[논문리뷰] Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (DragGAN)
SIGGRAPH 2023. [Paper] [Page] [Github]
Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, Christian Theobalt
Max Planck Institute for Informatics | MIT CSAIL | Google AR/VR
18 May 2023

Introduction
GAN과 같은 생성 모델은 임의의 사실적인 이미지를 합성하는 데 전례 없는 성공을 거두었다. 실제 애플리케이션에서 이러한 학습 기반 이미지 합성 방법의 중요한 요구 사항은 합성된 시각적 콘텐츠에 대한 제어 가능성이다. 다양한 사용자 요구 사항을 충족시키기 위해 이상적인 제어 가능한 이미지 합성 접근 방식은 다음과 같은 속성을 가져야 한다.
- 유연성: 생성된 개체의 위치, 포즈, 모양, 표현, 레이아웃을 포함한 다양한 공간 속성을 제어할 수 있어야 한다.
- 정밀도: 높은 정밀도로 공간 속성을 제어할 수 있어야 한다.
- 일반성: 특정 범주에 국한되지 않고 다양한 개체 카테고리에 적용할 수 있어야 한다.
이전 연구들은 이러한 속성 중 한두 가지만 만족했지만, 본 논문에서는 모두 달성하는 것을 목표로 한다.
대부분의 이전 접근 방식은 prior 3D model 또는 수동으로 주석을 단 데이터에 의존하는 supervised learning을 통해 GAN의 제어 가능성을 얻는다. 따라서 이러한 접근 방식은 새로운 개체 카테고리로 일반화하지 못하거나 종종 제한된 범위의 공간 속성을 제어하거나 편집 프로세스에 대한 제어를 거의 제공하지 않는다. 최근에는 텍스트 기반 이미지 합성이 주목받고 있다. 그러나 텍스트 기반 방법은 공간 속성 편집 측면에서 정확성과 유연성이 부족하다. 예를 들어 특정 픽셀 수만큼 개체를 이동하는 데 사용할 수 없다.
GAN에 대하여 세 가지 속성을 모두 만족하기 위해 본 논문에서는 강력하지만 훨씬 덜 탐색된 대화형 포인트 기반 조작을 탐색한다. 구체적으로, 사용자가 이미지에서 핸들 포인트와 타겟 포인트를 얼마든지 클릭할 수 있도록 허용하며 핸들 포인트가 해당 타겟 포인트에 도달하도록 유도하는 것이 목표이다. 본 논문과 가장 가까운 설정을 가진 접근 방식은 UserControllableLT이다. 이와 비교하여, 본 논문에서는 두 가지 더 많은 도전을 가지고 있다.
- 하나 이상의 지점에 대한 제어를 고려한다.
- 핸들 포인트가 타겟 포인트에 정확하게 도달해야 한다.
이러한 대화형 포인트 기반 조작을 달성하기 위해 다음 두 가지 하위 문제를 해결하는 DragGAN을 제안한다.
- 핸들 포인트가 대상을 향해 이동하도록 감독한다.
- 핸들 포인트를 추적하여 각 편집 step에서 해당 위치를 알 수 있도록 한다.
DragGAN은 GAN의 feature space가 motion supervision과 정확한 포인트 추적을 모두 가능하게 할 만큼 충분히 discriminative하다는 점을 기반으로 한다. 구체적으로 motion supervision은 latent code를 최적화하는 shift된 feature patch loss를 통해 달성할 수 있다. 각 최적화 step은 핸들 포인트가 대상에 더 가깝게 이동하도록 한다. 따라서 포인트 추적은 feature space에서 nearest neighbor 검색을 통해 수행된다. 이 최적화 프로세스는 핸들 포인트가 타겟 포인트에 도달할 때까지 반복된다. 또한 DragGAN을 사용하면 사용자가 선택적으로 관심 영역을 그려 영역별 편집을 수행할 수 있다. DragGAN은 RAFT와 같이 추가 네트워크에 의존하지 않기 때문에 효율적인 조작이 가능하며 대부분의 경우 RTX 3090 GPU 1개에서 몇 초밖에 걸리지 않는다. 이를 통해 사용자가 원하는 출력을 얻을 때까지 다양한 레이아웃을 빠르게 반복할 수 있는 실시간 대화형 편집 세션이 가능하다.
Method
본 논문은 사용자가 이미지를 클릭하기만 하면 몇 개의 (핸들 포인트, 타겟 포인트) 쌍을 정의하고 핸들 포인트를 해당 타겟 포인트에 도달하도록 히는 GAN을 위한 대화형 이미지 조작 방법을 개발하는 것을 목표로 한다. 본 논문은 StyleGAN2 아키텍처를 기반으로 한다.
1. Interactive Point-based Manipulation
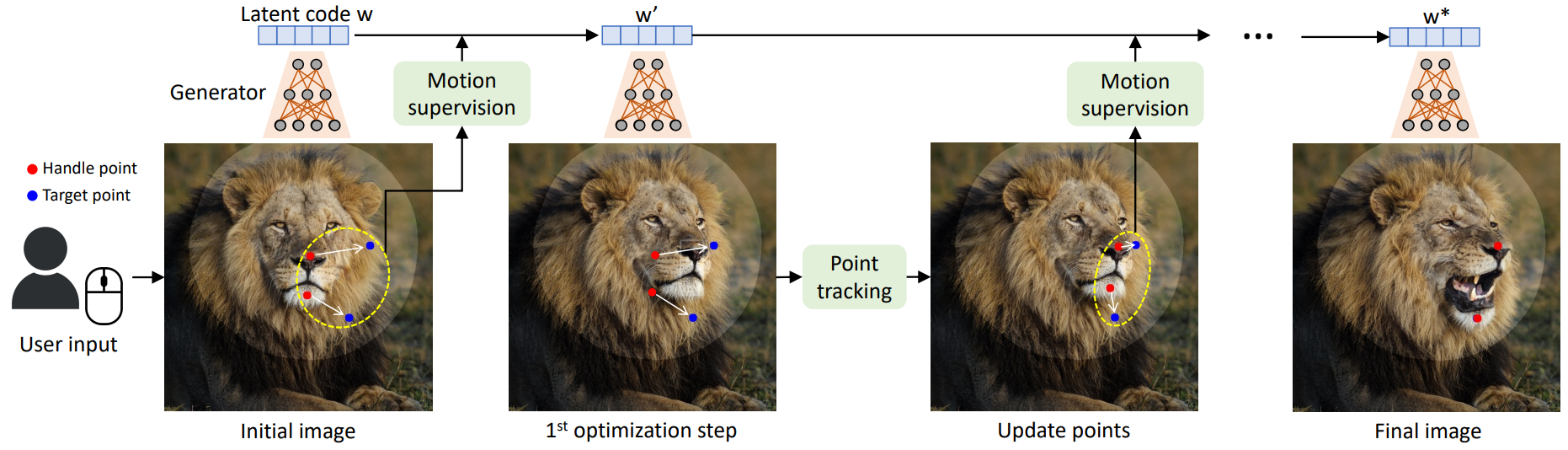
이미지 조작 파이프라인의 개요는 위 그림에 나와 있다. Latent code $w$를 사용하여 GAN에 의해 생성된 모든 이미지 $I \in \mathbb{R}^{3 \times H \times W}$에 대해 사용자가 여러 핸들 포인트 \(\{p_i = (x_{p,i}, y_{p,i}) \vert i = 1, 2, \cdots, n\}\)와 대응되는 타겟 포인트 \(\{t_i = (x_{t,i}, y_{t,i}) \vert i = 1, 2, \cdots, n\}\)를 입력한다 (즉, $p_i$에 $t_i$가 대응된다). 핸들 포인트의 semantic 위치가 해당 타겟 포인트에 도달하도록 이미지에서 개체를 이동하는 것이 목표이다. 또한 사용자가 이동 가능한 이미지 영역을 나타내는 binary mask $M$을 선택적으로 그릴 수 있다.
이러한 사용자 입력이 주어지면 최적화 방식으로 이미지 조작을 수행한다. 위 그림에서 볼 수 있듯이 각 최적화 step은
- Motion supervision (모션 감독)
- Point tracking (포인트 추적)
을 포함하는 두 개의 하위 step으로 구성된다. Motion supervision에서 핸들 포인트가 타겟 포인트를 향해 이동하도록 강제하는 loss는 latent code $w$를 최적화하는 데 사용된다. 한 번의 최적화 step 후에 새로운 latent code $w’$와 새로운 이미지 $I’$를 얻는다. 업데이트로 인해 이미지에서 개체가 약간 움직인다.
Motion supervision step은 각 핸들 포인트를 타겟을 향해 작은 step만 이동하지만 step의 정확한 길이는 복잡한 최적화 역학의 영향을 받기 때문에 명확하지 않다. 따라서 객체의 해당 포인트를 추적하기 위해 핸들 포인트 \(\{p_i\}\)의 위치를 업데이트한다. 핸들 포인트가 정확하게 추적되지 않으면 다음 motion supervision step에서 잘못된 포인트가 감독되어 원하지 않는 결과가 발생하기 때문에 이 추적 프로세스가 필요하다. 추적 후 새로운 핸들 포인트와 latent code를 기반으로 위의 최적화 step을 반복한다. 이 최적화 프로세스는 핸들 포인트 \(\{p_i\}\)가 타겟 포인트 \(\{t_i\}\)의 위치에 도달할 때까지 계속되며, 실험에서 일반적으로 30-200회 반복된다. 사용자는 중간 step에서 최적화를 중지할 수도 있다. 편집 후 사용자는 새 핸들 포인트와 타겟 포인트를 입력하고 결과에 만족할 때까지 계속 편집할 수 있다.
2. Motion Supervison
GAN 생성 이미지의 포인트 모션을 감독하는 방법은 이전에 많이 탐구되지 않았다. 본 논문에서는 추가 신경망에 의존하지 않는 motion supervision loss를 제안한다. 핵심 아이디어는 generator의 중간 feature가 매우 discriminative해서 간단한 loss만으로도 모션을 superise할 수 있다는 것이다. 구체적으로 StyleGAN2의 6번째 블록 이후의 feature map $F$를 고려한다. 이 feature는 해상도와 discriminativeness 사이의 적절한 균형으로 인해 모든 feature 중에서 가장 잘 수행된다. Bilinear interpolation을 통해 최종 이미지와 동일한 해상도를 갖도록 $F$의 크기를 조정한다.
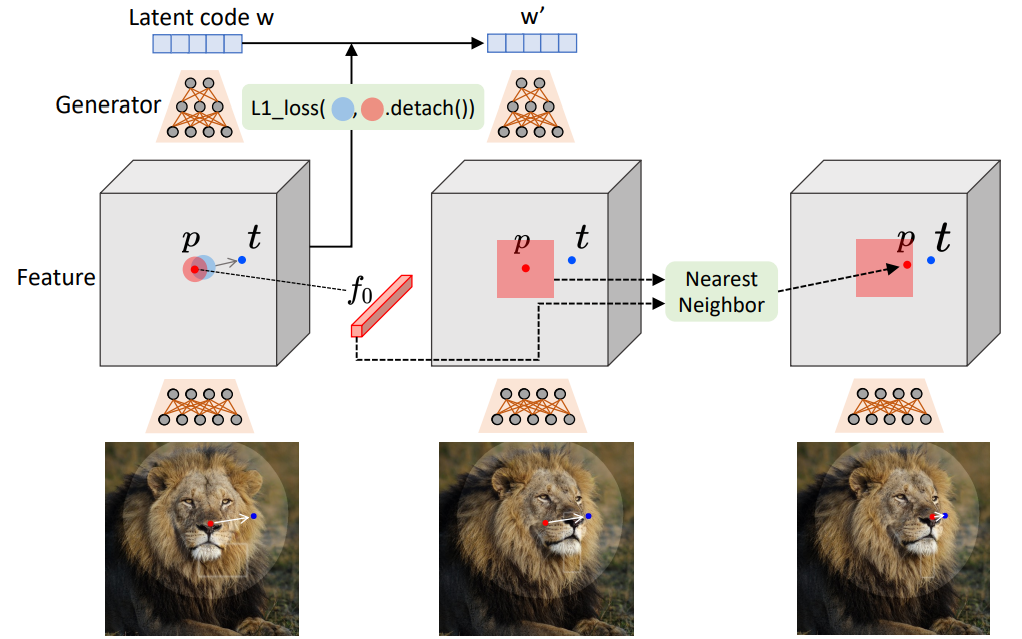
위 그림에서 볼 수 있듯이 핸들 포인트 $p_i$를 타겟 포인트 $t_i$로 이동하려면 $p_i$ (빨간색 원) 주변의 작은 패치를 감독하여 작은 step (파란색 원)만큼 $t_i$ 쪽으로 이동하는 것이 좋다. $\Omega (p_i, r_1)$를 사용하여 $p_i$까지의 거리가 $r_1$보다 작은 픽셀을 나타내며 motion supervision loss는 다음과 같다.
여기서 $F(q)$는 픽셀 $q$에서 $F$의 feature 값을 나타내며, $F_0$는 초기 이미지에 대응되는 feature map이다. 첫 번째 항은 모든 핸들 포인트 ${p_i}$에 대해 합산된다. $q_i + d_i$는 정수가 아니므로 bilinear interpolation을 통해 $F(q_i + d_i)$를 얻는다. 중요한 것은 이 loss를 사용하여 역전파를 수행할 때 기울기가 $F(q_i)$를 통해 흐르지 않는다는 것이다. 이것은 $p_i$가 $p_i + d_i$로 이동하도록 동기를 부여하지만 그 반대는 아니다. Binary mask $M$이 주어진 경우 마스크되지 않은 영역을 두 번째 항에서 표시된 재구성 loss로 고정된 상태로 유지한다.
각 motion supervision step에서 이 loss는 한 step에 대한 latent code $w$를 최적화하는 데 사용된다. $w$는 사용자가 더 제한된 이미지 manifold를 원하는지 여부에 따라 $\mathcal{W}$ space 또는 $\mathcal{W}^{+}$ space에서 최적화할 수 있다. $\mathcal{W}^{+}$ space는 out-of-distribution 조작을 달성하기 더 쉽기 때문에 더 나은 편집성을 위해 본 논문에서는 $\mathcal{W}^{+}$ space를 사용한다. 실제로 이미지의 공간 속성이 처음 6개 레이어의 $w$에 의해 주로 영향을 받는 반면 나머지 레이어는 모양에만 영향을 미친다. 따라서 style-mixing 테크닉에서 영감을 받아 처음 6개 레이어의 $w$만 업데이트하고 다른 레이어는 수정하여 모양을 유지한다. 이 선택적 최적화는 원하는 이미지 콘텐츠의 약간의 움직임으로 이어진다.
3. Point Tracking
이전 motion supervision의 결과로 새로운 latent code $w’$, 새로운 feature map $F’$, 새로운 이미지 $I’$가 생성된다. Motion supervision step은 핸들 포인트의 정확한 새 위치를 쉽게 제공하지 않기 때문에 여기서 목표는 객체의 해당 포인트를 추적하도록 각 핸들 포인트 $p_i$를 업데이트하는 것이다. Point tracking은 일반적으로 optical flow 추정 모델 또는 particle video 접근법을 통해 수행된다. 이러한 추가 모델은 특히 GAN에 앨리어스 아티팩트가 있는 경우 효율성을 크게 저하시킬 수 있으며 누적 오차로 인해 어려움을 겪을 수 있다.
따라서 본 논문은 GAN에 대한 새로운 point tracking 접근 방식을 제시한다. GAN의 discriminative한 특징이 밀집된 대응을 잘 포착하므로 특징 패치에서 nearest neighbor 검색을 통해 추적이 효과적으로 수행될 수 있다는 점을 이용한다. 구체적으로 초기 핸들 포인트의 feature를 $f_i = F_0 (p_i)$로 표시한다. $p_i$ 주변의 패치를
\[\begin{equation} \Omega_2 (p_i, r_2) = \{ (x,y) \; | \; |x - x_{p,i}| < r_2, |y - y_{p,i}| < r_2 \} \end{equation}\]로 나타낸다. 그런 다음 $\Omega_2 (p_i, r_2)$에서 $f_i$의 nearest nearest를 검색하여 추적 지점을 얻는다.
\[\begin{equation} p_i := \underset{q_i \in \Omega_2 (p_i, r_2)}{\arg \min} \| F' (q_i) - f_i \|_1 \end{equation}\]이런 식으로 $p_i$가 객체를 추적하도록 업데이트된다. 둘 이상의 핸들 포인트에 대해 각 포인트에 동일한 프로세스를 적용한다. 여기서는 StyleGAN2의 6번째 블록 이후의 feature map $F’$도 고려한다. Feature map은 256$\times$256의 해상도를 가지며 필요한 경우 이미지와 동일한 크기로 bilinear interpolation되므로 정확한 추적을 수행하기에 충분하다.
Experiments
- 데이터셋
- 512$\times$512: FFHQ, AFHQCat, SHHQ, LSUN Car, microscope
- 256$\times$256: LSUN Cat, Landscapes HQ
- self-distilled dataset: Lion (512), Dog (1024), Elephant (512)
- Implementation Details
- Adam optimizer
- learning rate: FFHQ, AFHQCat, LSUN Car는 $2 \times 10^{-3}$, 나머지는 $1 \times 10^{-3}$
- $\lambda = 20$, $r_1 = 3$, $r_2 = 12$
- 핸들 포인트가 타겟 포인트에서 $d$ 픽셀 이상 멀리 떨어지면 최적화 프로세스를 중지
- 핸들 포인트가 5개 이하인 경우 $d = 1$
- 핸들 포인트가 6개 이상인 경우 $d = 2$
1. Qualitative Evaluation
다음은 DragGAN을 UserControllableLT와 비교한 예시이다. 빨간 점이 핸들 포인트이고 파란 점이 타겟 포인트이다.

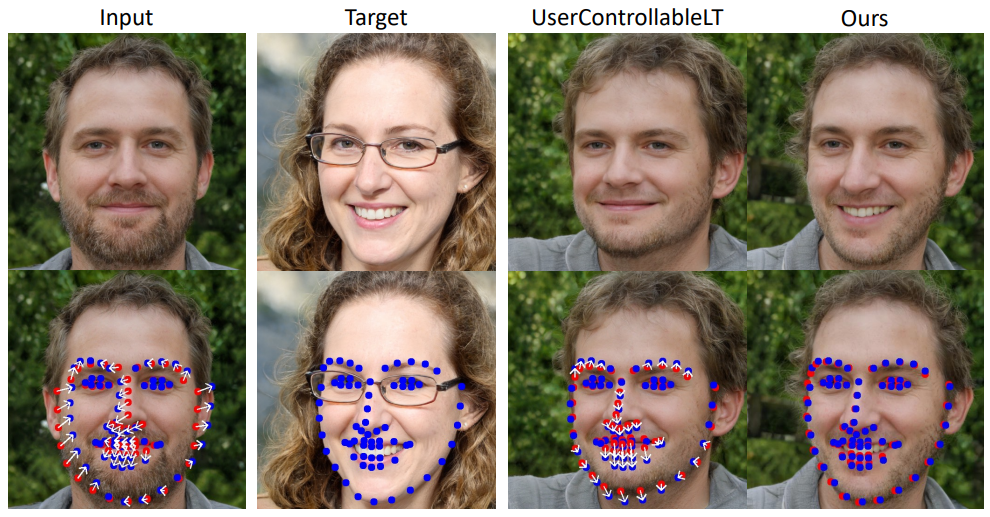
다음은 DragGAN을 RAFT, PIPs, tracking이 없는 DragGAN과 비교한 예시이다.

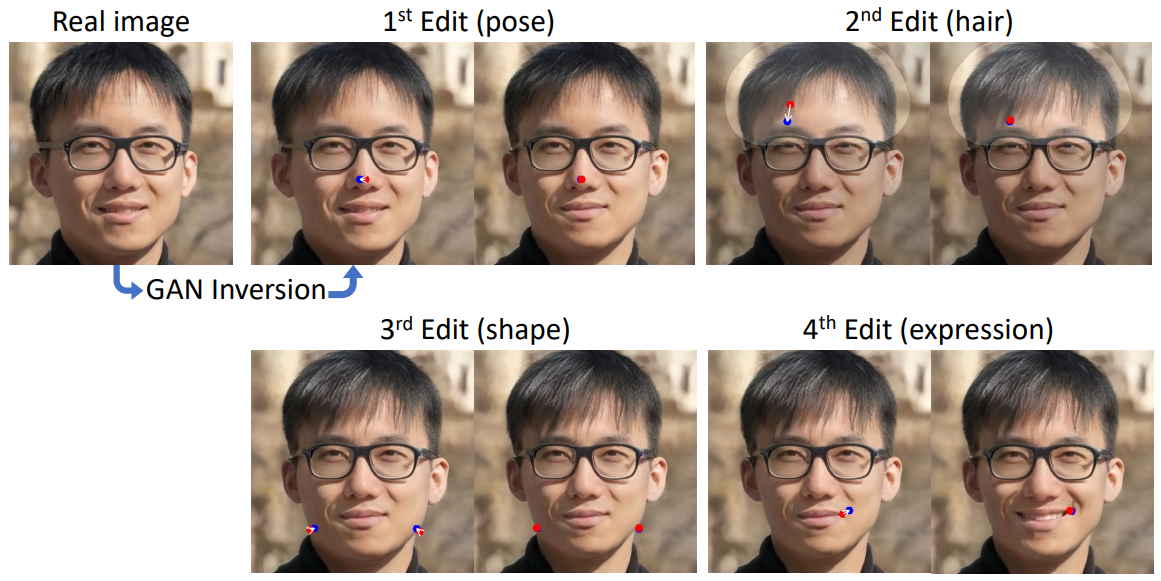
Real image editing
다음은 실제 이미지에 GAN inversion을 적용하여 StyleGAN의 latent space에 매핑한 후, 포즈, 머리카락, 모양, 표정을 연속해서 편집한 것이다.
2. Quantitative Evaluation
Face landmark manipulation
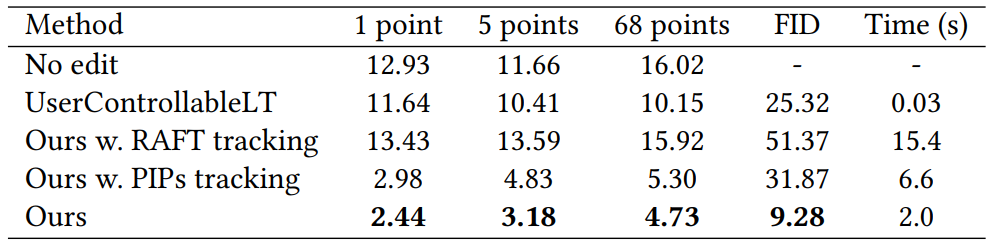
Paired image reconstruction

Ablation Study
다음은 사용한 feature에 대한 영향을 나타낸 표이다.

다음은 $r_1$의 영향을 나타낸 표이다.

3. Discussions
Effects of mask

Out-of-distribution manipulation
