[논문리뷰] DuDGAN: Improving Class-Conditional GANs via Dual-Diffusion
arXiv 2023. [Paper]
Taesun Yeom, Minhyeok Lee
Chung-Ang University
24 May 2023
Introduction
일반적으로 GAN을 사용한 이미지 생성은 unconditional 이미지 생성과 조건부 이미지 생성의 두 가지 카테고리로 분류할 수 있다. Unconditional 이미지 생성에는 추가 정보가 필요하지 않지만 조건부 접근 방식에는 특정 이미지 또는 클래스 레이블과 같은 추가 입력이 필요하다. 대부분의 조건부 GAN 모델은 학습 과정에서 보조 supervision을 통해 출력 이미지를 제어하는 것을 목표로 한다. 따라서 생성된 이미지의 품질을 향상시키기 위해 많은 연구가 수행되었다. 지금까지 달성한 주목할만한 결과에도 불구하고 조건부 이미지 생성은 더 작은 클래스 내 데이터 분포에 대한 학습의 필요성으로 인해 여전히 더 어렵다. 또한 이러한 방법은 안정적인 학습을 보장하기 위해 방대한 레이블이 지정된 데이터셋과 많은 iteration의 필요성으로 인해 방해를 받는다.
그럼에도 불구하고 대규모 클래스별 데이터셋을 수집하고 큐레이팅하는 프로세스는 노동 집약적이고 시간 소모적이다. 또한 조건부 GAN은 학습 단계에서 mode collapse와 gradient explosion 문제와 같은 몇 가지 문제에 자주 직면한다. 결과적으로 제한된 데이터로 조건부 GAN을 학습하는 데 적합한 기술을 탐색하는 것이 중요하다.
일부 데이터 효율적인 GAN 학습 방법이 제안되었지만 이러한 접근 방식은 클래스 레이블이 지정된 이미지를 사용하는 대신 unconditional한 데이터 영역 내에서 학습에 주로 중점을 둔다. 실제로 일부 최근 연구는 작은 데이터셋으로 조건부 이미지 생성을 향상시키는 것을 목표로 했다. 예를 들어, Transitional-CGAN은 조건에 의한 mode collapse를 해결하기 위해 unconditional 및 조건부 학습을 결합하는 새로운 학습 전략을 도입했다. 그러나 이 방법은 주로 학습 초기에 상태에 대한 supervision을 줄이는 데 집중하므로 학습 후반에 mode collapse를 방지하는 효과적인 솔루션이 아닐 수 있다. 또한 이 접근 방식은 반복 효율성 측면에서 효율적이지 않다.
이러한 문제에 대응하여 iteration 효율적인 학습에 탁월한 클래스 조건부 이미지 생성을 위한 강력한 방법인 DuDGAN을 제시한다. DuDGAN은 generator, discriminator, classifier의 세 가지 고유한 네트워크로 구성된다. 본 논문의 목표는 classifier가 diffusion 기반 noise 주입 프로세스를 통합하면서 학습 중에 클래스 조건부 정보를 학습하고 출력하는 것이다. 동시에 discriminator는 이미지가 진짜인지 가짜인지 식별하기 위해 classifier로부터 사전 지식을 얻는다.
Classifier의 출력은 contrastive loss를 계산하기 위한 고차원 클래스 정보와 classification loss를 위한 클래스 차원 로짓의 두 가지 유형으로 구성된다. 학습 프로세스 전반에 걸쳐 각 네트워크의 overfitting 정도에 따라 discriminator와 classifier 모두에 대해 적절한 diffusion 강도를 사용한다. 결과적으로 본 논문의 방법은 클래스 내 변동이 높은 이미지를 생성하고 mode collapse를 효과적으로 방지한다.
Method
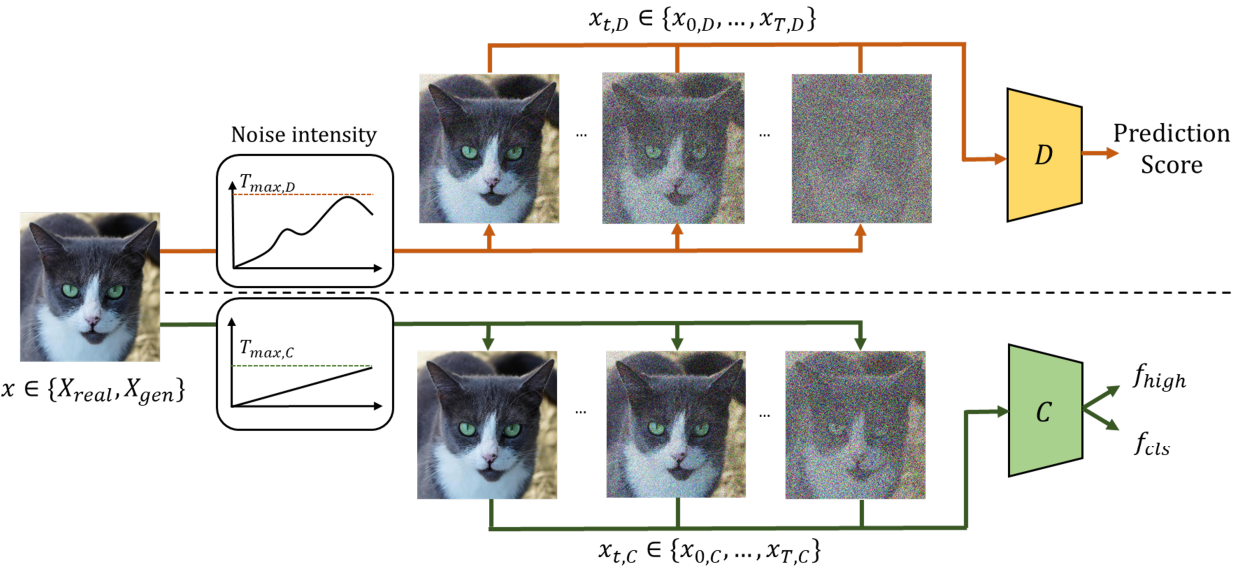
1. Noise injection through forward diffusion process
클래스 조건부 GAN은 실제 데이터 분포 $p_x$로 학습하여 고품질의 사진과 같은 조건부 샘플을 생성하는 동시에 $p_x$의 부분집합인 클래스별 분포 $p_{x \vert c}$에 대한 mode를 예측하는 것이 목표이다. 이 과정에서 Gaussian noise는 forward diffusion chain을 사용하여 discriminator와 classifier의 입력 모두에 주입된다. Forward Markov chain을 통한 임의의 noise 샘플 \(x_j \in \{x_0, \cdots, x_T\}\)의 noise 주입 프로세스에서 파생된 분포 구성 요소는 다음과 같이 표현할 수 있다.
\[\begin{equation} F_t (x_j \vert x_0) = \mathcal{N} (x_j; \sqrt{\vphantom{1} \bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) \sigma^2 I) \\ \textrm{where} \quad \bar{\alpha}_t := \prod_{k=1}^t 1 - \beta_k \end{equation}\]또한 reparameterization trick을 적용하여 noisy한 샘플 $x_j$를 원래 데이터와 noise의 선형 조합으로 표현할 수 있다.
\[\begin{equation} x_j (x_0, j) = \sqrt{\vphantom{1} \bar{\alpha}_j} x_0 + \sqrt{1 - \bar{\alpha}_j} \sigma \epsilon \\ \textrm{where} \quad j \in \{0, 1, \cdots, T\} \end{equation}\]불연속한 timestep $t$에서 Gaussian noise는 실제 이미지 또는 생성된 이미지에 주입된다. Timestep이 증가함에 따라 샘플에서 더 많은 정보 손실이 발생한다. 각 분포는 임의의 timestep에 대한 가우시안 혼합 분포를 형성한다.
그러나 본 논문의 방법은 클래스 조건부 이미지를 사용한 학습에 초점을 맞추기 때문에 각 이미지는 최대 timestep $T$와 클래스 $c$에서 혼합 가중치 $w_t$의 합으로 정의되는 조건부 혼합 분포의 영향을 받는다.
\[\begin{equation} F_c (x_j \vert x_0)_{x_0 \sim p_{x \vert c}} := \sum_{t=1}^T \{ w_t \cdot F_t (x_j \vert x_0) \} \end{equation}\]따라서, timestep $t$를 샘플링하여 noisy한 이미지 $x_j$를 샘플링할 수 있다.
2. Additional Classifier for Conditional Image Generation
생성된 이미지의 충실도와 다양성을 달성하기 위해 클래스 조건부 이미지 생성 모델은 전체 분포만큼 광범위한 클래스별 분포를 처리할 수 있어야 한다. 이를 위해서는 클래스 정보를 다루는 추가 네트워크가 필요하다. 본 논문의 방법에는 Gaussian-mixture noise가 있는 실제 이미지 또는 생성된 이미지를 받아 클래스 정보를 출력하는 독립적인 classifier가 포함된다. Classifier 입력은 실제 이미지 또는 생성된 이미지로만 구성되며 클래스 레이블을 포함하지 않는다. 결과적으로 classifier는 학습을 위해 클래스별 이미지로 구성된 제한된 정보 이상의 분포를 예측할 수 있다.
이 절차는 학습 셋에 대한 overfitting을 방지하고 클래스 정보를 광범위하게 학습할 수 있도록 한다. 또한 classifier 출력은 $f_\textrm{high}$와 $f_\textrm{cls}$로 표시되는 2단계 조건 정보로 구성된다. $f_\textrm{high}$는 고주파수 클래스 조건부 feature를 포함하는 고차원 latent 코드로 구성되며, 클래스 로짓인 $f_\textrm{cls}$와 네트워크에서 예측한 클래스는 차원이 클래스 레이블과 동일한 벡터로 구성된다. Classifier에 대한 정확한 학습을 위해 classifier는 generator에서 생성된 이미지가 아닌 실제 이미지로만 학습된다. 임의의 noisy한 이미지 $x_j$를 사용하여 classifier 출력을 다음과 같이 쓸 수 있다.
\[\begin{equation} (f_\textrm{high}, f_\textrm{cls}) = C (x_j) \end{equation}\]3. Dual-Diffusion Process
본 논문의 방법은 독립적인 diffusion 기반 noise 주입 프로세스를 통해 discriminator와 classifier를 동시에 학습하는 것을 목표로 한다. 두 네트워크 모두에 대해 먼저 명확한 샘플을 표시한 다음 noisy한 샘플을 도입하여 discriminator에게 더 어려운 task를 점진적으로 제시하는 절차를 사용한다.
학습 과정에서 실제 이미지와 생성된 이미지를 입력으로 취하여 실제 score를 예측하는 이중 분류 작업을 수행하는 판별자는 미리 정의된 hyperparameter $r_d$를 활용하여 noise 강도를 self-supervise하는 것을 목표로 한다. $r_d$는 discriminator가 학습 셋에 overfitting된 정도를 나타낸다. Noise의 세기가 이산적인 timestep $t$에 의해 결정된다는 점을 고려하면 4의 배수인 iteration $k$의 과정은 다음과 같이 요약된다.
\[\begin{equation} T_{k, D} = T_{k-4, D} + \textrm{sign} (r_d - D_\textrm{target}) \ast \textrm{const.} \end{equation}\]$T_{k,D} \in (0, 1)$은 $k$ iteration에서 noise 주입 프로세스의 최대 강도를 나타내며 $r_d$는 0.6을 사용한다.
Classifier는 입력 이미지에 따라 레이블별로 classification을 수행하는 것을 목표로 한다. Classifier는 독립적인 noise schedule을 갖는 noisy한 샘플을 받는다. Classification을 개선하기 위해 미리 정의된 학습 iteration의 총 수 $k_\textrm{max}$를 나누어 각 iteration에 대한 noise 레벨을 미리 정의한다. 이는 iteration 횟수에 비례하여 원본 이미지에서 noise가 완전히 제거된 이미지까지 noise 강도가 선형적으로 증가하는 것으로 해석할 수 있다. 또한 더 나은 classification을 위해 classifier를 학습할 때 최대 diffusion 강도를 제한한다. 독립적인 classifier의 noise 강도는 다음과 같이 쓸 수 있다.
\[\begin{equation} T_{k, C} = T_{k-4, C} + \frac{4}{k_\textrm{max}}, \quad T_{k, C} \in (0, 0.3) \end{equation}\]Discriminator와 classifier의 diffusion 강도는 iteration 4회마다 업데이트된다.
4. Overall Training with Diffusion
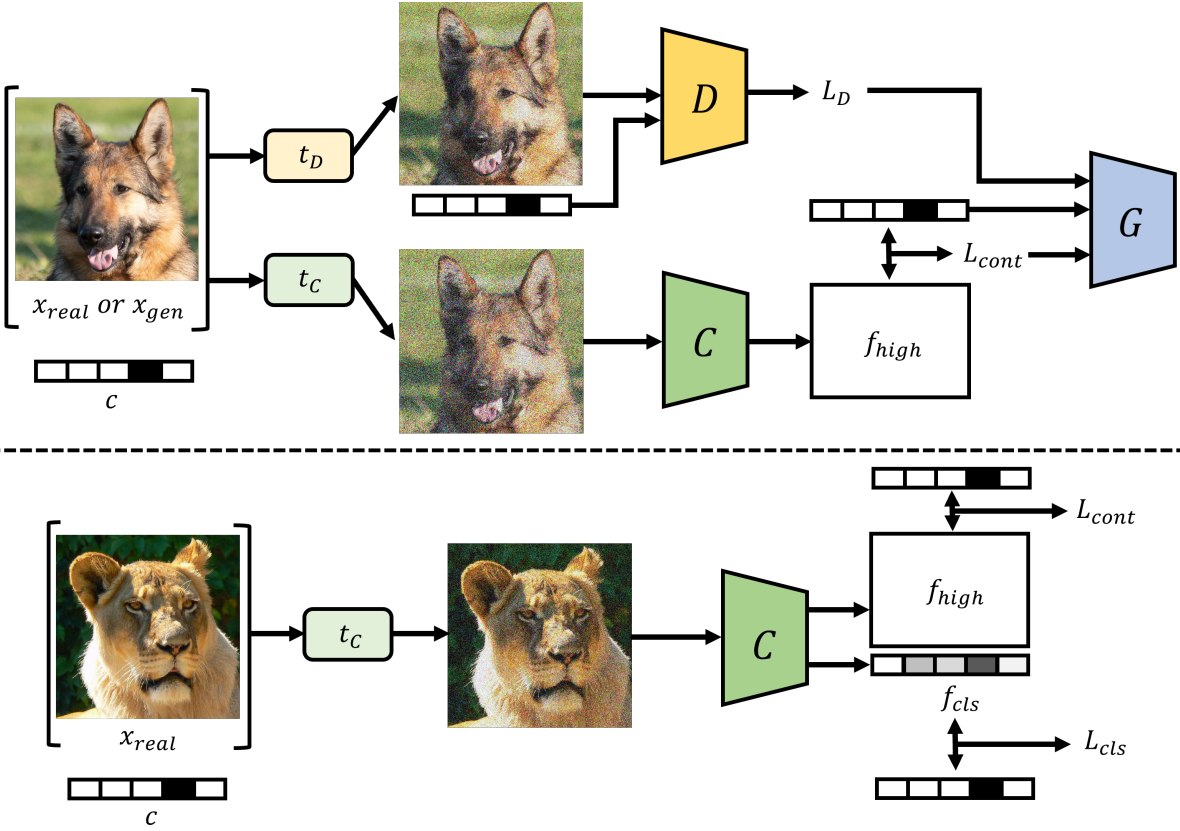
모델의 학습 절차의 개요는 위 그림과 같다. 품질을 향상시키고 클래스 조건부 이미지 생성의 collapse를 방지하기 위해 새로운 형태의 전체 loss function을 제안하였다. Generator, discriminator, classifier의 세 가지 네트워크는 각 목적 함수를 달성하기 위해 loss function과 공동으로 학습된다.
첫째, 실제 이미지로 classifier를 학습하는 동안 \(L_\textrm{cont}^\textrm{real}\)과 \(L_\textrm{cls}^\textrm{real}\)는 각각 $f_\textrm{high}$와 $f_\textrm{cls}$로부터 계산된다. \(L_\textrm{cont}^\textrm{real}\)는 고차원 latent space에서 파생된 supervised contrastive loss를 나타내고 \(L_\textrm{cls}^\textrm{real}\)는 예측 레이블과 주어진 레이블 간의 단순 classification error를 나타낸다.
클래스별 분포 내에서 사실적이고 다양한 이미지를 생성하기 위해 generator는 생성된 이미지에 대해 classifier로부터 추가 정보를 받는다. 따라서 classifier와 유사하게 generator의 loss function은 생성된 이미지의 contrastive loss로 구성되며, 이는 원본 loss \(L_G^\textrm{gen}\)가 남아 있는 동안 generator가 고화질 이미지를 생성하도록 guide한다.
마지막으로, discriminator는 classifier로부터 정보가 포함된 기울기를 수신하지 않으므로 loss function은 non-saturating GAN loss인 baseline model과 동일하게 유지된다. 다음과 같이 loss function이 전체 목적 함수를 구성한다.
\[\begin{aligned} L_C &= \lambda_C \cdot L_\textrm{cont}^\textrm{real} (f_\textrm{high}, c_r) + (1 - \lambda_C) \cdot L_\textrm{cls}^\textrm{real} \\ L_G &= \lambda_G \cdot L_G^\textrm{gen} + (1 - \lambda_G) \cdot L_\textrm{cont}^\textrm{gen} (f_\textrm{high}, c_f) \\ L_D &= L_D^\textrm{NS} \end{aligned}\]여기서 $\lambda_C$와 $\lambda_G$는 classifier와 generator의 학습을 각각 조절하는 hyperparameter이다.
Experiments
- 데이터셋: AFHQ (512$\times$512), Food-101 (128$\times$128), CIFAR-10 (32$\times$32)
- Implementation details
- 빠른 수렴에서 강점을 보인다는 것을 입증하기 위해 모든 모델은 discriminator가 비교 모델보다 60% 작은 1000만 개의 이미지를 처리할 때까지 학습
- Classifier의 경우 클래스로 인한 overfitting을 방지하기 위해 Adam 대신 AdamW를 채택
1. Experimental result
Quantitative result

Qualitative result

2. Ablation Study
다음은 classifier loss $L_C$에 대한 ablation study 결과이다.

다음은 $\lambda_G$에 대한 ablation study 결과이다.

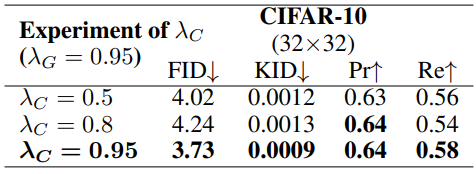
다음은 $\lambda_C$에 대한 ablation study 결과이다.