[논문리뷰] EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
CVPR 2023. [Paper] [Github]
Xinyu Liu, Houwen Peng, Ningxin Zheng, Yuqing Yang, Han Hu, Yixuan Yuan
The Chinese University of Hong Kong | Microsoft Research
11 May 2023
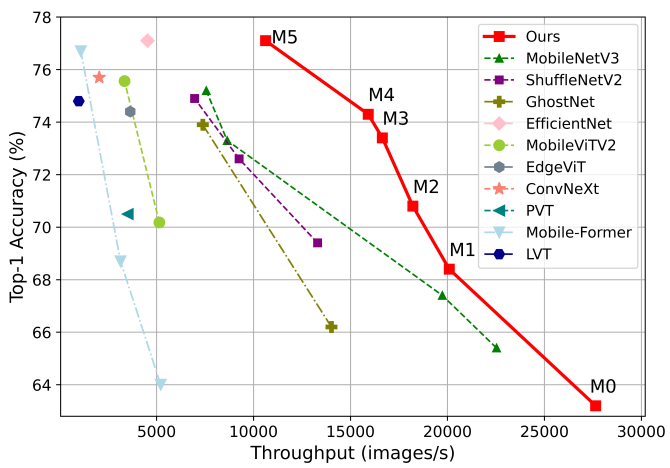
Introduction
ViT는 뛰어난 모델 능력과 성능으로 인해 컴퓨터 비전 도메인을 폭풍처럼 장악했다. 그러나 정확도가 지속적으로 향상되면서 모델 크기와 계산 오버헤드가 증가한다. 예를 들어 SwinV2는 30억 개의 파라미터를 사용하며 V-MoE는 147억 개의 파라미터를 사용하여 ImageNet에서 SOTA 성능을 달성하였다. 이러한 큰 모델 크기와 이에 따른 과도한 계산 비용으로 인해 이러한 모델은 실시간 애플리케이션에 적합하지 않다.
가볍고 효율적인 ViT 모델을 설계한 최근 연구들이 여러 개 있다. 불행하게도 이러한 방법의 대부분은 모델의 실제 inference 처리량을 반영하지 않는 모델 파라미터 또는 Flops를 줄이는 것을 목표로 한다. 예를 들어, 700M Flops의 MobileViT-XS는 Nvidia V100 GPU에서 1,220M Flops의 DeiT-T보다 훨씬 느리게 실행된다. 이러한 방법들은 더 적은 수의 Flops나 파라미터로 우수한 성능을 달성했지만, 이들 중 다수는 표준 transformer 또는 계층적 transformer (ex. DeiT, Swin)에 비해 상당한 실제 속도 향상을 나타내지 않았으며 널리 채택되지 않았다.
이 문제를 해결하기 위해 본 논문에서는 더 빠르게 ViT를 사용하는 방법을 탐색하고 효율적인 transformer 아키텍처를 설계하기 위한 원칙을 찾으려고 하였다. 널리 사용되는 ViT인 DeiT와 Swin을 기반으로 메모리 액세스, 계산 중복성, 파라미터 사용을 포함하여 모델 inference 속도에 영향을 미치는 세 가지 주요 요소를 체계적으로 분석하였다. 특히, 저자들은 transformer 모델의 속도는 일반적으로 메모리에 제한되어 있음을 발견했다. 즉, 메모리 액세스 지연은 GPU/CPU의 컴퓨팅 성능을 완전히 활용하는 것을 막아 transformer의 런타임 속도에 심각한 부정적인 영향을 미친다.
메모리를 가장 효율적으로 사용하지 않는 연산은 multi-head self-attention (MHSA)의 빈번한 텐서 reshaping과 element-wise 함수들이다. 저자들은 MHSA와 FFN(feedforward network) 레이어 사이의 비율을 적절하게 조정함으로써 성능 저하 없이 메모리 액세스 시간을 크게 줄일 수 있음을 관찰했다. 게다가 일부 attention head가 유사한 linear projection을 학습하는 경향이 있어 attention map이 중복되는 것을 발견했다. 다양한 feature를 제공하여 각 head의 계산을 명시적으로 분해하면 이 문제를 완화하는 동시에 계산 효율성을 향상시킬 수 있다. 또한 기존 경량 모델은 주로 표준 transformer 모델의 구성을 따르기 때문에 서로 다른 모듈의 파라미터 할당을 간과하는 경우가 많다. 파라미터 효율성을 향상시키기 위해 구조화된 pruning(가지치기)을 사용하여 가장 중요한 네트워크 구성요소를 식별한다.
분석의 결과를 바탕으로 본 논문은 EfficientViT라는 새로운 메모리 효율적인 transformer 모델을 제안한다. 구체적으로, 모델을 구축하기 위해 샌드위치 레이아웃으로 새로운 블록을 설계한다. 샌드위치 레이아웃 블록은 FFN 레이어 사이에 하나의 memory-bound MHSA 레이어를 적용한다. MHSA의 memory-bound 연산으로 인해 발생하는 시간 비용을 줄이고 더 많은 FFN 레이어를 적용하여 서로 다른 채널 간의 통신을 허용하므로 메모리 효율성이 향상된다.
그런 다음 계산 효율성을 향상시키기 위해 새로운 cascaded group attention (CGA) 모듈을 제안한다. 핵심 아이디어는 attention head에 공급되는 feature의 다양성을 향상시키는 것이다. 모든 head에 대해 동일한 feature를 사용하는 이전 self-attention과 달리 CGA는 각 head에 서로 다른 입력 split을 제공하고 출력 feature를 head 전체에 계단식으로 배열한다. 이 모듈은 multi-head attention의 계산 중복성을 줄일 뿐만 아니라 네트워크 깊이를 늘려 모델 용량을 높인다. 마지막으로, value projection과 같은 중요한 네트워크 구성요소의 채널 폭을 확장하는 동시에 FFN의 hidden 차원과 같이 중요도가 낮은 구성 요소를 축소하여 파라미터를 재분배한다. 이러한 재할당은 최종적으로 모델 파라미터 효율성을 향상시킨다.
Going Faster with Vision Transformers
1. Memory Efficiency
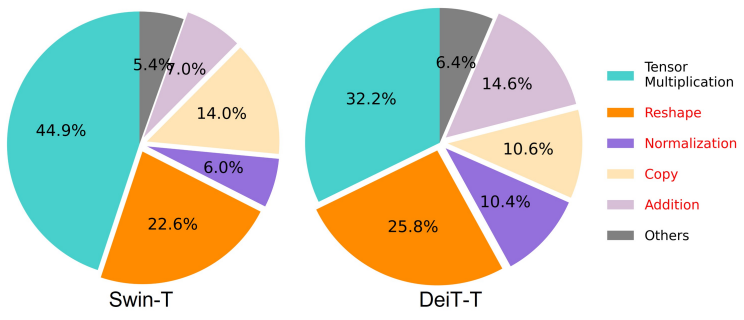
메모리 액세스 오버헤드는 모델 속도에 영향을 미치는 중요한 요소이다. 빈번한 reshaping, element-wise addition, 정규화와 같은 transformer의 많은 연산자는 메모리 비효율적이므로 위 그림에 표시된 것처럼 여러 메모리 장치에 걸쳐 시간이 많이 소요되는 액세스가 필요하다. 계산을 단순화하여 이 문제를 해결하기 위해 제안된 몇 가지 방법이 있지만 표준 softmax self-attention에서는 정확도가 저하되고 가속이 제한되는 대가를 치르는 경우가 많다.
본 논문에서는 메모리 비효율적인 레이어를 줄여 메모리 액세스 비용을 절감한다. 최근 연구에 따르면 메모리 비효율적인 연산은 주로 FFN 레이어가 아닌 MHSA에 위치한다. 그러나 대부분의 기존 ViT는 동일한 수의 두 레이어를 사용하므로 최적의 효율성을 달성하지 못할 수 있다. 따라서 본 논문은 소형 모델에서 MHSA와 FFN 레이어의 최적 할당을 탐색한다. 구체적으로 Swin-T와 DeiT-T를 inference 처리량이 1.25배 및 1.5배 더 높은 여러 개의 작은 하위 네트워크로 축소하고 MHSA 레이어의 비율이 다른 하위 네트워크의 성능을 비교하였다.
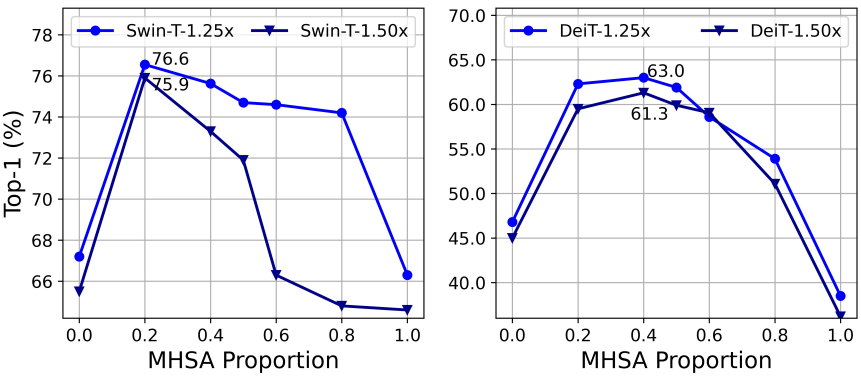
위 그림에서 볼 수 있듯이 20%-40% MHSA 레이어를 가진 하위 네트워크는 더 나은 정확도를 얻는 경향이 있다. 이러한 비율은 50% MHSA 레이어를 채택하는 일반적인 ViT보다 훨씬 작다. 또한 저자들은 reshaping, element-wise addition, 복사, 정규화를 포함한 메모리 액세스 효율성을 비교하기 위해 memory-bound 연산에 대한 시간 소비를 측정하였다. Memory-bound 연산은 20% MHSA 레이어가 있는 Swin-T-1.25$\times$에서 전체 런타임의 44.26%로 감소된다. 또한 1.5배 속도 향상을 통해 DeiT와 더 작은 모델로 일반화된다. MHSA 레이어 활용률을 적절하게 줄이면 모델 성능을 향상시키면서 메모리 효율성을 향상시킬 수 있다.
2. Computation Efficiency
MHSA는 입력 시퀀스를 여러 subspace (head)에 삽입하고 attention map을 별도로 계산하며 이는 성능 향상에 효과적인 것으로 입증되었다. 그러나 attention map은 계산 비용이 많이 들고, 연구에 따르면 그 중 상당수가 그다지 중요하지 않은 것으로 나타났다. 저자들은 계산 비용을 절약하기 위해 소규모 ViT 모델에서 중복 attention을 줄이는 방법을 살펴보았다. 저자들은 1.25배의 inference 속도 향상을 통해 너비가 축소된 Swin-T와 DeiT-T 모델을 학습하고 각 head와 각 블록 내의 나머지 head의 최대 코사인 유사도를 측정하였다.
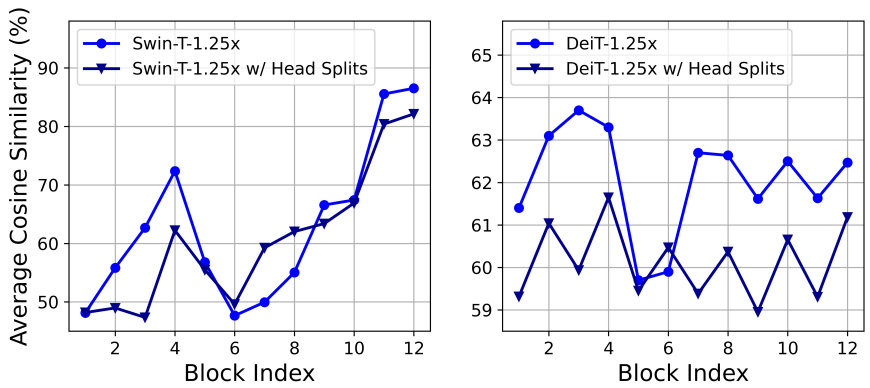
위 그래프에서는 특히 마지막 블록에서 attention head 사이에 높은 유사도가 있음을 관찰할 수 있다. 이 현상은 많은 head가 동일한 전체 feature에 대한 유사한 예측을 학습하고 계산 중복이 발생함을 시사한다. Head가 다양한 패턴을 학습하도록 명시적으로 장려하기 위해 각 head에 전체 feature의 split만 제공하는 직관적인 솔루션을 적용한다. 이는 group convolution 아이디어와 유사하다. 저자들은 수정된 MHSA를 사용하여 축소된 모델의 변형을 학습시키고 attention 유사도를 계산하였다. 위 그래프에서 볼 수 있듯이 모든 head에 대해 동일한 전체 feature를 사용하는 대신 서로 다른 head에서 feature를의 서로 다른 채널별 split을 사용하면 attention 계산 중복을 효과적으로 완화할 수 있다.
3. Parameter Efficiency
일반적인 ViT는 주로 NLP transformer의 설계 전략을 상속한다. 예를 들어 $Q$, $K$, $V$ projection에 동일한 너비를 사용하고, 단계에 걸쳐 head를 늘리고, FFN에서 확장 비율을 4로 설정한다. 경량 모델의 경우 이러한 구성 요소의 구성을 신중하게 다시 설계해야 한다. 저자들은 Taylor structured pruning을 채택하여 Swin-T와 DeiT-T에서 중요한 구성요소를 자동으로 찾고 파라미터 할당의 기본 원리를 탐색하였다. Pruning 방법은 특정 리소스 제약 하에서 중요하지 않은 채널을 제거하고 가장 중요한 채널을 유지하여 정확성을 최대한 유지한다. 채널 중요도로 기울기와 가중치의 곱셈을 사용하여 채널 제거 시 손실 변동을 근사화한다.
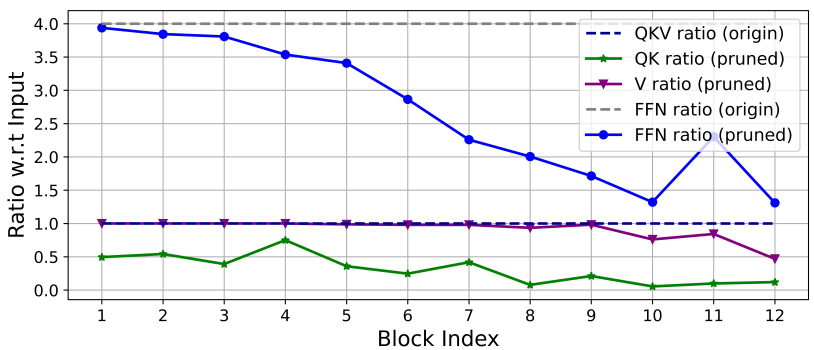
입력 채널에 대한 남은 출력 채널의 비율은 위 그래프에 표시되어 있다. 처음 두 단계에서는 더 많은 차원을 유지하는 반면 마지막 단계에서는 훨씬 적은 차원을 유지한다. 또한 $Q$, $K$, FFN 차원은 크게 잘려진 반면, $V$의 차원은 거의 보존되고 마지막 몇 블록에서만 감소한다. 이러한 현상은 다음을 보여준다.
- 각 단계 후에 채널을 두 배로 늘리거나 모든 블록에 대해 동일한 채널을 사용하는 일반적인 채널 구성이 마지막 몇 개의 블록에서 상당한 중복성을 생성할 수 있음을 보여준다.
- $Q$, $K$의 중복성은 동일한 차원을 가질 때 $V$보다 훨씬 크다. $V$는 입력 임베딩 차원에 가까운 상대적으로 큰 채널을 선호한다.
Efficient Vision Transformer
위의 분석을 바탕으로 저자들은 EfficientViT라는 빠른 inference를 갖춘 새로운 계층적 모델을 제안하였다.
1. EfficientViT Building Blocks
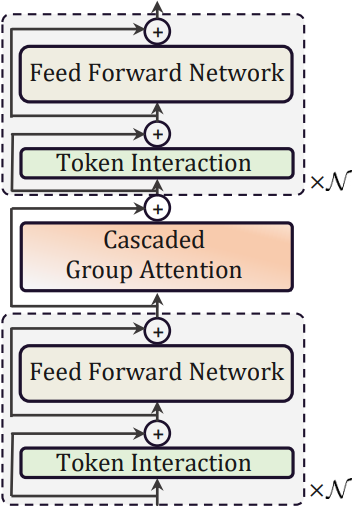
본 논문은 위 그림과 같이 ViT를 위한 새로운 효율적인 빌딩 블록을 제안하였다. 이는 메모리 효율적인 샌드위치 레이아웃, cascaded group attention (CGA) 모듈, 파라미터 재할당 전략으로 구성되며 각각 메모리, 계산량, 파라미터 측면에서 모델 효율성을 향상시키는 데 중점을 둔다.
Sandwich Layout
본 논문은 메모리 효율적인 블록을 구축하기 위해 채널 통신에서 memory-bound self-attention 레이어를 줄이고 메모리 효율적인 FFN 레이어를 사용하는 샌드위치 레이아웃을 제안한다. 구체적으로, 공간적 혼합을 위해 하나의 self-attention 레이어 $\Phi_i^A$를 적용하며, 이는 FFN 레이어 $\Phi_i^F$ 사이에 끼워져 있다. 계산은 다음과 같이 공식화될 수 있다.
\[\begin{equation} X_{i+1} = \prod^N \Phi_i^F (\Phi_i^A (\prod^N \Phi_i^F (X_i))) \end{equation}\]여기서 $X_i$는 $i$번째 블록의 전체 입력 feature이다. 블록은 하나의 self-attention 레이어 전후에 $N$개의 FFN을 사용하여 $X_i$를 $X_{i+1}$로 변환한다. 이 디자인은 모델의 self-attention 레이어로 인해 발생하는 메모리 시간 소비를 줄이고 더 많은 FFN 레이어를 적용하여 서로 다른 feature 채널 간의 효율적 통신을 가능하게 한다. 또한 depthwise convolution (DWConv)을 사용하여 각 FFN 앞에 추가 토큰 상호 작용 레이어를 적용한다. 모델 능력을 향상시키기 위해 로컬 구조 정보의 inductive bias를 도입한다.
Cascaded Group Attention
Attention head 중복은 MHSA에서 심각한 문제로, 이로 인해 계산 비효율이 발생한다. 효율적인 CNN의 group convolution에서 영감을 받아 ViT를 위한 cascaded group attention (CGA)라는 새로운 attention 모듈을 제안한다. 이는 각 head에 전체 feature를 서로 다르게 분할하여 제공하므로 head 전체에 걸쳐 attention 계산을 명시적으로 분해한다. 이 attention은 다음과 같이 공식화될 수 있다.
\[\begin{equation} \tilde{X}_{ij} = \textrm{Attn} (X_{ij} W_{ij}^Q, X_{ij} W_{ij}^K, X_{ij} W_{ij}^V) \\ \tilde{X}_{i+1} = \textrm{Concat} [\tilde{X}_{ij}]_{j = 1:h} W_i^P \end{equation}\]여기서 $j$번째 head는 입력 feature $X_i$의 $j$번째 split인 $X_{ij}$에 대한 self-attention을 계산한다.
\[\begin{equation} X_i = [X_{i1}, X_{i2}, \ldots, X_{ih}], \quad 1 \le j \le h \end{equation}\]$h$는 head의 총 개수이고, $W_{ij}^Q$, $W_{ij}^K$, $W_{ij}^V$는 서로 다른 subspace로 분할된 입력 feature를 매핑하는 projection layer이고, $W_i^P$는 concat된 출력 feature들을 입력과 일치하는 차원으로 다시 project하는 linear layer이다.
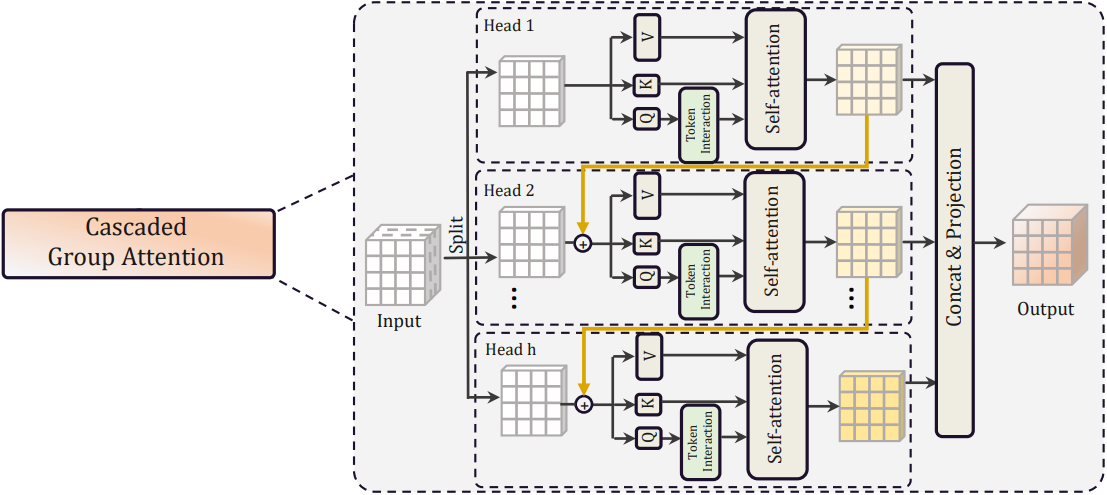
각 head에 대한 전체 feature 대신 feature split을 사용하는 것이 더 효율적이고 계산 오버헤드를 절약하지만 $Q$, $K$, $V$ 레이어가 더 풍부한 정보가 있는 feature에 대한 projection을 학습하도록 장려하여 용량을 지속적으로 개선한다. 위 그림에 표시된 것처럼 계단식 방식으로 각 head의 attention map을 계산한다. 이는 각 head의 출력을 다음 head에 추가하여 feature 표현을 점진적으로 개선한다.
여기서 $X_{ij}^\prime$는 $j$번째 입력 split $X_{ij}$와 $(j−1)$번째 head의 출력 \(\tilde{X}_{i(j−1)}\)의 합이다. 이는 self-attention을 계산할 때 $j$번째 head에 대한 새로운 입력 feature 역할을 하기 위해 $X_{ij}$를 대체한다. 게다가 $Q$ projection 이후에 또 다른 토큰 상호 작용 레이어가 적용되어 self-attention이 로컬 관계와 글로벌 관계를 공동으로 포착하고 feature 표현을 더욱 향상시킬 수 있다.
이러한 계단식 디자인에는 두 가지 장점이 있다.
- 각 head에 서로 다른 feature split을 제공하면 attention map의 다양성을 향상시킬 수 있다. Group convolution과 유사하게 cascaded group attention은 QKV 레이어의 입력 채널과 출력 채널이 $h$배만큼 감소하므로 Flops와 파라미터를 $h$배만큼 절약할 수 있다.
- Attention head를 계단식으로 배열하면 네트워크 깊이가 증가하므로 추가 파라미터를 도입하지 않고도 모델 용량이 더욱 향상된다. 각 head의 attention map 계산이 더 작은 QK 채널 차원을 사용하므로 약간의 지연 시간 오버헤드만 발생한다.
Parameter Reallocation
파라미터 효율성을 높이기 위해 중요한 모듈의 채널 폭을 확장하고 중요하지 않은 모듈은 축소하여 네트워크에서 파라미터를 재할당한다. 특히 저자들은 Taylor 중요도 분석을 기반으로 모든 단계에 대해 각 head의 $Q$ projection과 $K$ projection에 대한 작은 채널 크기를 설정했다. $V$ projection의 경우 입력 임베딩과 동일한 차원을 갖도록 허용한다. FFN의 확장 비율도 파라미터 중복으로 인해 4에서 2로 감소된다. 제안된 재할당 전략을 사용하면 중요한 모듈이 고차원 공간에서 표현을 학습할 수 있는 더 많은 수의 채널을 갖게 되어 feature 정보의 손실을 방지할 수 있다. 한편, 중요하지 않은 모듈의 중복 파라미터를 제거하여 inference 속도를 높이고 모델 효율성을 향상시킨다.
2. EfficientViT Network Architectures
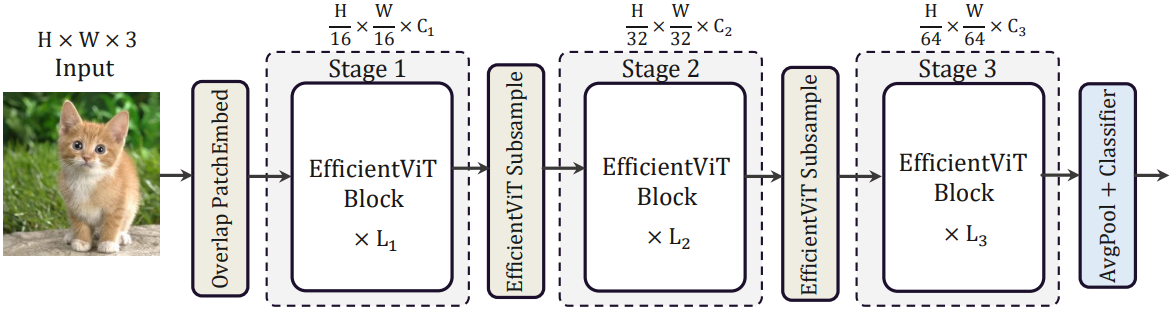
EfficientViT의 전체 아키텍처는 위 그림에 나와 있다. 구체적으로 $C_1$ 차원의 토큰에 16$\times$16 패치를 삽입하기 위해 overlapping patch embedding을 도입하여 낮은 수준의 시각적 표현 학습에서 모델 용량을 향상시킨다. 아키텍처에는 세 단계가 포함된다. 각 단계에서는 제안된 EfficientViT 빌딩 블록을 쌓고 토큰 수는 각 서브샘플링 레이어에서 4배만큼 줄어든다. 효율적인 서브샘플링을 달성하기 위해 샌드위치 레이아웃을 갖는 EfficientViT 서브샘플 블록을 사용한다. 단, self-attention 레이어는 서브샘플링 중 정보 손실을 줄이기 위해 inverted residual block으로 대체된다. 모델 전반에 걸쳐 Layer Norm (LN) 대신 BatchNorm (BN)을 채택한다는 점은 주목할 가치가 있다. BN은 이전 convolution layer 또는 linear layer로 접힐 수 있으며 이는 LN에 비해 런타임에 이점이 있다. 일반적으로 사용되는 GELU 또는 HardSwish는 훨씬 느리고 때로는 특정 inference 배포 플랫폼에서 잘 지원되지 않기 때문에 ReLU를 activation function으로 사용한다.
저자들은 6개의 서로 다른 너비와 깊이 스케일을 사용하여 모델들을 구축하고 각 단계마다 서로 다른 head 수를 설정하였다. MobileNetV3와 LeViT와 비슷하게 나중 단계보다 초기 단계에서 더 적은 수의 블록을 사용한다. 왜냐하면 더 큰 해상도의 초기 단계에서 처리하는 데 더 많은 시간이 소요되기 때문이다. 앞서 분석한 바와 같이, 나중 단계의 중복성을 완화하기 위해 작은 factor ($\le 2$)를 사용하여 단계에 걸쳐 너비를 늘린다. 모델들의 아키텍처 디테일은 아래 표와 같다. $C_i$, $L_i$, $H_i$는 $i$번째 단계의 너비, 깊이, head 수를 나타낸다.
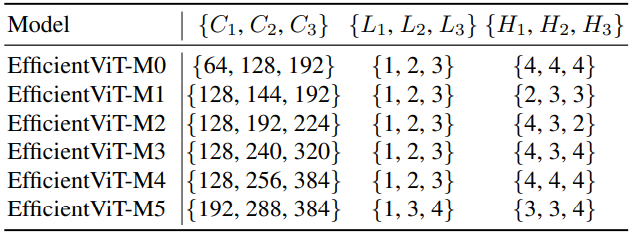
Experiment
- 데이터셋: ImageNet-1K
- 구현 디테일
- optimizer: AdamW
- epoch 수: 300
- learning rate: $2.5 \times 10^{-2}$, cosine schedule
- 전체 batch size: 2048
- 이미지 크기: 224$\times$224
- augmentation: Mixup, auto-augmentation, random erasing
- 8개의 Nvidia V100 GPU
- 다운스트림 task fine-tuning
- optimizer: AdamW
- epoch 수: 300
- learning rate: $1 \times 10^{-3}$, cosine schedule
- weight decay: $1 \times 10^{-8}$
1. Results on ImageNet
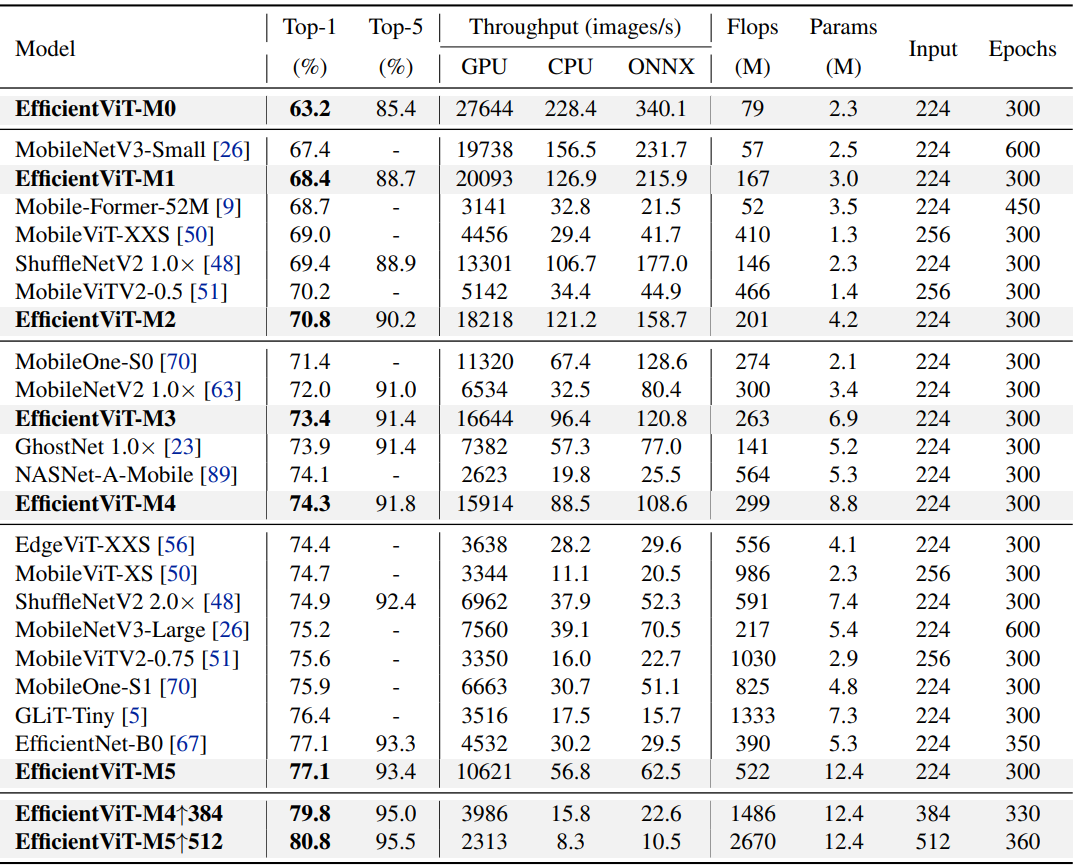
다음은 ImageNet-1K에서 EfficientViT의 이미지 분류 성능을 추가 데이터 없이 학습된 SOTA efficient CNN 및 ViT 모델과 비교한 표이다.
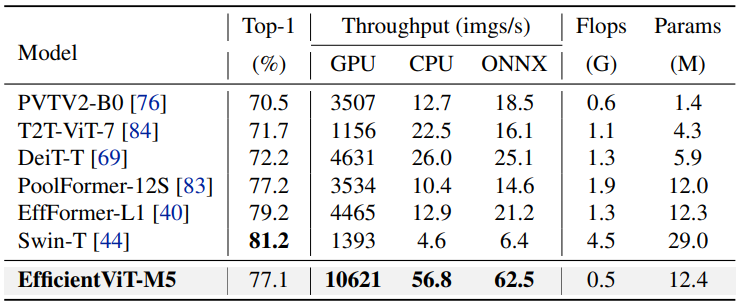
다음은 ImageNet-1K에서 tiny 버전의 대규모 ViT와 비교한 표이다.
2. Transfer Learning Results
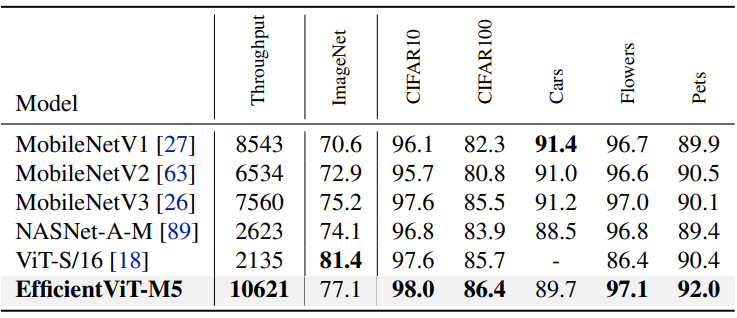
다음은 다운스트림 이미지 분류 데이터셋들에서 EfficientViT를 다른 efficient model과 비교한 표이다.
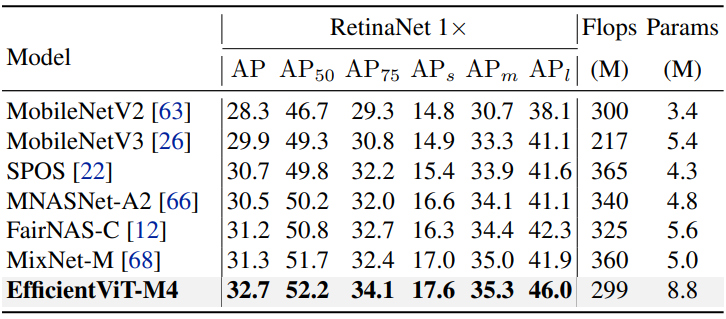
다음은 COCO val2017에서 EfficientViT의 object detection 성능을 다른 efficient model과 비교한 표이다.
3. Ablation Study
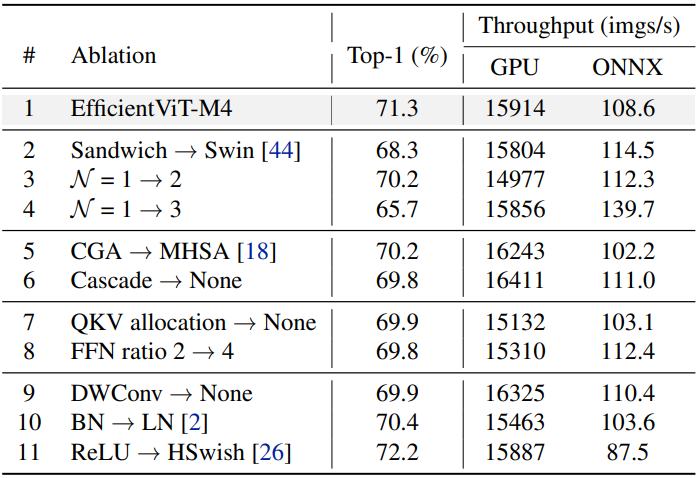
다음은 ImageNet-1K에서의 EfficientViT-M4에 대한 ablation 결과이다.
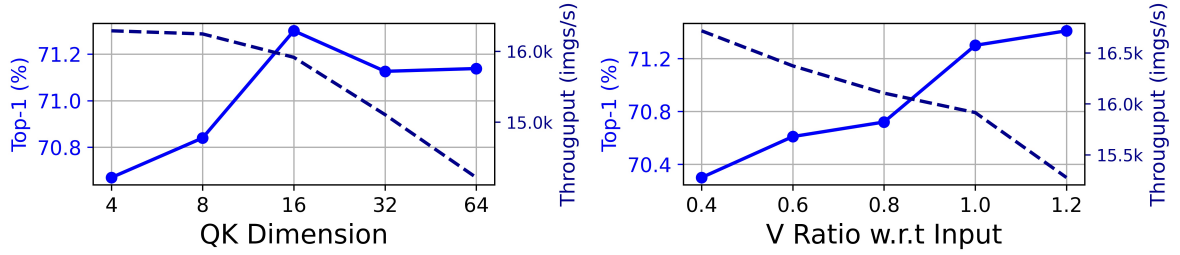
다음은 각 head의 QK 차원과 입력 임베딩에 대한 V 차원의 비율에 대한 ablation 결과이다.
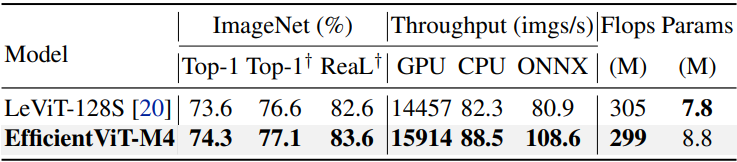
다음은 ImageNet-1K과 ImageNet-ReaL에 대한 성능 비교 결과이다.
Limitations
- 도입된 샌드위치 레이아웃의 추가 FFN으로 인해 모델 크기가 SOTA efficient CNN에 비해 약간 더 크다.
- EfficientViT는 효율적인 ViT 구축에 대해 파생된 가이드라인을 기반으로 수동으로 설계되었다.