[논문리뷰] EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
arXiv 2024. [Paper] [Page]
Linrui Tian, Qi Wang, Bang Zhang, Liefeng Bo
Alibaba Group
27 Feb 2024
Introduction
최근 몇 년 동안 이미지 생성 분야는 주로 diffusion model의 성공에 힘입어 놀라운 발전을 이루었다. Diffusion model은 대규모 이미지 데이터셋에 대한 광범위한 학습과 점진적인 생성 접근 방식을 통해 그 탁월함을 발휘한다. 이 혁신적인 방법론을 통해 놀라운 디테일과 현실감을 갖춘 이미지를 생성할 수 있다. Diffusion model의 적용은 정지된 이미지에만 국한되지 않는다. 동영상 생성에 대한 관심이 급증하면서 역동적이고 설득력 있는 동영상을 제작하는 데 있어 이러한 모델의 잠재력을 탐구하게 되었다. 이러한 선구적인 노력은 동영상 생성 분야에서 diffusion model의 엄청난 잠재력을 강조한다.
일반적인 동영상 합성을 넘어 talking head 등 인간 중심의 동영상 생성이 연구의 초점이 되어왔다. Talking head의 목적은 사용자가 제공한 오디오 클립에서 표정을 생성하는 것이다. 이러한 표정을 만드는 데는 인간 얼굴 움직임의 미묘함과 다양성을 포착하는 task가 포함되며, 이는 동영상 합성에 있어서 중요한 과제이다. 기존 접근 방식에서는 이 task를 단순화하기 위해 최종 동영상 출력에 제약을 가하는 경우가 많다. 예를 들어, 일부 방법은 3D 모델을 사용하여 얼굴 키포인트를 제한하며, 다른 방법은 기본 동영상에서 머리 움직임 시퀀스를 추출하여 전체 동작을 가이드한다. 이러한 제약으로 인해 동영상 생성의 복잡성이 줄어들지만 결과로 나오는 얼굴 표정의 풍부함과 자연스러움도 제한되는 경향이 있다.
본 논문의 목표는 미세한 표정을 포함하여 광범위한 사실적인 표정을 포착하고 자연스러운 머리 움직임을 촉진하여 놀라운 수준의 표현력을 부여하도록 설계된 혁신적인 talking head 프레임워크를 구축하는 것이다. 이 목표를 위해 본 논문은 주어진 이미지와 오디오 클립에서 머리 동영상을 직접 합성할 수 있는 diffusion model의 생성 능력을 활용하는 방법을 제안하였다. 이 접근 방식을 사용하면 중간 표현이나 복잡한 전처리가 필요하지 않으며 오디오 입력에 존재하는 뉘앙스와 밀접하게 일치하는 높은 수준의 시각적, 감정적 충실도를 보여주는 talking head 동영상 생성을 간소화한다. 오디오 신호에는 얼굴 표정과 관련된 정보가 풍부하므로 이론적으로 모델이 표정이 풍부한 다양한 얼굴 움직임을 생성할 수 있다.
그러나 오디오와 표정 간의 매핑에 내재된 모호성으로 인해 오디오를 diffusion model과 통합하는 것은 간단한 작업이 아니다. 이 문제로 인해 모델이 제작한 영상이 불안정해지며 얼굴 왜곡이나 영상 프레임 간 떨림 현상이 나타날 수 있으며 심한 경우 영상이 완전히 붕괴되는 경우도 있다. 저자들은 이러한 문제를 해결하기 위해 속도 컨트롤러와 얼굴 영역 컨트롤러라는 안정적인 제어 메커니즘을 모델에 통합하여 생성 프로세스 중 안정성을 향상시켰다. 이 두 컨트롤러는 hyperparameter 역할을 하며 최종 생성된 동영상의 다양성과 표현력을 손상시키지 않는 미묘한 제어 신호 역할을 한다. 또한 생성된 동영상의 캐릭터가 입력 레퍼런스 이미지와 일관되게 유지되도록 하기 위해 동영상 전체에서 캐릭터의 정체성을 보존하는 것을 목표로 하는 ReferenceNet과 유사한 모듈인 FrameEncoding을 설계하여 ReferenceNet의 접근 방식을 채택하고 향상시켰다.
마지막으로, 모델을 학습시키기 위해 저자들은 250시간이 넘는 동영상과 1억 5천만 개 이상의 이미지를 수집하는 방대하고 다양한 오디오-동영상 데이터셋을 구축했다. 이 광대한 데이터셋은 연설, 영화, TV 클립, 노래 공연 등 광범위한 콘텐츠를 포괄하며 중국어, 영어 등 여러 언어를 다루고 있다. 다양한 말하기 및 노래하는 영상을 통해 학습 데이터셋은 인간의 표현과 보컬 스타일의 광범위한 스펙트럼을 포착하여 EMO 개발을 위한 견고한 기반을 제공한다. EMO는 매우 자연스럽고 표현력이 풍부한 대화 및 노래하는 영상까지 생성할 수 있어 현재까지 최고의 결과를 달성할 수 있는 것으로 나타났다.
Method
캐릭터 초상화의 레퍼런스 이미지 1개가 주어지면 EMO는 입력 음성 오디오 클립과 동기화된 동영상을 생성하여 제공된 음성 오디오의 톤 변화와 조화를 이루면서 자연스러운 머리 움직임과 생생한 표현을 보존할 수 있다. EMO는 일련의 연속된 동영상을 생성함으로써 일관된 신원과 일관된 동작을 갖춘 길이가 긴 말하는 인물 동영상의 생성을 촉진한다.
1. Network Pipelines
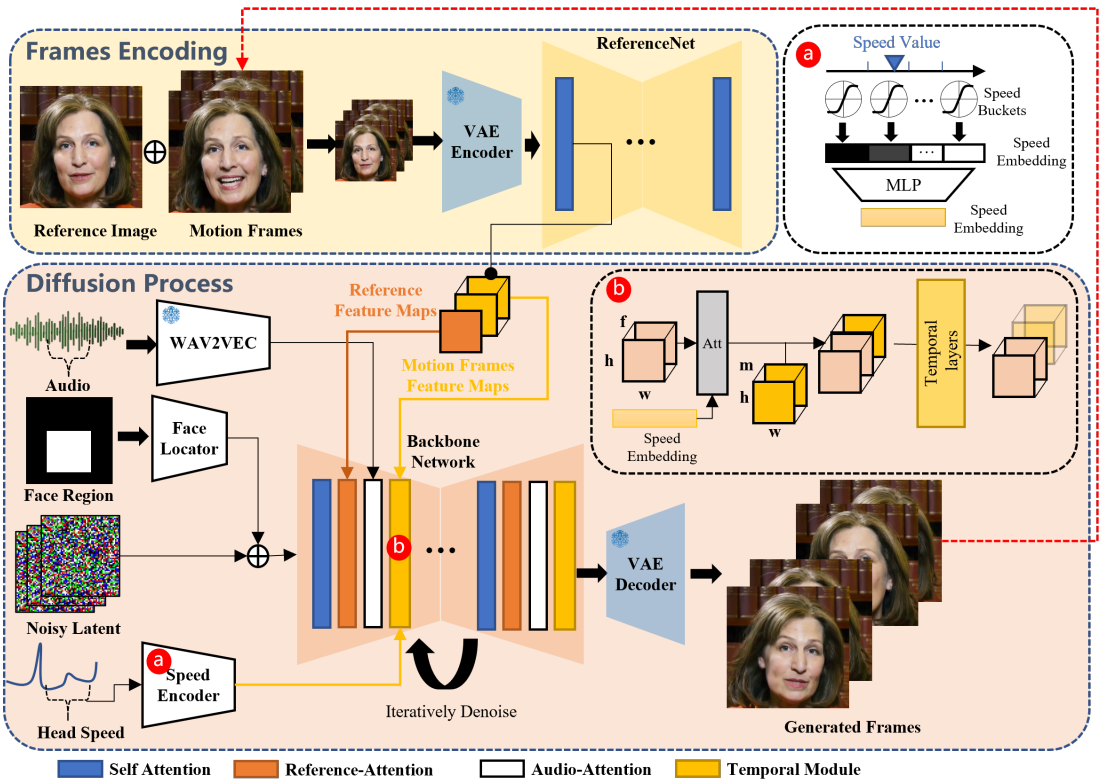
Backbone Network는 여러 프레임의 noisy latent 입력을 입력받아 각 timestep 동안 연속적인 동영상 프레임으로 이를 denoising하려고 시도한다. Backbone Network는 Stable Diffusion (SD) 1.5와 유사한 UNet 구조 구성을 갖는다.
- 생성된 프레임 간의 연속성을 보장하기 위해 Backbone Network에는 temporal module이 내장되어 있다.
- 생성된 프레임에서 초상화의 신원(ID) 일관성을 유지하기 위해 ReferenceNet이라는 UNet 구조를 Backbone과 병렬로 적용하고 레퍼런스 이미지를 입력하여 레퍼런스 feature를 얻는다.
- 캐릭터의 말하는 움직임을 구동하기 위해 오디오 레이어를 활용하여 음성 feature를 인코딩한다.
- 말하는 캐릭터의 동작을 제어 가능하고 안정적으로 만들기 위해 얼굴 탐지기와 속도 레이어를 사용하여 약한 조건을 제공한다.
Backbone Network
본 논문에서는 프롬프트 임베딩이 활용되지 않는다. 따라서 SD 1.5 UNet 구조의 cross-attention layer를 reference-attention layer에 적용했다. 수정된 레이어는 텍스트 임베딩이 아닌 ReferenceNet의 레퍼런스 feature를 입력으로 사용한다.
Audio Layers
목소리의 발음과 톤은 생성된 캐릭터의 움직임을 나타내는 주요 신호이다. 사전 학습된 wav2vec의 여러 블록에 의해 입력 오디오 시퀀스에서 추출된 feature들은 concatenate되어 $f$번째 프레임에 대한 오디오 표현 임베딩 $A^{(f)}$를 생성한. 그러나 모션은 미래/과거 오디오 세그먼트의 영향을 받을 수 있다. 이를 해결하기 위해 근처 프레임의 feature를 연결하여 생성된 각 프레임의 음성 feature를 정의한다.
\[\begin{equation} A_\textrm{gen}^{(f)} = \oplus \{ A^{(f−m)}, \ldots, A^{(f)}, \ldots, A^{(f+ m)}\} \end{equation}\]여기서 $m$은 한쪽으로의 추가 feature 수이다. 생성 프로세스에 음성 feature를 주입하기 위해 Backbone Network의 각 ref-attention 레이어 뒤에 latent code와 $A_\textrm{gen}$ 간의 cross-attention 메커니즘을 수행하는 audio-attention 레이어를 추가한다.
ReferenceNet
ReferenceNet은 Backbone Network와 동일한 구조를 가지며, 입력 이미지에서 세부적인 feature를 추출하는 역할을 한다. ReferenceNet과 Backbone Network가 모두 동일한 원본 SD 1.5 UNet 아키텍처에서 유래했다는 점을 고려하면 특정 레이어에서 이 두 구조에 의해 생성된 feature map은 유사성을 나타낼 가능성이 높다. 결과적으로 이는 ReferenceNet에서 추출된 feature의 Backbone Network 통합을 용이하게 한다. 대상 개체의 신원 일관성을 유지하는 데 있어 유사한 구조를 활용하는 것이 큰 영향을 미친다. ReferenceNet과 Backbone Network는 모두 원래 SD UNet의 가중치를 상속받는다. 대상 캐릭터의 이미지는 ReferenceNet에 입력되어 self-attention 레이어의 레퍼런스 feature map 출력을 추출한다. Backbone denoising 과정에서 해당 레이어의 feature는 추출된 feature map과 함께 reference-attention 레이어를 거친다. ReferenceNet은 주로 개별 이미지를 처리하도록 설계되었으므로 Backbone에 있는 temporal layer가 부족하다.
Temporal Modules
대부분의 연구들에서는 연속된 동영상 프레임 간의 시간적 관계를 쉽게 이해하고 인코딩하기 위해 사전 학습된 text-to-image 아키텍처에 temporal mixing layer를 삽입하려고 하였다. 이를 통해 향상된 모델은 프레임 전반에 걸쳐 연속성과 일관성을 유지할 수 있어 부드럽고 일관된 동영상 스트림이 생성된다. AnimateDiff의 아키텍처를 바탕으로 프레임 내의 feature에 self-attention temporal layer를 적용한다. 구체적으로 입력 feature map $x \in \mathbb{R}^{b \times c \times f \times h \times w}$를 $(b \times h \times w) \times f \times c$ 모양으로 재구성한다. 여기서 $b$는 batch size, $h$와 $w$는 feature map의 공간 차원, $f$는 생성된 프레임 수, $c$는 feature 차원이다. 특히, 동영상의 동적 콘텐츠를 효과적으로 캡처하기 위해 시간적 차원 $f$에 걸쳐 self-attention을 한다. Temporal layer는 Backbone Network의 각 해상도 계층에 삽입된다.
대부분의 최신 diffusion 기반 동영상 생성 모델은 미리 결정된 수의 프레임을 생성하도록 설계되어 본질적으로 제한되어 있으므로 확장된 동영상 시퀀스 생성이 제한된다. 이러한 제한은 의미 있는 말하기를 표현하기 위해 충분한 길이가 필수적인 talking head 동영상에 특히 영향을 미친다. 일부 방법론에서는 이전 클립 끝의 프레임을 후속 생성의 초기 프레임으로 사용하여 연결된 세그먼트 전체에서 원활한 전환을 유지하는 것을 목표로 한다. 이에 영감을 받아 클립 간 일관성을 향상시키기 위해 이전에 생성된 클립에서 ‘모션 프레임’이라고 하는 마지막 $n$개 프레임을 통합한다. 특히 이러한 $n$개의 모션 프레임은 다중 해상도 모션 feature map을 사전 추출하기 위해 ReferenceNet에 공급된다. Backbone Network 내의 denoising process 동안 프레임 차원을 따라 temporal layer 입력을 일치하는 해상도의 사전 추출된 모션 feature와 병합한다. 이 간단한 방법은 다양한 클립 간의 일관성을 효과적으로 보장한다. 첫 번째 동영상 클립 생성을 위해 모션 프레임을 zero map으로 초기화한다.
Backbone Network는 noisy한 프레임을 denoising하기 위해 여러 번 반복될 수 있지만 대상 이미지와 모션 프레임은 concatenate되어 ReferenceNet에 한 번만 입력된다. 결과적으로 추출된 feature는 프로세스 전반에 걸쳐 재사용되므로 inference 중에 계산 시간이 크게 증가하지 않는다.
Face Locator and Speed Layers
Temporal module은 생성된 프레임의 연속성과 동영상 클립 간의 원활한 전환을 보장할 수 있지만, 독립적인 생성 프로세스로 인해 클립 전반에 걸쳐 생성된 캐릭터 모션의 일관성과 안정성을 보장하기에는 부족하다. 이전 연구들에서는 일부 신호를 사용하여 캐릭터 동작을 제어하였다. 이러한 제어 신호를 사용하는 경우 자유도가 제한되어 생동감 넘치는 표정과 동작을 생성하는 데 좋지 않을 수 있으며, 학습 단계의 부적절한 라벨링은 얼굴 역학 전체를 포착하기에는 부족하다. 또한 동일한 제어 신호로 인해 서로 다른 캐릭터 간에 불일치가 발생하여 개별 뉘앙스를 설명하지 못할 수 있다. 제어 신호 생성을 활성화하는 것은 실행 가능한 접근 방식일 수 있지만 실제와 같은 모션을 생성하는 것은 여전히 어려운 과제이다. 따라서 저자들은 “약한” 제어 신호 접근 방식을 선택하였다.
구체적으로, 동영상 클립의 얼굴 bounding box 영역을 포함하는 마스크 $M = \bigcup_{i=0}^f M^i$를 얼굴 영역으로 활용한다. Bounding box 마스크를 인코딩하도록 설계된 가벼운 convolution layer로 구성된 Face Locator를 사용한다. 그 결과 인코딩된 마스크는 Backbone에 공급되기 전에 noisy한 latent 표현에 더해진다. 이러한 방식으로 마스크를 사용하여 캐릭터 얼굴이 생성되어야 하는 위치를 제어할 수 있다.
그러나 별도의 생성 프로세스 중 머리 모션 주파수의 변화로 인해 클립 간에 일관되고 부드러운 모션을 생성하는 것은 어렵다. 이 문제를 해결하기 위해 목표 머리 모션 속도를 생성에 통합한다. 보다 정확하게는 프레임 $f$의 머리 회전 속도 $w^f$를 고려하고 속도 범위를 각각 다른 속도 수준을 나타내는 $d$개의 discrete한 속도 버킷으로 나눈다. 각 버킷에는 중심 값 $c^d$와 반지름 $r^d$가 있다. $w^f$를 벡터 \(S = \{s^d\} \in \mathbb{R}^d\)로 다시 지정한다.
\[\begin{equation} s^d = \textrm{tanh}(\frac{3 (w^f - c^d)}{r^d}) \end{equation}\]오디오 레이어에서 사용된 방법과 유사하게 각 프레임에 대한 머리 회전 속도 임베딩은
\[\begin{equation} S^f = \oplus \{S^{(f−m)}, \ldots, S^{(f)}, \ldots, S^{(f+m)}\} \in \mathbb{R}^{b \times f \times c^\textrm{speed}} \end{equation}\]로 주어지며, $S^f$는 이후 MLP에 의해 처리되어 속도 feature를 추출한다. Temporal layer 내에서 $S^f$를 $(b \times h \times w) \times f \times c^\textrm{speed}$ 모양으로 반복하고 시간 차원 $f$에 걸쳐 속도 feature와 재구성된 feature map 사이에서 작동하는 cross-attention 메커니즘을 적용한다. 이렇게 하고 타겟 속도를 지정하면 생성된 캐릭터 머리의 회전 속도와 주파수를 여러 클립에서 동기화할 수 있다. Face Locator가 제공하는 얼굴 위치 제어와 결합하면 결과 출력이 안정적이고 제어 가능해진다.
지정된 얼굴 영역과 할당된 속도는 강력한 제어 조건을 구성하지 않는다. 얼굴 탐지기의 맥락에서 $M$은 전체 동영상 클립의 합집합이므로 얼굴 움직임이 허용되는 상당한 영역을 나타내므로 머리가 정적 자세로 제한되지 않는다. 속도 레이어와 관련하여 데이터셋 라벨링을 위한 사람의 머리 회전 속도를 정확하게 추정하는 것이 어렵다는 것은 예측된 속도 시퀀스가 본질적으로 잡음이 있다는 것을 의미한다. 결과적으로 생성된 머리 모션은 지정된 속도 수준에만 근접할 수 있다.
2. Training Strategies
학습 과정은 세 단계로 구성된다.
- 첫 번째 단계는 이미지 사전 학습으로, Backbone Network, ReferenceNet, Face Locator가 학습된다. 이 단계에서 Backbone은 단일 프레임을 입력으로 사용하고 ReferenceNet은 동일한 동영상 클립의 프레임에서 무작위로 선택된 별개의 프레임을 처리한다. Backbone과 ReferenceNet은 모두 Stable Diffusion에서 가중치를 초기화한다.
- 두 번째 단계에서는 temporal module과 오디오 레이어가 통합된 동영상 학습을 도입한다. $n+f$개의 연속 프레임이 동영상 클립에서 샘플링되고, 시작된 $n$ 프레임은 모션 프레임이다. Temporal module은 AnimateDiff에서 가중치를 초기화한다.
- 마지막 단계에서는 속도 레이어가 통합되며, 이 단계에서는 temporal module과 속도 레이어만 학습시킨다. 이 전략적 결정은 학습 과정에서 의도적으로 오디오 레이어를 생략한다. 말하는 캐릭터의 표정, 입 동작, 머리 움직임의 주파수가 주로 오디오의 영향을 받기 때문이다. 결과적으로 이러한 요소들 사이에는 상관 관계가 있는 것으로 보이며, 모델은 오디오가 아닌 속도 신호를 기반으로 캐릭터의 동작을 구동하도록 유도될 수 있다.
Experiments
- 데이터셋
- 250시간 분량의 talking head 동영상 + HDTF + VFHQ
- VFHQ는 오디오가 없으므로 첫번째 학습 단계에서만 사용
- 얼굴 bounding box 영역은 MediaPipe를 사용하여 추출
- 머리 회전 속도는 얼굴 랜드마크를 사용하여 각 프레임에 대한 6-DoF 머리 포즈를 추출한 후 연속 프레임 간의 회전 각도를 계산하여 라벨링
- 구현 디테일
- 동영상 클립은 512$\times$512로 resize 및 crop됨
- 첫 번째 학습 단계에서는 레퍼런스 이미지와 대상 프레임이 동영상 클립에서 별도로 샘플링되었으며 batch size 48로 Backbone Network와 ReferneceNet을 학습
- 두 번째와 세 번째 단계에서는 생성된 동영상 길이를 $f = 12$로 설정하고 모션 프레임 수를 $n = 4$로 설정하여 batch size 4를 채택
- 추가 feature 수 $m$은 Diffused Heads를 따라 2로 설정
- learning rate: $10^{-5}$
- inference: DDIM 샘플링 (40 step)
- 생성 속도: 한 batch ($f = 12$ 프레임)에 대해 약 15초 소요
1. Qualitative Comparisons
다음은 여러 talking head 생성 연구들과 생성 결과를 비교한 것이다.

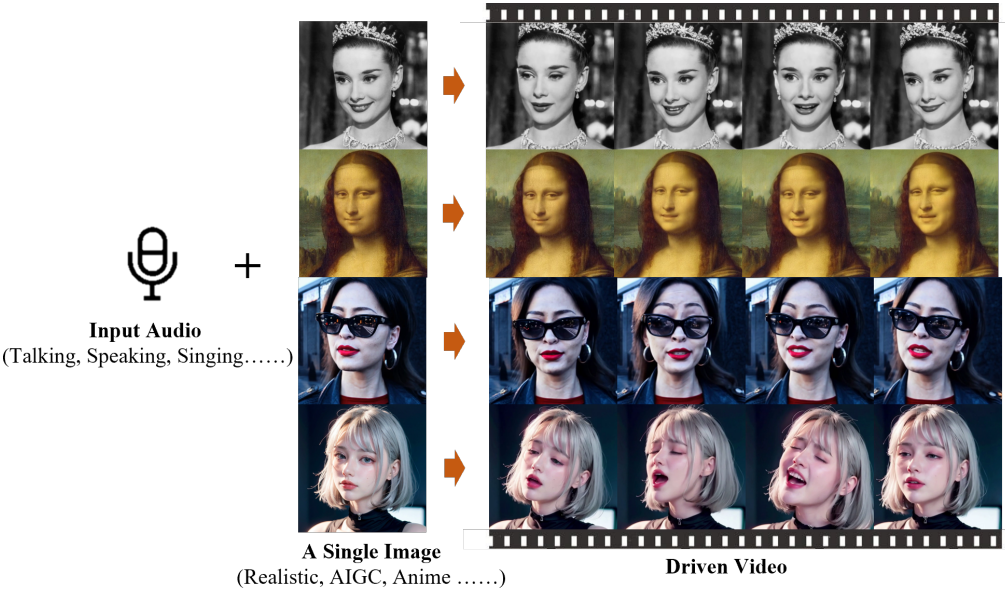
다음은 여러 초상화 스타일에 대한 생성 결과이다.

다음은 길이가 긴 보컬 오디오에 대하여 EMO로 생성된 결과이다.

다음은 Diffused Heads와 결과를 비교한 것이다.

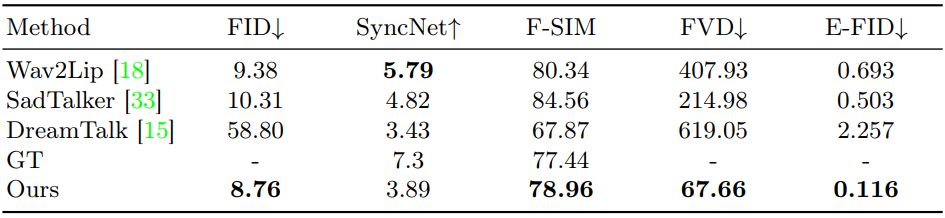
2. Quantitative Comparisons
다음은 여러 talking head 생성 연구들과 성능을 비교한 표이다.