[논문리뷰] Efficient Track Anything
ICCV 2025. [Paper] [Page] [Github]
Yunyang Xiong, Chong Zhou, Xiaoyu Xiang, Lemeng Wu, Chenchen Zhu, Zechun Liu, Saksham Suri, Balakrishnan Varadarajan, Ramya Akula, Forrest Iandola, Raghuraman Krishnamoorthi, Bilge Soran, Vikas Chandra
Meta AI | Nanyang Technological University
28 Nov 2024
Introduction
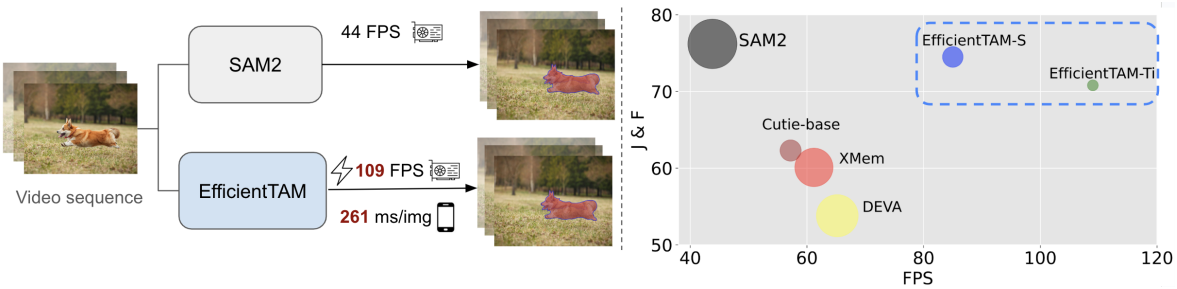
SAM 2는 모바일 배포에 효율적이지 않다. SAM 2의 기본 이미지 인코더인 HieraB+는 파라미터 비효율적이다 (80M). Tiny 버전이 있지만, 계층적인 이미지 인코더로 인해 실행 시간이 43.8 FPS로 기본 SAM 2 모델의 47.2 FPS와 유사하다. 또한, 메모리 토큰이 길어 (약 3만) cross-attention이 적용된 메모리 모듈의 효율성을 저해한다.
저자들은 video object segmentation (VOS)와 track anything을 위해 일반적이고 계층적이지 않은 이미지 인코더를 재검토하였다. 구체적으로, EfficientSAM처럼 가벼운 일반 ViT 이미지 인코더 (ex. ViT-Tiny/-Small)를 사용하여 SAM 2의 복잡도를 줄이면서도 적절한 성능을 유지하는 방안을 제안하였다. 또한, 메모리 모듈 가속을 위한 효율적인 cross-attention 기법을 제안하였다. 이 기법은 메모리 공간 토큰의 기본 구조를 활용하여 구현된다. 메모리 공간 토큰은 강력한 locality를 가지며, 메모리 공간 토큰의 더 coarse한 표현이 cross-attention 수행을 위한 좋은 대안이 될 수 있다.
EfficientTAM은 강력한 semi-supervised VOS 방법보다 성능이 뛰어나면서도 효율성이 더 높다. SAM 2와 비교했을 때, EfficientTAM은 SA-V 테스트 데이터셋에서 비슷한 성능을 보이며, FPS는 약 2배 감소했다. Image segmentation 벤치마크인 SA-23에서 EfficientTAM은 60.7%의 정확도를 달성했으며, SAM은 59.1%, SAM 2는 61.9%의 정확도를 보였다. 또한, iPhone 15 Pro Max에서 약 10 FPS의 속도로 합리적인 video segmentation 성능을 구현하였다.
Method
1. SAM 2
SAM 2의 아키텍처는 계층적 이미지 인코더, 프롬프트 기반 마스크 디코더, 그리고 새로운 메모리 메커니즘으로 구성된다. 안정적인 object tracking을 위해 SAM 2는 메모리 인코더, memory bank, memory attention 모듈로 구성된 메모리 메커니즘을 사용한다. SAM 2는 과거 프레임의 정보를 저장하고, memory attention 모듈을 사용하여 memory bank에 저장된 메모리와 현재 프레임 feature 간의 cross-attention을 수행하여 동영상의 시간적 의존성을 파악한다.
Memory attention 모듈은 transformer block의 스택으로 구성된다. 각 block에는 self-attention, cross-attention, MLP가 포함된다. 첫 번째 transformer block은 현재 프레임의 이미지 임베딩을 입력으로 받는다. Cross-attention은 현재 프레임 임베딩과 memory bank에 저장된 메모리를 통합하여 시간적 correspondence 정보가 있는 임베딩을 생성한다. 메모리 토큰 $M_b$는 메모리 인코더의 메모리 공간 토큰 $M_s$과 마스크 디코더의 object pointer 토큰 $M_p$의 두 부분으로 구성된다.
\[\begin{equation} M_b = \begin{bmatrix} M_s \in \mathbb{R}^{n \times d_m} \\ M_p \in \mathbb{R}^{P \times d_m} \end{bmatrix} \in \mathbb{R}^{(n+P) \times d_m} \end{equation}\]($n$은 공간 토큰의 개수, $P$는 object pointer 토큰의 개수, $d_m$은 채널 차원)
Self-attention 후 입력 프레임 feature를 $X \in \mathbb{R}^{L \times d_q}$라 하자. $X$는 query $Q \in \mathbb{R}^{L \times d}$로 projection되고, 메모리 토큰 $M_b$는 key $K \in \mathbb{R}^{(n+P) \times d}$와 value $V \in \mathbb{R}^{(n+P) \times d}$로 projection된다. Cross-attention 메커니즘은 다음과 같다.
\[\begin{equation} \textbf{C} (Q, K, V) = \textrm{softmax} \left( \frac{QK^\top}{\sqrt{d}} \right) V \end{equation}\]2. Efficient Video Object Segmentation and Track Anything
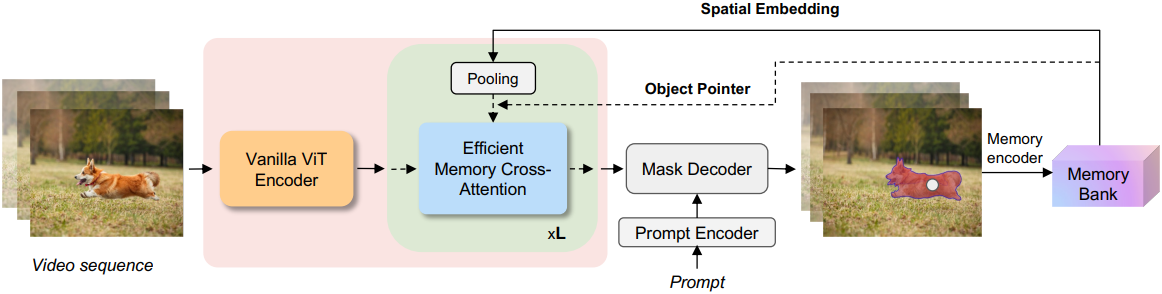
효율적인 이미지 인코더
이미지 인코더의 역할은 각 고해상도 프레임에 대한 feature 임베딩을 생성하는 것이다. 저자들은 EfficientSAM의 사전 학습된 기본 ViT 이미지 인코더를 사용하여 프레임 feature를 추출하였다. SAM 2의 이미지 인코더와 달리, 이 이미지 인코더는 단일 스케일 feature map을 제공하며, 디코딩 과정에서 마스크 디코더의 feature가 upsampling layer에 더해지지지 않는다.
구체적으로, 저자들은 16$\times$16 패치 크기를 갖는 ViT-Small과 ViT-Tiny를 이미지 인코더로 채택하였다. 고해상도 프레임에서 효율적으로 feature를 추출하기 위해, 14$\times$14 non-overlapping windowed attention을 사용하고, 4개의 block마다 global attention block을 사용한다. 이미지 인코더는 16배 감소된 64$\times$64 해상도의 feature 임베딩을 출력한다.
효율적인 메모리 모듈
메모리 모듈은 이전 프레임의 정보를 활용하여 일관된 object tracking을 용이하게 한다. Cross-attention은 긴 메모리 토큰 시퀀스로 인해 SAM 2 메모리 모듈의 효율성을 떨어뜨리는 주요 원인이다.
충분히 작은 local window $l_w \times l_h$가 주어졌을 때, 한 window 내에서 하나의 토큰을 사용하면 메모리 공간 토큰 $K_s$를 더 coarse한 공간 토큰 \(\tilde{K}_s\)로 표현할 수 있다. Cross-attention에서 높은 상관관계를 갖는 이웃 토큰에 average pooling을 수행하여, key $K$와 value $V$에 대한 더 coarse한 표현을 효율적으로 계산한다. 입력 공간 토큰
\[\begin{equation} K_s = \begin{bmatrix} k_{11} & \cdots & k_{1h} \\ \vdots & \ddots & \vdots \\ k_{w1} & \cdots & k_{wh} \end{bmatrix}, \quad V_s = \begin{bmatrix} v_{11} & \cdots & v_{1h} \\ \vdots & \ddots & \vdots \\ v_{w1} & \cdots & v_{wh} \end{bmatrix} \end{equation}\]에 대해, $n = w \times h$개의 토큰을 $\tilde{w} \times \tilde{h}$개의 직사각형 pooling 영역으로 나누고 각 영역의 평균 토큰을 계산한다. \(\tilde{K}_s\)와 \(\tilde{V}_s\)는 다음과 같이 계산할 수 있다.
\[\begin{equation} \tilde{k}_{ij} = \sum_{p = i \times l_w + 1}^{(i+1) \times l_w} \sum_{q = j \times l_h + 1}^{(j+1) \times l_h} \frac{k_{pq}}{l_w l_h}, \quad \tilde{v}_{ij} = \sum_{p = i \times l_w + 1}^{(i+1) \times l_w} \sum_{q = j \times l_h + 1}^{(j+1) \times l_h} \frac{v_{pq}}{l_w l_h} \\ \textrm{where} \quad i = 1, \ldots, \tilde{w}, \quad j = 1, \ldots, \tilde{h}, \quad l_w = \frac{w}{\tilde{w}}, \quad l_h = \frac{h}{\tilde{h}} \end{equation}\]이 token-pooling 방식은 토큰을 한 번 스캔하여 효율적인 coarse한 토큰을 생성한다. 2$\times$2 average pooling을 사용하면 공간 토큰에 대한 좋은 근사값을 확보하기에 충분하다.
\(\tilde{K}_s, \tilde{V}_s \in \mathbb{R}^{\tilde{w} \tilde{h} \times d}\)의 크기를 $K_s, V_s \in \mathbb{R}^{n \times d}$와 맞추기 위해, 각 \(\tilde{k}_i\)를 $l_w l_h$번 쌓아서 \(\bar{K}_s, \bar{V}_s \in \mathbb{R}^{n \times d}\)를 구성할 수 있다.
\[\begin{equation} \bar{K}_s = [\underbrace{\tilde{k}_1; \ldots; \tilde{k}_1}_{l_w l_h}; \ldots; \underbrace{\tilde{k}_{\tilde{w} \tilde{h}}; \ldots; \tilde{k}_{\tilde{w} \tilde{h}}}_{l_w l_h}] \\ \bar{V}_s = [\underbrace{\tilde{v}_1; \ldots; \tilde{v}_1}_{l_w l_h}; \ldots; \underbrace{\tilde{v}_{\tilde{w} \tilde{h}}; \ldots; \tilde{v}_{\tilde{w} \tilde{h}}}_{l_w l_h}] \\ \end{equation}\]그런 다음, 이 coarse한 공간 토큰을 object pointer 토큰과 concat한다.
\[\begin{equation} \bar{K} = [\bar{K}_s; K_p] \in \mathbb{R}^{(n+P) \times d}, \quad \bar{V} = [\bar{V}_s; V_p] \in \mathbb{R}^{(n+P) \times d} \end{equation}\]Coarse한 메모리 토큰 $\bar{K}$와 $\bar{V}$에 대해 다음과 같이 효율적으로 cross-attention을 계산한다.
\[\begin{equation} \bar{\textbf{C}} (Q, K, V) = \textrm{softmax} \left( \frac{Q \bar{K}^\top}{\sqrt{d}} \right) \bar{V} = \textrm{softmax}(A) \tilde{V} \\ \textrm{where} \quad A = [\frac{Q \tilde{K}_s^\top}{\sqrt{d}} + \ln (l_w l_h), \frac{QK_p^\top}{\sqrt{d}}] \in \mathbb{R}^{L \times (\tilde{w} \tilde{h} + P)}, \quad \tilde{V} = [\tilde{V}_s; V_p] \in \mathbb{R}^{(\tilde{w} \tilde{h} + P) \times d} \end{equation}\]아래 그림에서 볼 수 있듯이, 이 효율적인 cross-attention은 원래 cross-attention과 유사하다.

효율적인 cross-attention variant
Pooling 후 공간 토큰에 대한 attention이 감소하는 것을 방지하기 위해, coarse한 공간 토큰과 object pointer 토큰 간의 attention 점수를 균형 있게 조정하는 상수가 존재한다. Key에 상수를 추가하여 또 다른 cross-attention variant를 얻을 수 있다.
\[\begin{equation} \tilde{\textbf{C}} (Q, K, V) = \textrm{softmax} \left( \frac{Q \tilde{K}^\top}{\sqrt{d}} \right) \tilde{V} \\ \textrm{where} \quad \tilde{K} = [\tilde{K}_s + \ln (l_w l_h); K_p] \in \mathbb{R}^{(\tilde{w} \tilde{h} + P) \times d} \end{equation}\]Experiments
1. Main Results
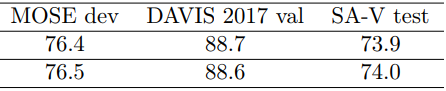
다음은 다양한 VOS 벤치마크에 대한 성능을 비교한 결과이다.
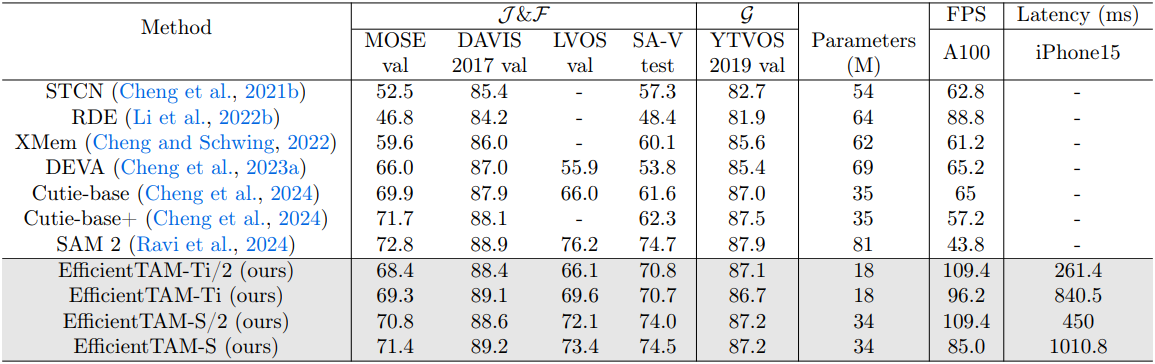
다음은 프롬프트를 사용한 VOS 성능을 비교한 결과이다.
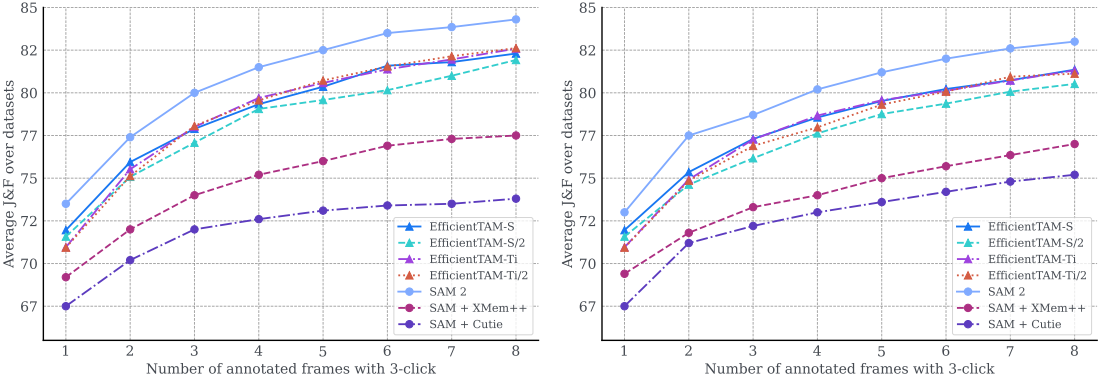
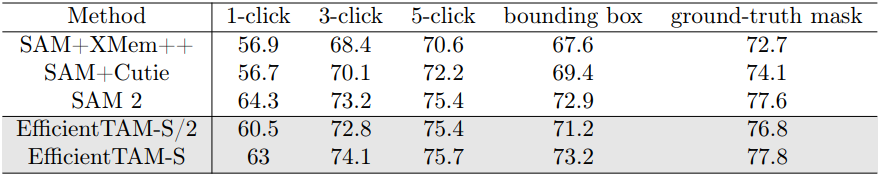
다음은 다양한 프롬프트에 대한 VOS 결과를 비교한 것이다.
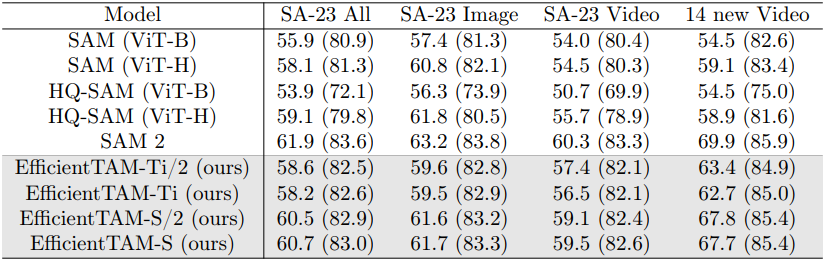
다음은 segment anything 성능을 1-click (5-click) mIoU로 비교한 결과이다.
다음은 SAM 2와 segmentation 및 tracking 결과를 비교한 예시들이다.

2. Ablation Studies
다음은 두 cross-attention variant에 대한 비교 결과이다. (위가 \(\bar{\textbf{C}} (Q, K, V)\), 아래가 \(\tilde{\textbf{C}} (Q, K, V)\))
다음은 입력 해상도에 대한 ablation study 결과이다.
