[논문리뷰] DreamText: High Fidelity Scene Text Synthesis
CVPR 2025. [Paper] [Page]
Yibin Wang, Weizhong Zhang, Honghui Xu, Cheng Jin
Fudan University | Zhejiang University of Technology
23 May 2024
Introduction
기존 텍스트 합성 방법들은 제한된 표현 영역으로 인해 텍스트를 정확하게 렌더링하는 데 어려움을 겪고, 모델이 최적의 문자 생성 위치를 추정하는 데 효과적인 guidance가 부족하여 이상적인 영역에서 문자를 합성하는 데 어려움을 겪는다. 본 논문에서는 고충실도 텍스트 합성을 위한 DreamText를 제안하였으며, 더욱 정교한 guidance를 내장하여 diffusion 학습 과정을 재구성하였다. 문자의 attention을 노출 및 교정하여 이상적인 생성 영역에 더욱 정확하게 집중하고, 추가적인 제약 조건을 통해 텍스트 영역 및 문자 표현의 학습을 향상시켰다.
그러나 이러한 재구성은 필연적으로 discrete한 변수와 continuous한 변수를 모두 포함하는 복잡한 하이브리드 최적화 문제를 야기한다. 따라서 본 논문에서는 heuristic alternate optimization 전략을 설계하였다. 동시에, 학습 데이터셋 내의 다양한 글꼴 스타일을 활용하여 텍스트 인코더와 generator를 공동으로 학습시키고, 문자 표현 공간을 풍부하게 하였다. 이 공동 학습이 heuristic alternate optimization 과정에 원활하게 통합되어 문자 표현 학습과 문자 attention 재추정 간의 시너지 효과를 촉진한다. 구체적으로, 각 iteration에서 cross-attention map에서 생성된 잠재적 문자 위치 정보를 latent character mask로 인코딩한다. 이 마스크는 이후 텍스트 인코더 내 특정 문자의 표현을 개선하는 데 사용되어, 후속 단계에서 문자의 attention 보정을 용이하게 한다. 이러한 반복적인 과정은 더 나은 문자 표현을 학습하는 데 기여할 뿐만 아니라, 문자 위치를 자율적으로 추정하기 위한 명확한 guidance를 제공한다.
특히, generator는 초기에 각 문자에 대해 원하는 생성 영역에 attention하는 데 어려움을 겪을 수 있으며, 이로 인해 좋지 못한 latent mask가 생성되어 학습 진행에 영향을 미친다. 문자의 attention을 엄격하게 제한하는 기존 방법과 달리, 본 논문에서는 초기에 warm-up을 위해 문자 segmentation mask를 사용하여 attention 보정을 지원한다. 모델이 이상적인 생성 위치를 추정하는 능력을 어느 정도 갖추면, 이러한 가이드를 제거하여 모델이 반복적으로 자율적으로 학습할 수 있도록 한다.
Method
- 입력
- Latent 이미지 $\textbf{z}$
- 합성할 텍스트 영역을 나타내는 바이너리 마스크 $\textbf{B}$
- 텍스트 조건 $c$
- 목표
- 주어진 텍스트를 입력 이미지의 주어진 텍스트 영역에 렌더링
다음과 같은 loss를 최소화하는 diffusion process로 정의된다.
\[\begin{equation} \min_{(\theta, \vartheta)} \mathcal{L}_\textrm{LDM} = \mathbb{E}_{\textbf{z}, c, \boldsymbol{\epsilon} \sim \mathcal{N}(0,1), t} \| \boldsymbol{\epsilon} - \epsilon_\theta (\textbf{z}_t, t, \psi_\vartheta (c), \textbf{B}) \|_2^2 \end{equation}\](\(\psi_\vartheta\)는 문자 수준의 텍스트 인코더)
1. Latent Diffusion with Refined Guidance
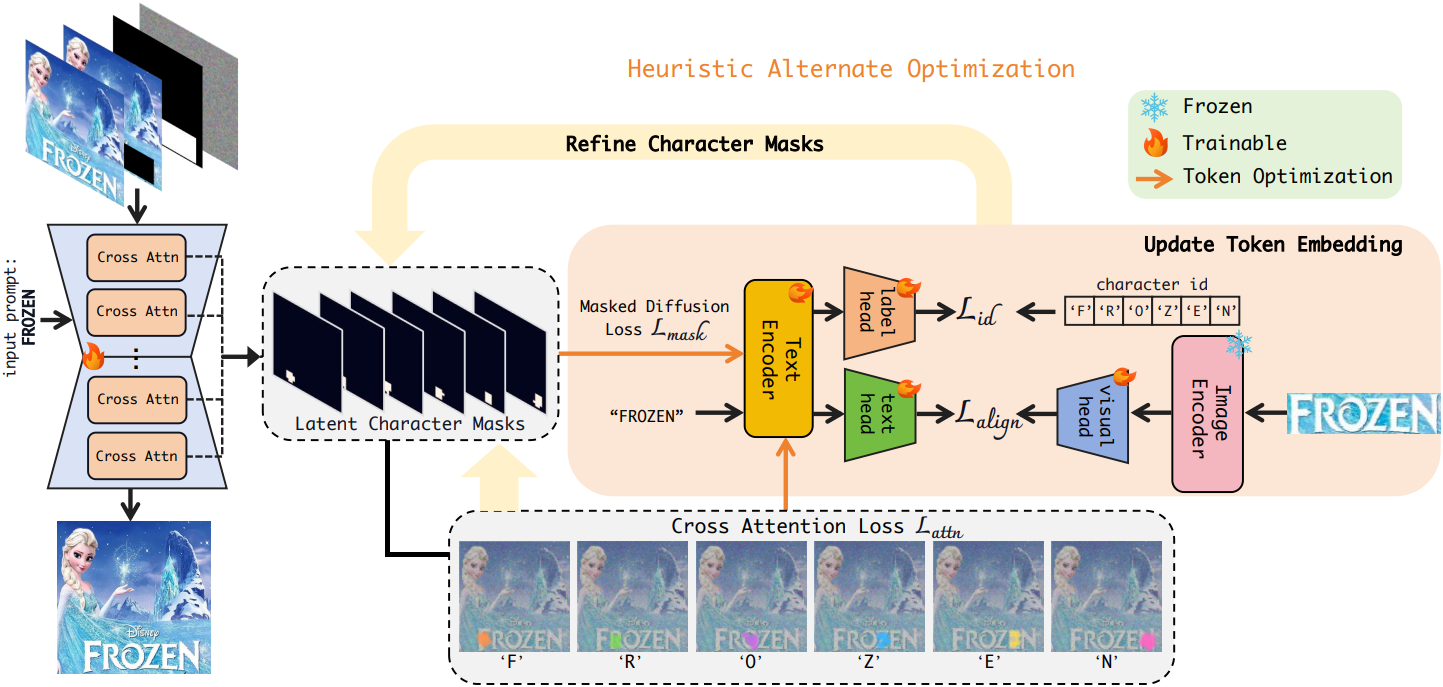
Latent Character Mask
Cross-attention map을 활용하여 latent character mask를 생성하고, 현재 step에서 문자의 위치 정보를 추출한다. Latent 이미지 \(\textbf{z}_t\)와 텍스트 임베딩 \(\psi_\vartheta (c)\)가 주어지면, 레이어 $l$의 cross-attention map은 다음과 같이 정의된다.
\[\begin{equation} \textbf{Q}_l = \textbf{z}_t \textbf{W}_l^q, \quad \textbf{K}_l = \psi_\vartheta (c) \textbf{W}_l^k \\ \textbf{A}_l = \textrm{softmax} \left( \frac{\textbf{Q}_l \textbf{K}_l^\top}{\sqrt{d}} \right) \end{equation}\](\(\textbf{W}_l^q\)과 \(\textbf{W}_l^k\)는 학습 가능한 파라미터, $d$는 임베딩 차원)
텍스트 토큰의 개수를 $N$이라 할 때, attention map \(\textbf{A}_l\)은 $N \times H \times W$로 reshape된다. 이러한 attention map은 U-Net의 모든 레이어에서 평균화되어 문자 토큰이 속한 영역에 대한 평균 응답 $\bar{\textbf{A}}$를 얻는다.
\[\begin{equation} \bar{\textbf{A}} = \frac{1}{L} \sum_{l=1}^L \textbf{A}_l \end{equation}\]Latent character mask \(\textbf{M} \in \mathbb{R}^{N \times H \times W}\)를 얻기 위해, 먼저 attention map에 Gaussian blur를 적용하여 low-pass filtering을 실행한다. 이 단계는 attention 영역의 과도한 분산을 완화하여 관련 문자 영역에 attention이 더욱 균일하게 분포되도록 한다. 그런 다음, 간단한 thresholding을 사용하여 blur 처리된 attention map을 바이너리 마스크로 변환한다.
\[\begin{aligned} \textbf{M} &= f( \textrm{blur} (\bar{\textbf{A}})) \\ f (\textbf{X}) &= \begin{cases} 1 & \textrm{if} \; x_{i,j} > \textrm{mean}(\textbf{X}) + 2 \textrm{std}(\textbf{X}) \\ 0 & \textrm{otherwise} \end{cases} \end{aligned}\]Latent character mask $\textbf{M}$을 기반으로 여러 loss function을 사용하여 텍스트 인코더와 U-Net을 반복적으로 최적화한다.
Masked Diffusion Loss
먼저, 현재 step에서 원하는 모든 문자 토큰을 강조하기 위해 LDM loss를 확장한다. 구체적으로, 관심 있는 $k$개의 토큰을 포함하는 텍스트 $c$ 내에서, 각 토큰의 latent character mask에서 얻은 해당 픽셀의 diffusion loss에 추가 가중치 $\gamma$를 적용한다.
$k$개의 문자에 대한 픽셀의 합집합을 \(\textbf{M}_k = \vee_{i=1}^k \textbf{M}_i\)라 하면, masked diffusion loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{mask} = \mathbb{E}_{\textbf{z}, c, \boldsymbol{\epsilon} \sim \mathcal{N}(0,1), t} \| (1 + \gamma \textbf{M}_k) (\boldsymbol{\epsilon} - \epsilon_\theta (\textbf{z}_t, t, \psi_\vartheta (c), \textbf{B})) \|_2^2 \end{equation}\]Cross Attention Loss
추가로, 프롬프트 내 각 토큰이 해당 합성 위치에 특화된 정보를 인코딩하도록 cross-attention loss를 통합한다. 이 loss는 토큰이 타겟 영역에만 집중하도록 유도한다.
\[\begin{equation} \mathcal{L}_\textrm{attn} = \mathbb{E}_{\textbf{z}, c, t} \| C_\textrm{attn} (\textbf{z}_t, \psi_vartheta (c)_i) - \textbf{M}_i \|_2^2 \end{equation}\](\(C_\textrm{attn}\)은 cross-attention map, \(\textbf{M}_i\)는 \(\psi_vartheta (c)_i\)의 latent character mask)
그러나 위에서 언급한 loss만으로는 최적의 문자 표현을 달성하기에 충분하지 않다. 이는 주로 latent character mask에 내재된 노이즈 때문이며, 이는 학습 과정에서 이상적인 문자 영역에 대한 잘못된 분할을 초래한다. 저자들은 노이즈의 영향을 완화하고 문자 표현의 왜곡된 학습을 방지하기 위해 추가적인 loss를 도입하였다.
Cross-modal Aligned Loss
정확하고 견고한 임베딩을 얻기 위해, 이미지 인코더 $\xi$, 텍스트 head $H_t$, 그리고 visual head $H_v$를 도입하여 두 모달리티 간의 문자 feature를 정렬한다. 구체적으로, 정렬을 최대화하기 위해 시각적 표현과 텍스트 표현 간의 코사인 유사도를 loss로 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{align} = \frac{\langle H_t (\textbf{y}), H_v (\xi (\textbf{I})) \rangle}{\| H_t (\textbf{y}) \|_2 \| H_v (\xi (\textbf{I})) \|_2} \end{equation}\]($\textbf{I}$는 데이터셋에서 bounding box를 통해 분할된 텍스트 이미지, $\langle, \rangle$는 내적)
배경 및 색상 변화로 인한 노이즈를 줄이기 위해 텍스트 이미지를 grayscale로 전처리하여 사용한다.
텍스트 head는 여러 문자의 전체 정보를 텍스트 feature space에 매핑하는 방법을 학습한다. 마찬가지로, visual head는 전체적인 시각적 텍스트 정보를 visual feature space에 매핑한다. 이를 통해 전체 텍스트 표현과 시각적 표현이 효과적으로 일치하여 높은 수준의 일관성을 확보할 수 있다.
Character Id Loss
저자들은 학습된 임베딩의 구별성을 높이기 위해 문자 ID loss를 도입하였다. 구체적으로, 텍스트 임베딩 $\textbf{y}$로부터 문자 인덱스를 예측하기 위해 multi-label classification head $H_l$을 도입한다. 그러면, cross-entropy loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{id} = - \sum_{i=1}^N \sum_{j=1}^K \textbf{l}_{i,j} \log (H_l (\textbf{y})_j) \end{equation}\]($N$은 문자 수, $K$는 가능한 인덱스 수, $\textbf{l}$은 GT 레이블)
이 loss는 대상 텍스트의 모든 문자에 대해 집계되므로, 텍스트 인코더가 각 문자에 대해 구별 가능한 임베딩을 생성하도록 보장한다.
전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{mask} + \alpha \mathcal{L}_\textrm{attn} + \beta (\mathcal{L}_\textrm{align} + \mathcal{L}_\textrm{id}) \end{equation}\]2. Optimization Strategy
Heuristic Alternate Optimization
Loss는 수많은 discrete한 변수를 포함하고 있어 미분 불가능하고 일반적인 SGD를 사용할 수 없다. 따라서 텍스트 인코더와 U-Net 간의 공생 관계를 촉진하기 위해, 잠재적인 합성 위치 정보를 가지는 latent character mask를 활용하는 heuristic alternate optimization을 사용한다.
구체적으로, latent character mask가 주어진 토큰과 마스크 자체를 번갈아 업데이트한다. 최적화 과정에서 마스크는 \(\mathcal{L}_\textrm{mask}\)를 사용하여 계산하고, 다른 파라미터의 경우 마스크를 고정하고 그에 따라 기울기를 계산한다. 위의 loss를 사용하여 각 iteration에서 주어진 마스크에 대한 특정 문자의 표현을 먼저 최적화한다. 이를 통해 generator는 후속 step에서 문자의 attention을 보정할 수 있다. 이 과정을 통해 모델은 문자 임베딩 최적화와 character mask 재추정을 동적으로 번갈아 수행할 수 있다.
문자 attention에 대한 균형 잡힌 supervision
초기 학습 단계에서는 generator가 각 문자의 의도된 생성 영역으로 attention하도록 유도하는 데 어려움을 겪을 수 있다. 저자들은 문자의 attention을 과도하게 제한하는 대신에, 균형 잡힌 supervision을 채택하였다. 초기에는 \(\mathcal{L}_\textrm{id}\)과 유사하게, latent character mask와 해당 문자의 segmentation mask 간의 cross-entropy loss를 사용하여 attention 보정을 유도한다. 모델이 이상적인 생성 위치를 추정할 수 있는 능력을 갖추면, guidance를 중단하고 자율적인 반복 학습을 시작한다. 이 전략은 모델을 제한하는 동시에 문자의 최적 생성 위치를 추정하는 데 있어 모델의 유연성을 최대한 발휘할 수 있도록 균형을 유지한다.
Experiments
- 데이터셋: LAION-OCR, SynthText, TextSeg, ICDAR13
- 구현 디테일
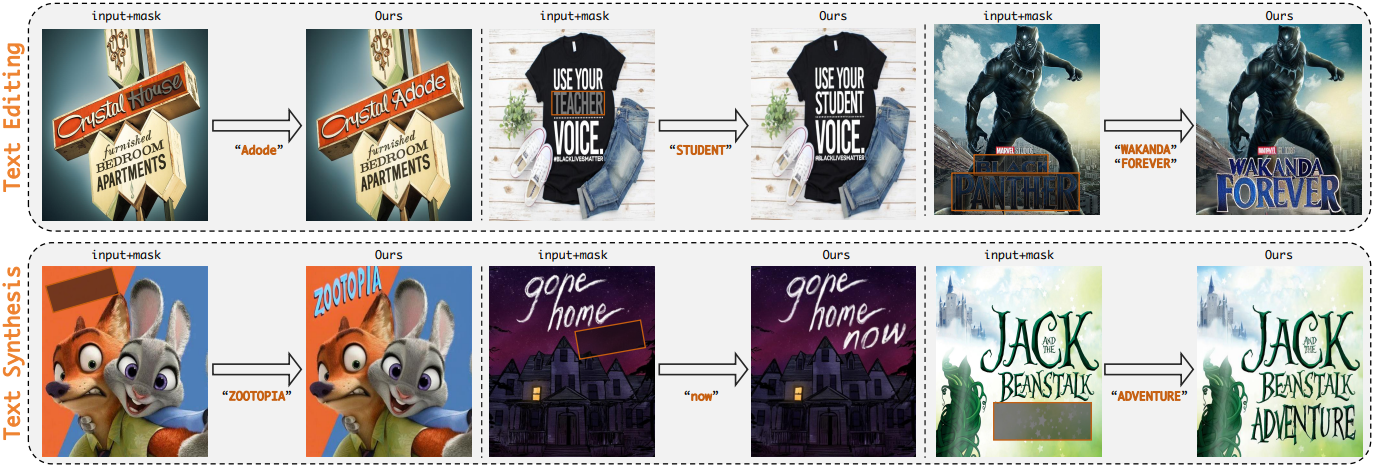
1. Results
다음은 기존 SOTA 방법들과의 비교 결과이다.



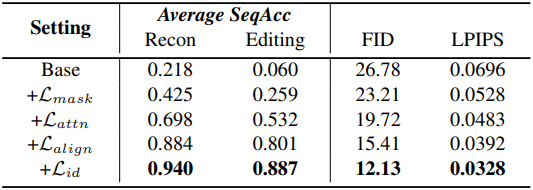
2. Ablation Studies
다음은 (왼쪽) loss와 (오른쪽) hyperparameter에 대한 ablation 결과이다.
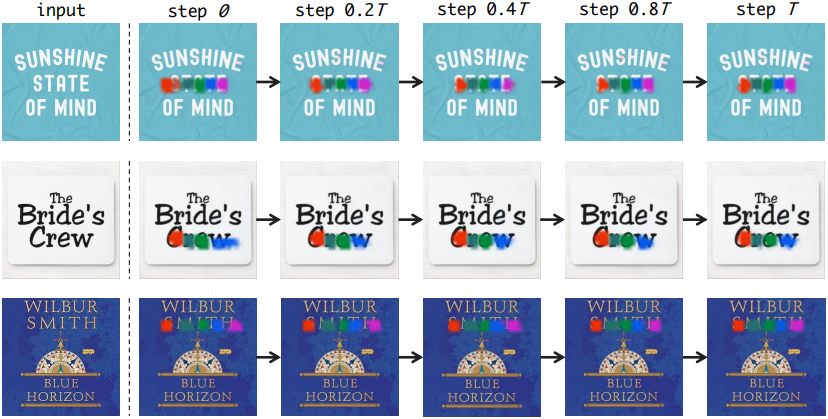
다음은 모든 문자에 대한 attention 결과를 step에 따라 시각화한 것이다.
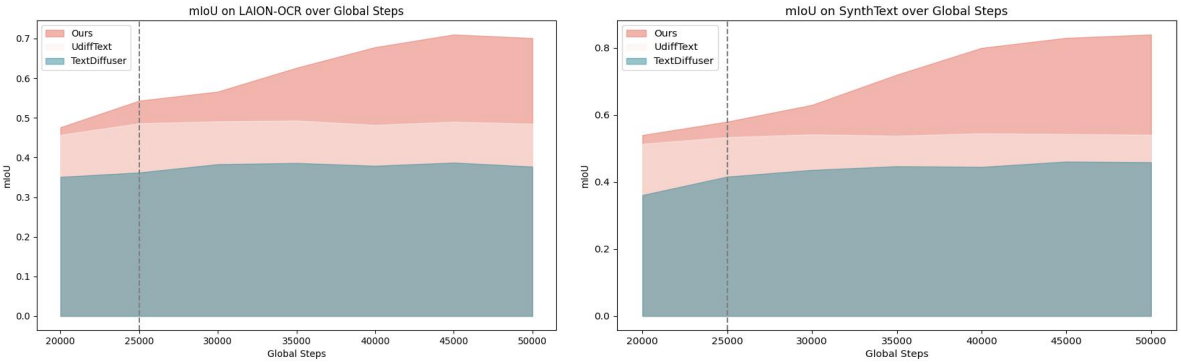
다음은 문자 생성 위치에 대한 mIoU를 비교한 그래프이다.
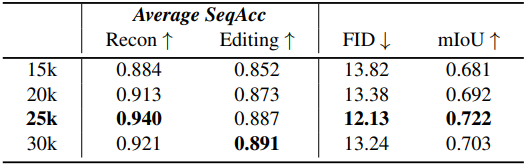
다음은 warm-up step에 대한 ablation 결과이다.