[논문리뷰] EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
INTERSPEECH 2023. [Paper]
Haobin Tang, Xulong Zhang, Jianzong Wang, Ning Cheng, Jing Xiao
Ping An Technology Co. | University of Science and Technology of China
1 Jun 2023
Introduction
seq2seq 모델링 아키텍처가 계속해서 빠르게 발전함에 따라 레퍼런스 기반 style transfer는 감정적인 음성 합성에 효과적인 방법이다. 최근 연구들은 “이렇게 말하라”라는 원칙을 따르고 Global Style Token (GST)과 같은 다양한 접근 방식과 업데이트를 탐구했다. 음소 및 분절 수준의 운율 임베딩은 Generspeech에서 사용되어 다양한 음계에 걸쳐 광범위한 감정 변화를 포착한다. 좀 더 복잡하지 않은 운율 임베딩을 모델링하기 위해 일부 연구에서는 음성 감정 인식 (SER) 또는 자동 음성 인식 (ASR) 모델의 특정 레이어에서 추출된 중간 임베딩을 심층 감정 feature로 사용한다. 감정 표현 측면에서 유망한 결과가 달성되었지만 강도 제어 가능한 감정 TTS는 여전히 어려운 과제이다. 스케일링, 보간, 거리 기반 양자화와 같은 내부 감정 표현을 조작하기 위해 다양한 방법이 제안되었다. 감정 TTS와 감정 음성 변환 (EVC)에서 상대적 속성의 도입을 제안하여 보다 적절하게 정의되고 계산된 감정 강도 값을 개발했다.
그러나 이전 방법은 주로 제한된 수의 감정 유형을 합성하는 데 집중했다. 서로 다른 감정 사이의 상관관계와 상호작용을 탐구한 프레임워크는 거의 없다. 인간은 약 34,000개의 뚜렷한 감정과 여러 감정 상태를 동시에 경험할 수 있다. 이 문제를 해결하기 위해 Plutchik은 슬픔, 혐오, 기쁨, 두려움, 분노, 기대, 놀라움, 신뢰라는 8가지 기본 감정을 제안했다. 다른 모든 감정은 파생된 형태 또는 이러한 기본 감정의 혼합으로 간주될 수 있다. 예를 들어, ‘Happy’와 ‘Surprise’의 혼합은 ‘Excitement’로 간주될 수 있다. 대규모 혼합 감정 데이터셋을 구축하면 실제 적용에 많은 비용이 든다. 레퍼런스 기반 style transfer는 혼합 감정 합성을 위한 솔루션일 수 있지만 적절한 혼합 감정 레퍼런스 오디오 세트를 얻기도 어렵다.
MixedEmotion은 처음으로 TTS에서 혼합된 감정의 모델링을 연구하였다. MixedEmotion은 감정 임베딩에 가중치를 부여하기 위해 상대적인 속성 순위에서 강도 값을 얻는다. 여러 감정의 원하는 혼합은 감정 속성 벡터를 수동으로 정의하여 달성된다. 그러나 이로 인해 눈에 띄는 품질 저하가 발생한다. EmoDiff는 제어 가능하고 혼합된 감정을 합성하기 위해 DDPM의 classifier guidance를 기반으로 하는 soft-label guidance 기술을 사용한다. 그러나 이 classifier는 noise가 추가된 오디오에 대해 학습되어야 하며 고차원 및 학습 중에 보지 못한 기본 감정 조절에는 비효율적이다.
본 논문에서는 DDPM과 사전 학습된 음성 감정 인식 (SER) 모델을 적용한 감정적인 speech style transfer 프레임워크인 EmoMix를 소개한다. 기본 감정 생성을 위한 diffusion model의 reverse process를 위해 SER 모델에서 추출한 감정 임베딩을 추가 조건으로 사용한다. 또한 강도 제어 및 혼합 감정 문제를 극복하기 위해 이미지 semantic 혼합 task에서 혼합 방법을 도입하여 혼합 감정을 직접 모델링하지 않는다. 구체적으로, 서로 다른 감정 조건을 기반으로 DDPM 모델에 의해 예측된 noise를 결합하여 런타임에 단 한 번의 샘플링 프로세스를 통해 혼합된 감정을 합성한다. 강도는 Neutral과 특정 감정 조합을 통해 추가로 제어된다.
EmoMix
1. Preliminary on Score-based Diffusion Model
DDPM은 최근 이미지 및 오디오 생성 task에서 뛰어난 성능을 달성했다. 본 논문은 확률적 미분 방정식 (SDE) 공식을 TTS에 적용한 GradTTS의 디자인을 기반으로 음성 합성에서 감정 혼합을 위한 새로운 방법인 EmoMix를 제안한다. GradTTS는 다음과 같이 모든 데이터 분포 $X_0$를 표준 정규 분포 $X_T$로 변환할 수 있는 diffusion process를 정의한다.
\[\begin{equation} dX_t = - \frac{1}{2} X_t \beta_t dt + \sqrt{\beta_t} dW_t, \quad t \in [0, T] \end{equation}\]여기서 $\beta_t$는 미리 정의된 noise schedule이고 $W_t$는 Wiener process이다. Diffusion process의 역궤도를 따르는 reverse process를 SDE로 공식화할 수 있다.
\[\begin{equation} dX_t = \bigg( - \frac{1}{2} X_t - \nabla_{X_t} \log p_t (X_t) \bigg) \beta_t dt + \sqrt{\beta_t} d \tilde{W_t} \end{equation}\]GradTTS는 표준 Gaussian noise $X_T$에서 데이터 $X_0$를 생성하기 위해 샘플링 중에 reverse SDE의 discretize된 버전인 다음 방정식을 사용한다.
\[\begin{equation} X_{t - \frac{1}{N}} = X_t + \frac{\beta_t}{N} \bigg( \frac{1}{2} X_t + \nabla_{X_t} \log p_t (X_t) \bigg) + \sqrt{\frac{\beta_t}{N}} z_t \end{equation}\]여기서 $N$은 discretize된 reverse process의 step 수이고 $z_t$는 표준 Gaussian noise이다. GradTTS가 $T$를 1로 설정했으므로 한 step의 크기는 $\frac{1}{N}$이고 \(t \in \{ \frac{1}{N}, \frac{2}{N}, \cdots, 1 \}\)이다.
데이터 $X_0$가 주어지면 score $\nabla_{X_t} \log p_t (X_t)$를 추정하기 위해 다음과 같이 $X_t$를 샘플링한다.
\[\begin{equation} X_t \;\vert\; X_0 \sim \mathcal{N} (\rho (X_0, t), \lambda (t)) \\ \rho (X_0, t) = X_0 \exp \bigg( - \frac{1}{2} \int_0^t \beta_s ds \bigg) \\ \lambda (t) = I - \exp \bigg( - \int_0^t \beta_s ds \bigg) \end{equation}\]주어진 $X_0$에서 $X_t$를 샘플링하기 위한 표준 Gaussian noise를 $\epsilon_t$라고 하면, score는 다음과 같다.
\[\begin{equation} \nabla_{X_t} \log p_t (X_t \vert X_0) = -\lambda (t)^{-1} \epsilon_t \end{equation}\]Score를 추정하기 위해 모든 $t \in [0, T]$에서 $\epsilon_\theta (X_t, t, \mu, s, e)$가 학습된다. 여기서 $\mu$는 화자 $s$와 감정 $e$에 따라 달라지는 음소에 의존하는 가우시안 평균이다. 항상 텍스트와 화자가 조건으로 필요하며 감정에 중점을 둔다. 따라서 $\epsilon_\theta (X_t, t, \mu, s, e)$의 $\mu$와 $s$는 생략되고 네트워크는 단순화된 표기법 $\epsilon_\theta (X_t, t, e)$로 표현된다. 다음 loss가 사용된다.
\[\begin{equation} \mathcal{L}_\textrm{diff} = \mathbb{E}_{x_0, t, e, \epsilon_t} [\lambda_t \| \epsilon_\theta (x_t, t, e) + \lambda (t)^{-1} \epsilon_t \|_2^2] \end{equation}\]2. Emotion Conditioning with SER
이전 연구는 단일 화자 감정 TTS만 고려하고 classifier의 로그 확률 기울기를 사용하여 제한된 수의 discrete한 감정 카테고리로 reverse process를 가이드한다. DeepEST에서 영감을 받아, 원하는 감정에 대한 모델을 컨디셔닝하기 위해 타겟 감정 운율을 예시하는 레퍼런스 음성에서 $e$를 포함하는 지속적인 감정을 생성하는 사전 학습된 SER 모델을 활용한다.
처음에 3D CNN 레이어는 mel-spectrogram과 그 파생물을 입력으로 사용하고 관련 없는 요소를 필터링하면서 감정 콘텐츠를 인코딩하는 latent 표현을 추출한다. 그런 다음 BLSTM과 attention layer는 감정 분류를 위한 음성 레벨 feature를 나타내는 감정 임베딩 $e$를 생성한다. 화자 컨디셔닝을 위해 Generspeech에서 wav2vec 2.0 모델을 사용하여 화자 음향 조건을 캡처한다.
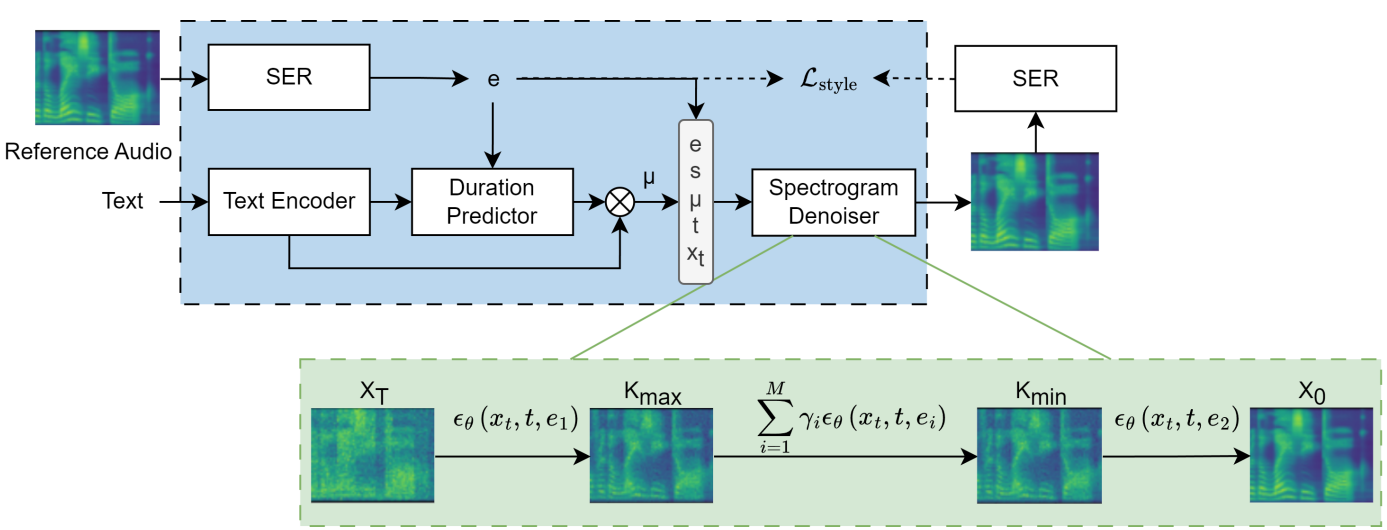
위 그림에서 볼 수 있듯이 EmoMix는 GradTTS를 기반으로 한다. 단, 예상 duration은 감정과 화자에 따라 결정된다. Hidden 표현 $\mu$는 입력 텍스트, 감정 임베딩 $e$, 화자 임베딩 $s$의 언어 내용을 반영한다. 결과적으로 spectrogram denoiser는 $\mu$를 기준 오디오의 주요 감정 및 화자를 타겟으로 mel-spectrogram으로 반복적으로 정제한다.
레퍼런스 음성과 합성된 음성 사이의 감정 스타일 차이를 더욱 최소화하기 위해 denoiser와 함께 다른 SER을 사용한다. 그람 행렬 (gram matrix)을 이용한 style loss는 컴퓨터 비전에서 널리 사용되는 기술이며 최근 mel-spectrogram과 감정 임베딩 측정에 적용되었다. 저자들은 합성 음성에서 레퍼런스 오디오의 감정 운율을 유지하기 위해 style reconstruction loss를 제안하였다.
\[\begin{equation} \mathcal{L}_\textrm{style} = \sum_j \| G_j (\hat{m}) - G_j (m) \|_F^2 \end{equation}\]여기서 $G_j (x)$는 입력 $x$에 대한 SER 모델의 3D CNN의 $j$번째 레이어 feature map의 그람 행렬이다. $m$과 $\hat{m}$은 각각 레퍼런스 mel-spectrogram과 합성된 mel-spectrogram을 나타낸다. 이 style reconstruction loss는 합성된 음성이 레퍼런스 오디오와 유사한 스타일을 갖도록 강제한다. 최종 목적 함수는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{dur} + \mathcal{L}_\textrm{diff} + \mathcal{L}_\textrm{prior} + \gamma \mathcal{L}_\textrm{style} \end{equation}\]여기서 \(\mathcal{L}_\textrm{dur}\)는 로그 스케일 duration의 $\ell_2$ loss고 \(\mathcal{L}_\textrm{diff}\)는 diffusion loss이다. $\gamma$는 hyperparamter이며 경험적으로 $10^{-4}$로 설정된다. 또한 수렴을 장려하기 위해 GradTTS에서 prior loss \(\mathcal{L}_\textrm{prior}\)를 채택한다.
3. Run-time Emotion Mixing
런타임에 혼합된 감정 또는 다양한 강도의 단일 기본 감정을 가진 음성을 합성하는 것이 목표이다. 원래 단일 기본 감정으로 컨디셔닝된 학습된 DDPM의 reverse process를 확장하여 혼합 감정을 합성한다. 혼합 방법은 layout semantics를 유지하면서 이미지에서 주어진 객체의 특정 부분의 콘텐츠를 수정하는 것을 목표로 하는 semantic mixing task를 해결하기 위해 처음 사용되었다. DDPM의 샘플링 절차는 대략적인 feature를 먼저 생성하고 디테일이 마지막에 나타나는 것으로 여겨진다.
EmoMix는 기본 감정 디테일을 혼합된 감정으로 덮어쓸 목적으로 inference 중에 샘플링 step $K_\textrm{max}$ 후 조건 벡터를 대체하여 두 가지 다른 감정의 감정 혼합을 가능하게 한다. 단일 레퍼런스 오디오의 불안정성을 피하기 위해 동일한 기본 감정을 가진 오디오 샘플 세트의 감정 임베딩을 평균화한다. 먼저 기본 감정 조건 $e_1$ (ex. Happy)이 주어진 Gaussian noise에서 중간 step $K_\textrm{max}$까지 denoise하여 대략적인 기본 감정 운율을 합성한 다음 $K_\textrm{min}$에서 감정 $e_2$ (ex. Surprise)가 혼합된 조건에서 denoise하여 혼합된 감정 (ex. Excitement)을 얻는다. Timestep $K_\textrm{max}$에서 $K_\textrm{min}$까지 noise 결합 접근 방식을 적용하여 주어진 기본 감정의 요소를 더 잘 보존하고 혼합된 감정에 의해 너무 쉽게 덮어쓰이는 것을 방지한다. 여러 감정 조건에서 예측된 noise를 결합하여 단 하나의 샘플링 프로세스를 통해 여러 감정 스타일을 합성한다. 특히 다음 규칙에 따라 여러 noise를 결합한다.
\[\begin{equation} \epsilon_\theta (x_t, t, e_\textrm{mix}) = \sum_{i=1}^M \gamma_i \epsilon_\theta (x_t, t, e_i) \end{equation}\]여기서 $\gamma_i$는 $\sum_{i=1}^M \gamma_i = 1$을 만족하는 각 조건 $e_i$의 가중치로, 각 감정의 정도를 조절하는 데 사용할 수 있다. $M$은 혼합된 감정 카테고리의 수이며 이중 감정 혼합을 위해 2로 설정된다. 따라서 EmoMix는 직접 모델링한 혼합 감정 조건을 타겟으로 새 모델을 학습할 필요 없이 다양한 조합으로 감정을 유연하게 혼합할 수 있다. 이 샘플링 프로세스는 다음 조건부 분포의 결합 확률을 증가시키는 것으로 해석할 수 있다.
\[\begin{equation} \sum_{i=1}^M \gamma_i \epsilon_\theta (x_t, t, e_i) \propto - \nabla_{x_t} \log \prod_{i=1}^M p (x_t \;\vert\; e_{\textrm{tar}, i})^{\gamma_i} \end{equation}\]여기서 \(e_{\textrm{tar}, i}\)는 타겟 감정 조건이다.
감정 강도 제어를 위해 Neutral과 기본 감정을 직관적으로 혼합한다. Neutral 조건의 noise와 기본 감정을 다양한 $\gamma$로 혼합하여 Neutral과 타겟 감정 사이를 부드럽게 보간하여 기본 감정 강도를 제어할 수 있다.
Experiment
- 데이터셋
- SER 모델은 IEMOCAP에서 학습
- IEMOCAP은 5가지 감정 종류를 가짐: Sad, Surprise, Happy, Neutral, Angry
- ESD 데이터셋의 영어 부분을 사용하며 IEMOCAP과 동일한 5가지 감정으로 실험을 진행
- 구현 디테일
- $\epsilon_\theta$는 U-Net과 선형 attention 모듈로 구성 (GradTTS와 동일)
- Batch size: 32
- Optimizer: Adam
- Learning rate = $10^{-4}$, 100만 step
- Montreal Forced Aligner (MFA)로 음성과 텍스트를 정렬
- HifiGAN을 vocoder로 사용
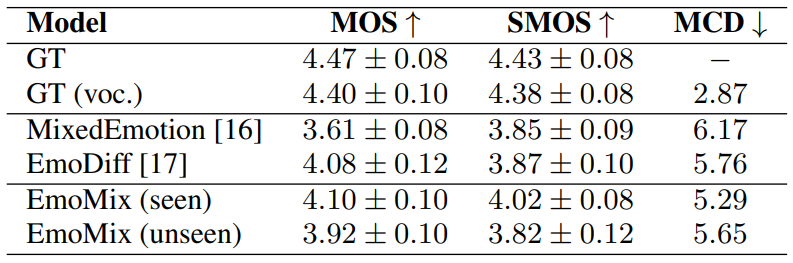
1. Evaluation of Emotional Speech
다음은 단일 기본 감정 합성 결과이다.
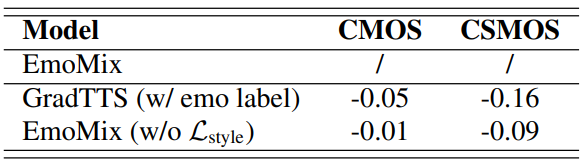
2. Ablation Study
다음은 ablation study를 위한 CMOS와 CSMOS 비교 결과이다.
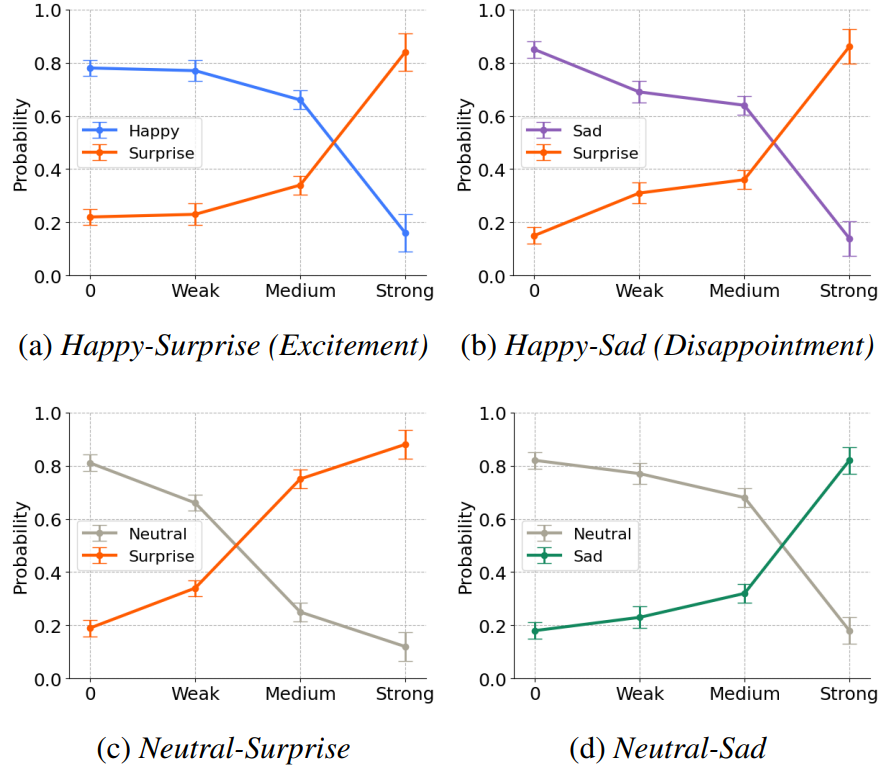
3. Evaluation of Mixed Emotion
다음은 사전 학습된 SER 모델에서 얻은 분류 확률이다.
다음은 혼합된 감정에 대한 CMOS 비교 결과이다.

다음은 혼합된 감정에 대한 confusion matrix들이다.
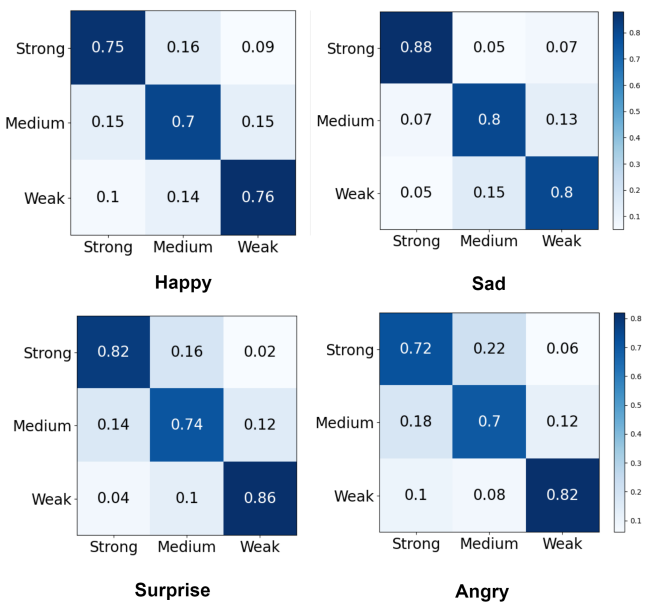
생성된 샘플이 원하는 강도를 정확하게 반영한다는 것을 명확하게 보여주며, 이를 통해 기본 감정 강도를 제어하는 데 있어 EmoMix의 효과를 확인할 수 있다.