[논문리뷰] EASI-Tex: Edge-Aware Mesh Texturing from Single Image
SIGGRAPH 2024. [Paper] [Page] [Github]
Sai Raj Kishore Perla, Yizhi Wang, Ali Mahdavi-Amiri, Hao Zhang
Simon Fraser University
27 May 2024

Introduction
본 논문에서는 풍부한 온라인 이미지 소스로부터 고품질 3D 메쉬 모델에 풍부한 텍스처를 적용하는 단일 이미지 메쉬 텍스처링 문제를 연구하였다. 구체적으로, 입력으로는 메쉬 object $\textbf{M}$과 임의의 시점에서 촬영된 다른 object의 이미지 \(\textbf{I}_\textrm{tex}\)를 사용한다. 출력은 \(\textbf{I}_\textrm{tex}\)을 조건으로 $\textbf{M}$의 geometry를 변경하지 않고 텍스처가 완벽하게 적용된 버전이다. 텍스처 전송이 합리적이기 위해서는 입력 이미지의 object와 $\textbf{M}$ 사이에 의미 있는 대응 관계가 있어야 한다. 그러나 두 object가 동일한 카테고리에 속한다고 가정하지 않으며, 설령 동일하더라도 geometry와 part 비율에 상당한 차이가 있을 수 있다. 본 논문의 방법은 \(\textbf{I}_\textrm{tex}\)에 충실하면서도 $\textbf{M}$의 geometry를 유지하여 3D 모델에 깨끗하고 선명한 텍스처를 생성함으로써 자연스럽고 타당한 텍스처 전송을 보장하는 것을 목표로 한다.
입력 이미지가 하나의 뷰에서 얻은 부분적인 정보만을 포함하고 있고, 잠재적인 불일치로 인해 입력 3D 모델에 적합하지 않은 텍스처를 포함하고 있기 때문에, 본 논문에서는 텍스처링 문제를 생성적 task로 간주하였다. 본 논문은 입력 텍스처는 물론 입력 3D 모델의 geometry와 semantic 정보까지 존중하는 고품질 텍스처 전송을 달성하기 위해, 적절한 컨디셔닝을 적용한 diffusion model을 활용하는 새로운 접근 방식을 제안했다.
- 사전 학습된 Stable Diffusion (SD) generator를 활용하여, 입력 이미지에서 직접적인 가이드가 없는 경우에도 주어진 메쉬에 텍스처를 전송할 수 있다.
- 3D 모델의 identity를 보존하기 위해, 입력 메쉬의 geometry를 특징짓는 edge를 추출하고, 이를 텍스처링 과정에서 ControlNet을 통해 diffusion model의 컨디셔닝 신호로 사용한다.
- 입력 이미지에서 추출한 feature와 IP-Adapter를 사용한 설명 텍스트 프롬프트를 모두 활용하여 생성 프로세스를 컨디셔닝한다. 이러한 이미지 프롬프트 어댑터를 사용하면 최적화나 학습 없이 이미지를 프롬프트로 사용하여 텍스처링 중에 diffusion model을 효율적으로 가이드할 수 있다.
본 논문에서 제안하는 메쉬 텍스처링 접근 방식인 EASI-Tex는 입력 메쉬의 geometry 및 semantic identity를 보존하면서 personalization 기반 텍스처 전송에 대한 효율적이고 최적화가 필요 없는 대안이다. 이러한 identity 보존은 깊이 컨디셔닝이 아닌 edge 컨디셔닝을 통해 달성되는데, 깊이 컨디셔닝은 identity 보존 및 메쉬의 geometry 디테일을 존중하는 측면에서 EASI-Tex보다 취약하기 때문이다. 또한, 사전 학습된 IP-Adapter가 입력 텍스처 이미지의 모든 디테일을 충실하게 포착하지 못하는 경우, 이미지를 사용하여 단일 개념에 맞게 diffusion model을 신속하게 조정하는 새로운 personalization 기법인 Image Inversion을 도입하였다.
Method
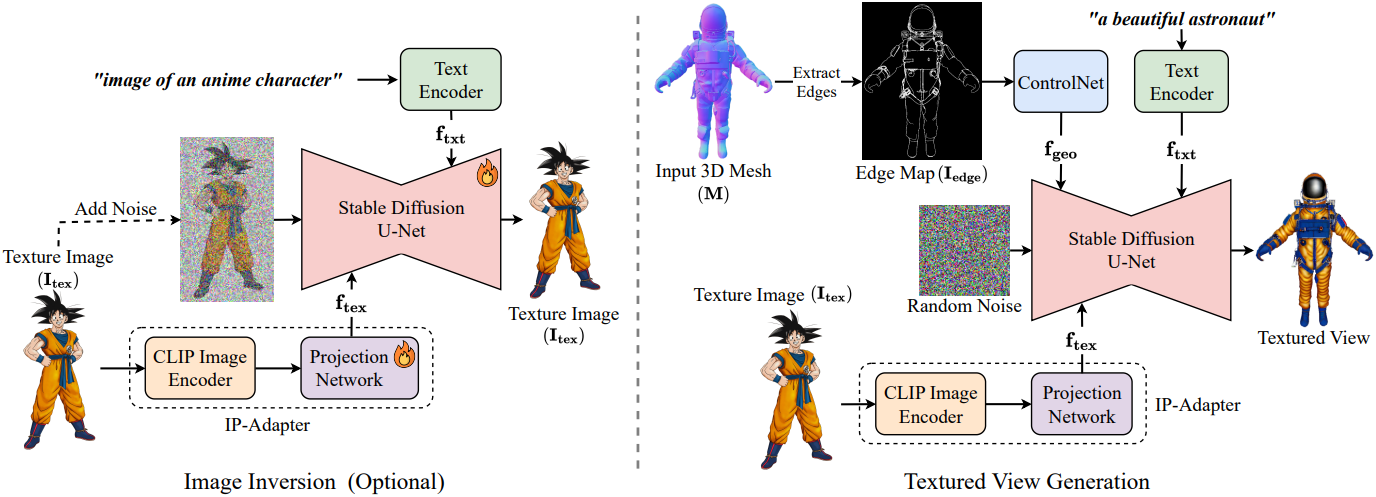
입력으로 텍스처링 되지 않은 3D 메쉬 $\textbf{M}$과 예시 텍스처 이미지 \(\textbf{I}_\textrm{tex}\)가 주어졌을 때, 본 논문의 목표는 3D object의 semantic feature와 geometric feature를 유지하면서 \(\textbf{I}_\textrm{tex}\)의 텍스처를 $\textbf{M}$으로 전송하는 것이다. 텍스처 전송 과정은 크게 두 단계로 구성된다.
- \(\textbf{I}_\textrm{tex}\)의 컨텐츠를 이해하고 텍스처 정보를 정확하게 추출하는 단계
- M의 semantic feature와 geometric feature를 이해하고 추출된 텍스처를 해당 부분에 충실하게 전송하는 단계
문제는 \(\textbf{I}_\textrm{tex}\)와 $\textbf{M}$의 컨텐츠가 서로 다를 때 발생하며, 이 경우 텍스처링 파이프라인은 자연스러운 텍스처를 생성하기 위해 텍스처 전송과 생성 사이의 균형을 맞춰야 한다. 저자들은 텍스처링 과정에서 모델이 \(\textbf{I}_\textrm{tex}\)와 $\textbf{M}$을 더 잘 이해하도록 함으로써 이 문제를 해결할 수 있다고 생각하였다.
이를 위해 diffusion model의 입력으로 더 나은 컨디셔닝 신호를 사용하는 것을 목표로 한다. 구체적으로, 텍스트 프롬프트나 depth map이 포함된 텍스트 프롬프트와 같은 일반적인 컨디셔닝 신호에서 벗어나, 입력 텍스처 이미지 \(\textbf{I}_\textrm{tex}\), 3D 메쉬에서 추출한 edge $\textbf{M}$, 텍스트 프롬프트와 같은 더 강력한 컨디셔닝 신호를 직접 사용한다. 이는 텍스처 전송 품질을 크게 향상시킬 뿐만 아니라, 3D 메쉬의 semantic과 geometry를 더욱 정확하게 반영할 수 있도록 한다. 또한, 사전 학습된 모델이 입력 텍스처 이미지의 모든 디테일을 충실하게 포착하지 못하는 경우를 위해 단일 이미지를 사용하는 새로운 personalization 기법인 Image Inversion을 도입하였다.
1. Edge Conditioning

본 논문에서는 텍스처링을 위해 강력한 컨디셔닝 신호인 edge를 채택하는 것을 제안하였다. 깊이 정보와 비교했을 때, edge는 텍스처가 없는 3D 메쉬의 디테일을 더 잘 표현할 수 있으며, diffusion model에 대한 더 강력한 컨디셔닝 신호 역할을 한다. 이를 통해 깨끗하고 선명하며 3D 모델의 geometry와 semantic 특성에 더 가깝게 정렬되는 텍스처를 생성할 수 있다. Depth map은 일반적으로 매끄럽고 edge를 통해 명확하게 보이는 많은 디테일들이 거의 보이지 않는다. 이러한 현상은 텍스처링이 된 뷰에서도 동일하게 나타난다.
본 논문에서는 connected component (CC), 깊이, normal와 같은 다양한 기하학적 속성을 활용하여 조건부 처리를 위한 풍부한 edge map을 추출하였다. CC에서 edge를 추출하기 위해 먼저 메쉬의 모든 CC를 식별하고 각 CC에 임의의 색상을 할당한다. 이렇게 임의의 색상이 지정된 메쉬를 원하는 시점에서 렌더링하여 RGB 이미지를 생성하고, 이 이미지를 Canny edge detector에 입력하여 edge를 추출한다. 그러나 이러한 랜덤 색상 할당 과정에서 인접한 CC에 유사하거나 동일한 색상이 할당될 수 있어 CC 간의 edge 추출이 어려워진다. 이를 해결하기 위해 CC에 서로 다른 임의의 색상을 할당하여 위의 과정을 여러 번 반복하고, 각 반복에서 추출된 모든 edge를 합집합한다.
깊이와 normal에서 edge를 추출하기 위해 먼저 원하는 시점에서 메쉬의 깊이/normal을 렌더링하고 값을 정규화한다. 이렇게 정규화된 depth map과 normal map을 Canny edge detector에 입력하여 edge를 추출한다. 최종 edge map인 \(\textbf{I}_\textrm{edge}\)는 입력 메쉬의 다양한 기하학적 속성에서 추출된 모든 edge를 합친 것으로 계산된다.
\(\textbf{I}_\textrm{edge}\)는 사전 학습된 Canny ControlNet에 입력되어 feature \(\textbf{f}_\textrm{geo}\)를 생성하고, 이 \(\textbf{f}_\textrm{geo}\)는 SD 모델에 입력되어 텍스처링된 뷰를 생성한다. 각 기하학적 속성을 여러 개의 ControlNet을 사용하여 개별적으로 통합할 수도 있지만, 세 가지 주요 단점이 있다.
- CC에 대한 사전 학습된 ControlNet 모델이 없다.
- 여러 개의 ControlNet을 사용하면 텍스처링 프로세스가 느려진다.
- 서로 다른 입력을 가진 여러 개의 ControlNet을 사용하면 동일한 영역에 출력을 적용하려는 여러 모델이 경쟁하게 되어 최종 결과물이 저하될 수 있다.
2. Image Conditioning & Image Inversion
입력 텍스처 이미지 \(\textbf{I}_\textrm{tex}\)에 대한 diffusion model의 컨디셔닝를 위해, 추가적인 학습이나 최적화 없이 단일 이미지를 입력 프롬프트로 사용할 수 있도록 하는 IP-Adapter를 사용한다. IP-Adapter는 먼저 이미지 토큰 \(\textbf{f}_\textrm{tex}\)를 추출하고, 이 토큰은 cross-attention layer를 사용하여 SD의 U-Net에 통합된다.
Image Inversion
사전 학습된 IP-Adapter는 입력 이미지에 작고 반복되지 않는 디자인이나 패턴이 있을 때 텍스처를 캡처하는 과정에서 세밀한 디테일을 놓치는 경우가 있다. 본 논문에서는 Image Inversion을 도입하여 이 문제를 완화하였다. Image Inversion은 하나의 이미지를 사용하여 단일 개념에 맞게 사전 학습된 SD 모델을 IP-Adapter로 빠르게 personalization하는 새로운 접근 방식이다. Textual Inversion은 텍스트 토큰을 직접 학습하거나 텍스트 토큰을 생성하는 네트워크를 학습하지만, IP-Adapter에서는 이것이 불가능하다. 이 문제를 해결하기 위해, personalization을 위한 텍스처 이미지 \(\textbf{I}_\textrm{tex}\)를 사용하여 IP-Adapter의 projection network \(\mathcal{P}_\textrm{ip}(\cdot)\)와 SD의 U-Net \(\mathcal{U}(\cdot)\)를 fine-tuning한다.
\[\begin{equation} \textbf{f}_\textrm{tex} = \mathcal{P}_\textrm{ip} (C_\textrm{img} (\textbf{I}_\textrm{tex})) \\ \mathcal{L} = \mathbb{E}_{z_t, t, \epsilon, p, \textbf{I}_\textrm{tex}} \left[ \| \mathcal{U} (z_t, t, \textbf{f}_\textrm{txt}, \textbf{f}_\textrm{tex}) - \epsilon \|_2^2 \right] \end{equation}\]Overfitting을 방지하기 위해 personalization 과정에서 텍스처 이미지에 random flip, random resize, random rotation과 같은 augmentation을 적용한다. 이어서, fine-tuning을 하는 동안 입력 이미지를 설명하는 중립적인 텍스트 프롬프트 세트에서 프롬프트를 무작위로 선택한다. Fine-tuning이 완료되면 \(\mathcal{P}_\textrm{ip}(\cdot)\)와 \(\mathcal{U}(\cdot)\)를 고정하고, 이를 메쉬 텍스처링에 사용한다. Image Inversion은 상당히 일반화 가능하며, 여러 이미지를 사용하여 단일 개념에 대한 네트워크를 personalization하는 데에도 사용할 수 있다.
3. Texturing Meshes
ControlNet과 IP-Adapter에서 컨디셔닝 신호인 \(\textbf{f}_\textrm{geo}\)와 \(\textbf{f}_\textrm{tex}\)를 획득한 후, 사전 학습된 네트워크 또는 personalization된 네트워크를 사용하여 텍스처링된 뷰를 생성한다. 텍스처링에는 Text2Tex를 사용하는데, 입력 3D 메쉬에 텍스처링된 뷰를 반복적으로 생성하고 붙여넣는 방식이다. 특히, 이 과정은 최적화가 필요하지 않으며 매우 빠르다. 필요에 따라 최적화 기반 기법을 사용하여 텍스처링의 디테일을 더욱 향상시킬 수 있지만, 이러한 방법은 텍스처 생성에 몇 시간이 걸릴 수 있는 반면, Text2Tex는 최적화가 필요 없어 단 몇 분 만에 완료된다.
Experiments
- 구현 디테일
- base model
- diffusion model: Stable Diffusion v1.5
- edge 컨디셔닝: Canny ControlNet v1.1
- 텍스처 이미지 컨디셔닝: IP-Adapter Plus
- Image Inversion fine-tuning
- learning rate: $1 \times 10^{-6}$
- batch size: 4
- base model
1. Qualitative Comparison
다음은 TEXTure와의 비교 결과이다.

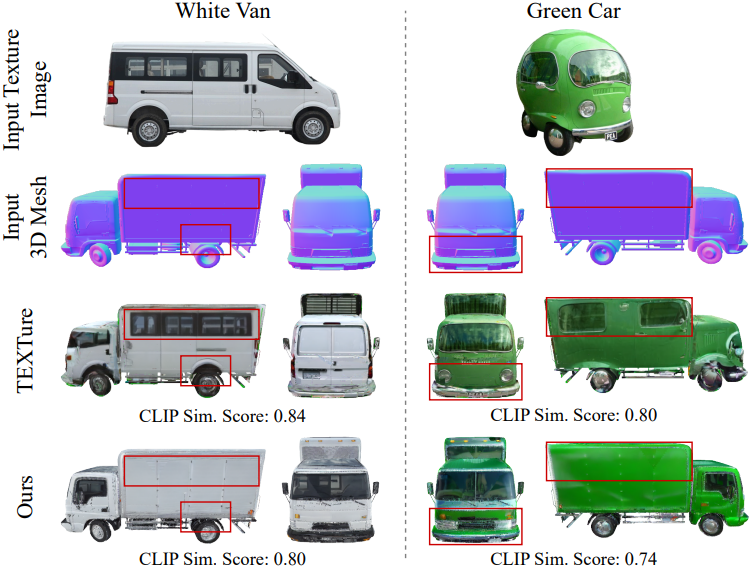
다음은 텍스처 전송 결과이다.


다음은 EASI-Tex로 생성한 텍스처에 대해 최적화 기반 방법과의 비교 결과이다.
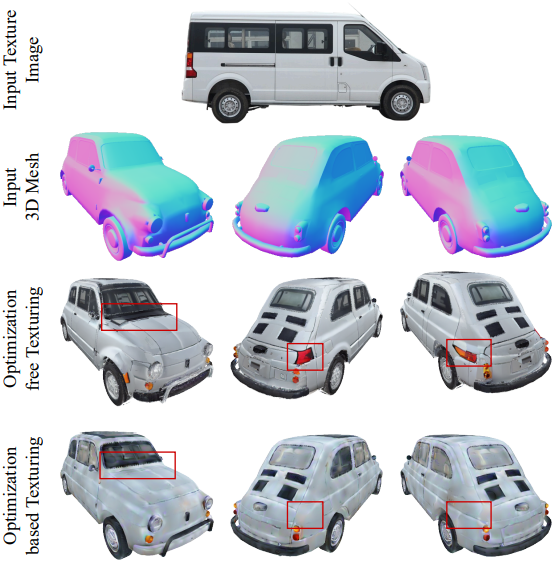
다음은 Latent-NeRF와의 비교 결과이다.

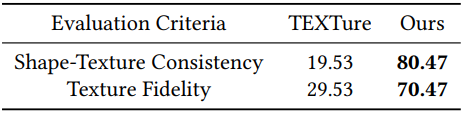
2. Quantitative Comparison
다음은 user study 결과이다.
다음은 텍스처링에 걸린 시간을 비교한 결과이다.

3. Ablation Studies
다음은 Image Inversion 유무에 따른 결과를 비교한 예시이다.

다음은 다양한 기하학적 속성들에 대해 추출된 edge map을 비교한 예시이다.
