[논문리뷰] Distilling Monocular Foundation Model for Fine-grained Depth Completion
CVPR 2025. [Paper] [Github]
Yingping Liang, Yutao Hu, Wenqi Shao, Ying Fu
Beijing Institute of Technology | Southeast University | Shanghai Al Laboratory
21 Mar 2025
Introduction
최근의 depth completion 방법들은 신경망을 활용하여 깊이 데이터로부터 학습시킨다. 일부 방법은 RGB 이미지를 통합하기도 한다. 하지만 SOTA 모델은 여전히 세밀한 기하학적 디테일을 포착하는 데 어려움을 겪고 있으며, 특히 깊이 주석이 부족한 복잡한 실외 장면에서는 더욱 그렇다.
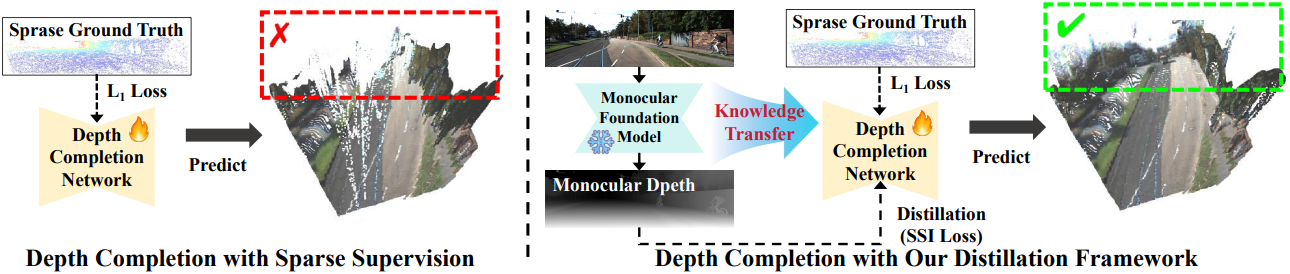
이러한 문제는 학습 과정에서 sparse한 GT에 의존하는 데서 발생한다. Dense한 GT가 부족하면 모델이 전체 장면에 걸쳐 depth completion을 정확하게 학습하기 어렵다. 반면, monocular depth estimation은 단일 이미지로부터 dense한 깊이 예측을 제공할 수 있으며, depth map이 세밀한 디테일과 상대적인 깊이 관계를 포함하기 때문에 depth completion 네트워크 학습에 유용한 guidance를 제공할 수 있다.
Monocular depth model의 장점을 최대한 활용하기 위해, monocular depth model에서 얻은 기하학적 지식을 depth completion 네트워크로 전달하는 새로운 2단계 distillation 프레임워크를 제안하였다. 첫 번째 distillation 단계에서는 monocular foundation model을 통해 학습 데이터를 생성하고, 사전 학습 전략을 통해 지식을 distillation한다. 구체적으로, 다양한 이미지를 사용하여 가상의 depth map을 생성한 다음, 무작위로 샘플링된 카메라 파라미터를 활용하여 메쉬를 만들고 LiDAR를 시뮬레이션한다. 생성된 데이터는 depth completion 모델이 monocular depth model에서 얻은 다양한 기하학적 지식을 학습하도록 학습시켜, 다양한 장면에서 일반화하는 능력을 향상시킨다.
그러나 monocular depth estimation은 본질적으로 스케일 모호성(scale ambiguity)을 가지고 있어 깊이 예측의 스케일이 맞지 않는다. 따라서 monocular depth만으로는 실제 깊이를 추정하는 신뢰할 수 있는 기준으로 사용할 수 없다. 이 문제를 해결하기 위해 두 번째 distillation 단계에서 scale- and shift-invariant loss (SSI Loss)를 도입한다. 특히, sparse한 GT 레이블이 있는 데이터셋에서 fine-tuning할 때, SSI loss는 scale과 shift를 무시하여 다양한 스케일에 걸쳐 monocular depth supervision을 정렬하는 일관된 depth completion을 보장한다.
Method
1. Motivation and Formulation
Depth completion task에서 입력은 일반적으로 RGB 이미지 $I$와 LiDAR 센서에서 얻은 sparse depth map \(D_\textrm{sparse}\)로 구성된다. 목표는 RGB 이미지와 sparse depth map을 입력으로 받아 장면의 깊이를 완전하고 상세하게 표현하는 dense depth map $D_f$를 생성하는 것이다.
\[\begin{equation} D_f = f_\theta (I, D_\textrm{sparse}) \end{equation}\]모델 학습을 가이드하기 위해 사용 가능한 sparse depth 주석을 기반으로 sparse supervision loss가 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{sup} = M \times \vert D_f - D_\textrm{sparse} \vert \end{equation}\]($M$은 \(D_\textrm{sparse}\)에 대한 유효 마스크)
이 loss는 예측된 depth depth map $D_f$를 sparse한 GT 데이터와 일치시킨다. 그러나 이러한 sparse supervision은 특히 야외 장면에서 제한적인 guidance를 제공하여, 세밀하고 일관된 깊이 예측을 달성하는 데 어려움을 겪게 한다.
Monocular depth estimation을 위한 foundation model은 하나의 RGB 이미지로부터 dense한 깊이를 생성한다. 따라서 첫 번째 단계에서는 monocular depth model을 활용하여 다양한 대규모의 학습 데이터를 생성하고, 사전 학습을 통해 dense supervision을 제공한다. 그러나 monocular 방식은 스케일 모호성 문제가 발생하여 dense한 monocular 예측과 sparse한 깊이를 결합할 때 불일치가 발생할 수 있다. 이 문제를 해결하기 위해 두 번째 단계에서는 sparse한 GT 레이블을 갖는 데이터셋에서 fine-tuning할 때 L1 loss와 결합된 SSI loss를 도입하여 스케일 불일치를 완화하고 실제 스케일을 학습시킨다.
2. First Stage: Data Generation and Pre-training
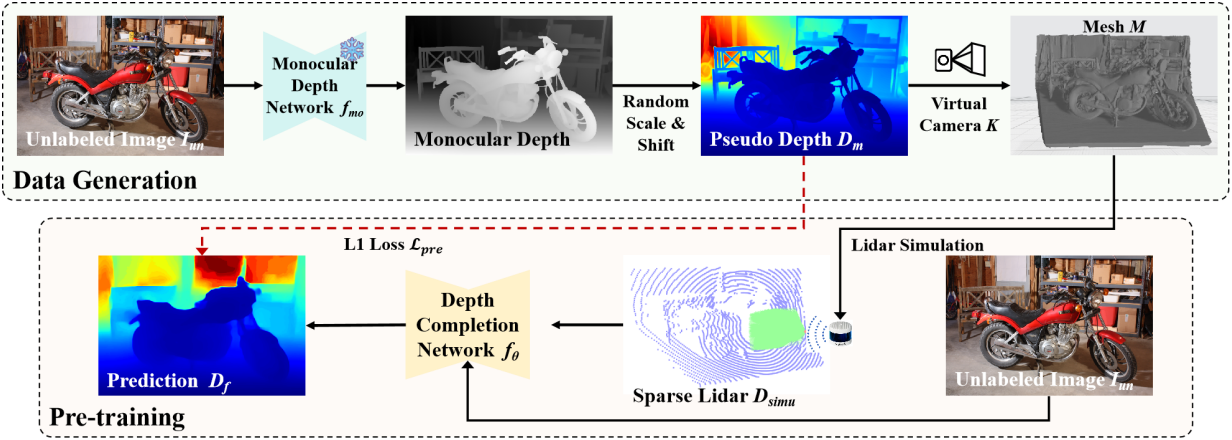
깊이 주석 없이 다양한 이미지를 활용하기 위해, 본 논문에서는 대규모 이미지 데이터셋에서 monocular depth estimation을 통해 생성된 합성 깊이 데이터를 활용하는 사전 학습 전략을 도입하였다. 이 사전 학습 단계를 통해 모델은 다양한 장면에서 monocular depth model로부터 robust한 geometric feature를 학습하여 실제 데이터셋에 대한 후속 fine-tuning을 준비할 수 있다.
먼저, Depth Anything V2와 같은 사전 학습된 monocular depth estimation 모델을 활용하여 이러한 이미지들의 depth map을 예측한다. 각 이미지 \(I_\textrm{un}\)에 대해, monocular depth estimation 모델 \(f_\textrm{mo}\)는 dense depth map \(D_\textrm{syn}\)을 예측한다.
\[\begin{equation} D_\textrm{syn} = f_\textrm{mo} (I_\textrm{un}) \end{equation}\]이러한 합성된 depth map은 스케일이 정확하지 않지만, 장면의 상대적인 깊이 관계와 구조적 디테일을 포착하여 사전 학습 중에 귀중한 supervision을 제공한다.
LiDAR 스캐닝을 시뮬레이션하기 위해 먼저 다음과 같이 랜덤 카메라 intrinsic $K$를 샘플링한다.
\[\begin{equation} K = \begin{bmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{bmatrix} \end{equation}\]Depth map의 각 픽셀 $(u, v)$에 대해, 샘플링된 카메라 intrinsic $K$를 사용하여 카메라 좌표계에서의 3D 좌표 $(X, Y, Z)$를 도출한다. 이 변환은 포인트 클라우드 \(P = \{(X, Y, Z)\}\)를 생성한다. 3D 포인트 클라우드 $P$를 활용하여, Poisson Surface Reconstruction과 같은 표면 재구성 기법을 통해 메쉬 $M$을 재구성하여 시뮬레이션을 위한 연속적인 3D 표면 모델을 생성한다.
다음으로, 광선 방향 벡터 집합 $\textbf{d}$를 생성하여 LiDAR 센서를 시뮬레이션한다. 각 광선은 원점에서 \(\textbf{d}_{i,j}\)를 따라 발사되어 메쉬 $M$과 교차하며 교차점까지의 거리를 계산하게 된다. 이 거리는 시뮬레이션된 LiDAR 깊이 측정값 \(D_\textrm{simu}\)로 기록된다.
그러면, depth completion model $f_\theta$는 RGB 이미지와 시뮬레이션된 스캐닝의 sparse depth를 입력으로 사용한다.
\[\begin{equation} D_f = f_\theta (I_\textrm{un}, D_\textrm{simu}) \end{equation}\]이후, $f_\theta$는 L1 loss를 사용하여 사전 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{pre} = \vert D_f - D_m \vert \end{equation}\]이 사전 학습 과정은 $f_\theta$는 다양한 장면에서 복잡한 기하학적 구조와 상대적인 깊이 관계를 학습하는데, 이는 fine-tuning 단계에서 정확한 depth completion에 필수적이다.
3. Second Stage: Fine-tuning
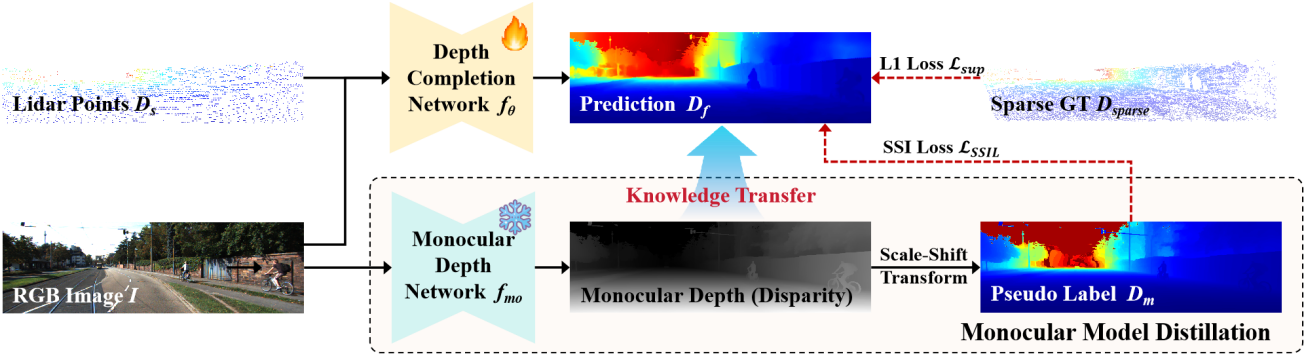
생성된 데이터로 사전 학습된 depth completion model은 monocular depth model로부터 강력한 geometric feature를 학습한다. 그러나 monocular depth의 본질적인 스케일 모호성으로 인해 모델 예측은 실제 스케일과 일치하지 않는다.
실제 스케일을 학습하기 위해 레이블이 있는 데이터셋에 대한 fine-tuning을 위한 loss를 도입한다. 구체적으로, \(\mathcal{L}_\textrm{sup}\)을 위해 sparse GT 데이터 \(D_\textrm{sparse}\)를 활용하여 실제 깊이에 초점을 맞춘다. 그런 다음, monocular depth model에서 예측된 dense monocular depth $D_m$을 사용하여 이미지 전체, 특히 GT 데이터 \(D_\textrm{sparse}\)로 커버되지 않는 영역의 대략적인 깊이 값을 제공한다.
저자들은 monocular depth의 스케일 모호성 문제를 해결하기 위해, scale- and shift-invariant loss (SSI loss)를 distillation 프레임워크에 통합했다. SSI loss는 예측된 depth map $D_f$를 dense monocular depth $D_m$과 일치시키도록 설계되었다. SSI loss은 $D_f$와 $D_m$ 사이의 scale 및 shift 차이에 대해 불변하며, 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{SSIL} = \min_{s,b} \vert D_f - (s \cdot D_m + b) \vert \end{equation}\]($s$와 $b$는 $D_f$를 $D_m$과 정렬하는 최적의 scale 및 shift 파라미터)
Loss function은 $D_f$와 $D_m$ 사이의 최적의 정렬을 찾아 scale 및 offset의 모든 글로벌한 차이를 효과적으로 정규화한다. 이미지의 모든 픽셀에서 이러한 loss를 최소화함으로써, 모델은 monocular depth 추정치에서 제공하는 상대적 깊이 구조와 일관성을 유지하는 depth map을 생성하도록 유도된다.
또한, 선명도를 유지하고 깊이 불연속성에 맞춰 다음과 같은 gradient matching 항을 조정한다.
\[\begin{equation} \mathcal{L}_\textrm{reg} = \frac{1}{N} \sum_{k=1}^K (\vert \nabla_x R^k \vert + \vert \nabla_y R^k \vert) \\ \textrm{where} \quad R = D_f - D_m \end{equation}\]($R^k$는 스케일 $k$에서 depth map의 차이, $K = 4$)
각 스케일 레벨에서 이미지 해상도를 절반으로 줄인다. 최종 loss는 supervised loss \(\mathcal{L}_\textrm{sup}\), dense distillation loss \(\mathcal{L}_\textrm{SSIL}\), 정규화 항 \(\mathcal{L}_\textrm{reg}\)의 결합이다.
Experiments
- 데이터셋
- 사전 학습: COCO, Google Landmarks, Nuscenes, Cityscapes, DAVIS
- Fine-tuning: KITTI, NYU Depth V2
- 구현 디테일
- GPU: NVIDIA A100 4개
- base model: BP-Net
- optimizer: AdamW (weight decay 0.05, gradient clip 0.1)
- batch size: 16
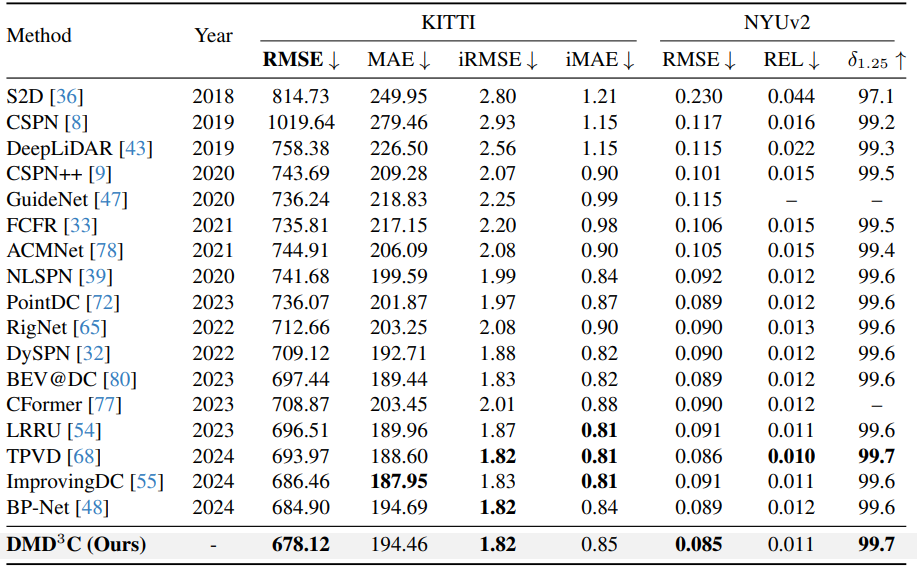
1. Comparison with State-of-the-art Methods
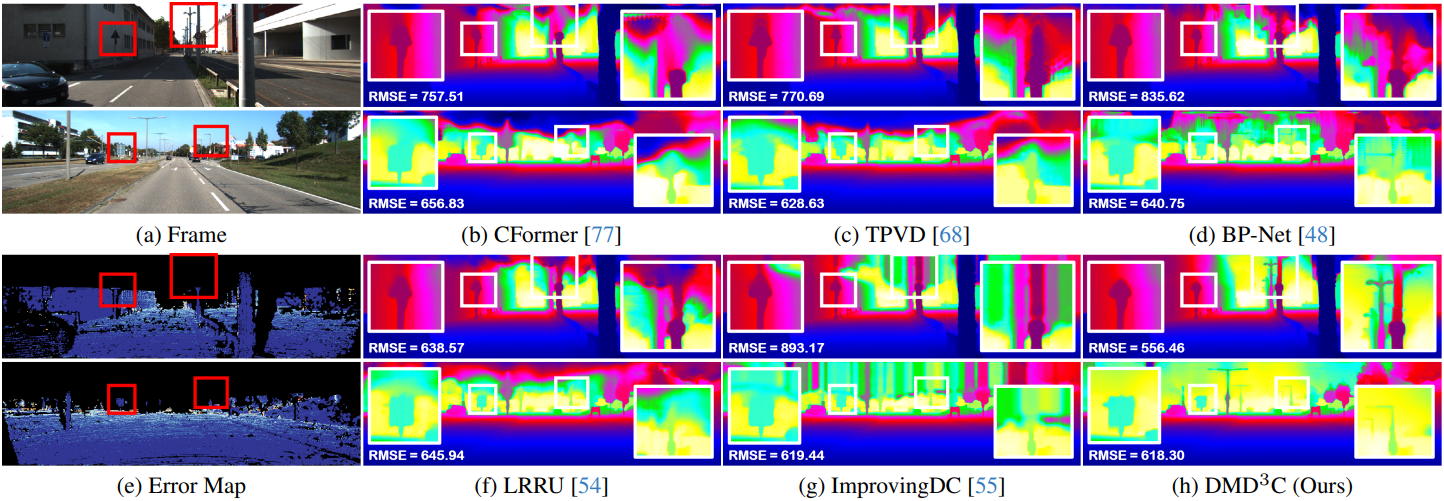
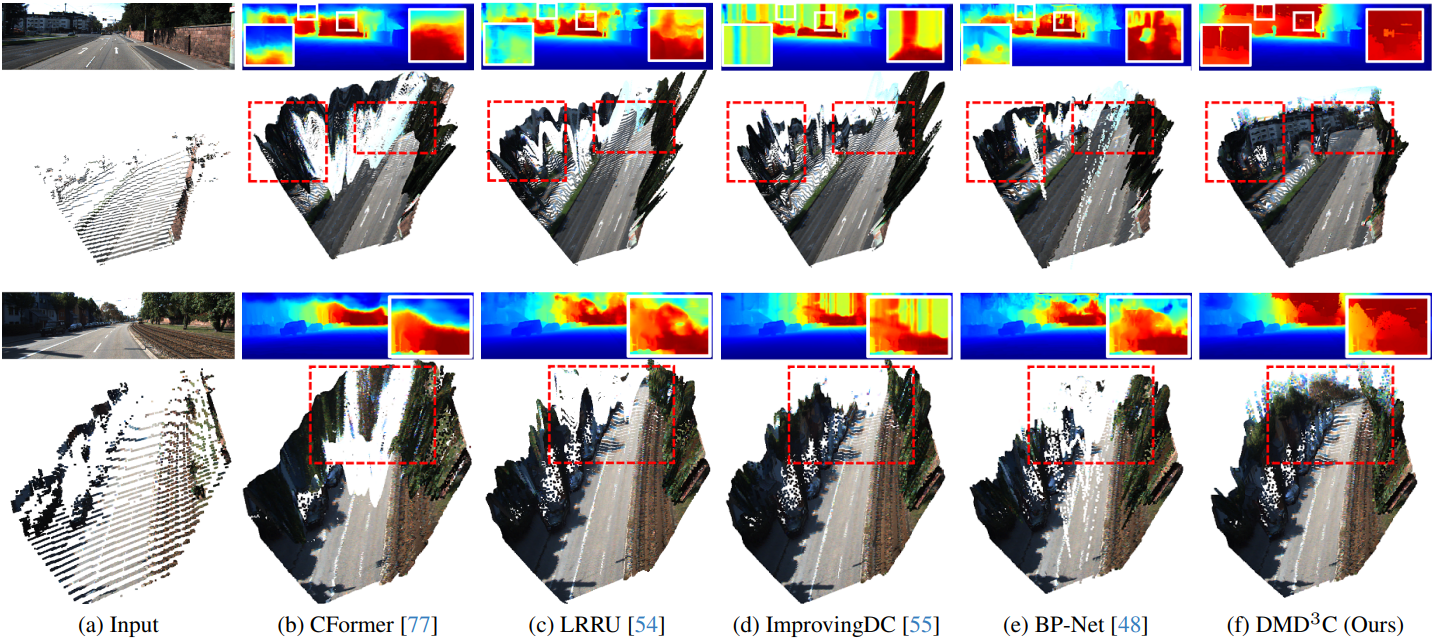
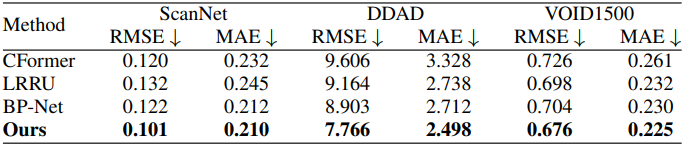
다음은 SOTA 방법들과의 비교 결과이다.
2. Discussions
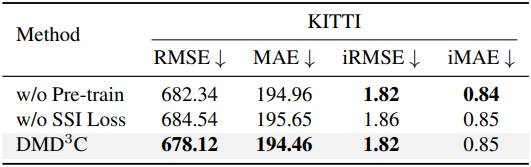
다음은 사전 학습과 SSI loss에 대한 ablation 결과이다.
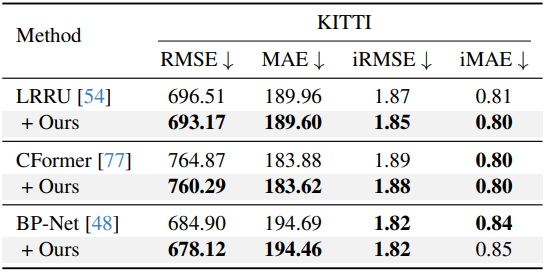
다음은 네트워크 아키텍처에 대한 ablation 결과이다.
다음은 out-of-the-domain 데이터셋에 대한 비교 결과이다.
다음은 SLAM에 적용한 예시이다.
