[논문리뷰] DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
ICLR 2024. [Paper] [Page] [Github]
Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, Yebin Liu
Tsinghua University | DeepSeek AI
25 Oct 2023

Introduction
2D 생성 모델링의 놀라운 성공은 시각적 콘텐츠를 만드는 방식에 큰 영향을 미쳤다. 3D 생성 모델링은 특정 카테고리에 대해 강력한 결과를 보여주었지만, 광범위한 3D 데이터가 부족하기 때문에 일반적인 3D 객체를 생성하는 것은 여전히 어려운 일이다. 최근 연구들은 사전 학습된 text-to-image (T2I) 생성 모델의 guidance를 활용하고 유망한 결과를 보여주기 위해 노력해 왔다.
3D 생성을 위해 사전 학습된 T2I 모델을 활용한다는 아이디어는 처음에 DreamFusion에서 제안되었다. Score Distillation Sampling (SDS) loss는 3D 모델을 최적화하기 위해 임의의 시점에서의 렌더링을 강력한 T2I diffusion model의 텍스트 조건부 이미지 분포와 일치하도록 한다. DreamFusion은 2D 생성 모델의 상상력을 계승하여 매우 창의적인 3D 에셋을 생성할 수 있다. Over-saturation과 흐릿함 문제를 해결하기 위해 최근 연구들에서는 단계적 최적화 전략을 채택하거나 개선된 2D distillation loss를 제안하여 사실성을 향상시켰다. 그러나 현재 연구들의 대부분은 복잡한 콘텐츠를 합성하는 데 부족하다. 또한, 이 연구들은 개별적으로 그럴듯해 보이는 3D 렌더링을 전체적으로 살펴보면 의미적, 스타일적 불일치가 나타나는 ‘Janus 문제’에 시달리는 경우가 많다.
본 논문에서는 전체적인 3D 일관성을 유지하면서 복잡한 3D 에셋을 생성하는 접근 방식인 DreamCraft3D를 제안하였다. DreamCraft3D는 계층적 생성의 잠재력을 탐구하였다. 저자들은 수작업으로 이루어지는 예술적 과정에서 영감을 얻었다. 예술 분야에서는 추상적 개념을 먼저 2D 초안으로 굳힌 다음, 대략적인 형상을 조각하고, 기하학적 디테일을 다듬고, 충실도가 높은 텍스처를 페인팅하는 작업이 이어진다. 저자들은 비슷한 접근 방식을 채택하여 까다로운 3D 생성을 관리 가능한 단계로 세분화했다. 텍스트 프롬프트에서 생성된 고품질 2D 레퍼런스 이미지부터 시작하여 형상 조각 및 텍스처 부스팅 단계를 통해 이를 3D로 끌어올린다. 이전 접근 방식들과 달리 DreamCraft3D는 각 단계를 신중하게 고려하여 계층 생성의 잠재력을 최대한 활용하여 우수한 품질의 3D 생성을 얻을 수 있다.
형상 조각 단계는 2D 레퍼런스 이미지로부터 타당하고 일관된 3D 형상을 생성하는 것을 목표로 한다. 새로운 뷰에 SDS loss를 사용하고 레퍼런스 뷰에서 photometric loss를 사용하는 것 외에도 기하학적 일관성을 향상하기 위한 여러 전략을 도입하였다. 무엇보다도 시점을 조건으로 하는 이미지 변환 모델인 Zero-1-to-3를 활용하여 레퍼런스 이미지를 기반으로 새로운 뷰의 분포를 모델링한다. 이 뷰 조건부 diffusion model은 다양한 3D 데이터에 대해 학습되므로 2D diffusion prior를 보완하는 풍부한 3D prior를 제공한다. 또한 저자들은 일관성을 더욱 향상시키기 위해서는 샘플링 시간 단계를 어닐링하고 학습 뷰를 점진적으로 확대하는 것이 중요하다는 것을 알았다. 최적화하는 동안 coarse-to-fine 형상 개선을 위해 암시적 표면 표현에서 mesh 표현으로 전환한다. 이러한 기술을 통해 형상 조각 단계에서는 대부분의 기하학적 아티팩트를 효과적으로 억제하면서 날카롭고 디테일한 형상을 생성한다.
저자들은 텍스처를 실질적으로 향상시키기 위해 bootstrapped score distillation을 제안하였다. 제한된 3D로 학습된 기존 뷰 조건부 diffusion model은 최신 2D diffusion model의 충실도를 맞추는 데 어려움을 겪는 경우가 많다. 대신 최적화되는 3D 인스턴스의 멀티뷰 렌더링에 따라 diffusion model을 fine-tuning한다. 이 개인화된 3D-aware 생성 prior는 뷰 일관성을 보장하면서 3D 텍스처를 강화하는 데 중요한 역할을 한다. 중요한 것은 생성적 prior와 3D 표현을 교대로 최적화하면 상호 강화적인 개선이 가능하다는 점이다. Diffusion model은 향상된 멀티뷰 렌더링에 대한 학습을 통해 이점을 얻을 수 있으며, 이는 결국 3D 텍스처 최적화를 위한 우수한 guidance를 제공한다. 고정된 타겟 분포를 추출하는 이전 연구들과 달리 최적화 상태에 따라 점진적으로 진화하는 분포를 학습한다. 이 “부트스트래핑”을 통해 DreamCraft3D는 뷰 일관성을 유지하면서 점점 더 자세한 텍스처를 캡처한다.
DreamCraft3D는 복잡한 기하학적 구조와 360도에서 일관되게 렌더링된 사실적인 텍스처를 갖춘 창의적인 3D 에셋을 생성할 수 있다. 최적화 기반 접근 방식들과 비교하여 DreamCraft3D는 실질적으로 향상된 텍스처와 복잡성을 제공한다. 한편, image-to-3D 기술과 비교했을 때 DreamCraft3D는 360도 렌더링에서 전례 없는 사실적인 렌더링을 생성하는 데 탁월하다. 이러한 결과는 3D 콘텐츠 제작에 있어 새로운 창의적 가능성을 가능하게 하는 DreamCraft3D의 강력한 잠재력을 시사한다.
Preliminaries
DreamFusion은 $\theta$로 parameterize된 3D 표현을 최적화할 떄 사전 학습된 text-to-image diffusion model $\epsilon_\phi$를 이미지 prior로 활용하여 text-to-3D 생성을 하였다. 렌더러에 의해 임의의 시점에서 렌더링된 이미지 $x = g(\theta)$는 사전 학습된 diffusion model에 의해 모델링된 텍스트 조건부 이미지 분포 $p(x \vert y)$에서 추출된 샘플을 나타낼 것으로 예상된다. Diffusion model $\phi$는 텍스트 프롬프트 $y$에 따라 noise level $t$에서 noisy한 이미지 $x_t$의 noise $\epsilon_\phi(x_t; y, t)$를 예측하도록 학습되었다. Score Distillation Sampling (SDS) loss는 렌더링된 이미지가 diffusion model에 의해 모델링된 분포와 일치하도록 장려한다. 특히 SDS loss는 기울기를 계산한다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{SDS} (\phi, g(\theta)) = \mathbb{E}_{t, \epsilon} [\omega (t) (\epsilon_\phi (x_t; y, t) - \epsilon) \frac{\partial x}{\partial \theta}] \end{equation}\]이는 렌더링된 이미지에서 예측된 noise와 추가된 noise 사이의 픽셀별 차이이다. 여기서 $\omega(t)$는 가중치 함수이다.
조건부 diffusion model의 생성 품질을 향상시키는 한 가지 방법은 classifier-free guidance (CFG) 기술을 사용하여 unconditional한 샘플링에서 약간 멀어지게 샘플링을 조정하는 것이다.
\[\begin{equation} \epsilon_\phi (x_t; y, t) + \epsilon_\phi (x_t; y, t) - \epsilon_\phi (x_t, t, \varnothing) \end{equation}\]여기서 $\varnothing$은 빈 텍스트 프롬프트를 나타낸다. 일반적으로 SDS loss에는 고품질 text-to-3D 생성을 위한 큰 CFG guidance 가중치가 필요하지만 이로 인해 over-saturation과 over-smoothing와 같은 부작용이 발생한다.
최근 ProlificDreamer는 표준 CFG guidance 강도에 적합하고 부자연스러운 텍스처를 더 잘 해결하는 Variation Score Distillation (VSD) loss를 제안했다. 이 접근 방식은 단일 데이터 포인트를 찾는 대신 텍스트 프롬프트에 해당하는 솔루션을 확률 변수로 간주한다. 특히, VSD는 텍스트 $y$에 해당하는 3D 표현 $\mu(\theta \vert y)$의 분포 $q^\mu (x_0 \vert y)$를 최적화하며, $q^\mu (x_0 \vert y)$가 diffusion timestep $t = 0$에서 정의된 분포 $p(x_0 \vert y)$와 일치하도록 KL divergence를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{VSD} = D_\textrm{KL} (q^\mu (x_0 \vert y) \;\|\; p(x_0 \vert y)) \end{equation}\]이 목적 함수는 각 시간 $t$에서 noisy한 실제 이미지의 score와 noisy한 렌더링된 이미지의 score를 일치시킴으로써 최적화될 수 있다. 따라서 \(\mathcal{L}_\textrm{VSD}\)의 기울기는 다음과 같다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{VSD} (\phi; g(\theta)) = \mathbb{E}_{t, \epsilon} [\omega (t) (\epsilon_\phi (x_t; y, t) - \epsilon_\textrm{lora} (x_t; y, t, c)) \frac{\partial x}{\partial \theta}] \end{equation}\]여기서 \(\epsilon_\textrm{lora}\)는 LoRA (low-rank adaptation) 모델을 사용하여 렌더링된 이미지의 score를 추정한다. 획득된 변형 분포는 충실도가 높은 텍스처를 갖는 샘플을 생성한다. 그러나 이 loss는 텍스처 향상을 위해 적용되며 SDS에서 처음 학습한 대략적인 형상에는 무력하다. 또한 SDS와 VSD는 모두 글로벌한 3D 일관성보다는 뷰별 타당성만 보장하는 고정된 타겟 2D 분포를 추출(distill)하려고 시도한다. 결과적으로 3D 품질을 저해하는 동일한 모양 및 semantic 이동 문제로 어려움을 겪는다.
DreamCraft3D
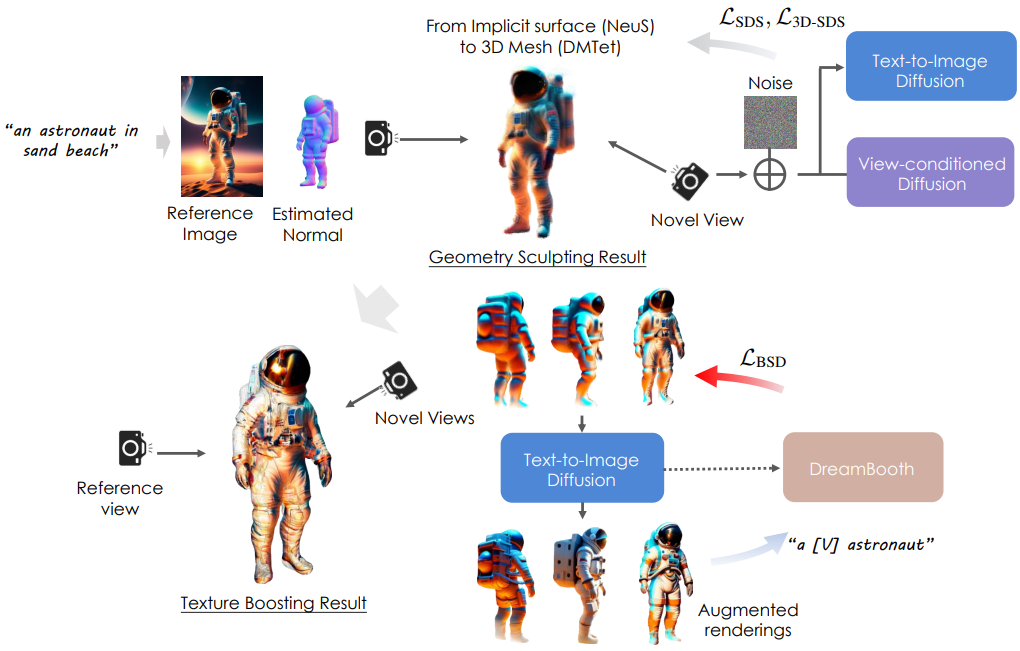
본 논문은 위 그림과 같이 3D 콘텐츠 생성을 위한 계층적 파이프라인을 제안하였다. 먼저 SOTA text-to-image 생성 모델을 활용하여 텍스트 프롬프트에서 고품질 2D 이미지를 생성한다. 이러한 방식으로 SOTA 2D diffusion model의 모든 능력을 활용하여 텍스트에 설명된 복잡한 시각적 의미를 묘사하면서 2D 모델로서의 창의적 자유를 유지할 수 있다. 그런 다음 형상 조각과 텍스처 부스팅의 계단식 단계를 통해 이 이미지를 3D로 끌어올린다. 문제를 분해함으로써 각 단계마다 특화된 기술을 적용할 수 있다. 형상의 경우 멀티뷰 일관성과 글로벌한 3D 구조를 우선시하여 세부 텍스처에 대한 어느 정도 절충을 허용한다. 형상이 고정된 상태에서 현실적이고 일관된 텍스처를 최적화하는 데만 집중하기 위해 3D 최적화를 부트스트랩하기 전에 3D-aware diffusion prior를 공동으로 학습시킨다.
1. 형상 조각 (Geometry sculpting)
이 단계에서 서로 다른 시야각에서 타당성을 유지하면서 동일한 레퍼런스 뷰에서 레퍼런스 이미지 $\hat{x}$의 모양과 일치하도록 3D 모델을 만드는 것을 목표로 한다. 이를 위해 사전 학습된 diffusion model로 무작위로 샘플링된 각 뷰에 대해 그럴듯한 이미지 렌더링을 권장한다. 이는 SDS loss \(\mathcal{L}_\textrm{SDS}\)를 사용하여 달성된다. 레퍼런스 이미지의 guidance를 효과적으로 활용하기 위해 렌더링된 이미지와 레퍼런스 간의 광량 차이에
\[\begin{equation} \mathcal{L}_\textrm{rgb} = \| \hat{m} \odot (\hat{x} − g(\theta; \hat{c})) \|_2 \end{equation}\]를 통해 페널티를 적용한다. 여기서 $\hat{c}$는 레퍼런스 뷰이다. Loss는 마스크 $\hat{m}$로 표시된 전경 영역 내에서만 계산된다. 한편, $g_m$이 실루엣을 렌더링하는 장면 희소성을 장려하기 위해 마스크 loss
\[\begin{equation} \mathcal{L}_\textrm{mask} \| \hat{m} - g_m (\theta; \hat{c}) \|_2 \| \end{equation}\]를 사용한다. 또한, 레퍼런스 이미지에서 추론된 형상 prior를 완전히 활용하고 레퍼런스 뷰에 대해 계산된 깊이 및 법선 맵과의 일관성을 강화한다. 해당 깊이 loss와 법선 loss는 각각 다음과 같이 계산된다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = - \frac{\textrm{conv} (d, \hat{d})}{\sigma (d) \sigma (\hat{d})}, \quad \mathcal{L}_\textrm{normal} = - \frac{n \cdot \hat{n}}{\| n \|_2 \cdot \| \hat{n} \|_2} \end{equation}\]여기서 $\textrm{conv}(\cdot)$와 $\sigma(\cdot)$는 각각 공분산 연산자와 분산 연산자를 나타내며, 레퍼런스 뷰의 깊이 $\hat{d}$와 법선 $\hat{n}$은 상용 단일 뷰 추정기를 사용하여 계산된다. 깊이 loss는 깊이의 스케일 불일치를 해결하기 위해 음의 Pearson 상관 관계의 형태를 채택한다.
그럼에도 불구하고 후면까지 일관된 semantic과 모양을 유지하는 것은 여전히 어려운 일이다. 따라서 저자들은 일관되고 디테일한 형상을 생성하기 위해 추가 기술을 사용하였다.
3D-aware diffusion prior
뷰별 supervision만으로는 3D 최적화가 제한적이다. 따라서 저자들은 대규모 3D 에셋에 대해 학습되고 향상된 시점 인식을 제공하는 뷰 조건부 diffusion model인 Zero-1-to-3을 활용한다. Zero-1-to-3는 fine-tuning된 2D diffusion model로, 레퍼런스 이미지 $\hat{x}$가 주어지면 상대적인 카메라 포즈 $c$에서 이미지를 상상한다. 이 3D-aware 모델은 보다 풍부한 3D 지식을 인코딩하고 레퍼런스 이미지가 제공된 뷰를 더 효과적으로 추정할 수 있도록 해준다. 따라서 이 Zero-1-to-3에서 확률 밀도를 추출(distill)하고 새로운 뷰에 대한 3D-aware SDS loss의 기울기를 계산한다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{3D-SDS} (\phi, g(\theta)) = \mathbb{E}_{t, \epsilon} [\omega (t) (\epsilon_\phi (x_t; \hat{x}, c, y, t) - \epsilon) \frac{\partial x}{\partial \theta}] \end{equation}\]이러한 loss는 ‘Janus 문제’와 같은 3D 일관성 문제를 효과적으로 완화한다. 그러나 렌더링 품질이 낮은 제한된 카테고리의 3D 데이터에 대한 fine-tuning은 diffusion model의 생성 능력을 손상시키므로 일반 이미지를 3D로 끌어올릴 때 3D-aware SDS loss만으로도 품질 저하를 유발하기 쉽다. 따라서 2D 및 3D diffusion prior를 동시에 통합하는 하이브리드 SDS loss를 사용한다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{hybrid} (\phi, g(\theta)) = \nabla_\theta \mathcal{L}_\textrm{SDS} (\phi, g(\theta)) + \mu \nabla_\theta \mathcal{L}_\textrm{3D-SDS} (\phi, g(\theta)) \end{equation}\]여기서 저자들은 3D diffusion prior의 가중치를 강조하기 위해 $\mu = 2$를 선택하였다. 저자들은 \(\mathcal{L}_\textrm{SDS}\)를 계산할 때 64$\times$64 해상도 픽셀 공간에서 작동하고 대략적인 형상을 더 잘 캡처하는 diffusion model인 DeepFloyd IF base model을 채택하였다.
점진적인 view 학습
그러나 360도 뷰에 대해 직접 적용시키면 단일 레퍼런스 이미지에 내재된 모호함으로 인해 기하학적 아티팩트가 여전히 발생할 수 있다. 이 문제를 해결하기 위해 학습 뷰를 점진적으로 확대하고 잘 확립된 형상을 360도 결과로 점진적으로 전파한다.
Diffusion timestep 어닐링
저자들은 3D 최적화의 대략적인 진행에 맞춰 DreamTime과 유사한 diffusion timestep 어닐링 전략을 채택하였다. 최적화 시작 시, 글로벌한 구조를 제공하기 위해 \(\nabla_\theta \mathcal{L}_\textrm{hybrid}\)을 계산할 때 $[0.7, 0.85]$ 범위에서 더 큰 diffusion timestep $t$를 샘플링하는 데 우선순위를 둔다. 학습이 진행됨에 따라 $t$의 샘플링 범위를 $[0.2, 0.5]$로 선형적으로 어닐링한다. 이 어닐링 전략을 통해 모델은 구조적 디테일을 개선하기 전에 초기 최적화 단계에서 먼저 그럴듯한 글로벌 형상을 설정할 수 있다.
디테일한 구조적 향상
초기에 대략적인 구조를 설정하기 위해 볼륨 렌더링을 사용하여 암시적 표면 표현을 최적화한다. 그런 다음 Magic3D를 따라 이 결과를 사용하여 DMTet을 사용하여 텍스처가 있는 3D mesh 표현을 초기화하여 고해상도 디테일을 구현한다. 이 표현은 형상과 디테일 학습을 분리한다. 따라서 이러한 구조적 향상이 끝나면 텍스처만 개선하고 레퍼런스 이미지의 고주파 디테일를 더 잘 보존할 수 있다.
2. Bootstrapped score sampling을 통한 텍스처 부스팅
형상 조각 단계에서는 일관되고 디테일한 형상 학습을 우선시하지만 텍스처는 흐릿하게 유지된다. 이는 coarse한 해상도에서 작동하는 2D prior 모델에 의존하고 3D-aware diffusion model이 선명도가 제한되기 때문이다. 또한 over-smoothing과 over-saturation과 같은 텍스처 문제는 지나치게 큰 classifier-free guidance로 인해 발생한다.
텍스처 사실성을 높이기 위해 VSD loss를 사용한다. 이 단계에서는 고해상도 기울기를 제공하는 Stable Diffusion 모델로 전환한다. 사실적인 렌더링을 촉진하기 위해 사면체 그리드를 고정한 상태에서 mesh 텍스처를 독점적으로 최적화한다. 이 학습 단계에서는 텍스처 품질에 부정적인 영향을 미치기 때문에 Zero-1-to-3 모델을 3D prior 모델로 활용하지 않는다. 그럼에도 불구하고 일관되지 않은 텍스처가 다시 나타나 기괴한 3D 결과를 초래할 수 있다.
저자들은 마지막 단계의 멀티뷰 렌더링이 약간의 흐릿함에도 불구하고 좋은 3D 일관성을 나타내는 것을 관찰했다. 한 가지 아이디어는 이러한 렌더링 결과를 사용하여 사전 학습된 2D diffusion model을 적용하여 모델이 장면의 주변 뷰에 대한 개념을 형성할 수 있도록 하는 것이다. 이를 고려하여 DreamBooth를 사용하여 멀티뷰 이미지 렌더링 \(\{x\}\)로 diffusion mdoel을 fine-tuning한다. 특히, 고유 식별자와 대상의 클래스 이름이 포함된 텍스트 프롬프트를 통합한다 (ex. “A $[V]$ astronaut”). Fine-tuning 중에 각 뷰의 카메라 파라미터가 추가 조건으로 도입된다. 실제로 저자들은 증강된 이미지 렌더링 $x_r = r_{t^\prime} (x)$을 사용하여 DreamBooth를 학습시켰다. Diffusion timestep $t^\prime$에 맞는 Gaussian noise를 멀티뷰 렌더링에 도입하며 diffusion model을 사용하여 복원된다.
\[\begin{equation} x_{t^\prime} = \alpha_{t^\prime} x_0 + \sigma_{t^\prime} \epsilon \end{equation}\]큰 $t^\prime$을 선택하면 이러한 증강된 이미지는 원본 렌더링에 대한 충실도를 희생하면서 고주파 디테일을 드러낸다. 이러한 증강된 렌더링으로 학습된 DreamBooth 모델은 텍스처 개선을 가이드하는 3D prior 역할을 할 수 있다.
또한 저자들은 부트스트랩 최적화를 촉진하기 위해 3D 장면을 대안적으로 최적화하는 방법을 제안하였다. 처음에는 3D mesh가 흐릿한 멀티뷰 렌더링을 생성한다. 3D 불일치를 도입하면서 텍스처 품질을 높이기 위해 큰 $t^\prime$을 채택한다. 이러한 증강된 렌더링을 통해 학습된 DreamBooth 모델은 장면의 통합된 3D 개념을 획득하여 텍스처 개선을 가이드한다. 3D mesh가 더 세밀한 텍스처를 나타내면 이미지 렌더링에 발생하는 diffusion noise가 줄어드므로 DreamBooth 모델은 보다 일관된 렌더링을 통해 학습하고 진화하는 뷰에 충실한 이미지 분포를 더 잘 캡처한다. 이 순환 프로세스에서 3D mesh와 diffusion prior는 부트스트랩 방식으로 상호 향상된다. 다음과 같이 bootstrapped score distillation (BSD) loss을 사용하여 3D 최적화 기울기를 계산한다.
\[\begin{equation} \nabla_\theta \mathcal{L}_\textrm{BSD} (\phi, g(\theta)) = \mathbb{E}_{t, \epsilon, c} [\omega (t) (\epsilon_\textrm{DreamBooth} (x_t; y, t, r_{t^\prime} (x), c) - \epsilon_\textrm{lora} (x_t; y, t, x, c)) \frac{\partial x}{\partial \theta}] \end{equation}\]Experiments
- 아키텍처
- 형상 조각: Instance NGP 사용
- 텍스처링: DMTet (128 grid, 512 렌더링 해상도)
- 데이터셋
- 실제 사진과 Stable Diffusion 및 Deep Floyd에서 제작한 사진을 혼합한 300장의 이미지
- 각 이미지에는 전경용 알파 마스크, 예측 깊이 맵, 텍스트 프롬프트가 함께 제공
- 실제 이미지의 경우 텍스트 프롬프트는 이미지 캡션 모델에서 제공
1. Comparisons with the State of the Arts
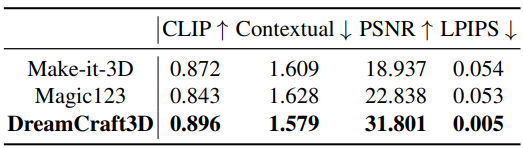
Quantitative comparison
다음은 이전 2D-to-3D 방법들과 DreamCraft3D의 성능을 비교한 표이다.
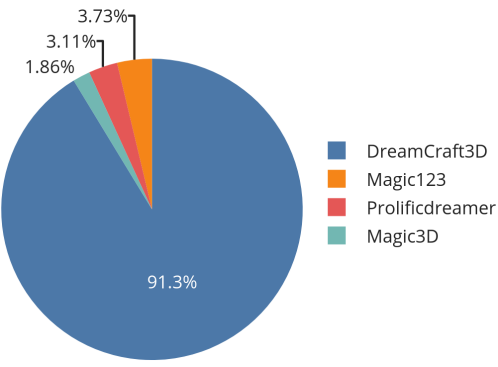
User study
다음은 32명의 참가자가 가장 선호하는 3D 모델을 고른 480개의 응답을 나타낸 그래프이다.
Qualitative comparison
다음은 다른 방법들과 정성적으로 비교한 결과이다.

2. Analysis
다음은 ablation study 결과이다.

다음은 각 단계의 중간 렌더링 결과를 시각화한 것이다.

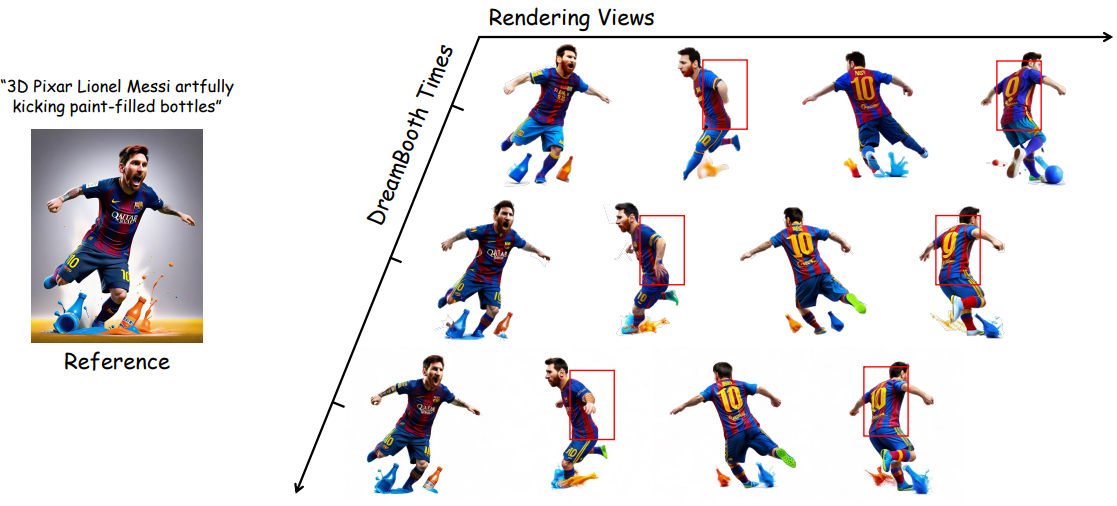
다음은 DreamBooth의 멀티뷰 데이터셋에 대한 결과를 단계별로 나타낸 것이다.