[논문리뷰] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
CVPR 2023. [Paper] [Page] [Github]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
Google Research | Boston University
25 Aug 2022
Introduction
최근에 개발된 대형 text-to-image 모델은 자연어로 작성된 텍스트 프롬프트를 기반으로 고품질의 다양한 이미지 합성을 가능하게 하여 AI 진화의 비약적인 도약을 이루고 있다. 이러한 모델의 주요 이점 중 하나는 이미지-캡션 쌍의 대규모 컬렉션에서 학습한 강력한 semantic prior이다. 예를 들어, 이러한 prior는 “개”라는 단어를 다양한 포즈와 컨텍스트로 나타날 수 있는 다양한 인스턴스와 바인딩하는 방법을 배운다.
이러한 모델은 주어진 레퍼런스에서 피사체의 모양을 모방하고 다른 컨텍스트에서 동일한 피사체의 새로운 해석을 합성하는 능력이 부족하며, 이는 출력 도메인의 표현력이 제한되어 있기 때문이다. 개체에 대한 가장 자세한 텍스트 설명조차도 모양이 다른 인스턴스를 생성할 수 있다. 또한 공유된 language-vision space에 텍스트 임베딩이 있는 모델도 주어진 대상의 모습을 정확하게 재구성할 수 없고 이미지 콘텐츠의 변형만 생성할 수 있다. (아래 그림 참고)

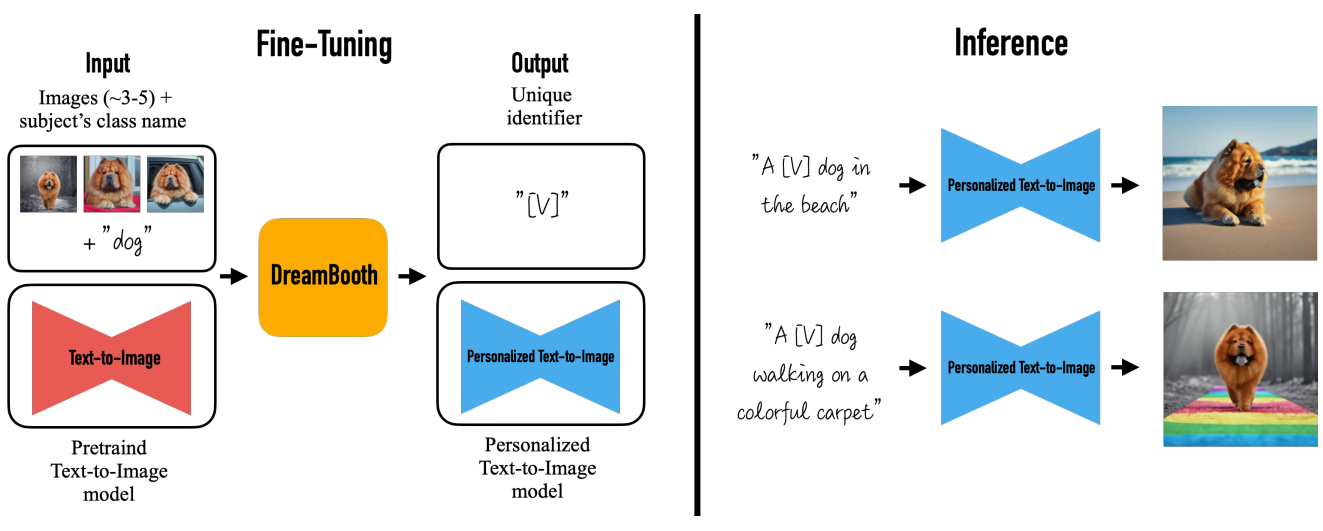
본 논문에서는 text-to-image diffusion model의 사용자의 이미지 생성 요구 사항에 맞게 모델이 조정되는, 즉 “개인화”를 위한 새로운 접근 방식을 제시한다. 본 논문의 목표는 사용자가 생성하려는 특정 주제와 새 단어를 바인딩하도록 모델의 language-vision 사전을 확장하는 것이다. 새 사전이 모델에 내장되면 이러한 단어를 사용하여 주요 식별 기능을 유지하면서 다양한 장면에서 상황에 맞는 주제의 참신한 사실적 이미지를 합성할 수 있다. 이 효과는 “magic photo booth”(이미지를 몇 장 찍으면 booth는 간단하고 직관적인 텍스트 프롬프트의 안내에 따라 다양한 조건과 장면에서 이미지를 생성)와 비슷하다. (아래 그림 참고)

본 논문의 목표는 피사체의 이미지 몇 개(~3-5)가 주어지면 모델의 출력 도메인에 피사체를 이식하여 고유 식별자로 합성할 수 있도록 하는 것이다. 이를 위해 저자들은 희귀한 토큰 식별자로 주어진 주제를 표현하고 두 단계로 작동하는 사전 학습된 diffusion 기반 text-to-image 프레임워크를 finetuning하는 기술을 제안한다. 텍스트에서 저해상도 이미지를 생성한 후 super-resolution (SR) diffusion model을 적용한다.
먼저 입력 이미지와 클래스 이름이 뒤에 오는 고유 식별자를 포함하는 텍스트 프롬프트를 사용하여 저해상도 text-to-image 모델을 finetuning한다 (ex., “A [V] dog”). 모델이 클래스 이름(ex. “dog”)을 특정 인스턴스와 연결하게 만드는 overfitting과 language drift를 방지하기 위해 클래스에 대한 semantic prior를 활용하는 autogenous, class-specific prior preservation loss을 제안한다. Semantic prior는 모델에 내장되어 있으며 주제와 동일한 클래스의 다양한 인스턴스를 생성하도록 권장한다.
두 번째 단계에서는 입력 이미지의 저해상도 버전과 고해상도 버전을 쌍으로 사용하여 super-resolution 부분을 finetuning한다. 이를 통해 모델은 주제의 작지만 중요한 세부 사항에 대해 높은 fidelity를 유지할 수 있다. 저자들은 사전 학습된 Imagen 모델을 실험의 기본 모델로 사용하지만 논문의 방법은 특정 text-to-image diffusion model에 제한되지 않는다.
저자들의 테크닉은 사용자가 피사체의 몇 가지 캐주얼한 이미지를 촬영하고 주요 기능을 유지하면서 다양한 컨텍스트에서 새로운 표현을 생성할 수 있도록 하는 이 어려운 문제 설정을 해결하는 첫 번째 테크닉이다. State-of-the-art 3D reconstruction 테크닉으로 이러한 결과를 달성하는 것은 입력의 다양성을 제한할 수 있고 (예를 들어, 입력 대상이 동물인 경우 포즈가 일관되어야 함), 더 많은 입력이 필요하며, 좋은 3D reconstruction을 사용하더로도 주제를 새로운 컨텍스트로 표현하는 것은 여전히 해결되지 않은 문제이다.
요약하자면 본 논문의 기여로는 다음의 2가지가 있다.
- Subject-driven generation(주제에 대해 캐주얼하게 캡처한 몇 가지 이미지가 주어지면 주요 시각적 특징에 대한 높은 fidelity를 유지하면서 다양한 컨텍스트에서 주제의 새로운 표현을 합성하는 것)이라는 새로운 문제
- 피사체 클래스에 대한 모델의 의미론적 지식을 보존하면서 few-shot setting에서 text-to-image diffusion model을 finetuning하는 새로운 기술
Preliminaries
Cascaded Text-to-Image Diffusion Models
Diffusion model은 가우시안 분포에서 샘플링한 변수를 점진적으로 denoising하여 데이터 분포를 학습하는 확률적 생성 모델이다. 이는 고정 길이의 Markov forward process의 reverse process를 학습하는 것을 의미한다. 다음의 간단한 식으로 조건부 diffusion model $\hat{x}_\theta$가 noise가 추가된 이미지 $z_t:= \alpha_t x + \sigma_t \epsilon$를 denoising하도록 squared error loss로 학습된다.
\[\begin{equation} \mathbb{E}_{x, c, \epsilon, t} [w_t \| \hat{x}_\theta (\alpha_t x + \sigma_t \epsilon, c) - x \|_2^2] \end{equation}\]여기서 $x$는 ground-truth 이미지, $c$는 컨디셔닝 벡터, $\epsilon \sim \mathcal{N}(0, I)$은 noise 항이다. $\alpha_t$, $\sigma_t$, $w_t$는 noise schedule과 샘플 품질을 조절하는 항이며 diffusion process time $t \sim \mathcal{U}([0,1])$의 함수이다. Inference 시에는 $z_{t_1} \sim \mathcal{N}(0, I)$을 반복적으로 denoising하여 샘플링하며, deterministic DDIM이나 stochastic ancestral sampler를 사용한다. 중간 지점 $z_{t_1}, \cdots, z_{t_T}$는 noise level이 감소하도록 $1 = t_1 > \cdots > t_T = 0$에 대하여 생성된다. 이 관점에서 \(\hat{x}_0^t := \hat{x}_\theta (z_t, c)\)는 $x$를 예측하는 함수이다.
최근 state-of-the-art text-to-image diffusion models은 cascaded diffusion model을 사용하여 고해상도 이미지를 텍스트로부터 생성한다. 구체적으로, 출력 해상도가 64$\times$64인 기본 text-to-image 모델을 사용하고, 2개의 텍스트 컨디셔닝 SR model (64$\times$64 → 256$\times$256, 256$\times$256 → 1024$\times$1024)이 사용된다.
Vocabulary Encoding
Text-to-image diffusion model에서 텍스트 컨디셔닝의 디테일들은 시각적 품질과 의미론적 fidelity에 매우 중요하다. 기존 논문들은 학습된 prior를 사용하여 이미지 임베딩으로 변환되는 CLIP 텍스트 임베딩을 사용하거나, 사전 학습된 대규모 언어 모델을 사용한다.
본 논문에서는 사전 학습된 대규모 언어 모델을 사용한다. 이 언어 모델은 토큰화된 텍스트 프롬프트의 암배당울 생성하며, vocabulary encoding은 프롬프트 임베딩을 위한 전처리 단계에서 굉장히 중요하다. 텍스트 프롬프트 $P$를 컨디셔닝 임베딩 $c$로 변환하기 위해서는 먼저 텍스트가 학습된 vocabulary를 사용하는 tokenizer $f$로 토큰화되어야 한다. 저자들은 SentencePiece tokenizer를 사용하였다.
$P$를 $f$로 토큰화하면 고정된 길이의 벡터 $f(P)$를 얻는다. 언어 모델 $\Gamma$는 이 토큰 식별자 벡터로 컨디셔닝되어 임베딩 $c := \Gamma(f(O))$를 생성한다. 마지막으로 text-to-image diffusion model이 직접적으로 $c$로 컨디셔닝된다.
Method
텍스트 설명 없이 특정 피사체에 대해 캐주얼하게 캡처된 이미지 몇 개(3-5개)만 주어졌을 때, 높은 디테일 fidelity로 텍스트 프롬프트에 의해 guide된 피사체의 새로운 이미지를 생성하는 것이 본 논문의 목표이다. 입력 이미지 캡처에 제한을 두지 않으며 피사체 이미지는 다양한 컨텍스트를 가질 수 있다. 출력의 예로는 피사체가 있는 장소 변경, 색상, 종 또는 모양과 같은 피사체의 속성 변경, 피사체의 포즈, 표정, 재료 및 기타 의미적 수정 수정이 있다. 저자들은 이러한 모델의 강력한 prior를 감안할 때 이러한 수정의 폭이 매우 크다는 것을 발견했다. 저자들의 방법에 대한 개요는 다음 그림과 같다.
이를 달성하기 위한 첫 번째 작업은 피사체 인스턴스를 모델의 출력 도메인에 이식하고 피사체를 고유 식별자로 바인딩하는 것이다. 중요한 문제는 피사체를 보여주는 작은 이미지들을 finetuning하면 주어진 이미지에 overfitting되는 경향이 있다는 것이다. 또한 language drift는 언어 모델에서 흔히 발생하는 문제이며 text-to-image diffusion model에서도 나타난다. 모델은 동일한 클래스의 다른 주제를 생성하는 방법을 잊고 다양성과 해당 클래스에 속하는 인스턴스의 자연스러운 변형에 대한 지식을 잃는다. 이를 위해 저자들은 diffusion model이 주제와 동일한 클래스의 다양한 인스턴스를 계속 생성하도록 장려하여 overfitting을 완화하고 language drift를 방지하는 autogenous class-specific prior preservation loss를 제시한다.
디테일의 보존을 강화하려면 모델의 super-resolution 부분도 finetuning해야 한다. 그러나 naive한 방식으로 대상 인스턴스를 생성하도록 finetuning된 경우 인스턴스의 중요한 디테일들을 복제할 수 없다. 저자들은 주제의 디테일을 더 잘 보존하기 위해 이러한 SR 모듈을 학습시키고 테스트할 수 있는 통찰력을 제공하여 재맥락화(recontextualization)에서 전례 없는 성능을 달성하였다. 제자들이 제안한 학습 절차의 자세한 스케치는 아래 그림에 나와 있다. 본 논문에서는 사전 학습된 Imagen 모델을 기본 모델로 사용한다.
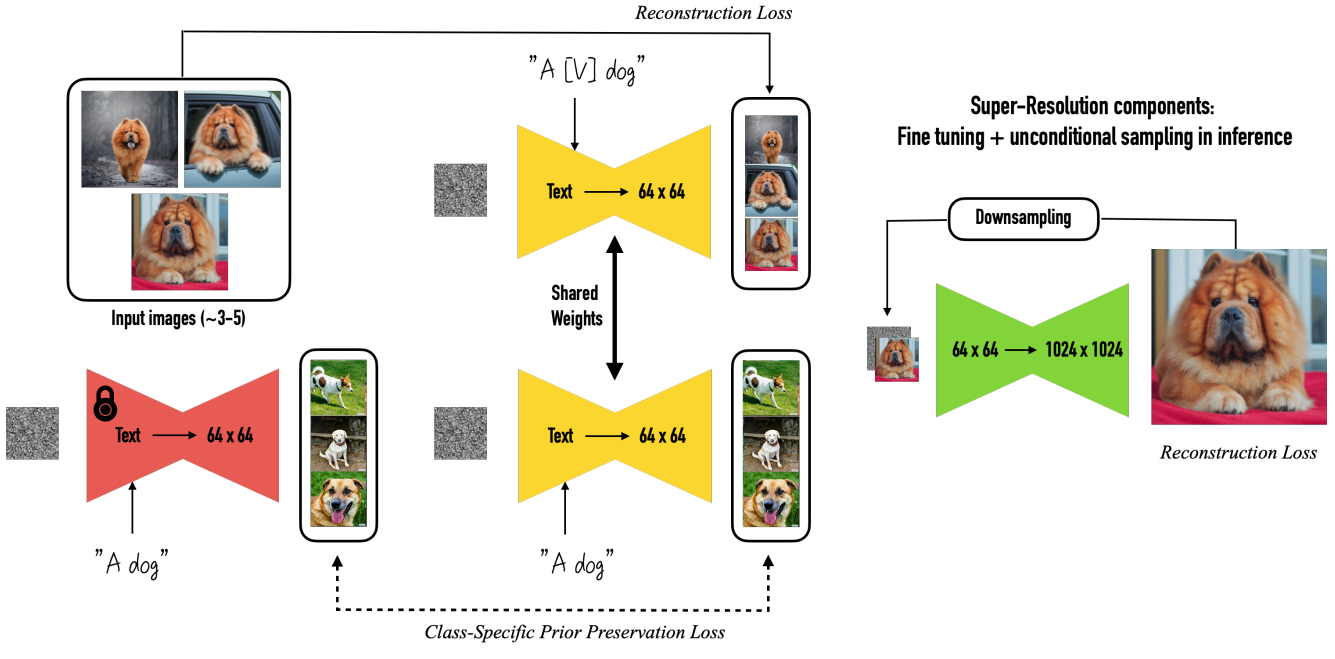
1. Representing the Subject with a Rare-token Identifier
Designing Prompts for Few-Shot Personalization
저자들의 목표는 새로운 (key, value) 쌍을 diffusion model의 사전에 삽입하여 주제에 대한 key가 주어지면 텍스트 프롬프트로 guide된 유의미한 의미 수정을 통해 이 특정 주제의 완전히 새로운 이미지를 생성할 수 있도록 하는 것이다. 한 가지 방법은 모델을 몇 번만 finetuning하는 것이다. 문제는 이 과정을 어떻게 supervise할 것인지이다. 일반적으로 텍스트 프롬프트는 사람이 작성하며 대규모 온라인 데이터 세트에서 가져온다. 주요 제한 사항에는 주어진 이미지들에 대한 자세한 이미지 설명을 작성하는 비용과 사람이 작성한 캡션의 높은 분산과 주관성이 포함된다.
저자들은 더 간단한 접근 방식을 선택하고 주제 “a [identifier] [class noun]”의 모든 입력 이미지에 레이블을 지정한다. 여기서 [identifier]는 주제에 연결된 고유 식별자이고 [class noun]는 주제의 대략적인 class descriptor이다. Class descriptor는 classifier를 사용하여 얻을 수 있다. 저자들은 클래스의 prior을 고유한 주제에 연결하기 위해 문장에서 class descriptor를 특별히 사용한다. [class noun] 없이 [identifier]만 사용하면 학습 시간이 늘어나고 성능이 저하된다는 사실을 발견했다고 한다. 본질적으로 diffusion model의 특정 클래스에 대한 prior를 활용하고 이를 대상의 고유 식별자 임베딩과 얽히게 하려고 한다. 이러한 방식으로 다양한 맥락에서 피사체의 새로운 포즈와 표현을 생성하기 전에 시각적인 요소를 활용할 수 있다.
주제에 대한 식별자를 구성하는 naive한 방법은 기존 단어를 사용하는 것이다. 예를 들어 “unique” 또는 “special”과 같은 단어를 사용하는 것이다. 한 가지 문제는 기존 영어 단어가 text-to-image diffusion model의 학습 데이터셋에 존재하기 때문에 prior에 더 강한 경향이 있다는 것이다. 일반적으로 이러한 일반적인 단어를 사용하여 주제를 색인화할 때 학습 시간이 증가하고 성능이 저하되는 것을 발견하였다고 한다. 이는 모델이 주제를 참조하기 위해 단어를 원래 의미에서 풀고 다시 얽히게 하는 방법을 모두 배워야 하기 때문이다. 이 접근 방식은 단어의 의미를 개체의 모양과 얽히게 하여 실패할 수도 있다. 예를 들어 극단적인 경우 선택한 식별자가 “파란색”이고 대상이 회색이면 유추할 때 색상이 얽히게 되고 회색과 파란색 피사체의 혼합을 샘플링한다.
따라서 언어 모델과 diffusion model 모두에서 weak prior를 갖는 식별자가 필요하다. 이를 수행하는 위험한 방법은 영어에서 임의의 문자를 선택하고 연결하여 희귀한 식별자 (ex. “xxy5syt00”)를 생성하는 것이다. 실제로 tokenizer는 각 문자를 개별적으로 토큰화할 수 있으며 diffusion model의 사전은 이러한 문자에 대해 강력하다. 특히 finetuning 전에 이러한 식별자로 모델을 샘플링하면 해당 문자와 연결된 문자나 개념의 그림 묘사를 얻을 수 있다. 저자들은 종종 이러한 토큰이 주제를 색인화하기 위해 일반적인 영어 단어를 사용하는 것과 동일한 약점을 초래한다는 것을 발견했다.
Rare-token Identifiers
간단히 말해서 본 논문의 접근 방식은 vocabulary에서 상대적으로 rare-token을 찾은 다음 텍스트 space로 반전시키는 것이다. 이를 위해 먼저 vocabulary에서 rare-token lookup를 수행하고 rare token identifier의 시퀀스 $f(\hat{V})$를 얻는다. 여기서 $f$는 tokenizer이고 $f(\hat{V})$는 문자 시퀀스를 토큰에 매핑하는 함수이며 $\hat{V}$는 토큰 $f(\hat{V})$에서 파생된 디코딩된 텍스트이다. 이 시퀀스는 길이가 가변 길이 $k$일 수 있으며 $k$는 hyperparameter이다. 저자들은 상대적으로 짧은 시퀀스 \(k = \{1, \cdots, 3\}\)가 잘 작동한다는 것을 확인하였다. 그런 다음 $f(\hat{V})$에 de-tokenizer를 사용해 vocabulary를 반전하여 고유 식별자 $\hat{V}$를 정의하는 일련의 문자를 얻는다. 3개 이하의 유니코드 문자(공백 제외)에 해당하는 토큰을 교체하지 않고 균일한 랜덤 샘플링을 사용하고 \(\{5000, \cdots, 10000\}\)의 T5-XXL tokenizer 범위에서 토큰을 사용하는 것이 잘 작동하는 것을 확인했다고 한다.
2. Class-specific Prior Preservation Loss
Few-shot Personalization of a Diffusion Model
목표 대상 \(\mathcal{X}_s := {x_s^i; i \in \{0, \cdots, N\}}\)를 묘사하는 작은 이미지 세트와 텍스트 프롬프트 “a [identifier] [class noun]”에서 얻은 동일한 조건 벡터 $c_s$를 사용하여 오리지널 diffusion model의 denoising loss로 text-to-image model을 finetuning한다. 이러한 naive한 finetuning 전략에는 overfitting과 language drift라는 두 가지 주요 문제가 발생한다.
Issue-1: Overfitting
입력하는 이미지의 양이 매우 적기 때문에 큰 이미지 생성 모델을 finetuning하면 주어진 입력 이미지에서 피사체의 컨텍스트와 모양 모두에 overfitting될 수 있다. 정규화니 모델의 특정 부분을 선택적으로 finetuning하는 것과 같이 이러한 문제를 해결하는 데 사용할 수 있는 많은 테크닉이 있다. 좋은 주제 fidelity와 의미론적 수정 유연성을 얻기 위해 모델의 어떤 부분을 고정해야 하는지에 대한 불확실성이 있다. 저자들의 경험에 따르면 모델의 모든 레이어를 finetuning하였을 때 가장 높은 fidelity를 달성하는 최상의 결과를 얻을 수 있었다고 한다. 그럼에도 불구하고 여기에는 텍스트 임베딩을 조건으로 하는 finetuning layer가 포함되어 있어 language drift 문제가 발생한다.
Issue-2: Language Drift
Language Drift 현상은 언어 모델 논문에서 관찰된 문제였다. 큰 텍스트 corpus에 대해 사전 학습되고 나중에 특정 task를 위해 finetuning된 언어 모델은 대상 task를 개선하기 위해 학습함에 따라 언어의 구조적 지식과 의미론적 지식을 점진적으로 잃는다. 저자들은 diffusion model에 영향을 미치는 유사한 현상을 처음으로 발견했다. 텍스트 프롬프트에는 [identifier]와 [class noun]가 모두 포함되어 있기 때문에 diffusion model이 작은 주제 이미지 세트에서 finetuning될 때 동일한 클래스의 주제를 생성하는 방법을 천천히 잊고 클래스별 prior를 점진적으로 잊어버리고 해당 클래스의 다른 인스턴스를 생성한다.
Prior-Preservation Loss
저자들은 autogenous class-specific prior-preserving loss를 통해 overfitting 문제와 language drift 문제를 동시에 해결하고자 한다. 본질적으로 본 논문의 방법은 모델을 자체 생성한 샘플들로 supervise하며 few-shot finetuning이 시작한 후 prior를 유지한다.
구체적으로, 초기 random noise $z_{t_1} ∼ \mathcal{N}(0,I)$과 컨디셔닝 벡터 $c_\textrm{pr} := \Gamma(f(\textrm{“a [class noun]”}))$가 있는 고정된 사전 학습된 diffusion model에서 ancestral sampler를 사용하여 데이터 $x_\textrm{pr} = \hat{x}(z_{t_1}, c_\textrm{pr})$을 생성한다.
Loss는 다음과 같다.
\[\begin{equation} \mathbb{E}_{x, c, \epsilon, \epsilon', t} [w_t \| \hat{x}_\theta (\alpha_t x + \sigma_t \epsilon, c) - x \|_2^2 + \lambda w_{t'} \| \hat{x}_\theta (\alpha_{t'} x_\textrm{pr} + \sigma_{t'} \epsilon', c_\textrm{pr}) - x_\textrm{pr} \|_2^2 ] \end{equation}\]$\lambda$는 prior-preservation 항의 상대적 가중치를 조절하는 값이다. 저자들은 loss가 단순함에도 불구하고 overfitting과 language-drift 문제를 극복하는 데 효과적이라는 것을 발견했다. 200 이하의 epoch, learning rate $10^{-5}$, $\lambda = 1$으로 두는 것이 좋은 결과를 달성하는 데 충분하다고 한다. 학습 과정에서 200$\times N$개 이하의 “a [class noun]” 샘플들이 생성되며, $N$은 주제 데이터셋의 크기로 일반적으로 3~5이다. 학습 과정은 1개의 TPUv4에서15분이 걸린다.
3. Personalized Instance-Specific Super-Resolution
Text-to-image diffusion model이 대부분의 시각적 의미를 제어하는 반면 SR 모델은 사실적인 콘텐츠를 달성하고 대상 인스턴스 디테일을 보존하는 데 필수적이다. Finetuning 없이 SR 네트워크를 사용하면 생성된 출력에 아티팩트가 포함될 수 있다. SR 모델이 대상 인스턴스의 특정 디테일이나 텍스처에 익숙하지 않거나, 대상 인스턴스가 잘못된 feature를 생성했거나, 디테일이 누락되었을 수 있기 때문이다. 64$\times$64 → 256$\times$256 SR 모델을 finetuning하는 것이 대부분 필수적이며 256$\times$256 → 1024$\times$1024 모델을 finetuning하면 높은 수준의 세밀한 디테일을 가지는 데에 도움이 될 수 있다고 한다.
Low-level Noise Augmentation
저자들은 Photorealistic text-to-image diffusion models with deep language understanding 논문의 학습 방법과 테스트 파라미터를 사용하여 대상 인스턴스의 주어진 몇 개의 이미지로 SR 모델을 finetuning하는 경우 결과가 최적이 아님을 확인했다. 특히, SR 네트워크를 학습시키는 데 사용되는 noise augmentation의 원래 수준을 유지하면 대상과 환경의 고주파수 패턴이 흐려지는 것으로 나타났다. 대상 인스턴스를 충실히 재현하기 위해 256$\times$256 SR 모델을 finetuning는 동안 noise augmentation의 수준을 $10^{-3}$에서 $10^{-5}$로 줄인다. 이 작은 수정으로 대상 인스턴스의 세분화된 디테일을 복구할 수 있다.
Experiments
저자들은 다음과 같은 텍스트로 guide된 주제 인스턴스의 의미 수정에 대한 광범위한 가능성을 발견했다.
- Recontextualization
- 색상과 같은 주제 속성의 수정
- 동물 종의 조합, 인스턴스를 묘사한 예술적 연출, 시점 및 표현 수정과 같은 더 복잡한 속성 수정
중요한 것은 이전에는 극복할 수 없었던 이러한 다양한 의미론적 수정을 통해 주제에 정체성이나 본질을 부여하는 고유한 시각적 특징을 보존할 수 있다는 것이다.
Recontextualization의 경우 대상 feature는 수정되지 않지만 모양이 변경될 수 있다 (ex. 포즈 변경). 대상과 다른 종/객체 사이의 교차와 같이 task에 더 강력한 의미 수정이 있는 경우 수정 후에도 대상의 주요 기능이 보존된다. 실험에서는 [V]를 사용하여 주체의 고유 식별자를 참조한다. 모든 실험은 Unsplash의 이미지를 사용하여 수행된다.
1. Applications
Recontextualization
맞춤형 모델 $\hat{x}_\theta$가 주어지면 고유 식별자와 클래스 명사를 포함하는 문장을 학습된 모델에 입력하여 특정 주제 인스턴스에 대한 새로운 이미지를 생성할 수 있다. Recontextualization을 위해 저자들은 일반적으로 “a [V] [class noun] [context description]”의 형식으로 문장을 형성한다.
다음 recontextualization의 예시이다.

또한 다른 물체와의 사실적인 접촉(ex. 부분적으로 눈에 심어진 것, 사람의 손으로 조작한 것 등)과 사실적인 그림자 및 반사를 포함하여 피사체의 integration 디테일에 주목할 필요가 있다. 이는 본 논문의 방법이 피사체 디테일의 interpolation이나 복구가 가능할 뿐만 아니라 피사체의 초기 데이터가 주어지지 않았을 때 “이 피사체가 부분적으로 눈에 심어지면 어떻게 될까요?”와 같은 형식의 질문에 답하는 extrapolation도 가능하다.
Art Renditions
“a painting of a [V] [class noun] in the style of [famous painter]”나 “a statue of a [V] [class noun] in the style of [famous sculptor]”와 같은 프롬프트로 대상 인스턴스의 예술적 연출을 생성할 수 있다. 특히, 이 task는 source scene의 semantic을 유지하고 다른 이미지의 스타일을 source scene으로 transfer하는 style transfer과 동일하지 않다. 대신 예술적 스타일에 따라 피사체 인스턴스 디테일과 정체성 보존을 통해 장면에서 의미 있는 변화를 얻을 수 있다. 즉, 생성되는 일부 이미지에는 주제 ground truth 데이터에서 볼 수 없는 다른 포즈의 주제와 ground truth에도 없는 장면이 있다.
다음은 art rendition의 예시이다.

Expression Manipulation
다음은 대상의 표정을 수정한 새로운 이미지 생성에 대한 예시이다.

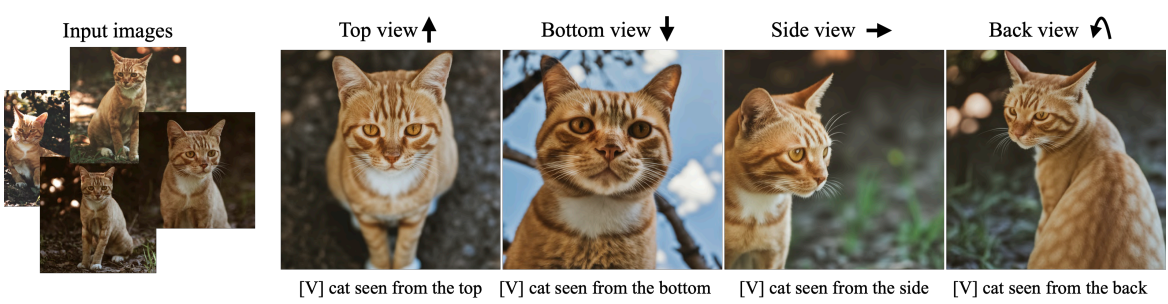
Novel View Synthesis
다음은 새로운 시점으로 대상을 렌더링한 예시이다.
Accessorization
다음은 강력하게 구성된 prior에 의해 가능한 대상에 액세서리를 추가하는 능력을 보여주는 예시이다.

Property Modification
다음은 대상의 속성을 수정한 예시이다.

본 논문의 방법을 사용하면 의미론적으로 복잡한 속성을 수정할 수 있다.
2. Ablation Studies
Class-Prior Ablation
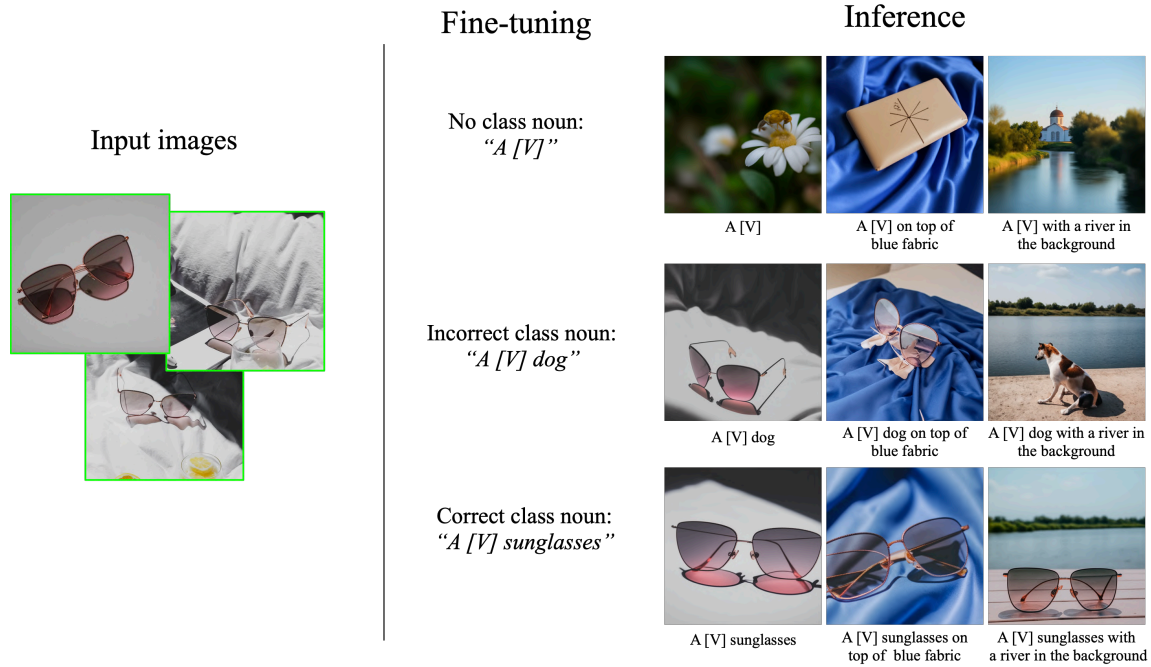
잘못된 클래스에 대한 클래스 prior가 얽힌 상태로 남아 있고 모델이 이러한 방식으로 학습될 때 대상의 새로운 이미지를 생성할 수 없음을 관찰할 수 있다. Class noun 없이 학습시키는 경우 모델은 대상 인스턴스를 학습하는 데 어려워하며 클래스 prior와 대상 인스턴스를 얽지 못한다. 모델은 수렴하는 데 더 오래 걸리고 오차가 큰 샘플을 생성한다.
Prior Preservation Loss Ablation
다음은 prior-preservation loss가 overfitting을 피하는 데 효과적인 것을 보여준다.

다음은 prior-preservation loss를 사용할 때 클래스 의미 prior가 보존되는 것을 보여준다.

Super Resolution with Low-Noise Forward Diffusion
다음은 noise augmentation의 level을 낮게 두는 것의 효과를 보여준다.

Noise augmentation의 level을 낮추었을 때 샘플 품질과 대상 fidelity가 개선된다.
3. Comparisons
다음은 An Image is Worth One Word 논문의 모델과 결과를 비교한 것이다.

본 논문의 접근 방식이 의미론적으로 정확한 이미지를 생성하며 대상의 feature를 더 잘 보존한다.
다음은 디테일한 프롬프트에 대하여 DALL-E 2와 Imagen 모델과 비교한 것이다.

4. Limitations
본 논문의 방법은 몇가지 제한점이 존재한다. 먼저, 다음과 같이 3가지 주요 failure mode가 존재한다.

- 프롬프트 맥락과 다른 이미지 생성
- Context-appearance entanglement
- 보여준 원본 대상과 비슷한 프롬프트에 대하여 overfitting 발생
또 다른 제한점은 몇몇 대상이 다른 대상에 비해 학습이 더 빠른 것이다. 흔한 대상에 대해서는 강한 prior가 있어 학습이 빠르고 희귀하거나 복잡한 대상에 대해서는 학습이 오래 걸린다.
마지막으로 주제의 fidelity에도 가변성이 있으며 일부 생성된 이미지에는 모델 prior의 강도와 의미론적 수정의 복잡성에 따라 주제에 대한 환각적인 feature가 포함될 수 있다.