[논문리뷰] Vision Transformers for Dense Prediction (DPT)
arXiv 2021. [Paper] [Github]
René Ranftl, Alexey Bochkovskiy, Vladlen Koltun
Intel Labs
24 Mar 2021
Introduction
Dense prediction을 위한 거의 모든 기존 아키텍처는 CNN을 기반으로 한다. Dense prediction 아키텍처의 디자인은 일반적으로 네트워크를 논리적으로 인코더와 디코더로 분리하는 패턴을 따른다. 인코더는 backbone이라고도 하는 이미지 분류 네트워크를 기반으로 하는 경우가 많으며, ImageNet과 같은 대규모 코퍼스에서 사전 학습된다. 디코더는 인코더의 feature를 집계하여 최종 dense prediction으로 변환한다. Dense prediction에 대한 아키텍처 연구는 디코더와 그 집계 전략에 초점을 맞추는 경우가 많다. 그러나 인코더에서 손실된 정보는 디코더에서 복구할 수 없기 때문에 backbone 아키텍처의 선택이 전체 모델의 능력에 큰 영향을 미친다는 것은 널리 알려져 있다.
Convolutional backbone은 입력 이미지를 점진적으로 다운샘플링하여 다양한 스케일의 feature를 추출한다. 다운샘플링을 사용하면 receptive field의 점진적으로 증가시키고, 낮은 레벨의 feature를 추상적인 높은 레벨의 feature로 그룹화하며, 동시에 네트워크의 메모리 및 계산 요구 사항을 다루기 쉬운 상태로 유지할 수 있다. 그러나 다운샘플링에는 dense prediction task에서 특히 두드러지는 뚜렷한 단점이 있다. 즉, 모델의 더 깊은 단계에서 특징 해상도와 세분성이 손실되므로 디코더에서 복구하기 어려울 수 있다. 특징 해상도 및 세분성은 이미지 분류와 같은 일부 task에서는 중요하지 않을 수 있지만 아키텍처가 이상적으로 입력 이미지의 해상도 또는 그에 가까운 feature를 해결할 수 있어야 하는 dense prediction에는 중요하다.
Feature 세분성의 손실을 완화하기 위한 다양한 기술이 제안되었다. 여기에는 더 높은 입력 해상도에서의 학습, 다운샘플링 없이 receptive field를 빠르게 증가시키는 dilated convolution, 인코더의 여러 단계에서 디코더로 적절하게 배치된 skip connection, 네트워크 전반에 걸친 여러 해상도 표현의 병렬 연결 등이 포함된다. 이러한 기술은 예측 품질을 크게 향상시킬 수 있지만 네트워크는 여전히 기본 구성 요소인 convolution으로 인해 병목 현상이 발생한다. Non-linearity와 함께 convolution은 이미지 분석 네트워크의 기본 계산 단위를 형성한다. 정의에 따르면 convolution은 제한된 receptive field를 갖는 선형 연산자이다. 제한된 receptive field와 개별 convolution의 제한된 표현성으로 인해 충분히 광범위한 컨텍스트와 충분히 높은 표현력을 확보하려면 매우 깊은 아키텍처에 순차적 스태킹이 필요하다. 그러나 이를 위해서는 많은 양의 메모리가 필요한 많은 중간 표현을 생성해야 한다. 기존 컴퓨터 아키텍처에서 실행 가능한 수준으로 메모리 소비를 유지하려면 중간 표현을 다운샘플링해야 한다.
본 연구에서는 Dense Prediction Transformer (DPT)를 소개한다. DPT는 transformer를 인코더의 기본 계산 빌딩 블록으로 활용하는 인코더-디코더 디자인을 기반으로 하는 dense prediction 아키텍처이다. 특히 최근 제안된 Vision Transformer (ViT)를 backbone 아키텍처로 사용한다. ViT가 제공하는 bag-of-words 표현을 다양한 해상도의 이미지와 같은 feature 표현으로 재조립하고 convolutional 디코더를 사용하여 feature 표현을 최종 dense prediction으로 점진적으로 결합한다. CNN과 달리 ViT backbone은 초기 이미지 임베딩이 계산된 후 명시적 다운샘플링 연산을 생략하고 모든 처리 단계에서 일정한 차원으로 표현을 유지한다. 또한 모든 단계에서 글로벌 receptive field를 갖추고 있다. 이러한 속성은 자연스럽게 세밀하고 전체적으로 일관된 예측으로 이어지기 때문에 dense prediction task에 특히 유리하다.
저자들은 monocular depth estimation과 semantic segmentation에 대한 실험을 수행하였다. 대규모 학습 데이터를 사용할 수 있는 범용적인 monocular depth estimation task의 경우 DPT는 SOTA 성능의 CNN와 비교할 때 28% 이상의 성능 향상을 제공한다. 또한 이 아키텍처는 NYUv2와 KITTI와 같은 작은 monocular depth estimation 데이터셋에 맞게 fine-tuning될 수 있으며, 이는 새로운 SOTA를 달성하였다. Semantic segmentation의 경우 DPT는 까다로운 ADE20K와 Pascal Context 데이터셋에 대한 새로운 SOTA를 달성하였다. 정량적 결과는 개선이 CNN에 비해 더 세밀하고 글로벌하게 일관된 예측에 기인할 수 있음을 나타낸다.
Architecture
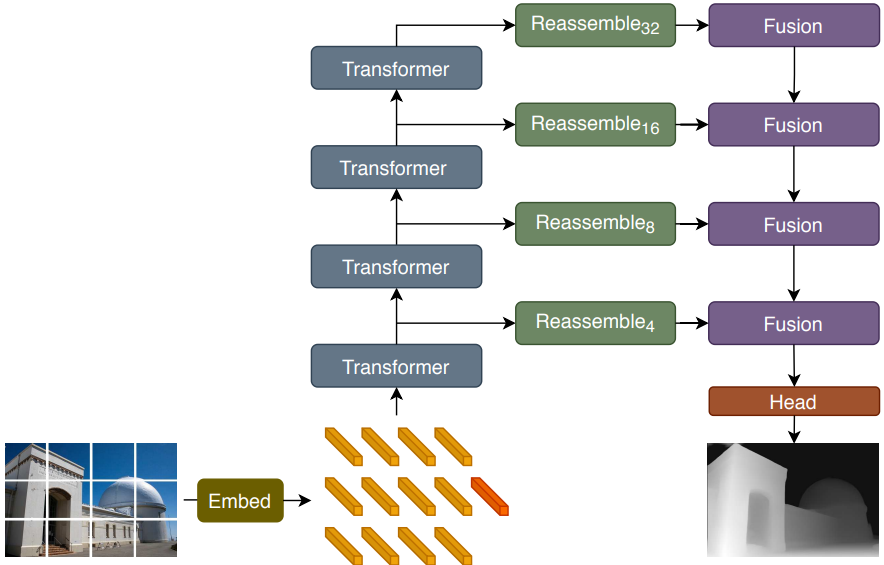
이전에 dense prediction에 성공했던 전체적인 인코더-디코더 구조를 유지한다. 본 논문은 ViT를 backbone으로 활용하고, 이 인코더에서 생성된 표현이 어떻게 효과적으로 dense prediction으로 변환될 수 있는지 보여주고, 이 전략의 성공을 위한 직관을 제공한다. 전체 아키텍처의 개요는 위 그림에 나와 있다.
Transformer encoder
높은 수준에서 ViT는 이미지의 bag-of-words 표현으로 작동한다. Feature space에 개별적으로 임베딩된 이미지 패치 또는 이미지에서 추출된 feature가 “단어”의 역할을 한다. 임베딩된 “단어”를 토큰이라 부른다. Transformer는 표현을 변환하기 위해 토큰을 서로 연관시키는 Multi-headed Self-Attention (MHSA)의 순차 블록을 사용하여 토큰 집합을 변환한다.
중요한 점은 ViT가 모든 계산 전반에 걸쳐 토큰 수를 유지한다는 것이다. 토큰은 이미지 패치와 일대일 대응을 가지므로 이는 ViT 인코더가 모든 transformer 단계에서 초기 임베딩의 공간 해상도를 유지한다는 것을 의미한다. 또한 MHSA는 모든 토큰이 다른 모든 토큰에 attend하고 영향을 미칠 수 있으므로 본질적으로 글로벌 연산이다. 결과적으로 transformer는 초기 임베딩 이후 모든 단계에서 글로벌 receptive field를 갖는다. 이는 연속적인 convolution 및 다운샘플링 레이어를 통과함에 따라 feature가 receptive field를 점진적으로 증가시키는 CNN과는 완전히 대조적이다.
보다 구체적으로 ViT는 이미지에서 $p^2$ 크기의 픽셀의 겹치지 않는 모든 정사각형 패치를 처리하여 이미지에서 임베딩된 패치를 추출한다. 패치는 벡터로 flatten되고 linear projection을 사용하여 개별적으로 임베딩된다. 샘플 효율이 더 높은 ViT의 대안은 ResNet50을 이미지에 적용하여 임베딩을 추출하고 결과 feature map의 픽셀 feature를 토큰으로 사용하는 것이다. Transformer는 집합 대 집합 함수이므로 개별 토큰의 공간 위치 정보를 본질적으로 유지하지 않는다. 따라서 이미지 임베딩은 학습 가능한 위치 임베딩과 연결되어 이 정보를 표현에 추가한다. NLP의 연구들을 따라 ViT는 입력 이미지에 기반하지 않고 분류에 사용되는 최종 글로벌 이미지 표현 역할을 하는 특수 토큰을 추가한다. 이 특수 토큰을 readout 토큰이라고 한다. $H \times W$ 크기의 픽셀 이미지에 임베딩 절차를 적용한 결과는 토큰 $t_n^0 \in \mathbb{R}^D$의 집합 \(t^0 = \{t_0^0, \ldots, t_{N_p}^0\}\)이며, 여기서 $N_p = \frac{HW}{p^2}$이고, $t_0$은 readout 토큰을 나타내고 $D$는 각 토큰의 feature 차원이다.
입력 토큰은 $L$개의 transformer 레이어를 사용하여 새로운 표현인 $t^l$로 변환된다. 여기서 $l$은 $l$번째 transformer 레이어의 출력을 나타낸다. ViT 논문은 이 기본 청사진의 여러 변형을 정의하였다. 본 논문에서는 세 가지 변형을 사용한다.
- ViT-Base: 패치 기반 임베딩 절차를 사용하고 12개의 transformer 레이어를 사용
- ViT-Large: 패치 기반 임베딩 절차를 사용하고 24개의 transformer 레이어와 더 넓은 feature 크기 $D$를 사용
- ViT-Hybrid: ResNet50을 사용하여 이미지 임베딩과 12개의 transformer 레이어를 계산
본 논문은 모든 실험에 패치 크기 $p = 16$을 사용한다.
ViT-Base와 ViT-Large에 대한 임베딩 절차는 flatten된 패치를 각각 차원 $D = 768$과 $D = 1024$로 project한다. 두 feature 차원 모두 입력 패치의 픽셀 수보다 크므로 이는 임베딩 절차가 task에 도움이 되는 경우 정보를 유지하는 방법을 학습할 수 있음을 의미한다. 입력 패치의 feature은 원칙적으로 픽셀 레벨의 정확도로 해결될 수 있다. 마찬가지로 ViT-Hybrid 아키텍처는 입력 해상도의 $\frac{1}{16}$배에서 feature를 추출한다. 이는 일반적으로 convolution backbone에 사용되는 최저 해상도 feature보다 두 배 높다.
Convolutional decoder
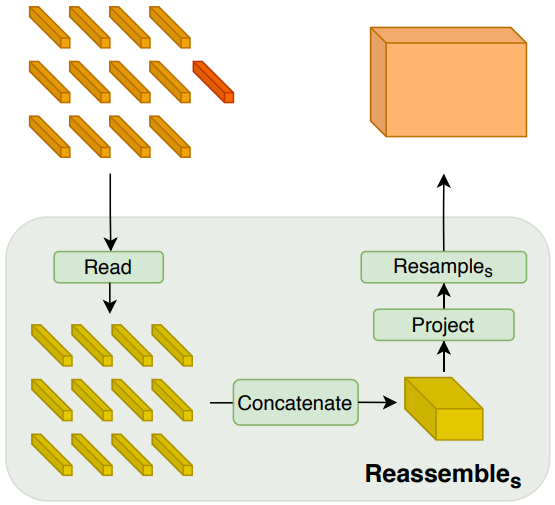
디코더는 토큰 집합을 다양한 해상도의 feature 표현으로 조립한다. Feature 표현은 점진적으로 최종 dense prediction에 융합된다. Transformer 인코더의 임의 레이어의 출력 토큰에서 이미지와 같은 표현을 복구하기 위한 간단한 3단계 Reassemble 연산을 사용한다.
여기서 $s$는 입력 이미지에 대한 복구된 표현의 출력 크기 비율이며, $\hat{D}$는 출력 feature 차원이다.
먼저 $N_p + 1$개의 토큰을 공간적으로 concatenation이 가능한 $N_p$개의 토큰 집합에 매핑한다.
\[\begin{equation} \textrm{Read} : \mathbb{R}^{(N_p + 1) \times D} \mapsto \mathbb{R}^{N_p \times D} \end{equation}\]이 연산은 기본적으로 readout 토큰을 적절하게 처리하는 역할을 한다. Readout 토큰은 dense prediction task에 대한 명확한 목적을 제공하지 않지만 잠재적으로 글로벌 정보를 캡처하고 배포하는 데 유용할 수 있으므로 저자들은 이 매핑의 세 가지 변형을 평가하였다.
\[\begin{aligned} \textrm{Read}_\textrm{ignore} (t) &= \{t_1, \ldots, t_{N_p}\} \\ \textrm{Read}_\textrm{add} (t) &= \{t_1 + t_0, \ldots, t_{N_p} + t_0\} \\ \textrm{Read}_\textrm{proj} (t) &= \{\textrm{mlp} (\textrm{cat} (t_1, t_0)), \ldots, \textrm{mlp} (\textrm{cat} (t_{N_p}, t_0))\} \end{aligned}\]$\textrm{mlp}$의 경우 linear layer와 GELU non-linearity를 사용하여 표현을 원래 feature 차원 $D$에 project한다.
Read 블록 이후, $N_p$개의 토큰은 이미지의 초기 패치 위치에 따라 각 토큰을 배치하여 이미지 모양의 표현으로 재구성될 수 있다. $D$ 채널을 갖는 $\frac{H}{p} \times \frac{W}{p}$ 크기의 feature map을 생성하는 공간적 concatenation 연산을 적용한다.
\[\begin{equation} \textrm{Concatenate} : \mathbb{R}^{N_p \times D} \mapsto \mathbb{R}^{\frac{H}{p} \times \frac{W}{p} \times D} \end{equation}\]마지막으로 이 표현을 픽셀당 $\hat{D}$개의 feature로 표현을 $\frac{H}{s} \times \frac{W}{s}$ 크기로 조정하는 공간적 resampling layer에 전달한다.
\[\begin{equation} \textrm{Resample}_s : \mathbb{R}^{\frac{H}{p} \times \frac{W}{p} \times D} \mapsto \mathbb{R}^{\frac{H}{s} \times \frac{W}{s} \times \hat{D}} \end{equation}\]먼저 1$\times$1 convolution을 사용하여 입력 표현을 $\hat{D}$로 project한 다음, $s \ge p$일 때 (strided) 3$\times$3 convolution을 사용하고 $s < p$일 때 strided 3$\times$3 transpose convolution을 사용하여 공간적 다운샘플링과 업샘플링 연산을 각각 구현한다.
Transformer backbone에 관계없이 4가지 단계와 4가지 해상도에서 feature를 재조립한다. 더 낮은 해상도에서 transformer의 더 깊은 레이어의 feature를 조립하는 반면, 초기 레이어의 feature는 더 높은 해상도에서 조립한다.
- ViT-Base: 레이어 \(l = \{5, 12, 18, 24\}\)에서 토큰을 재조립
- ViT-Large: 레이어 \(l = \{5, 12, 18, 24\}\)에서 토큰을 재조립
- ViT-Hybrid: 첫 번째와 두 번째 ResNet block의 임베딩 네트워크와 단계 \(l = \{9, 12\}\)의 feature를 사용
기본 아키텍처는 projection을 readout 연산으로 사용하고 $\hat{D} = 256$ 차원의 feature map을 생성한다. 이러한 아키텍처를 각각 DPT-Base, DPT-Large 및 DPTHybrid라고 한다.
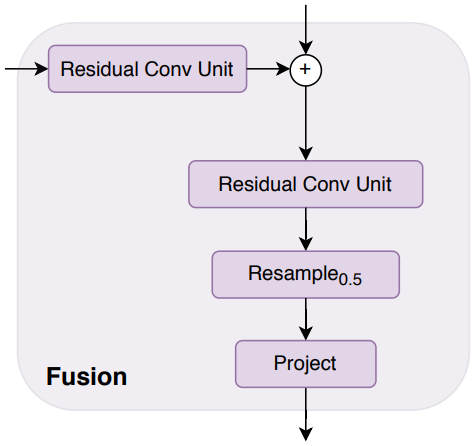
마지막으로 RefineNet 기반 feature 융합 블록 (위 그림 참조)을 사용하여 연속 단계에서 추출된 feature map을 결합하고 각 융합 단계에서 표현을 2배로 점진적으로 업샘플링한다. 최종 표현 크기는 입력 이미지 해상도의 절반이다. 최종 예측을 생성하기 위해 task별 출력 head를 연결한다.
Handling varying image sizes
Fully-convolutional network과 유사하게 DPT는 다양한 이미지 크기를 처리할 수 있다. 이미지 크기를 $p$로 나눌 수 있는 한 임베딩 절차를 적용할 수 있으며 다양한 수의 이미지 토큰 $N_p$가 생성된다. 집합 대 집합 아키텍처인 transformer 인코더는 다양한 수의 토큰을 간단하게 처리할 수 있다. 그러나 위치 임베딩은 입력 이미지의 패치 위치를 인코딩하므로 이미지 크기에 종속된다. ViT 논문에서 제안된 접근 방식을 따르고 위치 임베딩을 적절한 크기로 선형 보간한다. 이 연산은 모든 이미지에 대해 즉석에서 수행될 수 있다. 임베딩 절차와 변환 단계 후에 입력 이미지가 convolutional decoder (32픽셀)의 stride에 맞춰 정렬된 경우 재조립 모듈과 융합 모듈 모두 다양한 수의 토큰을 간단하게 처리할 수 있다.
Experiments
1. Monocular Depth Estimation
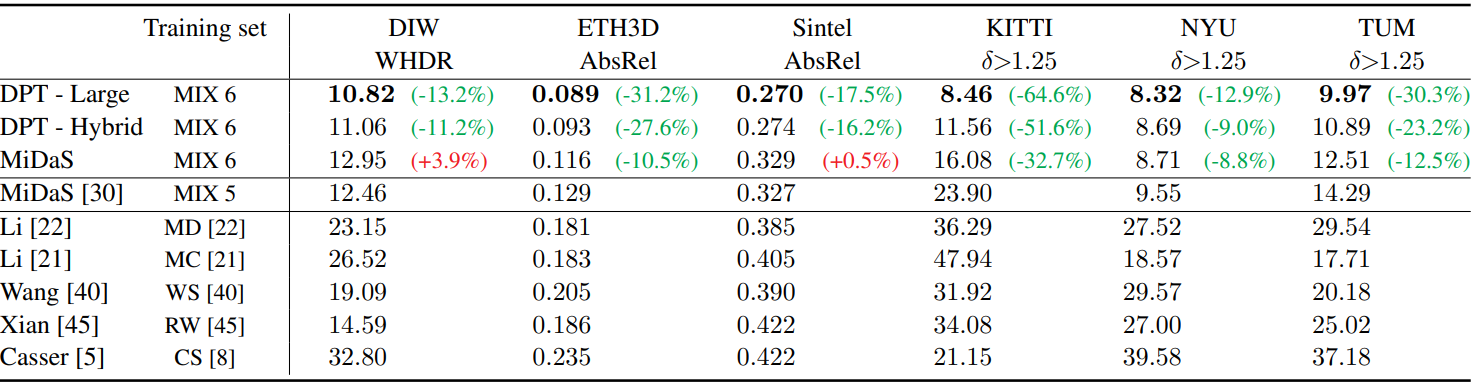
다음은 SOTA 방법들과 monocular depth estimation 성능을 비교한 표이다.
다음은 monocular depth estimation의 샘플 결과들이다.

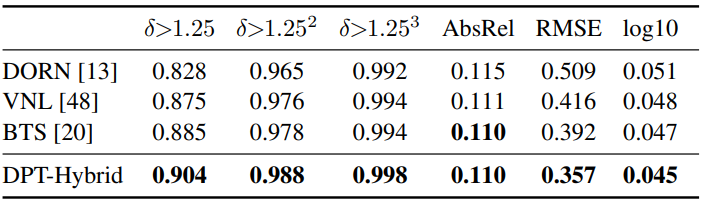
다음은 NYUv2 depth에서의 평가 결과를 비교한 표이다.
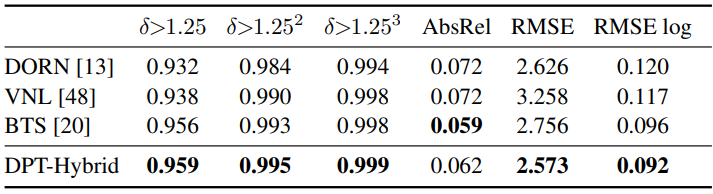
다음은 KITTI (Eigen split)에서의 평가 결과를 비교한 표이다.
2. Semantic Segmentation
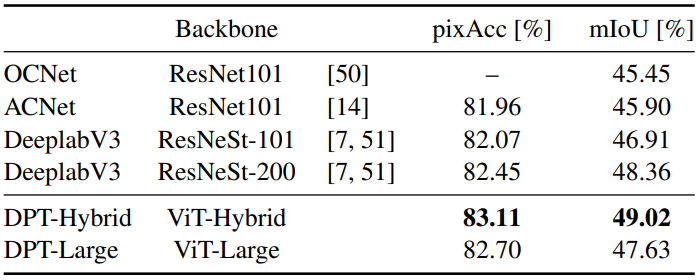
다음은 ADE20K validation set에서의 semantic segmentation 결과이다.
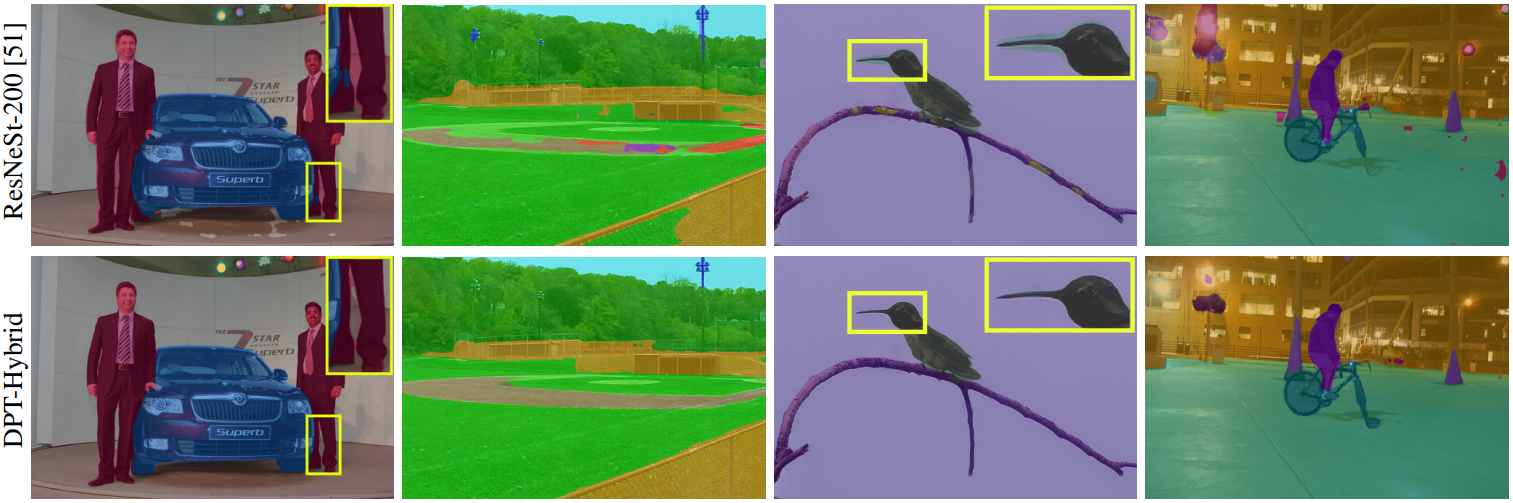
다음은 ADE20K에서의 semantic segmentation 샘플 결과이다.
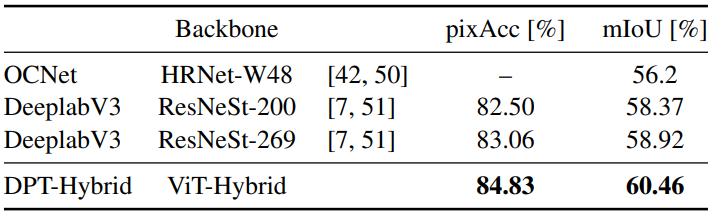
다음은 Pascal Context validation set에서의 segmentation 결과이다.
3. Ablations
다음은 다양한 인코더 레이어에 skip connection을 연결하는 성능이다.

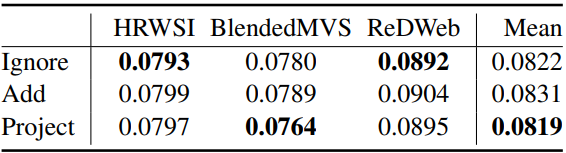
다음은 readout 토큰을 다루는 접근 방식에 대한 성능 비교 결과이다.
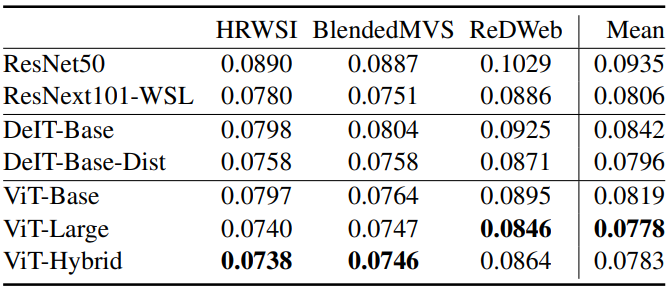
다음은 backbone에 대한 ablation 결과이다.
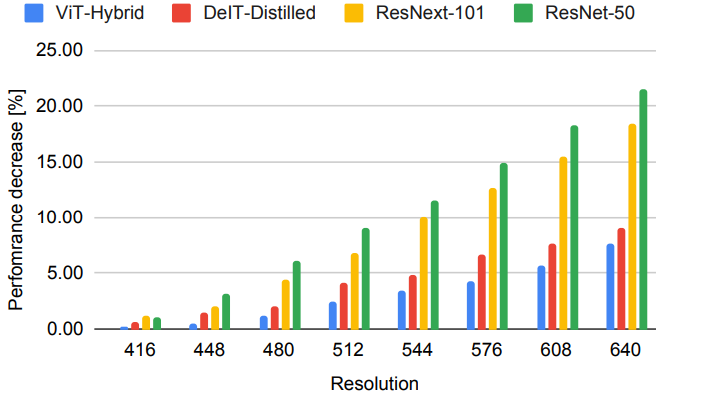
다음은 다양한 inference 해상도에 대한 상대적인 성능 손실을 비교한 그래프이다. (낮을수록 좋음)
다음은 모델의 파라미터 수와 inference 속도를 비교한 표이다.
