[논문리뷰] EnvGS: Modeling View-Dependent Appearance with Environment Gaussian
CVPR 2025. [Paper] [Page] [Github]
Tao Xie, Xi Chen, Zhen Xu, Yiman Xie, Yudong Jin, Yujun Shen, Sida Peng, Hujun Bao, Xiaowei Zhou
Zhejiang University | Ant Group
19 Dec 2024

Introduction
3D Gaussian Splatting (3DGS)은 3D Gaussian을 사용하여 장면을 명시적으로 모델링하고 렌더링에 rasterization을 활용하여 경쟁력 있는 품질로 실시간 렌더링을 달성하였다. 그러나 복잡한 고주파 정반사(specular reflection)를 모델링하는 것은 Spherical Harmonics (SH)의 표현력이 제한되어 3DGS에 여전히 어려운 과제이다.
최근, GaussianShader와 3DGS-DR은 environment map을 통합하고 셰이딩 함수를 사용하여 최종 렌더링을 위해 environment map과 SH에서 얻은 색상을 혼합하여 3DGS를 향상시켰다. 추가적인 환경 조명은 3DGS의 반사 모델링 능력을 향상시킬 수 있지만 두 가지 요인으로 인해 복잡한 정반사를 정확하게 재구성하는 데 여전히 어려움을 겪는다.
- Environment map에서의 원거리 조명 가정은 원거리 조명만 캡처하는 능력으로 제한하고 정확한 근거리 반사를 합성하기 어렵다.
- Environment map은 본질적으로 고주파의 디테일한 반사를 캡처하기에 용량이 충분하지 않다.
본 논문에서는 실제 장면에서 복잡한 반사를 모델링하기 위한 새로운 접근 방식인 EnvGS를 제시하여 앞서 언급한 과제를 해결하였다. Environment Gaussian이라는 Gaussian을 사용하여 반사를 모델링한다. 형상과 기본 외형은 base Gaussian이라는 또 다른 Gaussian들로 표현된다. 렌더링 및 최적화를 위해 두 Gaussian을 효과적으로 블렌딩한다.
렌더링 프로세스는 픽셀별 표면 위치, normal, 기본 색상, 블렌딩 가중치에 대한 base Gaussian을 렌더링하는 것으로 시작한다. 다음으로, 표면 normal 주변의 뷰 방향의 반사 방향으로 표면 지점에서 environment Gaussian을 렌더링하여 반사 색상을 캡처한다. 마지막으로 기본 색상을 반사 색상과 블렌딩하여 최종 렌더링 결과를 얻는다.
EnvGS는 Gaussian을 사용하여 디테일한 반사를 캡처하여 environment map에 비해 뛰어난 모델링 능력을 제공한다. 더불어, 명시적인 3D 반사 표현은 원거리 조명 가정의 필요성을 없애고, 가까운 거리의 반사를 정확한 모델링한다.
반사 방향을 따라 각 교차점에서 환경을 Gaussian으로 렌더링하기 위해 rasterization이 적합하지 않기 때문에, 저자들은 2DGS에 대한 완전히 미분 가능한 ray tracing renderer를 만들었다. 실시간 렌더링과 environment Gaussian의 효율적인 최적화를 위해 CUDA와 OptiX에서 ray tracing renderer를 빌드하였다. 렌더링 프로세스는 2D Gaussian에서 bounding volume hierarchy (BVH)를 구성한 다음, BVH에 광선을 투사하여 청크로 정렬된 교차점을 수집하고 볼륨 렌더링을 통해 Gaussian 속성을 통합하여 최종 결과를 얻는다.
Gaussian ray tracing renderer는 실시간으로 자세한 반사 렌더링을 가능하게 한다. 또한 정확한 반사 모델링에 필수적인 environment Gaussian과 base Gaussian의 효율적인 공동 최적화를 가능하게 한다.
EnvGS는 실시간 novel view synthesis에서 SOTA 성능을 달성하고, 특히 실제 장면에서 복잡한 반사를 합성하는 데 있어서 기존의 실시간 방법을 상당히 능가한다.
Method
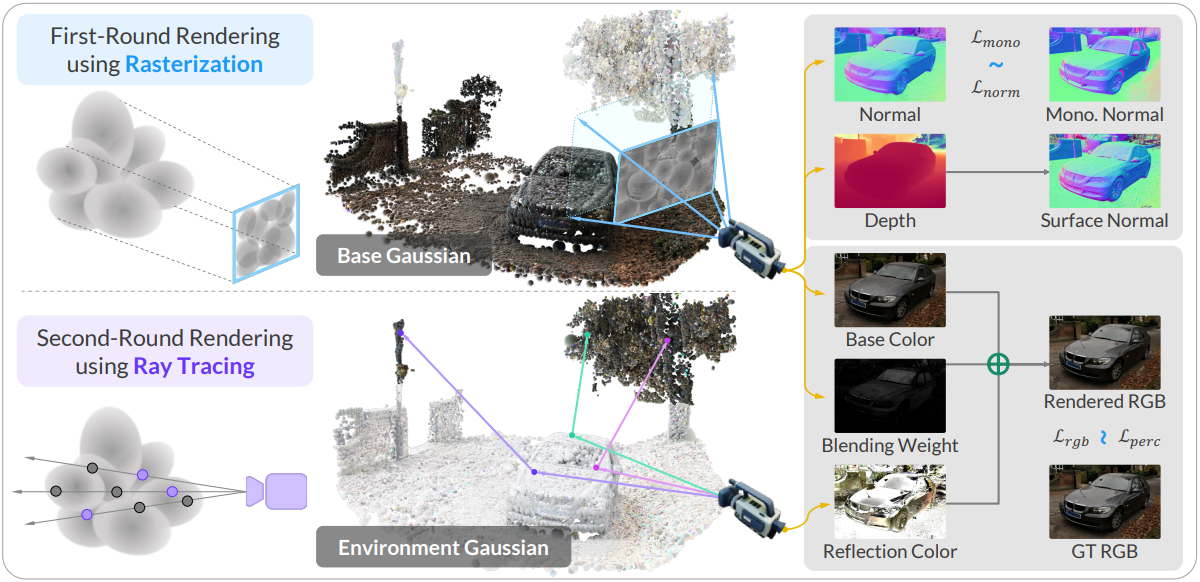
본 논문의 목표는 입력 이미지 집합이 주어지면, 3D 장면을 재구성하고 실시간으로 사실적인 새로운 뷰를 합성하는 것이다. 저자들은 실제 장면에서 복잡한 반사를 정확하게 모델링할 수 있는 명시적 3D 환경 표현으로 environment Gaussian을 활용하는 것을 제안하였다. 또한, base Gaussian이라 부르는 또 다른 Gaussian들을 사용하여 장면 형상과 기본 색상을 표현한다.
1. Reflective Scenes Modeling
Gaussian splatting은 뷰 종속 효과에 대한 표현 용량이 제한적인 Spherical Harmonics (SH)를 사용하여 외형을 모델링한다. 이러한 제한은 복잡하고 디테일한 정반사를 포착하는 능력을 방해한다. 저자들의 핵심 통찰력은 Gaussian으로 반사를 모델링하면 각 Gaussian이 SH 내에서 복잡한 디테일을 포착하는 데 필요한 복잡성을 크게 줄이면서 복잡한 반사 효과를 더 잘 모델링할 수 있다는 것이다.
제안된 반사 장면 표현에는 두 세트의 2D Gaussian이 포함된다.
- base Gaussian \(\mathbf{P}_\textrm{base}\): 장면의 형상과 기본 외형을 모델링
- environment Gaussian \(\mathbf{P}_\textrm{env}\): 장면 반사를 캡처
각 Gaussian의 기본 parameterization은 3D 중심 위치 $\mathbf{p}$, 불투명도 $\alpha$, 두 개의 접선 벡터 \((\mathbf{t}_u, \mathbf{t}_v)\), 스케일링 벡터 $(s_u, s_v)$, SH 계수를 포함하여 원래 2DGS와 일치한다. Base Gaussian과 environment Gaussian을 최종 결과로 결합하기 위해 각 base Gaussian에 블렌딩 가중치 $\beta$를 도입한다.
렌더링 프로세스는 세 단계로 수행된다. 먼저, base Gaussian \(\mathbf{P}_\textrm{base}\)는 기본 색상 \(\mathbf{c}_\textrm{base}\)를 얻기 위해 2D Gaussian Splatting을 사용하여 렌더링된다. 볼륨 렌더링을 통해 표면 위치 $\mathbf{x}$, 표면 normal $\mathbf{n}$, 블렌딩 가중치 $\beta$를 다음과 같이 얻는다.
\[\begin{equation} v = \sum_{i \in \mathcal{N}} = v_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j), \; v \in \{\mathbf{x}, \mathbf{n}, \beta\} \end{equation}\]그런 다음 카메라 광선 방향 \(\mathbf{d}_\textrm{cam}\)과 표면 normal $\mathbf{n}$을 기반으로 반사 방향 \(\mathbf{d}_\textrm{ref}\)를 계산한다.
\[\begin{equation} \mathbf{d}_\textrm{ref} = \mathbf{d}_\textrm{cam} - 2 (\mathbf{d}_\textrm{cam} \cdot \mathbf{n}) \mathbf{n} \end{equation}\]반사 방향 \(\mathbf{d}_\textrm{ref}\)와 표면 지점 $\mathbf{x}$를 사용하여 environment Gaussian \(\mathbf{P}_\textrm{env}\)는 미분 가능한 Gaussian tracer를 사용하여 렌더링되어 반사 색상 \(\mathbf{c}_\textrm{ref}\)를 얻는다. 최종 색상은 블렌딩 가중치 $\beta$를 사용하여 기본 색상 \(\mathbf{c}_\textrm{base}\)와 반사 색상 \(\mathbf{c}_\textrm{ref}\)를 블렌딩하여 얻는다.
\[\begin{equation} \mathbf{c} = (1 - \beta) \cdot \mathbf{c}_\textrm{base} + \beta \cdot \mathbf{c}_\textrm{ref} \end{equation}\]
GaussianShader와 3DGS-DR에서 사용하는 environment map과 비교했을 때, 명시적인 environment Gaussian은 여러 가지 장점을 제공한다.
- 근처 물체의 가려짐으로 인해 발생하는 근거리 반사를 더 정확하게 포착한다. 이러한 개선은 각 Gaussian을 정확한 공간 위치에서 명시적으로 모델링하여 원거리 조명을 가정하는 environment map 표현에 내재된 모호성과 부정확성을 피했기 때문이다.
- EnvGS의 환경 표현은 Gaussian을 활용하여 저주파 environment map보다 더 큰 표현력을 달성하여 더 세밀한 반사 디테일을 포착하고 렌더링 품질을 향상시킬 수 있다.
2. Differentiable Ray Tracing
Rasterization을 사용하여 환경을 Gaussian으로 렌더링하는 것은 각 픽셀이 고유한 반사 광선에 해당하고 가상 카메라로 기능하기 때문에 비실용적이다. 저자들은 이를 해결하기 위해 최신 GPU의 고급 최적화를 활용하여 완전히 미분 가능한 새로운 ray tracing 프레임워크를 설계하였다. OptiX를 기반으로 구축된 프레임워크는 RTX 4090 GPU에서 30 FPS, 1292$\times$839의 해상도로 200만 개의 2DGS를 실시간으로 렌더링한다.
Ray-primitive intersection에 대한 하드웨어 가속을 최대한 활용하기 위해 각 2D Gaussian을 GPU 처리와 호환되는 geometric primitive로 변환하고 bounding volume hierarchy (BVH)에 삽입해야 한다. 이를 고려하여 각 2D Gaussian을 두 개의 삼각형으로 표현한다. 구체적으로, 먼저 로컬 접평면에서 네 개의 Gaussian bounding vertex를 정의한다.
\[\begin{equation} V_\textrm{local} = \{(r, r), (r, -r), (-r, r), (-r, -r)\} \end{equation}\]($r$은 3으로 설정)
그런 다음 네 개의 \(V_\textrm{local}\)은 transformation matrix
\[\begin{equation} \mathbf{H} = \begin{bmatrix} s_u \mathbf{t}_u & s_v \mathbf{t}_v & 0 & \mathbf{p}_k \\ 0 & 0 & 0 & 1 \end{bmatrix} \end{equation}\]를 사용하여 world space로 변환되어 Gaussian \(V_\textrm{world}\)를 덮는 두 삼각형이 된다. 변환 후 삼각형은 BVH로 구성되며 이는 ray tracing 프로세스의 입력으로 사용된다.
저자들은 OptiX의 raygen과 anyhit을 사용하여 커스텀 CUDA 커널을 개발하였다. 3DGRT와 동일하게 렌더링은 청크 단위로 수행된다. anyhit 커널은 입력 광선을 추적하여 크기 $k$의 청크를 얻으며, raygen은 이 청크를 통합하고 anyhit을 호출하여 광선을 따라 다음 청크를 검색한다.
구체적으로 원점이 $\mathbf{o}$이고 방향이 $\mathbf{d}$인 입력 광선을 고려하자. raygen 프로그램은 먼저 BVH에 대한 순회를 시작하여 광선을 따라 가능한 모든 교차점을 식별한다. 순회 중에 anyhit 프로그램은 깊이에 따라 교차된 각 Gaussian을 정렬하고 가장 가까운 $k = 16$개의 교차점에 대해 정렬된 $k$-buffer를 유지한다. 순회 후 raygen 프로그램은 볼륨 렌더링 식에 따라 $k$-buffer에 있는 정렬된 Gaussian의 속성을 통합한다. Transformation matrix $\mathbf{H}$의 역행렬을 광선의 교차점 \(\mathbf{x}_i\)에 적용하고 변환된 지점의 Gaussian 값을 다음과 같이 평가하여 계산된다.
이 과정은 광선을 따라 더 이상 교차점이 발견되지 않거나 누적 투과율이 지정된 threshold 아래로 떨어질 때까지 반복된다.
Ray tracing 프레임워크는 완전히 미분 가능하여 base Gaussian과 environment Gaussian의 end-to-end 최적화가 가능하다. 그러나 3DGS에서와 같이 forward pass 중에 모든 교차점을 저장하고 backward pass를 뒤에서 앞으로 순서대로 수행하는 것은 메모리 소모가 높아서 비실용적이다. 이를 해결하기 위해 광선을 다시 캐스팅하고 각 단계에 대한 gradient를 계산하여 forward pass와 동일하게 앞에서 뒤 순서로 backward pass를 구현한다. 핵심적인 측면은 입력 광선 원점과 방향에 대한 gradient \(\frac{\partial \mathcal{L}}{\partial \mathbf{o}}\)와 \(\frac{\partial \mathcal{L}}{\partial \mathbf{d}}\)를 계산하는 것이며, 이는 모델의 공동 최적화에 매우 중요하다. 이러한 형상 및 외형의 공동 최적화가 기하학적으로 정확한 표면을 복구하는 데 필수적이다.
3. Optimization
학습 안정성을 높이기 위해 Structure-from-Motion (SfM)에서 얻은 sparse한 포인트 클라우드로 초기화된 base Gaussian \(\mathbf{P}_\textrm{base}\)를 먼저 학습하여 최적화를 시작한다. 그런 다음, 장면의 bounding box \(\mathbf{B}_\textrm{scene}\)을 $N^3$개의 sub-grid로 분할하고 각 sub-grid 내에서 무작위로 $K$개의 environment Gaussian \(\mathbf{P}_\textrm{env}\)를 초기화한 다음, base Gaussian과 environment Gaussian을 함께 최적화한다. \(\mathbf{B}_\textrm{scene}\)은 SfM에서 얻은 포인트 클라우드의 bounding box \(\mathbf{B}_\textrm{sfm}\)의 99.5% quantile로 결정되고, sub-grid 해상도 $N$은 32, 각 sub-grid의 $K$는 5로 설정된다.
렌더링된 normal map $\mathbf{n}$과 depth map의 gradient \(\mathbf{N}_d\)에 normal 일관성 제약 조건을 추가하기 위해 2DGS를 따른다.
\[\begin{equation} \mathcal{L}_\textrm{norm} = \frac{1}{N_p} \sum_{i=1}^{N_p} (1 - \mathbf{n}_i^\top \mathbf{N}_d) \\ \textrm{where} \; \mathbf{N}_d (\mathbf{u}) = \frac{\nabla_u \mathbf{p}_d \times \nabla_v \mathbf{p}_d}{\| \nabla_u \mathbf{p}_d \times \nabla_v \mathbf{p}_d \|} \end{equation}\]그러나 normal 일관성 제약만으로는 반사와 굴절을 모두 포함하는 모호한 표면을 정확하게 모델링하기에 충분하지 않다. 따라서 렌더링된 normal map $\mathbf{n}$과 monocular normal 추정치 \(\mathbf{N}_m\) 사이의 일관성 제약 조건을 추가한다.
\[\begin{equation} \mathcal{L}_\textrm{mono} = \frac{1}{N_p} \sum_{i=1}^{N_p} (1 - \mathbf{n}_i^\top \mathbf{N}_m) \end{equation}\]3DGS에서 사용하는 이미지 loss \(\mathcal{L}_1\)과 D-SSIM loss \(\mathcal{L}_\textrm{SSIM}\) 외에도, 렌더링된 이미지의 품질을 향상시키기 위해 perceptual loss도 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{perc} = \| \Phi (\mathbf{I}) - \Phi (\mathbf{I}_\textrm{gt}) \|_1 \end{equation}\]($\Phi$는 사전 학습된 VGG-16 네트워크, $\mathbf{I}$는 렌더링된 이미지, \(\mathbf{I}_\textrm{gt}\)는 실제 이미지)
최종 loss function은 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{rgb} + \lambda_1 \mathcal{L}_\textrm{norm} + \lambda_2 \mathcal{L}_\textrm{mono} + \lambda_3 \mathcal{L}_\textrm{perc} \\ \textrm{where} \; \mathcal{L}_\textrm{rgb} = (1 - \lambda) \mathcal{L}_1 + \lambda \mathcal{L}_\textrm{SSIM} \end{equation}\]($\lambda = 0.2$, \(\lambda_1 = 0.04\), \(\lambda_2 = 0.01\), \(\lambda_3 = 0.01\))
Experiments
- 데이터셋: Ref-Real, NeRF-Casting Shiny Scenes, 자체 캡처한 장면들
- 구현 디테일
1. Baseline Comparisons
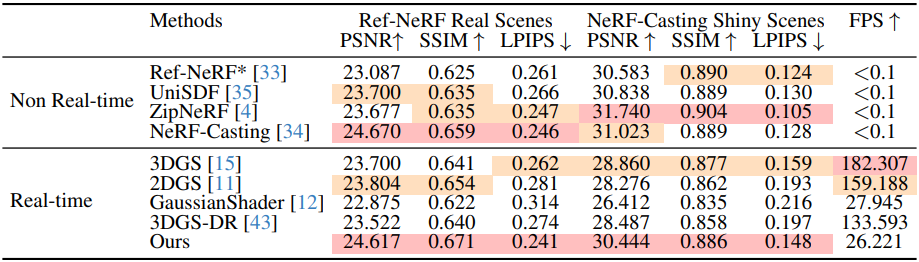
다음은 Ref-Real과 NeRF-Casting Shiny Scenes에 대한 비교 결과이다.

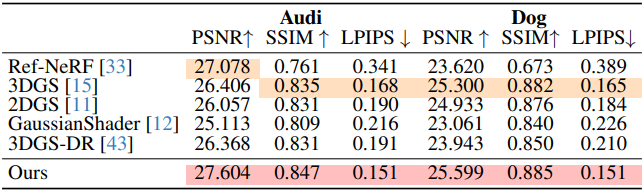
다음은 저자들이 직접 캡처한 장면들에 대한 비교 결과이다.
2. Ablation Studies
다음은 ablation study 결과이다.