[논문리뷰] Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
ICCV 2025. [Paper] [Page]
Edgar Sucar, Zihang Lai, Eldar Insafutdinov, Andrea Vedaldi
Visual Geometry Group (VGG), University of Oxford
20 Mar 2025

Introduction
본 논문에서는 DUSt3R의 단순하고 우아한 접근 방식을 동적 데이터에 적용할 수 있는 가능성을 모색하고자 하였다. 본 논문에서 답하고자 하는 핵심 질문은 point map 표현을 사용하여 동적 3D 재구성 task를 해결할 수 있는지 여부와 그 방법이다. Point map의 핵심은 시점을 포함한 카메라 파라미터에 대한 불변성이다. 장면이 정적일 때는 카메라만 변경되므로 시점 불변성으로 충분하다. 그러나 장면이 동적일 때는 3D 포인트 자체가 시간에 따라 변화한다. DUSt3R에서 정의된 대로 point map을 계산할 수는 있지만, 이 경우 카메라를 고정하더라도 3D 포인트는 계속 움직이기 때문에 출력값이 불변하지 않는다.
본 논문에서는 이러한 요구 사항을 충족하고 DUSt3R를 동적 장면으로 쉽게 확장할 수 있는 Dynamic Point Maps (DPM)을 소개한다. DPM의 핵심은 동적 장면에서의 불변성을 위해서는 카메라 시점과 장면 시간을 모두 고정해야 한다는 점이다. 특정 시점과 타임스탬프를 정의하는 두 장면 이미지 쌍을 생각해 보자. 각 이미지에 대해 각 픽셀을 해당 ‘물리적’ 3D 포인트의 두 가지 버전으로 보내는 point map 쌍을 도입한다. 하나는 첫 번째 이미지의 타임스탬프에 해당하고 다른 하나는 두 번째 이미지의 타임스탬프에 해당한다. DUSt3R와 마찬가지로 모든 3D 포인트는 첫 번째 이미지의 레퍼런스 좌표계를 기준으로 한다.
본 논문에서는 이 디자인이 4D task를 완벽하게 일반화하여 처리할 수 있는 최소한의 디자인이라고 주장한다. 정적 장면의 경우, 두 개의 dual point map이 동일하므로 DUSt3R를 직접적으로 일반화한 것이며, 네 개의 dual point map 중 두 개가 MonST3R와 일치하므로 MonST3R도 일반화한 것이다. 그러나 결정적으로, dual point map은 동적 correspondence뿐만 아니라 장면의 움직임까지 인코딩하므로 MonST3R에서처럼 optical flow와 같은 추가 데이터 처리가 필요하지 않다.
특히, 각 물리적 포인트가 두 시점에서 모두 재구성되므로 scene flow와 motion segmentation을 즉시 추론하고 이 정보를 사용하여 rigid object의 움직임을 추적할 수 있다. 또한, 서로 다른 카메라의 물리적 포인트가 동일한 시공간 레퍼런스 프레임에 존재하므로 시점 변화(시점 고정)와 장면 움직임(시간 고정)의 영향을 제거하여 시점 간 매칭이 매우 간단하다. 이러한 특성 덕분에 장면의 움직임에도 불구하고 포인트 클라우드를 융합할 수 있다.
Method

1. Point Maps
3D로 재구성하고자 하는 장면을 담은 이미지를 $I$라고 하자. 이 문제는 각 픽셀 $\textbf{u}$를 카메라의 레퍼런스 좌표계 $\pi$에서 표현된 해당 장면 포인트 \(\textbf{p} = P(\textbf{u}) \in \mathbb{R}^3\)에 연결하는 point map $P$를 예측하는 문제라고 할 수 있다. 따라서 point map은 depth map과 유사하지만 훨씬 더 많은 정보를 포함한다. 실제로 카메라의 intrinsic이 주어졌을 때만 depth map으로부터 point map을 복원할 수 있다. 반대로, point map에 대한 정보를 알면 카메라의 intrinsic을 추론할 수 있다.
다음으로, 서로 다른 시점 \(\pi_1\)과 \(\pi_2\)를 가진 두 대의 카메라로 촬영한 두 이미지 $I_1$과 $I_2$, 그리고 이에 대응하는 point map $P_1$과 $P_2$를 생각해 보자. DUSt3R는 두 point map 모두 첫 번째 이미지와 동일한 레퍼런스 좌표계로 표현되는 모델을 제안했다. 이를 \(P_1 (\pi_1)\)과 \(P_2 (\pi_1)\)로 표기하자. 이러한 간단한 변화는 point map이 시점에 관계없이 일정하다는 것을 의미하므로 매우 중요한 의미를 갖는다. 즉, \(\textbf{u}_1\)과 \(\textbf{u}_2\)가 동일한 3D 포인트에 대응하는 두 픽셀이라면
\[\begin{equation} P_1 (\pi_1) (\textbf{u}_1) = P_2 (\pi_1) (\textbf{u}_2) \end{equation}\]가 성립한다.
DUSt3R가 지적했듯이, 이러한 불변성은 카메라 extrinsic 추정, 이미지 간 point correspondence 설정, 포인트 클라우드 정렬 및 융합 등과 같은 여러 핵심 3D task를 해결하는 데 충분하다. 위에서 언급했듯이, 이는 또한 카메라 intrinsic과 depth map을 추론하는 데에도 도움이 된다. 따라서 DUSt3R의 아이디어는 두 이미지로부터 point map을 예측할 수 있는 신경망 $\Phi$를 학습하는 것이다.
\[\begin{equation} (P_1 (\pi_1), P_2 (\pi_1)) = \Phi(I_1, I_2) \end{equation}\]DUSt3R의 가장 큰 한계는 동적인 장면을 처리할 수 없다는 점이다.
2. Dynamic point maps
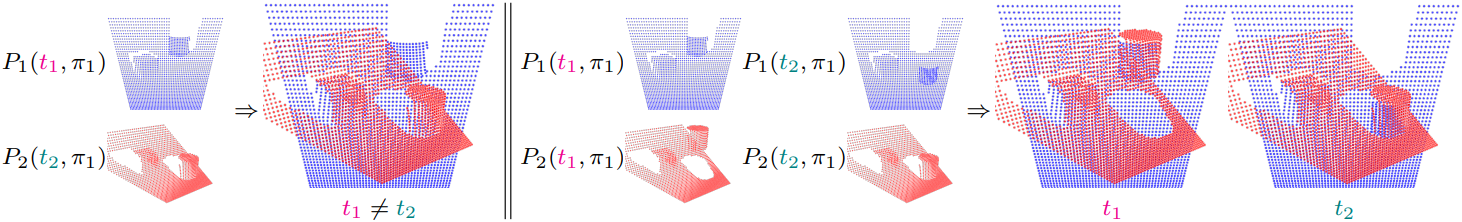
서로 다른 두 시간 $t_1$과 $t_2$에 촬영된 두 이미지 $I_1$과 $I_2$를 생각해 보자. Point map \(P_1 (\pi_1)\)과 \(P_2 (\pi_1)\)을 고려하면 표현이 더 이상 불변하지 않기 때문에 문제가 발생한다. 실제로 두 point map은 동일한 레퍼런스 좌표계 \(\pi_1\)에 대해 정의되지만, 3D 포인트 자체는 시간에 따라 움직이므로 일반적으로 \(P_1 (\pi_1) (\textbf{u}_1) \ne P_2 (\pi_1) (\textbf{u}_2)\)이다. 그렇기 때문에 MonST3R는 추가적인 이미지 매칭 네트워크를 사용한다.
시점뿐만 아니라 시간까지 제어하여 point map \(P_1 (t_1, \pi_1)\)과 \(P_2 (t_1, \pi_1)\)을 추정함으로써 불변성을 복원할 수 있다. 이 표기법은 두 point map의 3D 포인트들이 첫 번째 카메라와 동일한 레퍼런스 좌표계 \(\pi_1\)과 시간 $t_1$을 기준으로 한다는 것을 의미하며, 이를 통해 시점 변화와 장면 모션을 모두 되돌릴 수 있다. 이렇게 하면
\[\begin{equation} P_1 (t_1, \pi_1) (\textbf{u}_1) = P_2 (t_1, \pi_1) (\textbf{u}_2) \end{equation}\]라는 불변성 속성을 다시 확립할 수 있다. 그러나 장면 모션을 되돌리면 움직임 분석에 필수적인 장면 모션 추정 능력을 잃게 된다.
따라서 본 논문에서는 Dynamic Point Maps (DPM)이라는 개념을 도입하여 해결책을 제시하였다. DPM이란 각 이미지에 대해 두 시점 $(t_1, t_2)$의 점을 나타내는 point map 쌍을 예측하는 것을 의미한다. 이미지 $I_1$은 point map 쌍 \(P_1 (t_1, \pi_1)\)과 \(P_1 (t_2, \pi_1)\)에, 이미지 $I_2$는 point map 쌍 \(P_2 (t_1, \pi_1)\)과 \(P_2 (t_2, \pi_1)\)에 대응된다.
모든 point map은 첫 번째 카메라의 동일한 레퍼런스 좌표계 \(\pi_1\)으로 표현된다. 동일한 인자를 가진 쌍은 동일한 시공간 레퍼런스 좌표계를 공유하므로 불변하다. 예를 들어, \(P_1 (t_1, \pi_1)\)과 \(P_2 (t_1, \pi_1)\)의 3D 포인트를 매칭하여 두 이미지 간의 correspondence를 설정할 수 있다. 동시에, \(P_1 (t_2, \pi_1) - P_1 (t_1, \pi_1)\)를 계산하는 것만으로 scene flow를 간단하게 복원할 수 있다.
DUSt3R가 정적 장면을 위한 강력한 표현 방식인 것처럼, DPM은 동적 장면을 위한 강력한 표현 방식이다. DPM은 정적 장면에서 다룰 수 있는 모든 task를 포괄할 뿐만 아니라, 4D 재구성에 특화된 여러 task도 해결할 수 있으며, rigid body motion 추정과 같은 더 많은 task에도 도움을 준다.
Dynamic DUSt3R
DUSt3R는 이미지 $I_1$과 $I_2$를 한 쌍의 point map으로 매핑하는 네트워크 $\Phi$를 학습시킨다. 저자들은 적절한 head를 추가하여 이미지당 3개가 아닌 6개의 채널을 출력하도록 이 네트워크를 확장하여 각 이미지가 두 개의 맵으로 매핑되도록 하였다. 이는 또한 다음과 같은 함수로도 볼 수 있다.
\[\begin{equation} \{P_i (t_j, \pi_1)\}_{i, j \in \{1, 2\}} = \Phi (I_1, I_2) \end{equation}\]따라서 이미지 $i = 1, 2$와 시간 $j = 1, 2$ 각각에 대해 두 개씩, 총 네 개의 point map이 추정된다. 모든 point map은 첫 번째 카메라의 레퍼런스 좌표계 \(\pi_1\)을 기준으로 한다.
3. Training formulation
모델 $\Phi$를 학습시키기 위해서는 DPM이 포함된 동영상 시퀀스가 필요하다. 즉, 학습 데이터 $\mathcal{D}$는 튜플
\[\begin{equation} (I_1, I_2, P_1(t_1, \pi_1), P_1(t_2, \pi_1), P_2(t_1, \pi_1), P_2(t_2, \pi_1)) \end{equation}\]의 모음이다. 이러한 데이터를 얻기 위해 저자들은 합성 데이터와 실제 데이터를 혼합하여 사용하였다. 합성 데이터를 사용하면 장면의 동적 요소로 인한 변형을 포함하여 장면의 geometry에 대한 완벽한 정보를 얻을 수 있다. 이를 통해 이미지 $I_1$의 각 픽셀 $\textbf{u}$에 해당하는 3D 포인트 \(\textbf{p}(t_1, \pi_1)\)을 결정할 수 있다. 카메라 모션을 알고 있으므로 \(\textbf{p}(t_1, \pi_2)\)를 복원할 수 있다. 장면의 변형을 알고 있으므로 이미지 $I_2$에 대해 \(\textbf{p}(t_2, \pi_1)\)과 \(\textbf{p}(t_2, \pi_2)\)도 복원할 수 있다.
Training loss
3D 장면의 크기는 여러 시점에서 고유하게 결정될 수 없다는 점에 유의해야 한다. 따라서 예측 결과가 scaling factor까지는 미정인 상태로 결정되도록 완화한다. $P \in \mathbb{R}^{3 \times HW}$를 GT 포인트 클라우드라고 하고, $\hat{P}$를 그에 대한 예측 포인트 클라우드라고 하면, per-pixel regression loss는 다음과 같이 정의된다.
\[\begin{equation} L_\textrm{reg} (\hat{P}, P, i) = \left\| \frac{\hat{P}_{:,i}}{\frac{1}{HW} \sum_{j=1}^{HW} \| \hat{P}_{:,j} \|} - \frac{P_{:,i}}{\frac{1}{HW} \sum_{j=1}^{HW} \| P_{:,j} \|} \right\| \end{equation}\]이는 포인트들이 카메라 중 하나의 레퍼런스 좌표계에서 표현되기 때문에 타당하다. 전체 loss는 신뢰도를 고려하여 다음과 같이 계산된다.
\[\begin{equation} L_\textrm{conf} (\hat{P}, P) = \frac{1}{HW} \sum_{i=1}^{HW} C_i L_\textrm{reg} (\hat{P}, P, i) - \alpha \log C_i \end{equation}\]네트워크 $\Phi$는 네 개의 개별 포인트 클라우드를 예측한다. 단순화를 위해 이들을 $P$와 $\hat{P}$라는 포인트 클라우드로 쌓고 \(L_\textrm{conf} (\hat{P}, P)\)를 최소화한다. 모든 포인트 클라우드가 동일한 레퍼런스 좌표계 \(\pi_1\)에서 정의되므로 이는 타당하다.
Experiments
1. Depth prediction
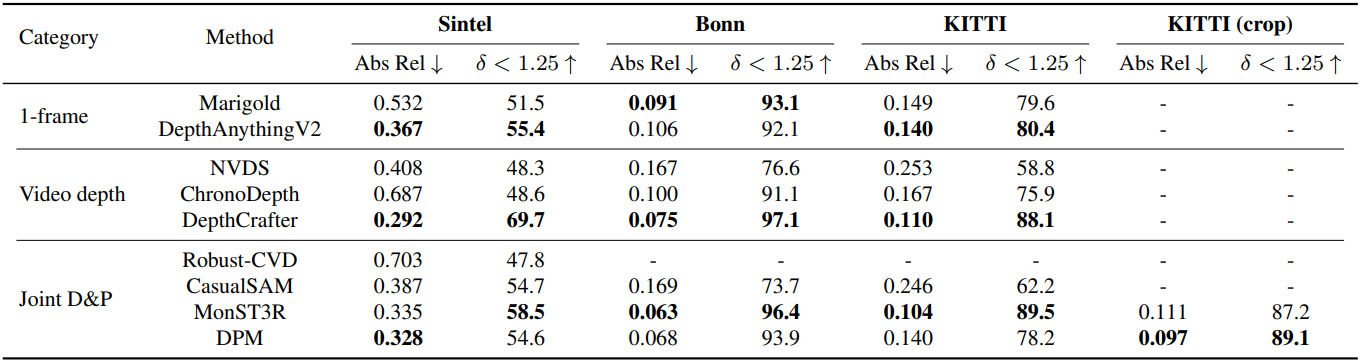
다음은 2-view에 대한 깊이 추정 결과이다.

다음은 동영상 깊이 추정 결과이다.
2. Dynamic reconstruction
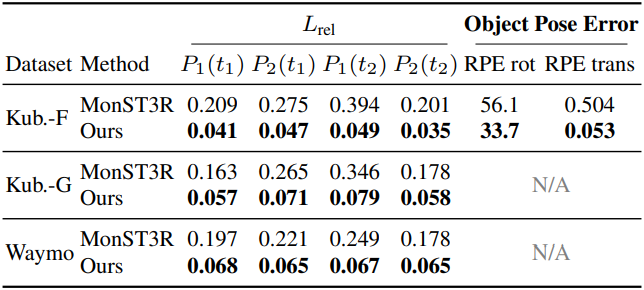
다음은 동적 재구성 결과를 비교한 것이다.
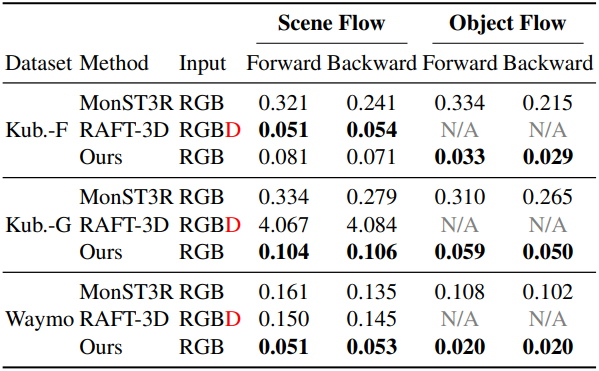
다음은 scene flow와 object flow를 3D End-Point Error (EPE)로 비교한 결과이다.
다음은 scene flow 추정 결과를 시각화한 것이다.

3. Downstream Applications
다음은 motion segmentation 예시이다.

다음은 point correspondence 추정 예시이다.

다음은 카메라 추적 예시이다.

다음은 rigid object motion 추정 예시이다.
