[논문리뷰] Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer (DualStyleGAN)
CVPR 2022. [Paper] [Page] [Github]
Shuai Yang, Liming Jiang, Ziwei Liu, Chen Change Loy
S-Lab, Nanyang Technological University
24 Mar 2022

Introduction
본 논문에서는 예시 예술적 초상화의 스타일을 대상 얼굴에 전이하는 것을 목표로 하는 예시 기반 초상화 style transfer에 초점을 맞춘다.
이미지 style transfer와 image-to-image 변환을 기반으로 한 자동 초상화 style transfer가 광범위하게 연구되었다. 최근 최첨단 state-of-the-art face generator인 StyleGAN은 transfer learning을 통해 고해상도의 예술적인 초상화 생성에 매우 유망했다. 특히 StyleGAN은 얼굴 도메인에서 예술적 초상화 도메인으로 생성 space를 변환하기 위해 일반적으로 수백 개의 초상화 이미지와 몇 시간의 학습 시간만 있으면 효과적으로 fine-tuning할 수 있다. 이 전략은 이미지 style transfer와 image-to-image 변환 모델에 비해 품질, 이미지 해상도, 데이터 요구 사항 및 효율성에서 월등한 우월성을 보여준다.
이 전략은 효과적이지만 분포의 전체적인 translation만 학습하므로 예시 기반 style transfer를 수행할 수 없다. 고정된 캐리커처 스타일을 생성하기 위해 transfer된 StyleGAN의 경우 웃는 얼굴은 캐리커처 도메인에서 가장 가까운 얼굴, 즉 입이 과장된 초상화로 매핑된다. 사용자는 선호하는 작품을 붙여넣기 위해 얼굴을 축소할 방법이 없다. StyleGAN은 latent swapping을 통해 고유한 예시 기반 단일 도메인 style mixing을 제공하지만, 이러한 단일 도메인 연산은 소스 도메인과 타겟 도메인을 포함하는 style transfer에 대해 직관적이지 않고 무능하다. 이는 이러한 두 도메인 간의 불일치로 인해 특히 도메인별 구조의 경우 style mixing 중에 원치 않는 아티팩트가 발생할 수 있기 때문이다. 그러나 중요한 것은 전문적인 파스티슈(pastiche)가 만화의 추상화와 캐리커처와 같이 아티스트가 얼굴 구조를 처리하는 방법을 모방해야 한다는 것이다.
본 논문은 이러한 문제를 해결하기 위해 예시 기반 초상화 style transfer를 위한 이중 스타일의 효과적인 모델링 및 제어를 실현하는 새로운 DualStyleGAN을 제안한다. DualStyleGAN은 StyleGAN의 intrinsic style path를 유지하여 원래 도메인의 스타일을 제어하는 동시에 extrinsic style path를 모델에 추가하고 확장된 타겟 도메인의 스타일을 제어한다. 이는 자연스럽게 표준 style transfer 패러다임의 content path와 style path에 해당한다. 또한 extrinsic style path는 StyleGAN의 계층적 아키텍처를 상속하여 유연한 multi-level 스타일 조작을 위해 coarse-resolution layer의 구조 스타일과 fine-resolution layer의 색상 스타일을 변조한다.
원래 StyleGAN 아키텍처에 extrinsic style path를 추가하는 것은 사전 학습된 StyleGAN의 생성 space와 동작을 변경할 위험이 있기 때문에 쉽지 않다. 이 문제를 극복하기 위해 extrinsic style path를 설계하고 DualStyleGAN을 학습하는 효과적인 방법과 통찰력을 제시한다.
- 모델 설계: StyleGAN의 fine-tuning 동작에 대한 분석을 기반으로 외부 스타일을 residual 방식으로 convolution layer에 도입할 것을 제안한다. 이는 fine-tuning이 StyleGAN의 convolution layer에 미치는 영향을 잘 추정할 수 있다. 이러한 설계를 통해 DualStyleGAN이 주요 구조 스타일을 효과적으로 변조할 수 있음을 보여준다.
- 모델 학습: DualStyleGAN이 원활한 transfer learning을 위해 StyleGAN의 생성 space를 유지하도록 extrinsic style path가 먼저 정교하게 초기화되는 새로운 점진적 fine-tuning 방법론을 도입한다. 그런 다음 쉬운 style transfer task로 DualStyleGAN 학습을 시작한 다음 점진적으로 작업 난이도를 증가시켜 생성 space를 타겟 도메인으로 점진적으로 변환한다. 또한 모델이 다양한 스타일을 배우고 mode collapse를 방지하도록 supervision 역할을 하는 얼굴-초상화 쌍을 제공하는 facial destylization 방법을 제시한다.
Portrait Style Transfer via DualStyleGAN

본 논문의 목표는 사전 학습된 StyleGAN을 기반으로 DualStyleGAN을 구축하는 것이다. 이 StyleGAN은 새로운 도메인으로 전송될 수 있고 원래 도메인과 확장된 도메인 모두의 스타일을 특성화할 수 있다. Unconditional한 fine-tuning은 StyleGAN 생성 space를 전체적으로 변환하여 위 그림과 같이 캡처된 스타일의 다양성 loss로 이어진다.
1. Facial Destylization

Facial destylization는 supervision으로서 고정된 얼굴-초상화 쌍을 형성하기 위해 예술적 초상화에서 사실적인 얼굴을 복구하는 것을 목표로 한다. 타겟 도메인의 예술적 초상화가 주어지면 얼굴 도메인에서 합리적인 상대를 찾는 것이 목표이다. 두 도메인의 외모 차이가 클 수 있기 때문에 사실적인 얼굴과 초상화에 대한 fidelity 사이의 균형을 맞추는 것이 쉽지 않다. 이 문제를 해결하기 위해 초상화의 사실성을 점진적으로 향상시키는 multi-level destylization 방법을 제안한다.
Stage I: Latent initialization
예술적 초상화 $S$는 먼저 인코더 $E$에 의해 StyleGAN latent space에 포함된다. 여기서는 pSp 인코더를 사용하고 이를 수정하여 FFHQ 얼굴을 $\mathcal{Z}+$ space에 포함하도록 수정한다. $\mathcal{Z}+$ space는 AgileGAN에서 제안한 것처럼 원래 $\mathcal{W}+$ space보다 얼굴과 무관한 배경 디테일과 왜곡된 모양에 더 robust하다. 재구성된 얼굴 $g(z_e^{+})$의 예시는 위 그림의 (b)에 나와 있으며, $g$는 FFHQ에서 사전 학습된 StyleGAN이고 $z_e^{+} = E(S) \in \mathbb{R}^{18 \times 512}$는 latent code이다. $E$는 실제 얼굴에 대해 학습되었지만 $E(S)$는 인물 사진 $S$의 색상과 구조를 잘 포착한다.
Stage II: Latent optimization
이 이미지를 재구성하기 위해 $g$의 latent code를 최적화하고 이 code를 fine-tuning된 모델 $g’$에 적용하여 얼굴 이미지를 stylize한다. 새로운 정규화 항으로 $S$를 재구성하기 위해 $g′$의 latent $z^{+}$를 최적화하기 위해 reverse step을 수행하고, 결과 $\hat{z}_e^{+}$를 $g$에 적용하여 destylize된 버전을 얻는다.
\[\begin{aligned} \hat{z}_e^{+} = \; & \underset{z^{+}}{\arg \min} \mathcal{L}_\textrm{perc} (g' (z^{+}), S) \\ & + \lambda_\textrm{ID} \mathcal{L}_\textrm{ID} (g' (z^{+}), S) + \| \sigma (z^{+}) \|_1 \end{aligned}\]\(\mathcal{L}_\textrm{perc}\)는 perceptual loss이고 \(\mathcal{L}_\textrm{ID}\)는 얼굴의 ID를 보존하기 위한 identity loss이다. $\sigma (z^{+})$는 $z^{+}$의 서로 다른 18개의 512차원 벡터의 표준 오차이다. \(\lambda_\textrm{ID} = 0.1\)이다.
위 그림의 (f)와 (g)에서와 같이 overfitting을 피하기 위해 $\hat{z}_e^{+}$를 잘 정의된 $\mathcal{Z}$ space로 끌어오도록 정규화 항을 설계하고 최적화 전에 $z^{+}$를 초기화하기 위해 평균 latent code 대신 $z_e^{+}$를 사용한다. 이는 위 그림의 (i)와 (j)에서와 같이 얼굴 구조를 정확하게 맞추는 데 도움이 된다.
Stage III: Image embedding
마지막으로 $g(\hat{z}_e^{+})$를 $z_i^{+} = E(g(\hat{z}_e^{+}))$로 임베딩하여 비현실적인 얼굴 디테일을 추가로 제거한다. $g(z_i^{+})$는 $S$를 모방하기 위해 얼굴 구조를 변형하고 추상화하는 방법에 대한 유효한 supervision을 제공하는 합리적인 얼굴 구조를 갖는다.
2. DualStyleGAN
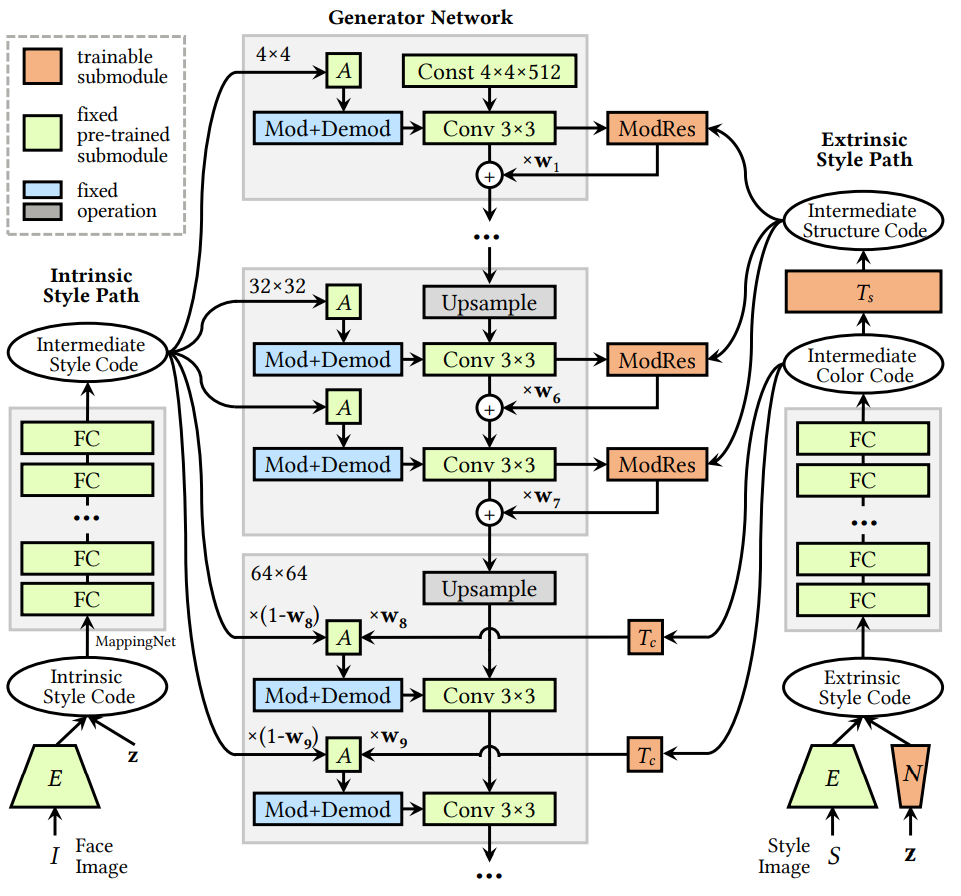
위 그림은 DualStyleGAN $G$의 네트워크 디테일을 보여준다. Intrinsic style path와 generator network는 표준 StyleGAN을 형성하고 fine-tuning 중에 고정된 상태로 유지된다. Intrinsic style path는 단위 Gaussian noise $z \in \mathbb{R}^{1 \times 512}$, 예술적 초상화의 $z_i^{+}$, $E$로 임베딩된 실제 얼굴의 intrinsic style code $z^{+}$가 가능하다.
extrinsic style path는 단순히 예술적 초상화의 $z_e^{+}$를 extrinsic style code로 사용하며, 머리 색깔과 얼굴 모양과 같은 의미 있는 semantic 단서를 포착하는 style code이다. Extrinsic style code는 단위 Gaussian noise를 외부 스타일 분포에 매핑하여 샘플링 네트워크 $N$을 통해 샘플링할 수도 있다. 얼굴 이미지 $I$와 예술적인 초상화 이미지 $S$가 주어지면 예시 기반 style transfer은 $G(E(I), E(S), w)$에 의해 달성된다. 여기서 $w \in \mathbb{R}^{18}$은 두 path의 유연한 스타일 조합을 위한 가중치 벡터이며 기본적으로 1로 설정된다. 예술적 초상화 생성은 $G(z_1, N(z_2), w)$에 의해 실현된다. $w = 0$일 때 $G$는 얼굴 생성을 위한 표준 $g$, 즉 $G(z, \cdot, 0) \sim g(z)$로 저하된다.
StyleGAN은 계층적 스타일 제어를 제공한다. 여기서 fine-resolution layer와 coarse-resolution layer는 낮은 레벨의 색상 스타일과 높은 레벨의 모양 스타일을 각각 모델링하여 extrinsic style path 설계에 영감을 준다.
Color control
Fine-resolution layer (8 ~ 18)에서 extrinsic style path는 StyleGAN과 동일한 전략을 사용한다. 특히, $z_e^{+}$는 매핑 네트워크 $f$, color transform block $T_c$, affine transform block $A$를 통과한다. 결과 style bias는 최종 AdaIN에 대한 가중치 $w$가 있는 intrinsic style path의 style path와 융합된다. $g$와 달리 fully connected layer로 구성된 학습 가능한 $T_c$가 추가되어 도메인별 색상을 특성화한다.
Structure control
Coarse-resolution layer (1~7)에서는 구조적 스타일을 조정하고 도메인별 구조적 스타일을 특성화하기 위해 구조 변환 블록 $T_s$를 추가하며, modulative residual block (ModRes)을 사용한다. ModRes에는 fine-tuning 중 convolution layer의 변경 사항을 시뮬레이션하는 ResBlock과 스타일 조건에 대한 AdaIN block이 포함되어 있다.
Simulating fine-tuning behavior

Toonification의 성공 여부는 fine-tuning 전후의 모델의 의미론적 정렬에 달려 있다. 즉, 두 모델이 latent space를 공유하고 밀접하게 관련된 convolution feature들을 가진다. 또한 이러한 feature의 차이가 원래 feature와 밀접한 관련이 있음을 의미한다.
또한 StyleGAN의 모든 하위 모듈 중에서 fine-tuning 중에 convolution layer가 가장 많이 변경된다. 따라서 다른 모든 하위 모듈은 고정된 상태로 유지하면서 fine-tuning에서 convolution 가중치 행렬의 변경 사항을 시뮬레이션하기 위해 convolution feature에 대한 변경 사항만 학습할 수 있다. StyleGAN에서 feature에 대한 일반적인 조정에는 각각 AdaIN, Diagonal Attention (DAT), ResBlock에 해당하는 채널별, 공간별, 요소별 변조가 포함된다.
저자들은 toy experiment를 수행하고 채널 (위 그림의 (d)) 또는 공간 (위 그림의 (e)) 차원의 변조만으로는 fine-tuning 동작을 근사화하기에 충분하지 않다는 것을 발견했다. ResBlocks는 전체 StyleGAN(위 그림의 (b))을 fine-tuning하여 가장 유사한 결과(위 그림의 (c))를 달성한다. 따라서 residual block을 선택하고 residual path의 convolution layer에 AdaIN을 적용하여 외부 스타일 조건을 제공한다.
3. Progressive Fine-Tuning

DualStyleGAN의 생성 space를 타겟 도메인으로 원활하게 변환하기 위한 점진적인 fine-tuning 방식을 제안한다. 이 계획은 위 그림의 (a)와 같이 난이도를 3단계로 점진적으로 증가시키는 커리큘럼 학습의 아이디어를 차용한다.
Stage I: Color transfer on source domain
DualStyleGAN은 Stage I에서 소스 도메인 내에서 색상 전송을 담당한다. Extrinsic style path의 설계 덕분에 순전히 특정 모델 초기화를 통해 이를 달성할 수 있다. 특히 ModRes의 convolution filter는 무시할 수 있는 residual feature을 생성하기 위해 0에 가까운 값으로 설정되고 color transform block의 fully connected layer는 입력 latent code에 변경 사항이 없음을 의미하는 항등 행렬로 초기화된다. 이를 위해 DualStyleGAN은 StyleGAN의 표준 style mixing 연산을 실행한다. 여기서 fine-resolution layer와 coarse-resolution layer는 각각 intrinsic style path와 extrinsic style path의 latent code를 사용한다. 위 그림의 (b)에서 볼 수 있듯이 초기화된 DualStyleGAN은 사전 학습된 StyleGAN의 생성 space에 여전히 있는 그럴듯한 사람 얼굴을 생성하여 다음 단계에서 원활한 fine-tuning이 가능하다.
Stage II: Structure transfer on source domain
Stage II는 소스 도메인에서 DualStyleGAN을 fine-tuning하여 extrinsic style path를 완전히 학습시켜 중간 레벨 스타일을 캡처하고 전송하는 것을 목표로 한다. StyleGAN의 중간 layer의 style mixing은 메이크업과 같은 소규모 style transfer을 포함하며, 이는 DualStyleGAN에 효과적인 supervision을 제공한다. Stage II에서 랜덤 latent code $z_1$과 $z_2$를 그리고, $G(z_1, \tilde{z}_2, 1)$이 perceptual loss가 있는 style mixing target $g(z_l^{+})$에 근사하도록 한다. 여기서 $\tilde{z}_2$는 \(\{z_2, E(g(z_2))\}\)에서 샘플링되며, $l$은 style mixing이 발생하는 layer이고 $z_l^{+} \in \mathcal{Z}+$는 $l$개의 벡터 $z_1$과 $(18−l)$개의 벡터 $z_2$를 concat한 것이다. 다음 목적 함수로 fine-tuning하는 동안 $l$을 7에서 5로 점차 감소시킨다.
\[\begin{equation} \min_G \max_D \lambda_\textrm{adv} \mathcal{L}_\textrm{adv} + \lambda_\textrm{perc} \mathcal{L}_\textrm{perc} (G (z_1, \tilde{z}_2, 1), g(z_l^{+})) \end{equation}\]여기서 $\mathcal{L}_\textrm{adv}$는 StyleGAN adversarial loss이다. $l$을 줄이면 $g(z_l^{+})$는 $\tilde{z}_2$에서 더 많은 구조 스타일을 갖게 된다. 따라서 extrinsic style path는 색상 외에 더 많은 구조 스타일을 캡처하고 전송하는 방법을 학습한다.
Stage III: Style transfer on target domain
마지막으로 타겟 도메인에서 DualStyleGAN을 fine-tuning한다. $\mathcal{L}_\textrm{perc} (G(z_i^{+}, z_e^{+}, 1), S)$로 $S$를 재구성하기 위해 예술적 초상화 예시 $S$의 style code $z_i^{+}$와 $z_e^{+}$를 원한다. 표준 예시 기반 style transfer 패러다임에서와 같이 임의의 intrinsic style code $z$에 대해 style loss를 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{sty} = \lambda_\textrm{CX} \mathcal{L}_\textrm{CX} (G (z, z_e^{+}, 1), S) + \lambda_\textrm{FM} \mathcal{L}_\textrm{FM} (G (z, z_e^{+}, 1), S) \end{equation}\]여기서 \(\mathcal{L}_\textrm{CX}\)는 contextual loss이고 \(\mathcal{L}_\textrm{FM}\)은 feature matching loss이다. Content loss의 경우 identity loss와 ModRes의 가중치 행렬의 $L_2$ regularization을 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{con} = \lambda_\textrm{ID} \mathcal{L}_\textrm{ID} (G (z, z_e^{+}, 1), g(z)) + \lambda_\textrm{reg} \| W \|_2 \end{equation}\]Stage I의 초기화와 비슷하게 가중치 행렬의 regularization은 residual feature과 0에 가깝도록 만들며, 원래의 고유 얼굴 구조를 보존하고 overfitting을 막는다. 전체 목적 함수는 다음과 같다.
\[\begin{equation} \min_G \max_D \lambda_\textrm{adv} \mathcal{L}_\textrm{adv} + \lambda_\textrm{perc} \mathcal{L}_\textrm{perc} + \mathcal{L}_\textrm{sty} + \mathcal{L}_\textrm{con} \end{equation}\]4. Latent Optimization and Sampling
Latent optimization

매우 다양한 스타일을 완벽하게 캡처하기는 어렵다. 이 문제를 해결하기 위해 DualStyleGAN을 수정하고 각각의 extrinsic style code를 해당 ground truth $S$에 맞게 최적화한다. 최적화는 이미지를 latent space에 삽입하는 프로세스를 따르고 perceptual loss와 contextual loss를 최소화한다. 위 그림에서 볼 수 있듯이 latent 최적화를 통해 색상이 잘 정제되었다.
Latent sampling
임의의 외부 스타일을 샘플링하기 위해 샘플링 네트워크 $N$을 학습시켜 최대 likelihood 기준을 사용하여 단위 Gaussian noise를 최적화된 extrinsic style code의 분포에 매핑한다. 구조 ($z_e^{+}$의 처음 7개 행)와 색상 ($z_e^{+}$의 마지막 11개 행)은 DualStyleGAN에서 잘 disentangle되므로 이 두 부분을 별도로 처리한다. 즉, 구조 코드와 색상 코드는 $N$에서 독립적으로 샘플링되고 concat되어 완전한 extrinsic style code를 형성한다.
Experiments
- 데이터셋: WebCaricature, Danbooru Portraits, CelebA-HQ
- Implementation details
- NVIDIA Tesla V100 GPU 8개로 fine-tuning (각 GPU당 batch size 4)
- Stage II
- $\lambda_\textrm{adv} = 0.1$, $\lambda_\textrm{perc} = 0.5$
- $l = 7, 6, 5$에 대하여 각각 300, 300, 3000 iteration으로 학습
- Stage III
- $\lambda_\textrm{adv} = 1$, $\lambda_\textrm{perc} = 1$, $\lambda_\textrm{CX} = 0.25$, $\lambda_\textrm{FM} = 0.25$
- cartoon, caricature, anime에 대하여 $(\lambda_\textrm{ID}, \lambda_\textrm{reg})$를 각각 $(1, 0.015)$, $(4, 0.005)$, $(1, 0.02)$로 설정하고 각각 1400, 1000, 2100 iteration으로 학습
1. Comparison with State-of-the-Art Methods
다음은 예시 기반 초상화 style transfer의 시각적 비교이다.

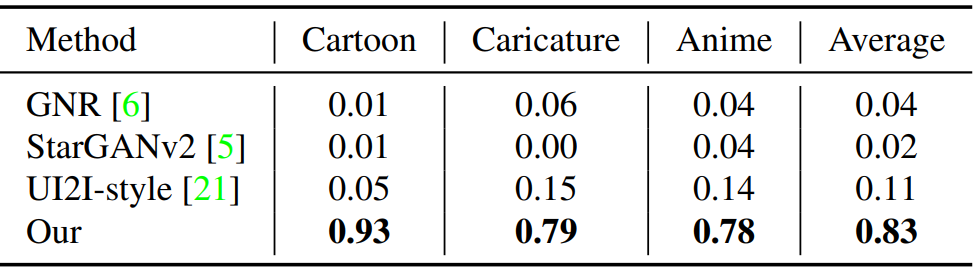
다음은 사용자 선호도 점수를 측정한 표이다.
다음은 StyleCariGAN과 비교한 예시이다.

2. Ablation Study
다음은 얼굴-초상화 supervision (a), 정규화 항 (b), 점진적 transfer learning (c)의 효과를 나타낸 예시이다.

다음은 서로 다른 layer들의 효과를 나타낸 예시이다.

3. Further Analysis
Color and structure preservation
다음 그림은 사진의 색상과 구조가 잘 보존되는 것을 보여준다.

Style blending
다음은 고유 스타일과 외부 스타일을 혼합한 예시이다.

Performance on other styles
다음은 Pixar, Comic, Slam Dunk 스타일에서의 성능을 보여준다. 각각 122, 101, 120개의 이미지로 fine-tuning하였다고 한다.

Performance on unseen style
다음은 보지 못한 스타일에서의 성능을 보여준다.

4. Limitations

위 그림에서는 DualStyleGAN의 세 가지 일반적인 실패 사례를 보여준다.
- 얼굴 특징은 잘 캡처되지만 모자 및 배경 텍스처와 같은 얼굴이 아닌 영역의 디테일은 손실된다.
- 애니메이션 얼굴에는 종종 매우 추상적인 코가 있다. 사진의 색상을 유지하면 코가 눈에 띄지만 애니메이션 스타일에는 부자연스럽다.
- 여전히 데이터 편향 문제를 겪고 있다. 애니메이션 데이터셋은 직모와 앞머리에 대한 강한 편향을 가지고 있어 앞머리가 없는 곱슬머리를 처리하지 못한다. 한편 유난히 큰 눈과 같은 흔하지 않은 스타일은 흉내낼 수 없다. 결과적으로 심각한 데이터 불균형 문제가 있는 task에 DualStyleGAN을 적용하면 과소 표현된 데이터에 대해 만족스럽지 못한 결과를 초래할 수 있다.