 boundary detection과 watershed segmentation을 통합하였다. Boundary detection은 학습 task를 단순화하고 SAM의 641M 파라미터에서 3.7M 파라미터로 모델 크기를 줄이는 동시에 유사한 수준의 segmentation 품질을 달성할 수 있게 해준다. 또한, 재검토된 watershed 알고리즘은 포괄적인 segmentation을 보장하는 동시에 하나의 스칼라 hyperparameter를 통해 segmentation 세분성에 대한 유연한 제어를 제공한다. 이 디자인은 비용을 마스크 수에 관계없이 만들어 inference 효율성을 향상시킨다 (즉, $O(1)$ 복잡도).
Problem Formulation
입력 이미지를 $\textbf{X} \in \mathbb{R}^{H \times W \times 3}$라고 하고 타겟 레이블을 $\textbf{Y}$라고 했을 때, 이미지 이해에 대한 task는 $\textbf{X}$를 $\textbf{Y}$에 매핑하는 함수 $f$를 학습하는 것이다. Transformer와 같은 시퀀스 모델을 사용할 때, 이러한 매핑은 $\textbf{X}$와 $\textbf{Y}$에서 파생된 토큰 시퀀스를 처리하고 생성함으로써 달성된다. 즉, \(f([\textbf{x}_1, \ldots, \textbf{x}_N]) = [\textbf{y}_1, \ldots, \textbf{y}_m]\)이며, 각 벡터 \(\textbf{x}_i \in \mathbb{R}^d\)는 개별 비주얼 토큰이고 \(\{\textbf{y}_i\}_{i=1}^m\)은 텍스트 토큰이다. Image tokenization은 입력 $\textbf{X}$를 비주얼 토큰의 컴팩트한 집합 \([\textbf{x}_1, \ldots, \textbf{x}_N]\)로 변환하는 것이다.
Image tokenization은 token segmentation과 토큰 임베딩으로 구성된다. Token segmentation은 입력 이미지 $\textbf{X} \in \mathbb{R}^{H \times W \times 3}$에서 토큰 인덱스 맵 \(\textbf{M} \in \{0, \ldots, N −1\}^{H \times W}\)를 생성하는 것을 목표로 한다. 토큰 인덱스 맵은 각 픽셀을 $N$개의 토큰 중 하나에 할당한다. 동일한 토큰 인덱스에 할당된 모든 픽셀은 개별 비주얼 토큰으로 그룹화된다.
Adaptive Token Segmentation
1. Segment Anything Model (SAM)
SAM은 다양한 image segmentation 벤치마크에서 강력한 성능을 보여주지만, image tokenization에서의 효과적인 적용은 다음의 두 가지 중요한 한계로 인해 방해를 받는다.
- 효율성: 32$\times$32 포인트 프롬프트의 그리드를 사용하여 하나의 이미지에서 segment anything을 하려면 1,024번의 마스크 디코더 forward pass가 필요하다. 마스크 디코더가 경량화되었고 인코더 크기 감소 및 프롬프트 수 감소와 같은 개선 사항이 도입되었지만 복잡도는 여전히 $O(N)$이다.
- 포괄성: SAM의 segment anything 모드의 결과는 panoptic segmentation이라는 보장이 없다. 각 마스크를 독립적으로 생성하는 SAM의 디자인은 개별 세그먼트 사이에 유격을 도입하거나 특정 배경 영역이 분할되지 않은 상태로 남을 수 있다.
2. Proposed EPOC
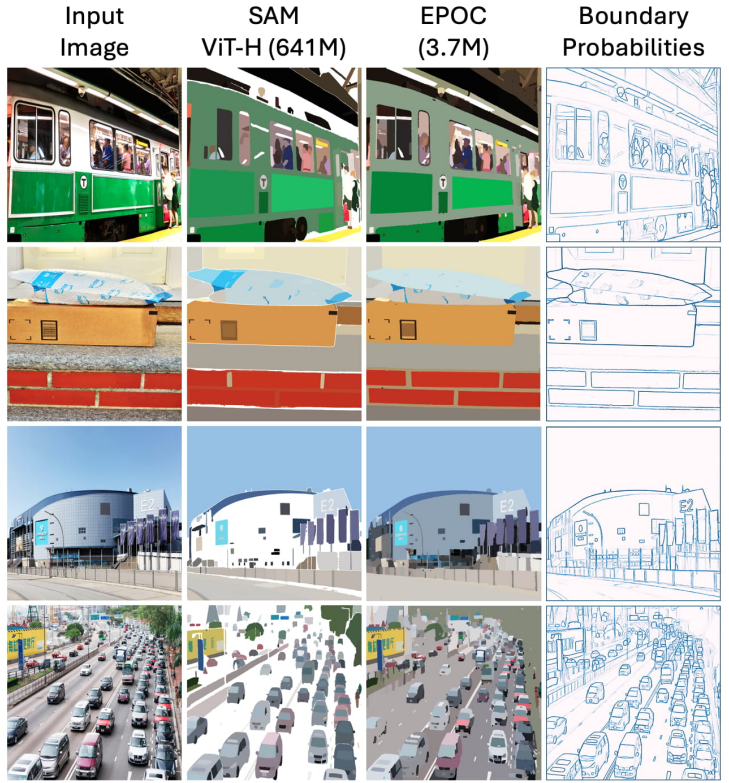
본 논문에서는 EPOC이라는 새로운 segment anything 접근 방식을 제안하였다. EPOC은 포괄적인 segmentation을 보장하는 동시에 계산 효율을 크게 향상시킨다. SAM의 프롬프트 기반 마스크 디코딩과 달리, EPOC은 boundary detection 방식을 채택하여 전체 이미지에 걸쳐 subobject들의 윤곽을 나타내는 경계 확률 맵 \(\textbf{P} \in [0,1]^{H \times W}\)를 예측한다. 이 접근 방식은 개별 마스크 생성에 따른 오버헤드를 줄이고 boundary detection의 단순성을 활용한다. 이러한 단순성 덕분에 매우 컴팩트한 모델을 사용할 수 있다. 본 논문에서는 3.7M 파라미터만을 갖는 SegFormer-b0를 SA-1B 데이터셋으로 학습시켰다.
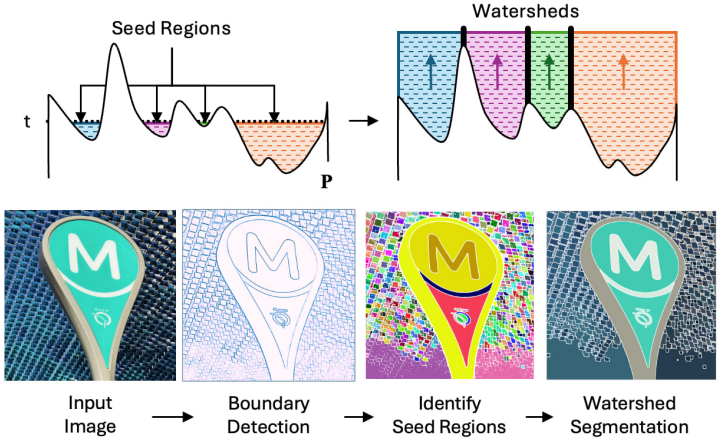
예측된 경계 확률 맵 $\textbf{P}$를 기반으로 토큰 segmentation map $\textbf{M}$을 도출하기 위해, 포괄성을 자연스럽게 보장하는 watershed 알고리즘을 사용한다. 이 방법은 예측된 $\textbf{P}$를 지형학적 표면로 취급한다. 확률이 높은 곳은 봉우리나 능선과 같은 높은 영역에 해당하고 확률이 낮은 곳은 유역을 나타냅니다. 이 알고리즘은 이러한 유역의 점진적인 “홍수”를 시뮬레이션하며, segmentation mask의 경계가 생성되어 서로 다른 유역 간에 물이 합쳐지는 것을 방지하는 장벽 역할을 한다.
Watershed는 일반적으로 “홍수”를 시작하기 위해 시드 영역이 필요하며, 이는 $\textbf{P}$에 threshold $t$를 적용하여 얻는다. $t$ 미만의 픽셀은 물체 내부에 있는 것으로 가정하고 시드 역할을 한다. $t$를 조정하면 segmentation 결과의 세분성을 완벽하게 제어할 수 있다. $t$가 높을수록 시드를 더 큰 세그먼트로 병합하는 반면, $t$가 낮을수록 더 미세한 디테일이 유지된다.
EPOC은 세 가지 장점을 통해 계산 효율성을 달성하였다.
- 경계 확률 예측 모델은 한 번의 forward pass로 전체 이미지에 대해 연산을 수행하여 토큰 개수 $N$에 관계없이 $O(1)$의 복잡도를 보인다.
- SegFormer-b0의 간결성은 GPU 메모리 사용량을 더욱 줄여 대규모 batch size 또는 멀티프로세스 병렬 처리를 가능하게 한다.
- Watershed 알고리즘은 따로 학습이 필요 없으며 CPU에서 효율적으로 실행된다.
Evaluations
1. Intrinsic Evaluations
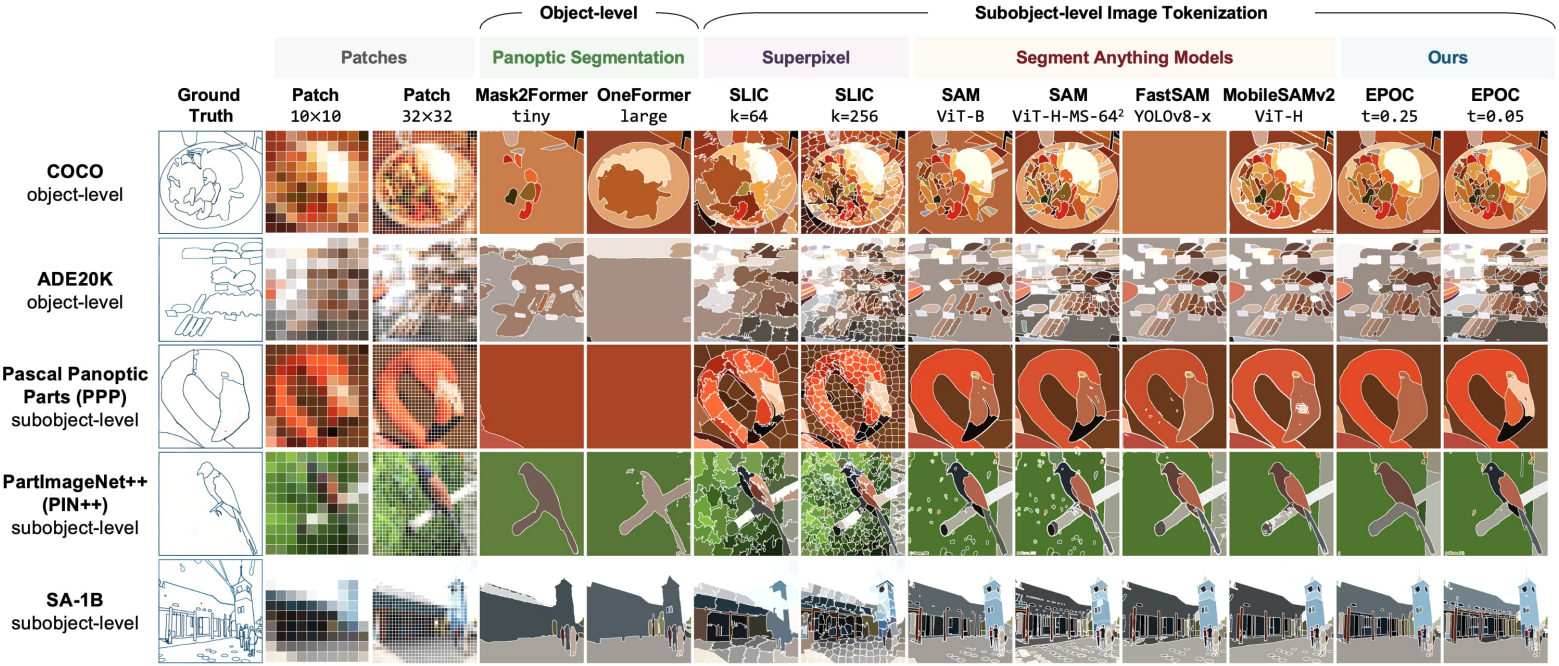
다음은 token segmentation 성능을 비교한 결과이다.
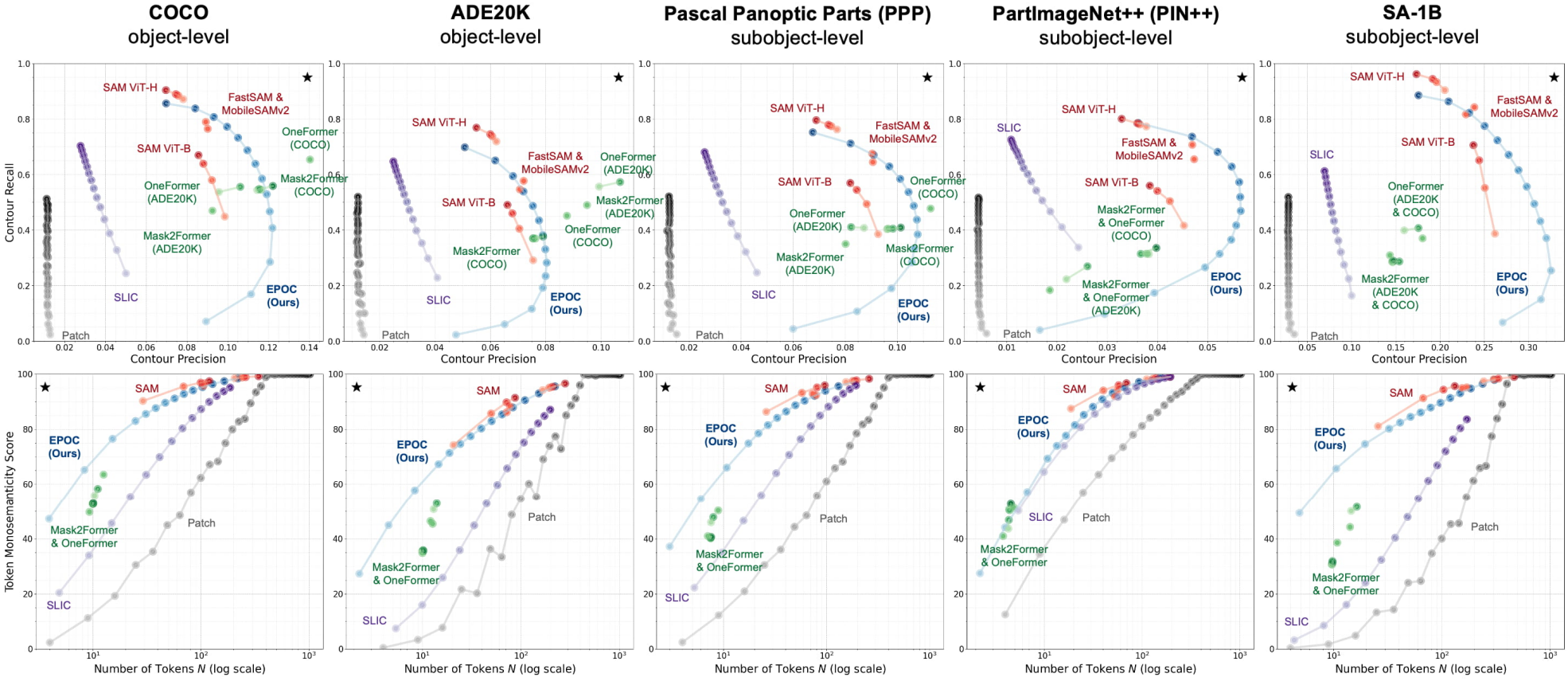
다음은 image tokenizer의 계산 효율성을 비교한 표이다.
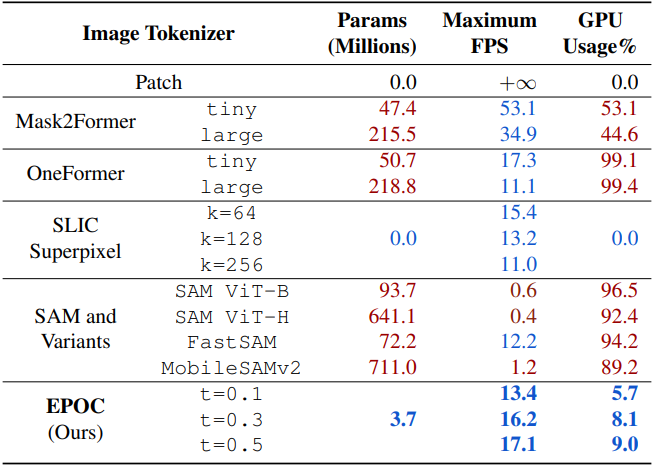
2. Extrinsic Evaluations
다음은 VLM 학습에 각 image tokenizer를 사용하였을 때의 validation perplexity를 비교한 그래프이다.
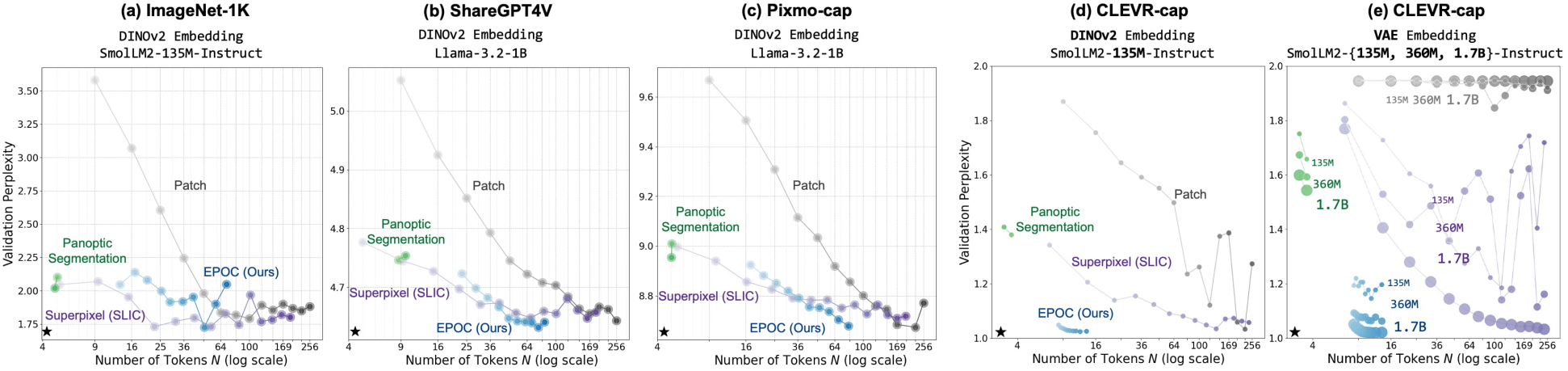
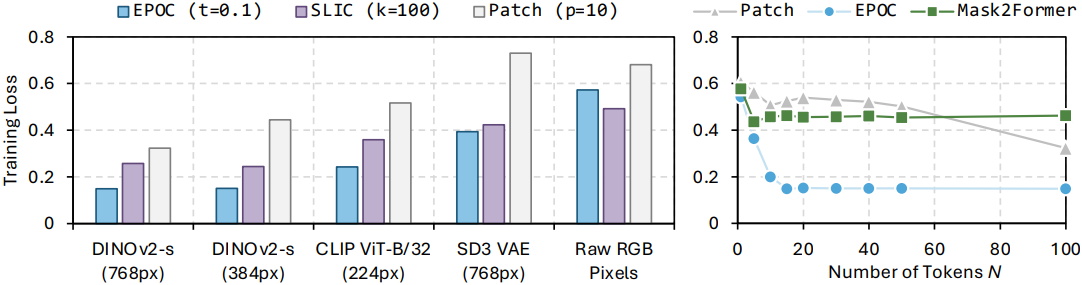
다음은 (왼쪽) 사용한 토큰 임베딩과 (오른쪽) 토큰 수 $N$에 대한 ablation 결과이다.