[논문리뷰] Dual Recursive Feedback on Generation and Appearance Latents for Pose-Robust Text-to-Image Diffusion
ICCV 2025. [Paper] [Page] [Github]
Jiwon Kim, Pureum Kim, SeonHwa Kim, Soobin Park, Eunju Cha, Kyong Hwan Jin
Korea University | Sookmyung Women’s University
13 Aug 2025
Introduction
Text-to-image (T2I) diffusion model은 생성된 이미지의 공간적 구성을 제어하는 데 한계가 있어 복잡한 구조를 표현하는 데 어려움을 겪는다. 이러한 문제를 해결하기 위해 T2I 모델은 점차 조건부 guidance 기술을 도입하여 원하는 이미지 속성에 대한 더욱 세밀한 제어를 가능하게 했다. 예를 들어, ControlNet은 특정 구조를 활용하여 사용자에게 더욱 정밀한 제어 기능을 제공함으로써 생성된 이미지가 사용자의 의도에 더욱 정확하게 부합하도록 한다. Image-to-image (I2I) translation 방법들은 소스 이미지를 입력으로 받아 텍스트 쿼리에 따라 변환함으로써 생성 기능을 확장하였으며, 원본 이미지의 구조적 또는 맥락적 요소를 활용하기 때문에 T2I보다 더욱 정밀한 제어가 가능하다. 그럼에도 불구하고 신뢰성과 다양성 사이의 trade-off는 여전히 남아 있다.
생성된 이미지에 포함될 구조와 유지될 외형을 모두 반영하는 또 다른 전략은 IP-Adapter나 Ctrl-X와 같이 각 측면에 대한 전용 이미지를 프롬프트로 사용하는 것이다. 사용자가 원하는 구조와 외형을 직접 지정함으로써 이러한 방법은 사용자의 의도를 생성된 결과에 더 잘 통합할 수 있다. 그러나 이러한 기술은 여전히 매번 모델을 재학습해야 하거나 두 이미지 간의 카테고리 유사성에 의존한다는 단점을 가지고 있다. 결과적으로 구조와 외형의 카테고리가 매우 다르거나 구조와 외형 간에 상당한 구조적 불일치가 있는 환경에서는 적절한 이미지를 생성하지 못할 수 있다.
이러한 문제들을 해결하기 위해, 본 논문에서는 극단적인 상황에서도 주어진 구조와 외형을 가진 이미지를 합성하기 위해 score guidance의 유연성을 성공적으로 활용하는 Dual Recursive Feedback (DRF) 모델을 제안하였다. 구조 이미지와 외형 이미지가 입력으로 제공되므로, 추가적인 학습이나 guidance 메커니즘이 필요하지 않다. 외형을 묘사하는 텍스트 조건부 score를 조정하여 결과적인 latent space를 재귀적으로 정제함으로써 사용자의 의도를 정확하게 반영한다. 외형 피드백 덕분에 구조와 외형이 크게 다르더라도 외형 누출 문제를 해결할 수 있다. 또한, 두 이미지를 모두 주입하여 얻은 latent도 사용자의 의도에 맞춰 업데이트되는데, 이를 생성 피드백이라고 한다. 외형 피드백과 생성 피드백을 중간 latent에 재귀적으로 적용함으로써, 최종 출력은 사용자의 의도를 정확하게 반영할 수 있다.
DRF는 다양한 T2I 모델과 호환되며, 품질 측면에서 baseline 모델보다 일관되게 우수한 성능을 보여준다.
Method
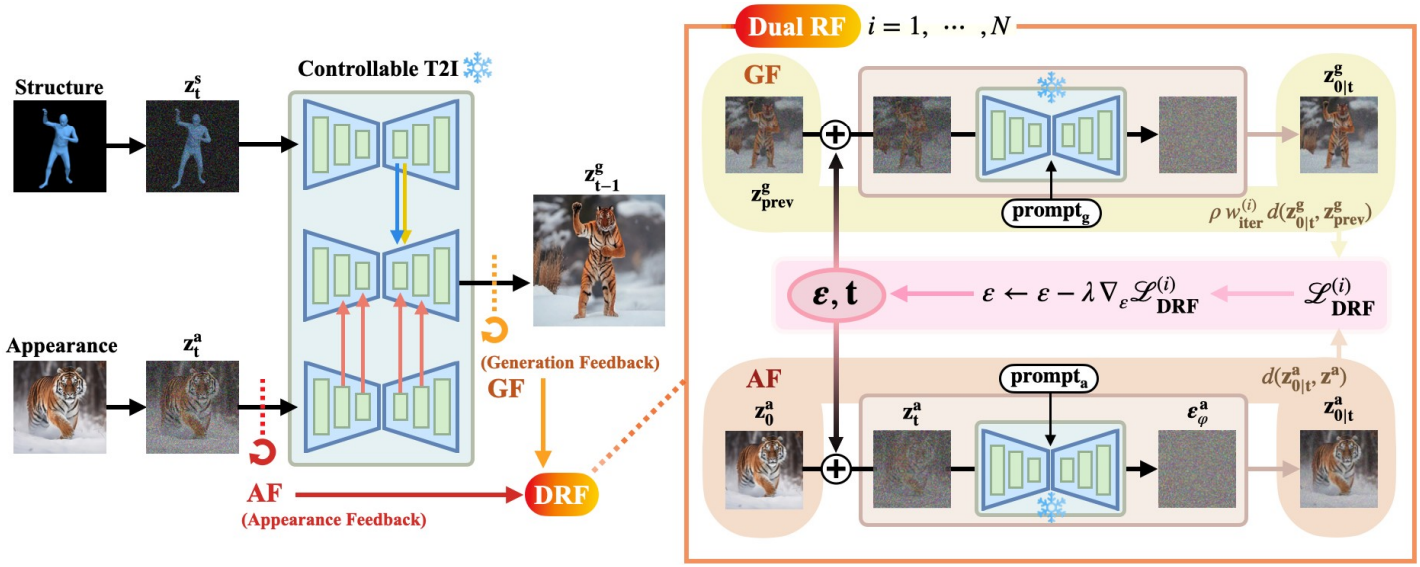
외형 이미지 \(\textbf{I}^a\)와 구조 이미지 \(\textbf{I}^s\)가 제어 가능한 요소로 작용하는 T2I diffusion model에서, DRF는 생성된 이미지 \(\textbf{I}^g\)를 robust하게 변환하면서 \(\textbf{I}^a\)의 특징을 유지하고 \(\textbf{I}^s\)의 구조를 준수한다.
먼저 \(\textbf{I}^a\)와 \(\textbf{I}^s\)를 아무런 guidance 없이 T2I 모델에 주입한 다음, 그 결과로 생성되는 latent 출력 \(\textbf{z}^g\)에 초점을 맞춘다. 구체적으로, \(\textbf{z}^g\)는 \(\textbf{I}^s\)에서 얻은 convolutional feature $f_t^s$, \(\textbf{I}^s\)에 대한 self-attention map $A_t^s$, \(\textbf{I}^a\)에서 얻은 self-attention 기반 appearance latent $h_t^a$를 통합한다.
\[\begin{equation} \textbf{z}_{t-1}^g = \textrm{Ctrl-X} (\textbf{z}_t^g \; \vert \; t, y, f_t^s, A_t^s, h_t^a) \end{equation}\]\(\textbf{I}^a\)와 \(\textbf{I}^s\)가 서로 다른 카테고리에 속하거나 구조적으로 상당한 차이를 보이는 경우, attention map 내에서 외형 정보와 구조 정보를 단순히 분리하는 것만으로는 \(\textbf{I}^a\)와 \(\textbf{I}^s\)의 특징 모두를 정확하게 반영하는 \(\textbf{I}^g\)를 생성하기에 불충분하다. 이러한 한계를 해결하기 위해, 본 논문에서는 생성 프로세스에서 \(\textbf{z}^g\)에 대한 score guidance 방법을 활용하는 것을 제안하였다. 이 기법을 Dual Recursive Feedback (DRF)이라고 부른다.
외형 피드백
FreeControl의 외형 누출 문제와 Ctrl-X에서 지적된 외형 특징의 정렬 불일치를 해결하기 위해, 외형과 관련된 latent에 기반한 gradient를 조사해야 한다. IDS에서 분석된 바와 같이, \(\textbf{z}_t^a\)에서 계산된 텍스트 조건부 score \(\epsilon_\theta^a\)는 \(\textbf{z}^a\)에 대한 gradient로 항상 보장될 수 없으므로 외형의 identity 손실로 이어진다. 따라서 본 논문에서는 고정점 (fixed point) 개념을 사용하여 gradient 업데이트가 \(\textbf{z}^a\) 쪽으로 향하도록 유도하는 방법을 제시하였다.
무작위로 샘플링된 timestep $t \sim \mathcal{U}(0, 1)$을 사용하여 latent를 최적화하는 IDS와 달리, DRF는 timestep $t = 1, \ldots, 0$에 대해 초기 noise \(\textbf{z}_1 \sim \mathcal{N}(0,I)\)로부터 출력을 생성한. 큰 timestep에서 posterior mean \(\textbf{z}_{0 \vert t}^a\)는 \(\textbf{z}_0^a\)에 대한 정보가 부족하기 때문에 \(\textbf{z}_{0 \vert t}^a\)와 \(\textbf{z}_0^a\)의 차이가 증가하여 \(\textbf{z}_0^a\)에 과도한 영향을 미친다. 이러한 과도한 차이를 피하기 위해 수정된 latent \(\tilde{z}_t^a\)를 다음과 같이 계산하도록 forward process를 수정한다.
\[\begin{equation} \tilde{\textbf{z}}_t^a = \sqrt{\frac{\alpha_t}{\alpha_{t-1}}} \textbf{z}_0^a + \sqrt{1 - \frac{\alpha_t}{\alpha_{t-1}}} \epsilon \end{equation}\]Score \(\epsilon_\theta^a = \epsilon_\theta^\omega (\tilde{\textbf{z}}_t^a, y^a, t)\)에서 계산된 \(\textbf{z}_{0 \vert t}^a = \mathbb{E}[\textbf{z}_0 \vert \tilde{\textbf{z}}_t^a]\)와 \(\textbf{z}^a\)의 차이를 최소화하는 loss function을 설계함으로써 외형 정보가 손상되지 않도록 한다.
\[\begin{equation} \mathcal{L}_\textrm{app} = d(\textbf{z}_{0 \vert t}^a, \textbf{z}_0^a) \end{equation}\]수정된 latent에 의해 외형 이미지에 대한 과도한 강조가 완화되기는 하지만, 외형 피드백만을 고려하는 것은 latent가 \(\textbf{I}^g\)에 원활하게 통합되는 것을 방해할 수 있다.
생성 피드백
외형 overfitting 문제를 더욱 효과적으로 해결하기 위해 \(\textbf{z}^g\)에 생성 피드백을 통합한다. 이를 통해 외형 신호의 보다 균형 잡힌 융합이 이루어지고, 궁극적으로 생성 품질이 향상된다. 구체적으로, 피드백은 재귀적인 방식으로 반복적으로 적용되며, 이전 gradient에 의해 업데이트된 score \(\epsilon_\theta^g\)는 이전 recursion의 생성 latent \(\textbf{z}_\textrm{prev}^g\)를 수정한다. \(\textbf{z}_\textrm{prev}^g\)를 또 다른 고정점으로 취급하여 현재 업데이트 방향을 \(\textbf{z}_\textrm{prev}^g\)와 일치시킴으로써 보다 효율적인 이미지 합성이 가능하도록 한다.
출력 피드백에 대한 loss function은 \(\textbf{z}_\textrm{prev}^g\)와 \(\textbf{z}_{0 \vert t}^g\)의 차이를 최소화하도록 다음과 같이 설계되었다.
\[\begin{equation} \mathcal{L}_\textrm{gen} = d(\textbf{z}_{0 \vert t}^g, \textbf{z}_\textrm{prev}^g) \end{equation}\]Dual Recursive Feedback
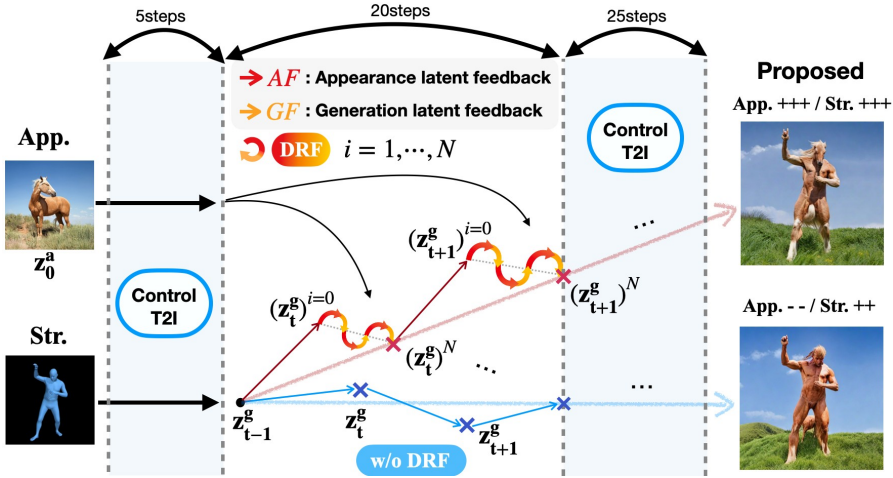
DRF를 구성하기 위해 외형 피드백 loss와 생성 피드백 loss를 결합한다. 초기 단계의 구조 정보를 사용하면 충분한 정보가 포함되지만, 초기 latent \(\textbf{z}_T^g\)를 랜덤 Gaussian noise로 초기화하는 특성상 첫 번째 inference step에서 생성된 이미지의 구조가 \(\textbf{I}^s\)와 일치하지 않을 수 있다.
따라서 저자들은 효율성과 생성 품질을 모두 고려하여 처음 5 step 이후의 중간 20 step에 DRF를 적용했다. 각 단계에서 DRF를 여러 번 반복하면서 \(\textbf{z}_t^g\)는 점진적으로 개선되어 더 많은 피드백을 통합하고 외형 및 구조 제약 조건 모두에 점점 더 잘 부합하게 된다.
외형 피드백과 생성 피드백의 균형을 맞추기 위해, 재귀적 iteration($i$)이 진행됨에 따라 생성 피드백 가중치를 다음과 같이 점진적으로 증폭시킨다.
\[\begin{equation} w_\textrm{iter}^{(i)} = \sqrt{\frac{\exp \left( k \frac{i}{N-1} \right) - 1}{\exp (k) - 1}} \end{equation}\]즉, 외형의 identity가 출력에 제대로 반영될 수 있도록 초기에는 외형 피드백이 더욱 중요하다. Iteration이 증가함에 따라, 사용자의 의도에 더 잘 부합하는 출력을 얻기 위해 생성 피드백이 더욱 중요하게 고려된다. 이를 위해 DRF loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{DRF}^{(i)} \leftarrow d(\textbf{z}_{0 \vert t}^a, \textbf{z}_0^a) + \rho w_\textrm{iter}^{(i)} d(\textbf{z}_{0 \vert t}^g, \textbf{z}_\textrm{prev}^g) \end{equation}\]($\rho$는 hyperparameter)
주입 noise $\epsilon$은 \(\textbf{z}_{t-1}^g\)와 \(\textbf{z}^a\)에 더해져 \(\textbf{z}_t^g\)와 \(\tilde{\textbf{z}}_t^a\)를 얻는데, 이는 \(\textbf{z}_t^g\)와 \(\tilde{\textbf{z}}_t^a\) 사이의 연결 고리로 볼 수 있다. 따라서, 우리는 여러 recursive step을 거쳐 DRF loss를 최소화하는 방향으로 주입 noise $\epsilon$을 업데이트한다.
\[\begin{equation} \epsilon \leftarrow \epsilon - \lambda \nabla_\epsilon \mathcal{L}_\textrm{DRF}^{(i)} \end{equation}\]수정된 noise $\epsilon$을 사용한 위 식을 통해 완전히 정제된 \(\textbf{z}^{g \ast}\)를 얻을 수 있다. 결과적으로, 이 최종 \(\textbf{z}^{g \ast}\)는 외형 이미지의 필수적인 특징을 유지하면서 각 step에서 적절하게 보정되어 구조 또한 보존하므로 두 가지 제약 조건을 모두 만족하는 고품질 이미지를 생성한다.
전체 알고리즘은 아래와 같다.

Experiments
1. Qualitative results
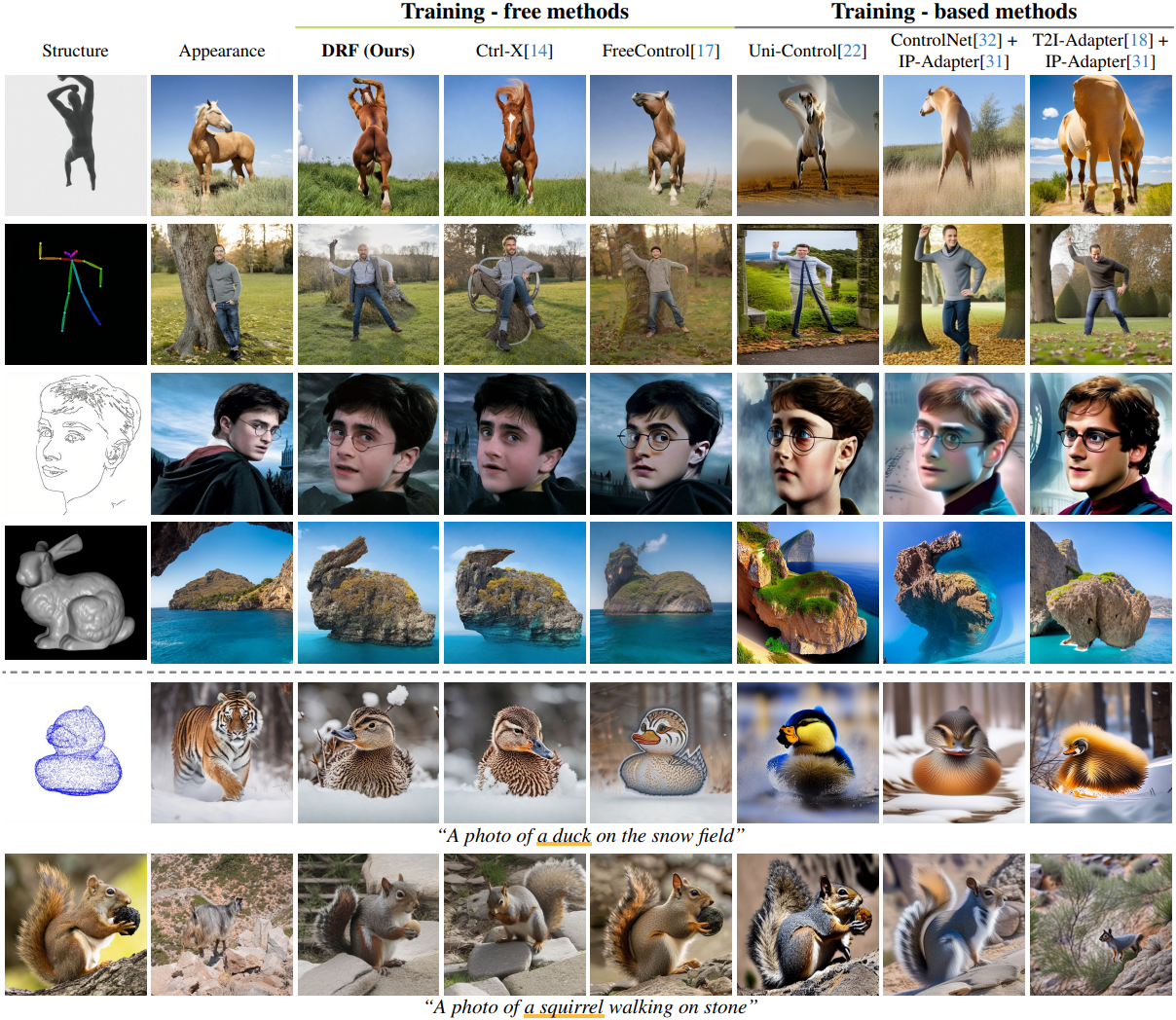
다음은 다양한 구조 이미지에 대한 생성 결과를 비교한 것이다.
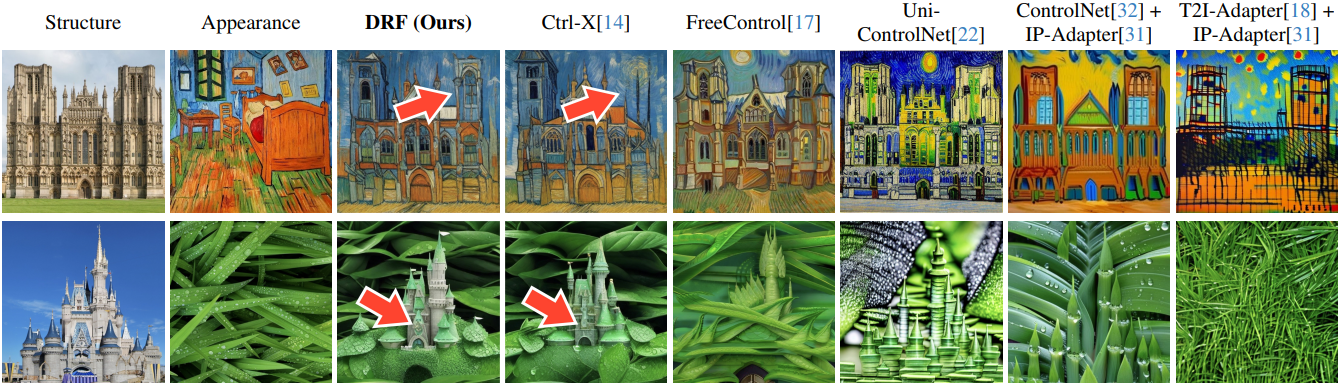
다음은 스타일 이미지에 대한 생성 결과를 비교한 것이다.
다음은 외형 이미지 없이 텍스트 기반으로 생성한 결과이다.

2. Quantitative results
다음은 다른 방법들과 정량적으로 비교한 결과이다.

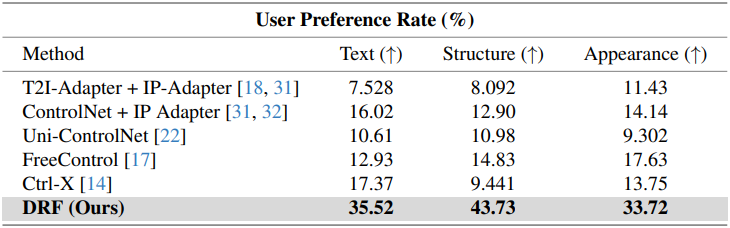
다음은 user study 결과이다.
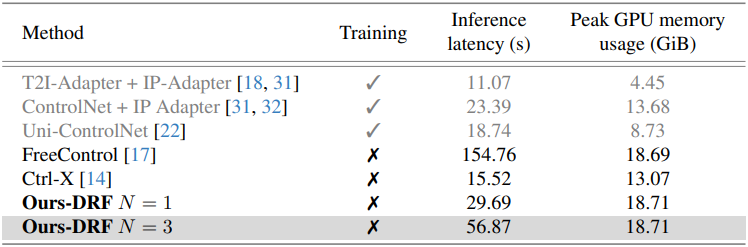
다음은 inference 시간과 GPU 메모리 사용량을 비교한 결과이다.
3. Discussions
다음은 plug-and-play 방식으로 DRF를 기존 T2I 모델에 통합한 결과이다.

다음은 diffusion scheduler에 따른 성능을 비교한 결과이다.

다음은 Stable Diffusion backbone에 따른 성능을 비교한 결과이다.
