[논문리뷰] Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
arXiv 2026. [Paper] [Github]
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, Wenfeng Liang
Peking University | DeepSeek-AI
12 Jan 2026
Introduction
언어 모델링은 질적으로 다른 두 가지 하위 task, 즉 구성적 추론과 지식 검색을 포함한다. 전자는 깊고 동적인 계산을 요구하는 반면, 텍스트의 상당 부분은 로컬하고 정적이며 고도로 정형화되어 있다. 이러한 로컬 의존성을 포착하는 데 있어 고전적인 $N$-gram 모델의 효율성은 이러한 규칙성이 계산 비용이 저렴한 조회로 자연스럽게 표현될 수 있음을 시사한다. 표준 Transformer에는 지식 조회 기능이 없기 때문에 현재의 LLM은 계산을 통해 검색을 시뮬레이션해야 한다. 예를 들어, 익숙한 복합 단어를 인식하는 데도 여러 attention layer와 FFN layer가 필요하다. 이 과정은 본질적으로 정적 lookup table을 런타임에 재구성하는 비용이 많이 드는 작업으로, 상위 수준 추론에 할당될 수 있는 귀중한 layer들을 사소한 연산에 낭비하게 된다.
이러한 언어적 이중성에 맞춰 모델 아키텍처를 조정하기 위해, 본 논문은 조건부 메모리를 제안하였다. 조건부 연산이 동적 논리를 처리하기 위해 파라미터를 sparse하게 활성화하는 반면, 조건부 메모리는 고정된 지식에 대한 정적 임베딩을 검색하기 위해 sparse한 조회 연산에 의존한다. 이 패러다임을 예비적으로 탐구하기 위해, 저자들은 $N$-gram 임베딩에 대한 실험을 진행했으며, 로컬 컨텍스트가 $\mathcal{O}(1)$ 조회를 통해 방대한 임베딩 테이블을 인덱싱하는 key 역할을 한다. 실험 결과, 놀랍게도 이러한 정적 검색 메커니즘이 적절하게 설계된 경우 현대 MoE 아키텍처를 이상적으로 보완할 수 있음을 보여준다. 본 논문에서는 고전적인 $N$-gram 구조에 기반을 두고 조건부 메모리 모듈인 Engram을 제안하였다.
저자들은 이 두 가지 primitive 간의 시너지 효과를 정량화하기 위해 sparsity allocation 문제를 구성했다. 즉, 고정된 총 파라미터 예산이 주어졌을 때 MoE expert와 Engram 메모리 사이에 용량을 어떻게 분배해야 하는지를 정의했다. 실험 결과, 뚜렷한 U자형 scaling law가 나타났으며, 이는 단순한 조회 메커니즘조차도 모델링 primitive로 취급될 때 신경망 계산을 보완하는 데 필수적인 역할을 한다는 것을 보여준다.
저자들은 이 allocation law에 따라 Engram을 27B 모델로 scaling했다. 동일한 파리미터 수와 동일한 FLOPs를 가진 MoE baseline과 비교했을 때, Engram-27B는 다양한 도메인에서 우수한 효율성을 달성했다. 특히, 이러한 효율성 향상은 메모리 용량이 직관적으로 유리한 지식 집약적 task에만 국한되지 않으며, 일반적인 추론 능력과 코드/수학 도메인에서 훨씬 더 큰 향상이 있었다.
Architecture
1. Overview
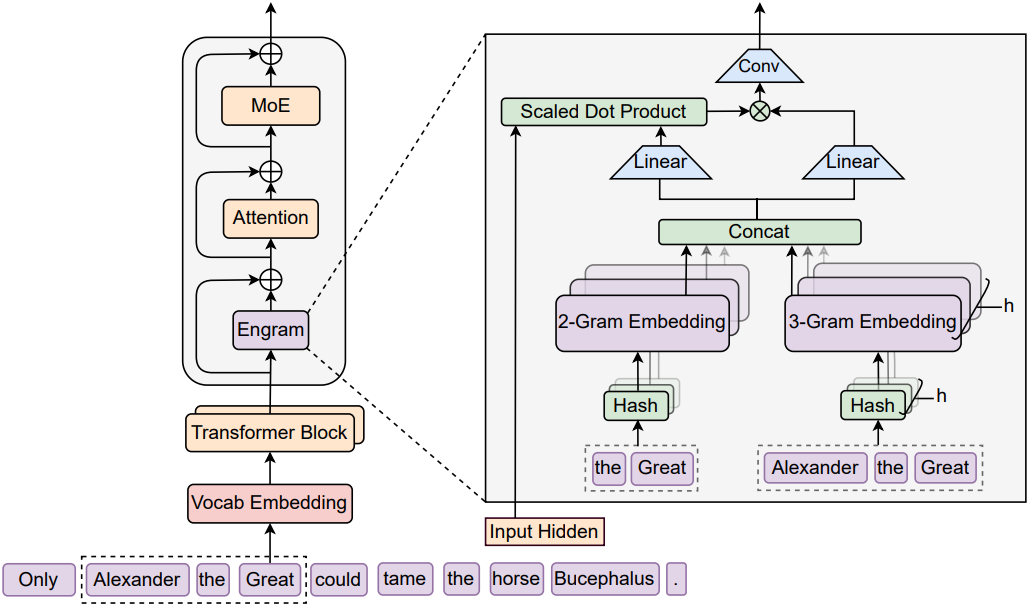
Engram은 Transformer backbone을 강화하기 위해 정적 패턴 저장과 동적 연산을 구조적으로 분리하도록 설계된 조건부 메모리 모듈이다. 입력 시퀀스 $X = (x_1, \ldots, x_T)$와 layer $\ell$에서의 hidden state $\textbf{H}(\ell) \in \mathbb{R}^{T \times d}$가 주어졌을 때, 이 모듈은 각 위치 $t$를 두 가지 단계, 즉 검색과 융합을 통해 처리한다. 먼저, suffix $N$-gram을 추출하고 압축하여 해싱을 통해 정적 임베딩 벡터를 deterministic하게 검색한다. 다음으로, 이러한 검색된 임베딩은 현재 hidden state에 의해 동적으로 변조되고 가벼운 convolution을 통해 정제된다.
2. Sparse Retrieval via Hashed $N$-grams
첫 번째 단계에서는 로컬 컨텍스트를 정적 메모리 entry에 매핑하는데, 이 과정에는 tokenizer 압축과 deterministic한 해싱을 통한 임베딩 검색이 포함된다.
Tokenizer Compression
$N$-gram 모델은 일반적으로 tokenizer 출력에 직접 접근하는 반면, 표준 subword tokenizer들은 무손실 재구성을 우선시하여 의미적으로 동일한 용어에 서로 다른 ID를 할당하는 경우가 많다. 저자들은 semantic 밀도를 극대화하기 위해 vocabulary projection layer를 구현했다. 구체적으로, 정규화된 텍스트 동등성 (ex. 소문자 변환, NFKC)을 기반으로 토큰 ID를 표준 식별자로 변환하는 전사 함수 \(\mathcal{P} : V \rightarrow V^\prime\)을 미리 계산한다. 실제로 이 과정을 통해 128k tokenizer의 유효 vocabulary 크기를 23% 줄일 수 있다. 위치 $t$에 있는 토큰의 경우, 해당 ID $x_t$를 \(x_t^\prime = \mathcal{P} (x_t)\)로 매핑하여 suffix $N$-gram $g_{t,n} = (x_{t-n+1}^\prime, \ldots, x_t^\prime)$을 형성한다.
Multi-Head Hashing
가능한 모든 $N$-gram의 조합 공간을 직접 parameterize하는 것은 불가능하다. 따라서 본 논문에서는 해싱 기반 접근 방식을 채택하였다. 충돌을 완화하기 위해 각 $N$-gram 순서 $n$에 대해 $K$개의 서로 다른 hash head를 사용한다. 각 head $k$는 deterministic function \(\phi_{n,k}\)를 통해 압축된 컨텍스트를 임베딩 테이블 \(\textbf{E}_{n,k}\) 내의 인덱스로 매핑한다.
\[\begin{equation} z_{t,n,k} = \phi_{n,k} (g_{t,n}), \quad \textbf{e}_{t,n,k} = \textbf{E}_{n,k} [z_{t,n,k}] \end{equation}\]실제로 \(\phi_{n,k}\)는 가벼운 multiplicative-XOR hash로 구현된다. 최종 메모리 벡터 \(\textbf{e}_t \in \mathbb{R}^{d_\textrm{mem}}\)는 검색된 모든 임베딩을 concat하여 구성한다.
\[\begin{equation} \textbf{e}_t = \underset{n=2}{\overset{N}{\|}} \; \underset{k=1}{\overset{K}{\|}} \textbf{e}_{t,n,k} \end{equation}\]3. Context-aware Gating
검색된 임베딩 \(\textbf{e}_t\)는 컨텍스트에 독립적인 prior 역할을 한다. 하지만 정적인 특성 때문에 컨텍스트 적응성이 부족하고 해시 충돌이나 다의성으로 인한 노이즈에 취약할 수 있다. 표현력을 향상시키고 이러한 모호성을 해결하기 위해, attention 메커니즘에서 영감을 받은 context-aware gating 메커니즘을 사용한다.
구체적으로, 이전 attention layer를 통해 글로벌 컨텍스트가 집계된 현재 hidden state \(\textbf{h}_t\)를 동적 query로 활용하고, 검색된 메모리 \(\textbf{e}_t\)는 key projection과 value projection의 소스로 사용한다.
\[\begin{equation} \textbf{k}_t = \textbf{W}_K \textbf{e}_t, \quad \textbf{v}_t = \textbf{W}_V \textbf{e}_t \end{equation}\](\(\textbf{W}_K\), \(\textbf{W}_V\)는 학습 가능한 projection 행렬)
Gradient 안정성을 보장하기 위해 스칼라 게이트 \(\alpha_t \in (0, 1)\)을 계산하기 전에 query와 key에 RMSNorm을 적용한다.
\[\begin{equation} \alpha_t = \sigma \left( \frac{\textrm{RMSNorm}(\textbf{h}_t)^\top \textrm{RMSNorm}(\textbf{k}_t)}{\sqrt{d}} \right) \end{equation}\]게이팅된 출력은 \(\tilde{\textbf{v}}_t = \alpha_t \cdot \textbf{v}_t\)로 정의된다. 이 설계는 semantic 정렬을 강제한다. 검색된 메모리 $t$가 현재 컨텍스트 \(\textbf{h}_t\)와 모순되면 \(\alpha_t\)는 0에 가까워져 노이즈를 효과적으로 억제한다.
저자들은 receptive field를 확장하고 모델의 비선형성을 강화하기 위해 짧은 depthwise causal convolution을 도입하였다. 게이팅된 value들의 시퀀스를 \(\tilde{\textbf{V}} \in \mathbb{R}^{T \times d}\)로 나타내자. 그러면, 커널 크기 $w$ (4로 설정), dilation $\delta$ (최대 $𝑁$-gram order로 설정), SiLU activation을 사용하여 노이즈를 적극적으로 억제하면서 최종 출력 $\textbf{Y}$를 계산한다.
\[\begin{equation} \textbf{Y} = \textrm{SiLU} \left( \textrm{Conv1D} (\textrm{RMSNorm} (\tilde{\textbf{V}})) \right) + \tilde{\textbf{V}} \end{equation}\]Engram 모듈은 residual connection \(\textbf{H}^{(\ell)} \leftarrow \textbf{H}^{(\ell)} + \textbf{Y}\)를 통해 backbone에 통합된 후 표준 attention과 MoE가 이어진다. 중요한 점은 Engram이 모든 layer에 적용되는 것은 아니며, 구체적인 배치 위치는 시스템 수준의 지연 제약에 따라 결정된다는 것이다.
4. Integration with Multi-branch Architecture
본 논문에서는 표준적인 단일 스트림 연결 방식 대신, 우수한 모델링 기능을 갖춘 multi-branch 아키텍처를 기본 backbone으로 채택했다. 이 아키텍처의 핵심 특징은 residual 스트림이 $M$개의 병렬 branch로 확장되며, 정보 흐름은 학습 가능한 연결 가중치에 의해 조절된다는 점이다.
Engram 모듈은 본질적으로 topology에 구애받지 않지만, 이 multi-branch 프레임워크에 적용하려면 효율성과 표현력의 균형을 맞추기 위해 구조적 최적화가 필요하다. 구체적으로, 저자들은 파라미터 공유 전략을 구현하였다. 하나의 sparse 임베딩 테이블과 value projection 행렬 \(\textbf{W}_V\)는 모든 $M$개의 branch에서 공유되는 반면, $M$개의 서로 다른 key projection 행렬 \(\{\textbf{W}_K^{(m)}\}_{m=1}^M\)은 branch별 게이팅을 가능하게 하는 데 사용된다. Hidden state가 \(\textbf{h}_t^{(m)}\)인 $m$번째 branch에 대해 branch별 게이팅 신호는 다음과 같이 계산된다.
\[\begin{equation} \alpha_t^{(m)} = \sigma \left( \frac{\textrm{RMSNorm}(\textbf{h}_t^{(m)})^\top \textrm{RMSNorm}(\textbf{W}_K^{(m)} \textbf{e}_t)}{\sqrt{d}} \right) \end{equation}\]검색된 메모리는 공유 value 벡터에 적용된 이러한 독립적인 게이트에 의해 변조된다.
\[\begin{equation} \textbf{u}_t^{(m)} = \alpha_t^{(m)} \cdot (\textbf{W}_V \textbf{e}_t) \end{equation}\]이 설계는 linear projection들을 하나의 FP8 행렬 곱셈으로 통합하여 최신 GPU의 연산 활용도를 극대화한다.
5. System Efficiency: Decoupling Compute and Memory
메모리 증강 모델의 scaling은 종종 GPU HBM의 제한된 용량으로 인해 제약을 받는다. 그러나 Engram의 deterministic한 검색 메커니즘은 파라미터 저장과 연산 자원의 분리를 자연스럽게 지원한다. 동적 라우팅을 위해 런타임 hidden state에 의존하는 MoE와 달리, Engram의 검색 인덱스는 입력 토큰 시퀀스에만 의존한다. 이러한 예측 가능성은 학습과 inferece 모두에 특화된 최적화 전략을 가능하게 한다.
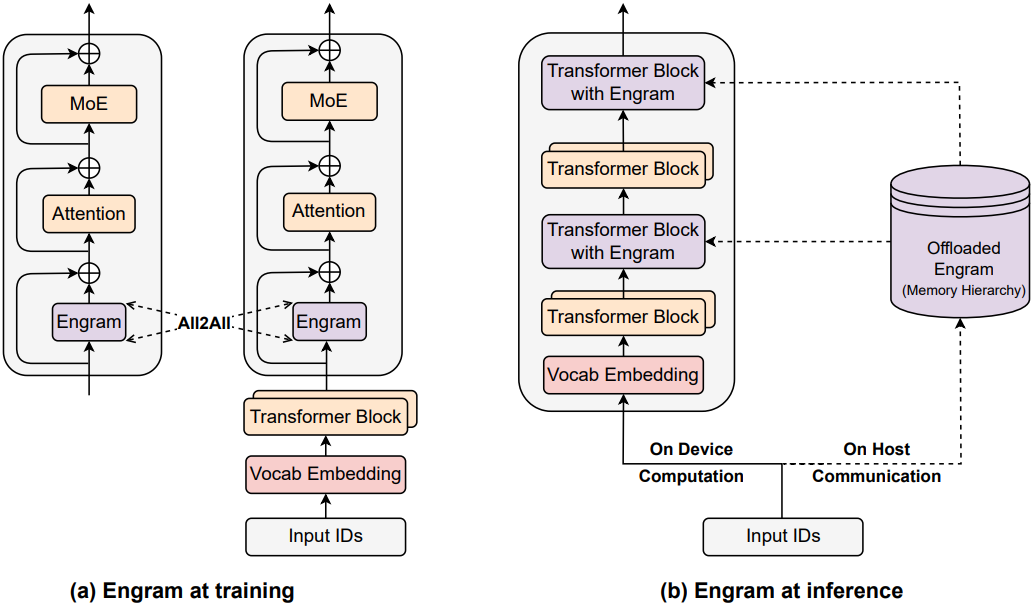
학습 과정에서 대규모 임베딩 테이블을 처리하기 위해, 사용 가능한 GPU에 테이블을 분산시켜 모델 병렬 처리를 활용한다. 모든 GPU에 대한 통신 (All-to-All) 방식을 사용하여 forward pass에서 active row를 수집하고 backward pass에서 gradient를 전달함으로써 전체 메모리 용량을 GPU 수에 비례하여 확장할 수 있다.
Inference 시에는 deterministic한 특성 덕분에 prefetch-and-overlap 전략을 사용할 수 있다. 메모리 인덱스가 forward pass 이전에 이미 결정되기 때문에, 시스템은 PCIe를 통해 상대적으로 풍부한 호스트 메모리로부터 임베딩을 비동기적으로 가져올 수 있다. 통신 지연을 효과적으로 숨기기 위해, Engram 모듈은 backbone 내의 특정 layer에 배치되며, 앞선 layer들의 연산을 버퍼처럼 활용해 GPU가 멈추는 상황을 방지한다.
이 과정은 하드웨어-알고리즘 공동 설계 전략을 필요로 한다. Engram을 깊은 layer에 배치할수록, 앞에서 수행되는 연산 시간이 길어져 메모리 지연을 숨기기에는 유리하다. 하지만, 모델링 성능 측면에서는 로컬 패턴 재구성을 Engram으로 넘겨 처리하기 위해 더 앞쪽에 배치하는 것이 더 효과적이다. 따라서 최적의 배치는 모델링 성능과 시스템 지연이라는 두 가지 제약을 동시에 만족해야 한다.
또한, 자연어 $N$-gram은 본질적으로 Zipfian distribution을 따르는데, 이는 소수의 패턴이 대부분의 메모리 접근을 담당한다는 것을 의미한다. 이러한 통계적 특성은 다단계 캐시 계층 구조를 필요로 한다. 자주 액세스되는 임베딩은 더 빠른 스토리지 계층 (ex. GPU HBM, Host DRAM)에 캐싱되고, 드물게 사용되는 패턴은 속도는 느리지만 용량이 큰 저장 매체 (ex. NVMe SSD)에 저장된다. 이러한 계층화 덕분에 Engram은 실질적인 지연에 미치는 영향을 최소화하면서 대규모 메모리 용량으로 확장할 수 있다.
Experiments
1. Scaling Laws and Sparsity Allocation
다음은 총 파라미터 수와 학습 연산량이 고정된 경우에 MoE expert와 Engram 임베딩 간의 용량 분배에 따른 성능을 비교한 결과이다. $\rho = 1$이면 순수한 MoE 모델에 해당하며, 비활성 파라미터는 모두 라우팅되는 expert로 사용된다. $\rho < 1$이면 라우팅되는 expert의 수를 줄이고, 그만큼 남는 파라미터를 Engram 임베딩 슬롯으로 재할당된다.
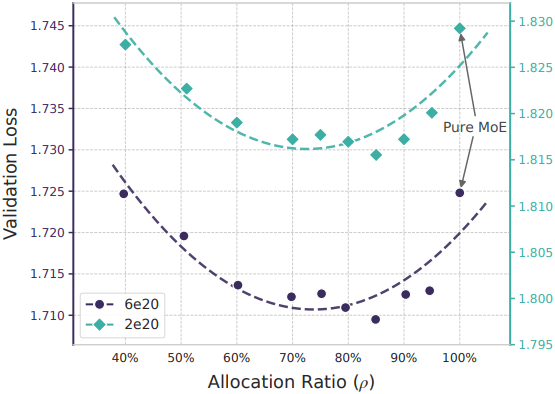
다음은 학습 연산량에 제한이 없을 때 Engram 임베딩 슬롯 수에 따른 성능을 비교한 결과이다.
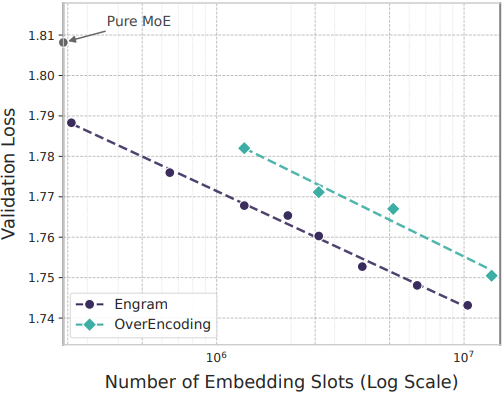
2. Large Scale Pre-training
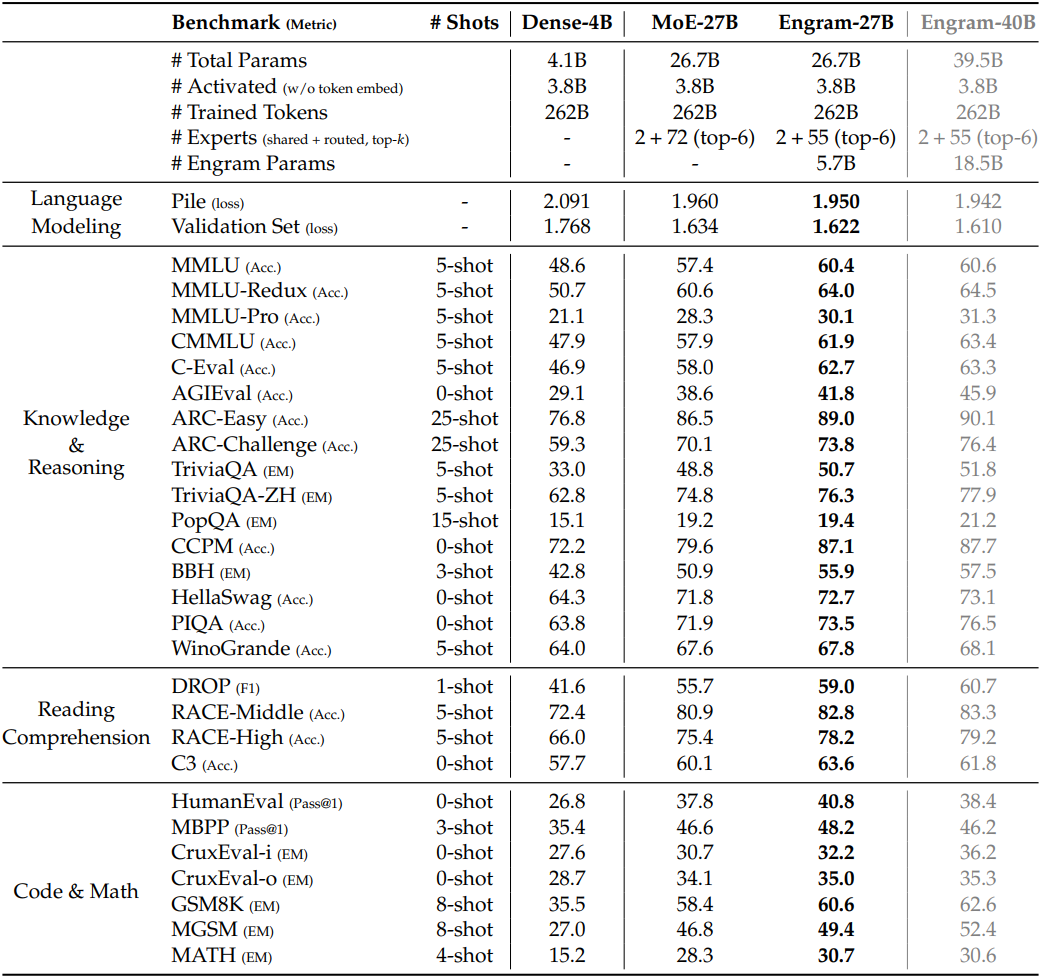
다음은 allocation law에 따라 scaling한 Engram의 성능을 비교한 결과이다. (동일한 학습 토큰 수, 동일한 활성 파라미터 수)
3. Long Context Training
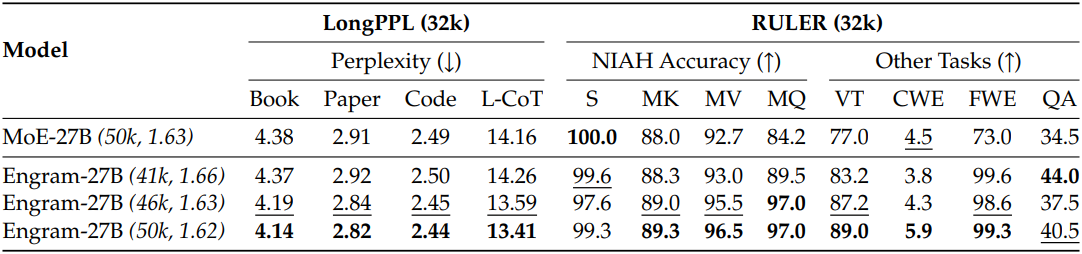
다음은 긴 컨텍스트에 대한 성능을 비교한 결과이다.
4. Analysis
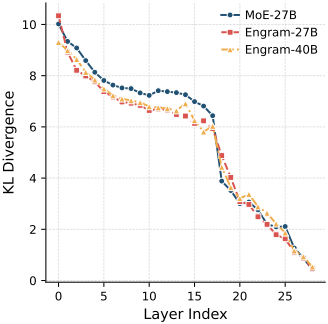
다음은 MoE와 layer-wise KL divergence를 비교한 결과이다. 초기 단계에서 Engram의 KL divergence가 낮은 것은 Engram이 예측 수렴을 가속화한다는 것을 의미한다.
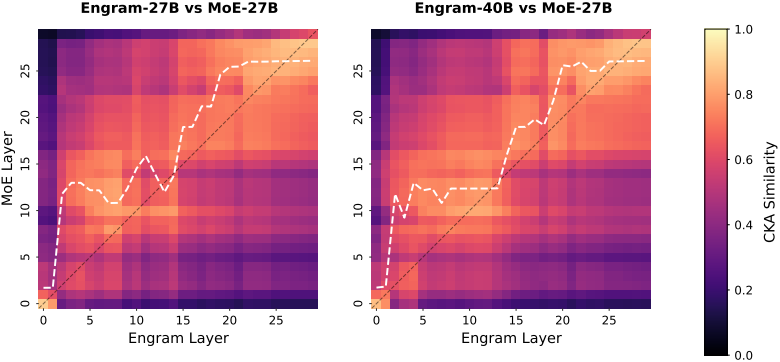
다음은 CKA (Centered Kernel Alignmen)로 MoE와의 유사도 히트맵을 얻은 결과이다. 높은 유사성을 나타내는 대각선의 뚜렷한 상향 이동은 Engram의 얕은 layer가 MoE 모델의 더 깊은 layer와 기능적으로 동일하며, 결과적으로 Engram이 모델의 깊이를 효과적으로 증가시킨다는 것을 보여준다.
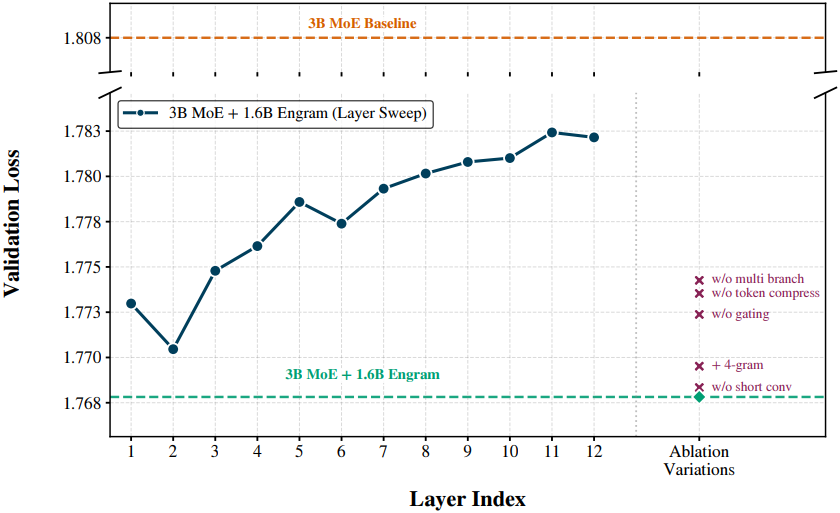
다음은 아키텍처에 ablation 결과이다. Layer Sweep은 Engram 모듈 1개를 적용한 layer에 따른 성능을 나타낸다.
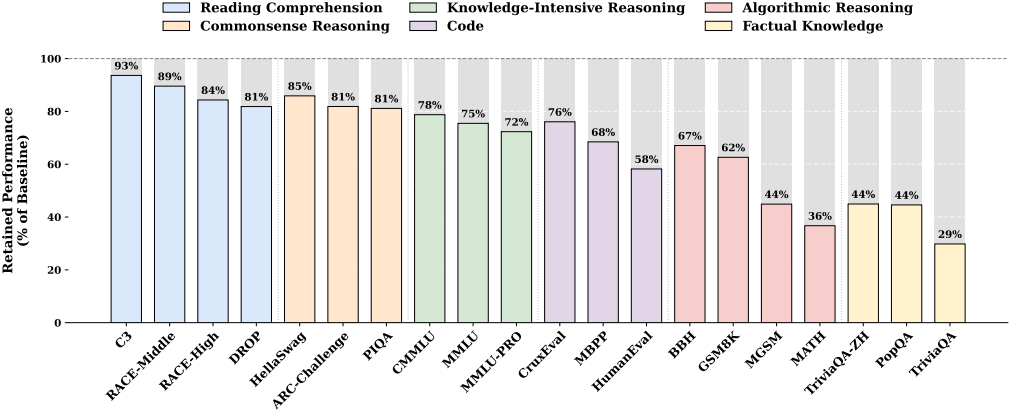
다음은 Engram을 제거한 상태에서 유지되는 성능을 비교한 결과이다. 사실적 지식은 Engram 모듈에 크게 의존하는 반면, 독해 능력은 주로 backbone에 의해 유지된다.
다음은 end-to-end inferece 처리량을 비교한 결과이다.