[논문리뷰] Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation
CVPR 2024. [Paper] [Github]
Haofeng Liu, Chenshu Xu, Yifei Yang, Lihua Zeng, Shengfeng He
Singapore Management University | South China Normal University
1 Apr 2024

Introduction
Diffusion model에 내재된 제한된 제어 가능성으로 인해 이미지 조작 시 대화형 편집의 필요성을 커졌으며, 최근 다양한 대화형 접근 방식이 탄생하게 되었다. 보다 사용자 친화적이고 정확한 편집 방법에 대한 요구가 증가함에 따라 제어점의 드래그 앤 드롭 조작 구현이 실제 응용 프로그램에서 간단하고 효율적인 접근 방식으로 등장했다.
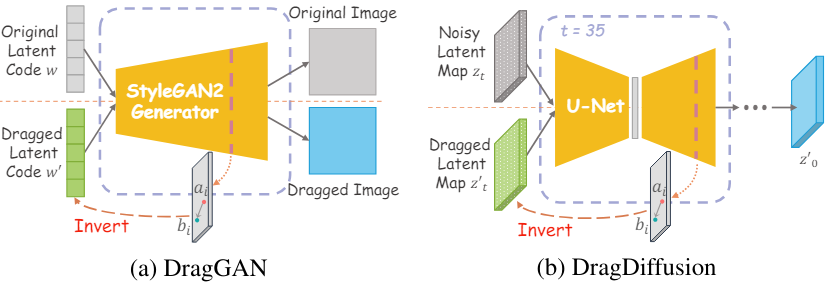
DragGAN은 GAN의 본질적인 제약으로 인해 고품질 편집 결과 달성이 제한되는 경우가 많다. 또한, 편집된 결과에 해당하는 새로운 latent code를 최적화하는 GAN 기반 편집 방법은 글로벌 콘텐츠를 보존하는 데 어려움을 겪는다. 실제 이미지를 latent code로 변환하는 전통적인 “outer-inversion”과 달리, 사용자 편집을 latent code로 inversion시키는 이러한 내부 최적화 프로세스를 “inner-inversion”이라고 부른다. DragDiffusion은 사전 학습된 대규모 모델의 장점을 활용하여 diffusion model을 적용하여 이 분야를 발전시켰지만 inner-inversion을 고수하였다. 이 방법은 의도된 편집을 반영하는 출력을 생성하기 위해 중간의 noisy latent map의 최적화를 가이드한다.
그러나 DragDiffusion에서는 기울기 소실 (gradient vanishing)과 inversion 충실도라는 두 가지 주요 문제가 발생한다. 기울기 소실은 드래그 전후의 feature 차이를 기반으로 하는 motion supervision loss에 대한 의존으로 인해 발생한다. 이 문제는 feature 차이가 최소화되고 inversion의 역전파 체인이 길어 결과가 “under-dragging”되는 경우 더욱 악화된다. 또한 재구성 충실도를 유지하는 것은 inversion 기술에서 오랜 과제로 남아 있다. DragDiffusion은 “inner-inversion”을 2D latent map으로 확장하여 DragGAN의 1D latent code 최적화를 능가하고 공간 제어를 향상시키지만, noisy latent map으로 돌아가는 최적화 경로로 인해 세밀한 재구성에 여전히 어려움을 겪고 있다.
Diffusion semantic 분석
이전 연구들에서는 noise predictor의 중간 diffusion feature가 semantic 정보를 효과적으로 포착할 뿐만 아니라 구조-외관 제어 가능성을 촉진한다는 사실이 입증되었다. 이로부터 영감을 받아 본 논문은 latent map을 재추적할 필요성을 재평가하고 편집 메커니즘 내에서 diffusion semantic을 탐구하였다. 처음에는 사전 학습된 Stable Diffusion 모델에 대해 DDIM inversion을 사용하여 feature 분석을 수행하였다. 다양한 U-Net 레이어에서 학습된 semantic을 이해하기 위해 이러한 레이어의 feature를 복사하고 다양한 timestep부터 시작하여 모든 후속 U-Net의 해당 feature를 대체하였다. 이는 diffusion model이 semantic 지식을 언제 어디서 학습하는지 보여주기 위한 것이다. 결과 이미지와 정량적 결과는 아래와 같다.

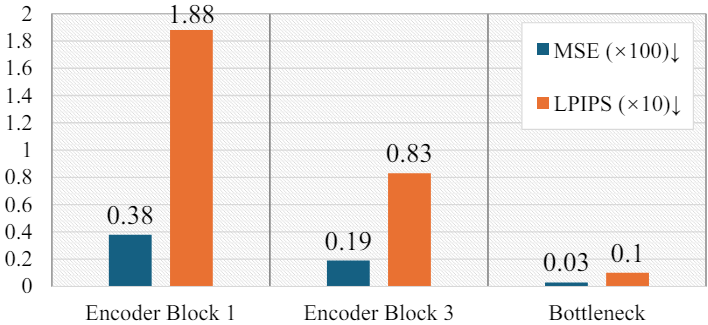
U-Net 인코더가 feature를 점진적으로 축소하기 때문에 네트워크가 bottleneck에 접근함에 따라 더 높은 수준의 feature를 얻을 수 있다. 위 결과의를 보면 낮은 수준의 feature를 대체하면 이미지 재구성 디테일과 품질이 손상된다는 것을 보여준다. 이 결과는 최종 단계에서 미세한 텍스처를 추가하는 것과 같이 공유할 수 없는 다양한 timestep에서 하위 수준 feature의 고유한 역할에 기인한다. 반면, noise predictor에서 높은 수준의 feature를 생성하는 bottleneck은 초기 timestep에서도 보다 완전한 semantic을 포착할 수 있다. 일반적으로 나중 timestep에서 feature를 복사하고 교체하면 원본 이미지를 더 잘 재구성할 수 있다. 그러나 $t=45$에서는 bottleneck feature가 개의 대략적인 윤곽을 포착할 수 있지만 귀와 다리와 같은 더 미세한 디테일은 누락될 수 있다. 흥미롭게도, $t=35$의 bottleneck feature를 대체하면 전체 구조가 보존되고, 이 초기 timestep의 semantic을 이후 timestep으로 전파해도 재구성 품질이 저하되지 않는다.
이러한 결과를 통해 bottleneck feature가 최적의 diffusion semantic 표현을 나타내며 특히 효율적인 편집에 적합하다는 결론을 내릴 수 있다. 초기 timestep에서 효과적으로 학습할 수 있으므로 bottleneck feature를 조작하면 이후 timestep으로 원활하게 전파될 수 있어 완전한 diffusion semantic의 무결성이 유지된다. 또한, 짧은 최적화 경로로 인해 기울기 소실 문제를 효율적으로 피할 수 있다.
Semantic 편집기로서의 noise map
본 논문은 위와 같은 분석을 바탕으로 diffusion semantic 전파를 활용하는 대화형 포인트 기반 이미지 편집 방법인 DragNoise를 소개한다. DragNoise의 근거는 예측된 noise를 순차적 semantic 편집기로 처리하는 것이다. 편집 프로세스는 높은 수준의 semantic이 잘 학습된 timestep (ex. $t=35$)에서 시작된다. 이 timestep에서는 사용자 편집 내용을 반영하기 위해 U-Net의 bottleneck에 대한 diffusion semantic 최적화가 수행된다. 최적화된 bottleneck feature는 의도한 드래그 효과를 학습하고 해당 manipulation noise를 생성한다. 이 최적화된 bottleneck feature에는 타겟 semantic이 포함되어 있으므로 중복되는 feature 최적화를 피하면서 해당 bottleneck feature을 대체하여 모든 후속 timestep으로 전파된다. 이러한 대체는 안정적이고 효율적인 방식으로 조작 효과를 크게 향상시킨다. 특히 DragNoise는 DragDiffusion에 비해 최적화 시간을 50% 이상 크게 단축하였다.
Methodology
1. Diffusion Semantic Optimization
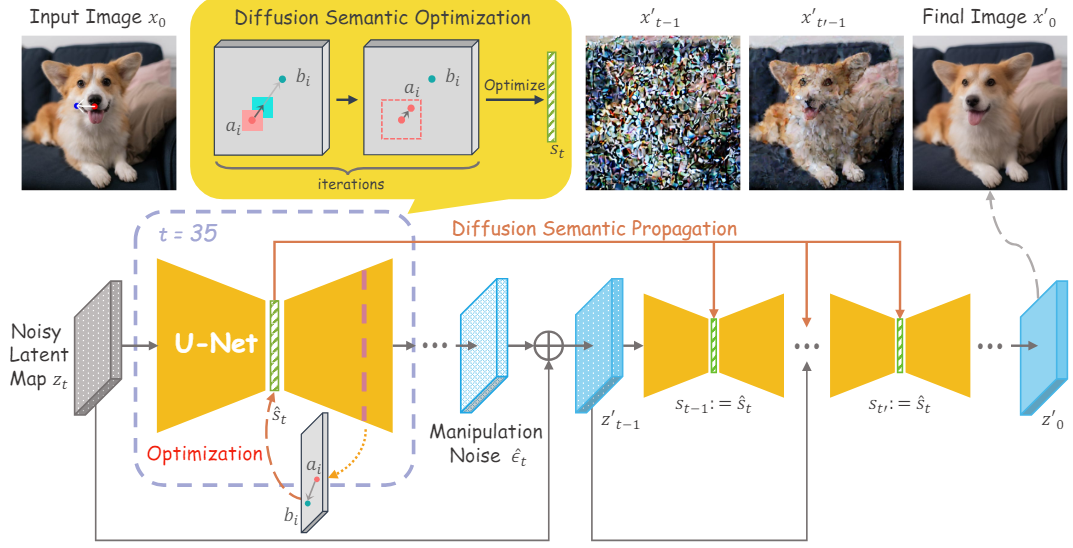
전체 방법의 개요는 위와 같다. Diffusion model에서 U-Net의 bottleneck feature는 다른 feature 비해 더 포괄적인 noise semantic을 캡처하는 능력을 가지고 있다. 또한 bottleneck feature는 특정 초기 timestep $t$에서 대부분의 semantic을 효율적으로 포착한다. 따라서 사용자의 포인트 입력이 주어지면 이 timestep에서 bottleneck feature을 사용하여 diffusion semantic 최적화를 수행한다.
사용자가 제공한 앵커 포인트를 \(\{a_i = (x_i^a, y_i^a)\}_{i=1,\ldots,m}\)으로 표시하고 대응되는 타겟 포인트를 \(\{b_i = (x_i^b, y_i^b)\}_{i=1,\ldots,m}\)로 표시하자. 여기서 $m$은 포인트 쌍의 수이다. 포인트와 bottleneck 간의 직접적인 공간 매핑은 추상화 수준의 상당한 차이로 인해 어려움이 있다. 이를 극복하기 위해 중간 feature를 추가로 도입한다. Label-Efficient Semantic Segmentation with Diffusion Models 논문에 따르면 U-Net 디코더의 세 번째 레이어의 feature는 정보가 풍부하고 구조를 인식한다. 따라서 이러한 feature를 supervision에 활용하여 포괄적인 구조 표현과 디테일의 세분성 사이의 균형을 달성한다. 구체적으로, bilinear interpolation을 통해 이 feature map에서 점 $p$에 해당하는 feature 성분 $F_p$를 얻는다. 앵커 포인트의 구조적 feature를 타겟 포인트에 정렬하기 위해 semantic alignment loss \(\mathcal{L}_\textrm{alignment}\)를 다음과 같이 정의한다.
\[\begin{equation} \mathcal{L}_\textrm{alignment} = \sum_{i=1}^m \sum_{p_i \in \Omega (a_i, r_1)} \| F_{p_i} - F_{p_i + v_i} \|_1 \\ \textrm{where} \quad v_i = \frac{b_i - a_i}{\| b_i - a_i \|_2}, \quad \Omega (a_i, r_1) = \{(x, y) \;\vert\; \vert x - x_i^a \vert \le r_1, \vert y - y_i^a \vert \le r_1 \} \end{equation}\]$v_i$는 $a_i$에서 $b_i$를 가리키는 정규화된 벡터이며 $\Omega (a_i, r_1)$은 앵커 포인트의 neighborhood이다. \(\mathcal{L}_\textrm{alignment}\)는 앵커 포인트 근처의 포인트 feature를 작은 step만큼 타겟 포인트 근처의 포인트 쪽으로 끌어당긴다. 또한 마스크가 제공되면 semantic masking loss \(\mathcal{L}_\textrm{mask}\)를 사용하여 마스크 외부의 bottleneck feature을 변경하지 않고 유지한다.
\[\begin{equation} \mathcal{L}_\textrm{mask} = \| (s_t - \hat{s}_t) \odot (1 - M) \|_1 \end{equation}\]여기서 $s_t$는 timestep $t$에서의 bottleneck feature이고 \(\hat{s}_t\)는 최적화된 feature이다. Bottleneck의 향상된 semantic 분리로 인해 일반적으로 대부분의 경우 마스크가 필요하지 않다.
모든 iteration에서 위의 loss 항들을 사용하여 manipulation noise 생성에 영향을 미치도록 bottleneck feature을 업데이트한다. 전체적으로 최적화 목표는 다음과 같이 정의된다.
\[\begin{equation} \hat{s}_t = \underset{s_t}{\arg \min} (\mathcal{L}_\textrm{alignment} + \lambda \mathcal{L}_\textrm{mask}) \end{equation}\]역전파 중에는 기울기가 \(F_{p_i}\)를 통해 역전파되지 않는다.
각 iteration 후에 bottleneck feature과 앵커 포인트의 해당 feature 성분이 업데이트된다. 방정식과 같이. \(\mathcal{L}_\textrm{alignment}\)가 최적화 iteration에 대한 정확한 방향을 더 이상 제공하지 않으므로 각 iteration 후에 앵커 포인트의 위치를 업데이트해야 한다. 따라서 $a_i$의 neighborhood $\Omega (a_i, r_2)$에서 최적화된 feature의 nearest neighbor를 찾아 업데이트한다.
\[\begin{equation} a_i := \underset{p_i \in \Omega (a_i, r_2)}{\arg \min} \| F_{p_i}^\prime - f_i^0 \|_1 \\ \textrm{where} \quad \Omega (a_i, r_2) = \{(x, y) \;\vert\; \vert x - x_i^a \vert \le r_2, \vert y - y_i^a \vert \le r_2 \} \end{equation}\]여기서 \(F_{p_i}^\prime\)는 업데이트된 feature map에서 $p_i$의 feature 성분이고, $f_i^0$는 초기 앵커 포인트의 feature 성분이다.
마지막으로, 앵커 포인트와 대응되는 타겟 포인트 사이의 거리가 모두 1픽셀 이내이거나 최대 iteration에 도달하면 최적화가 종료된다. 최적화된 bottleneck feature \(\hat{s}_t\)를 사용하여 U-Net의 디코더는 manipulation noise \(\hat{\epsilon}_\theta\)를 생성한다.
2. Diffusion Semantic Propagation
Manipulation noise \(\hat{\epsilon}_\theta\)는 이미지 생성에 대한 denoising 방향을 수정한다. 그러나 저자들은 후속 denoising process가 단순히 한 timestep에서 diffusion semantic 최적화를 수행하여 조작 효과를 잊어버리는 문제를 관찰하였다. Bottleneck feature를 이후 timestep으로 전파하는 것이 전체 semantic에 큰 영향을 미치지 않는 것처럼, 이 최적화된 bottleneck feature들을 복사하여 후속 timestep에서 대체한다. 이는 noise 예측을 위한 조작을 계속 강조하는 편집 단계로 간주된다. 마지막 timestep 몇 개에서는 이미지의 구조가 본질적으로 구체화되기 때문에 timestep $t^\prime$ 후에 bottleneck feature 교체를 중단한다. Denoising process에서 diffusion semantic 전파 후에 생성된 출력 latent map $z_0^\prime$을 얻어 최종 이미지 $x_0^\prime$을 생성한다.
Experiments
1. Qualitative Evaluations
다음은 여러 기존 방법들과 편집 결과를 비교한 것이다.

다음은 다양한 이미지들에 대한 편집 결과를 DragDiffusion과 비교한 것이다.
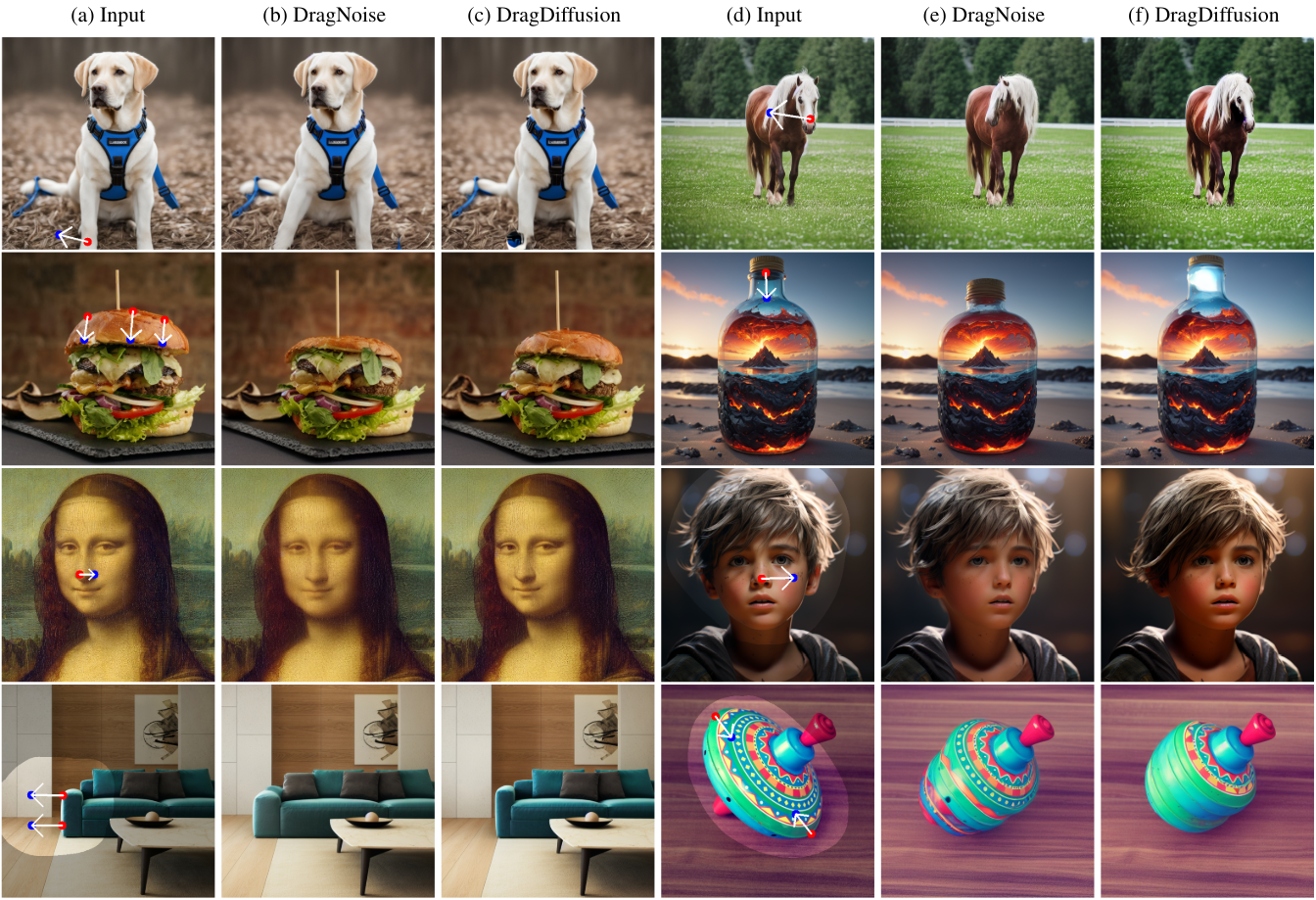
다음은 여러 포인트로 편집을 수행한 예시이다.

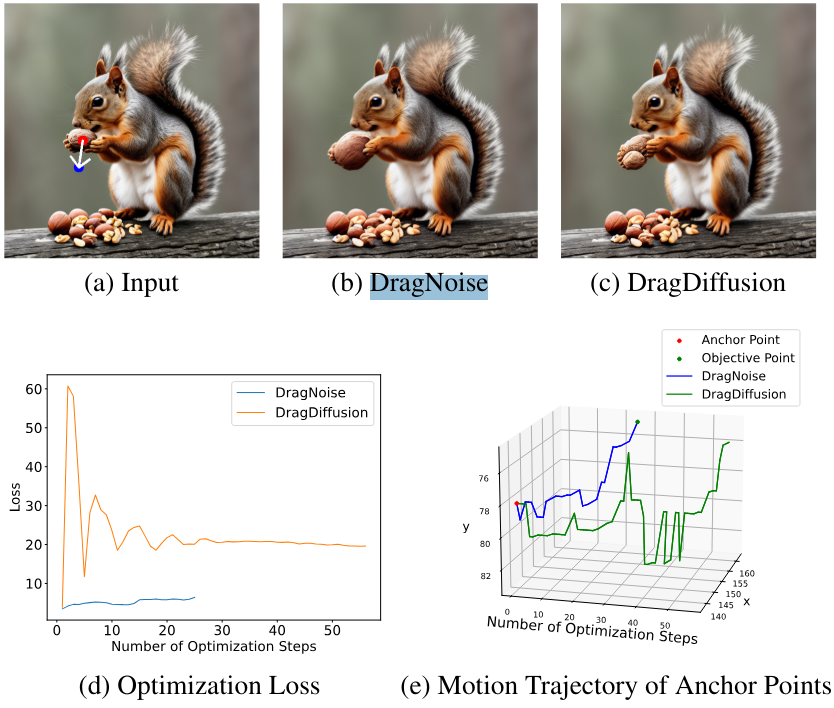
2. Analysis of Optimization Efficiency
다음은 DragNoise의 최적화 효율성을 DragDiffusion과 비교한 것이다.
3. Ablation Study
다음은 서로 다른 초기 timestep으로 편집 프로세스를 시작하면서 동일한 드래그 연산을 수행한 결과이다.

다음은 U-Net의 여러 feature layer들을 최적화 대상으로 사용하였을 때의 결과를 비교한 것이다.

다음은 최적화된 bottleneck feature를 denoising process에 복사하고 여러 timestep에서 전파를 중지한 결과를 비교한 것이다.

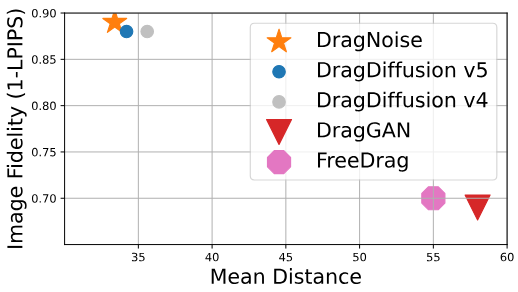
4. Quantitative Analysis
다음은 DragBench에서 편집 정확도 및 충실도를 비교한 그래프이다.
Limitation

DragDiffusion과 마찬가지로 원본 충실도를 유지하면서 실제 이미지를 처리하는 데 어려움이 있다. 현재 편집 과정에서 실제 이미지의 무결성을 유지하기 위해 LoRA와 같은 방법을 사용한다. 이는 효과적이지만 때로는 편집 능력의 범위와 깊이를 제한할 수 있다. 또한 위 그림에서 볼 수 있듯이 의도한 회전을 실행하는 데 때때로 실패한다.