[논문리뷰] Diffusion Models Beat GANs on Image Synthesis
arXiv 2021. [Paper] [Github]
Prafulla Dhariwal, Alex Nichol
OpenAI
11 May 2021
Introduction
기존의 여러 diffusion 기반의 모델들이 놀라운 성능을 보이고 있지만, 여전히 GAN의 성능을 따라잡지는 못했으며 대부분의 데이터셋에서 state-of-the-art를 달성하지 못하였다. 하지만, 이 논문은 GAN을 제치고 대부분의 데이터셋에서 state-of-the-art가 되었다.
저자들은 diffusion model과 GAN 사이의 격차가 적어도 두 가지 요인에서 비롯된다고 가정한다.
- 최근 GAN 논문에서 사용된 모델 아키텍처가 많이 탐구되고 정제되었다.
- GAN은 fidelity와 diversity의 trade-off에서 fidelity를 선택하였으며, 고품질 샘플을 생성하지만 전체 분포를 포함하지는 않는다.
저자들은 먼저 모델 아키텍처를 개선한 다음 fidelity를 위해 diversity를 절충하는 방법을 고안한다. 이러한 개선 사항을 통해 여러 가지 metric과 데이터셋에서 GAN을 능가하는 새로운 모델을 만들었다.
Background
(자세한 내용은 논문리뷰 참고)
Diffusion model은 점진적으로 noise를 추가하는 process를 reverse하여 샘플링을 한다. Noise $x_T$에서 샘플링을 시작하여 점진적으로 noise가 덜 있는 $x_{T-1}, x_{T-2}, \cdots$을 샘플링하고 최종적으로 $x_0$을 샘플링한다. 각 timestep $t$는 특정 noise level에 해당하며, $x_t$는 $t$에 의해 결정되는 noise $\epsilon$과 $x_0$의 합으로 생각할 수 있다.
Diffusion model은 $x_t$로부터 noise가 덜 있는 $x_{t-1}$을 생성하도록 학습된다. DDPM 논문에서는 모델을 함수 $\epsilon_\theta (x_t, t)$로 parameterize하여 $x_t$의 noise 부분을 예측하도록 하였다. 이 모델을 학습시키기 위해서는 데이터 $x_0$, timestep $t$, noise $\epsilon \sim \mathcal{N}(0,I)$로 랜덤하게 만들어진 샘플 $x_t$가 minibatch에 포함되어야 한다. 학습에 사용하는 목적 함수는 $||\epsilon_\theta(x_t, t) - \epsilon)||^2$이고, 실제 noise $\epsilon$과 예측된 noise $\epsilon_\theta$의 간단한 mean-squared error loss로 구성된다.
DDPM에서는 $p_\theta (x_{t-1} \vert x_t)$를 가우시안 분포 $\mathcal{N}(x_{t-1}; \mu_\theta (x_t, t), \Sigma_\theta(x_t, t))$로 가정하며, 평균 $\mu_\theta(x_t, t)$는 $\epsilon_\theta (x_t, t)$로부터 계산할 수 있고 분산 $\Sigma_\theta (x_t, t)$는 상수 $\beta_t$나 $\tilde{\beta}_t$로 둔다.
또한, 실제 variational lower bound $L_{\textrm{vlb}}$보다 간단한 mean-squared error 목적 함수 $L_{\textrm{simple}}$이 더 좋은 결과를 나타낸다.
Improvements
DDPM 논문이 나오고 여러 논문들에서 diffusion model을 개선하고자 하였다. 이 논문에서 사용한 개선점들을 설명하고자 한다.
Improved DDPM 논문은 분산 $\Sigma_\theta (x_t, t)$을 상수로 고정하는 것이 차선책이며, 다음과 같이 $\Sigma_\theta (x_t, t)$을 parameterize하는 것을 제안하였다.
\[\begin{equation} \Sigma_\theta (x_t, t) = \exp (v \log \beta_t + (1-v) \log \tilde{\beta}_t) \end{equation}\]$v$를 출력하는 모델을 두어 $\beta_t$와 \(\tilde{\beta}_t\) 사이로 interpolate한다. 또한 $\epsilon_\theta (x_t, t)$와 $\Sigma_\theta (x_t, t)$를 모두 학습하기 위하여 가중치 합 \(L_{\textrm{simple}} + \lambda L_{\textrm{vlb}}\)을 목적 함수로 사용한다. ($\lambda = 0.001$)
DDIM 논문은 DDPM과 같은 forward marginals를 가지지만, reverse noise의 분산을 변경하여 다른 reverse sampling이 가능한 non-Markovian noising process를 제안하였다. Noise를 0으로 두면 $\epsilon_\theta$가 deterministic하게 latent와 이미지를 매핑하게 되어 더 적은 step으로 샘플링이 가능하다.
Architecture Improvements
DDPM은 UNet 아키텍처를 사용하였다. UNet은 residual layer와 downsampling convolution을 쌓아 구성하며 크기가 같은 layer끼리 skip connection으로 연결한다. 추가로, $16 \times 16$ feature map에는 head가 하나인 global attention을 사용하였으며, 각 residual block에 timestep embedding의 projection을 넣어주었다.
저자들은 다음의 아키텍처의 변화를 실험하였다.
- 모델 크기를 일정하게 유지하면서 깊이/너비 증가
- Attention head의 수 증가
- Attention을 $16 \times 16$ 뿐만 아니라 $32 \times 32$와 $8 \times 8$에서도 사용
- BigGAN의 residual block을 upsampling과 downsampling에 사용
- Residual connection을 $\frac{1}{\sqrt{2}}$로 rescale
위 항목에 대하여 ImageNet $128 \times 128$에서 배치 사이즈 256, 샘플링 step 250으로 학습한 모델의 FID는 아래 표와 같다.
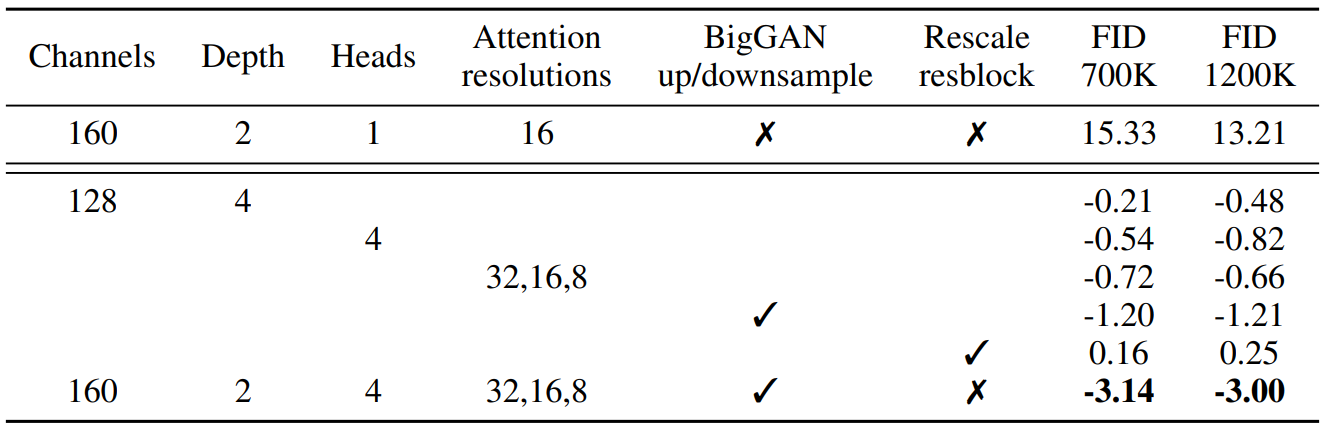
Residual connection을 rescale하는 것을 제외하고는 모두 성능이 개선되었으며 같이 사용하였을 때 긍정적인 효과를 보였다.
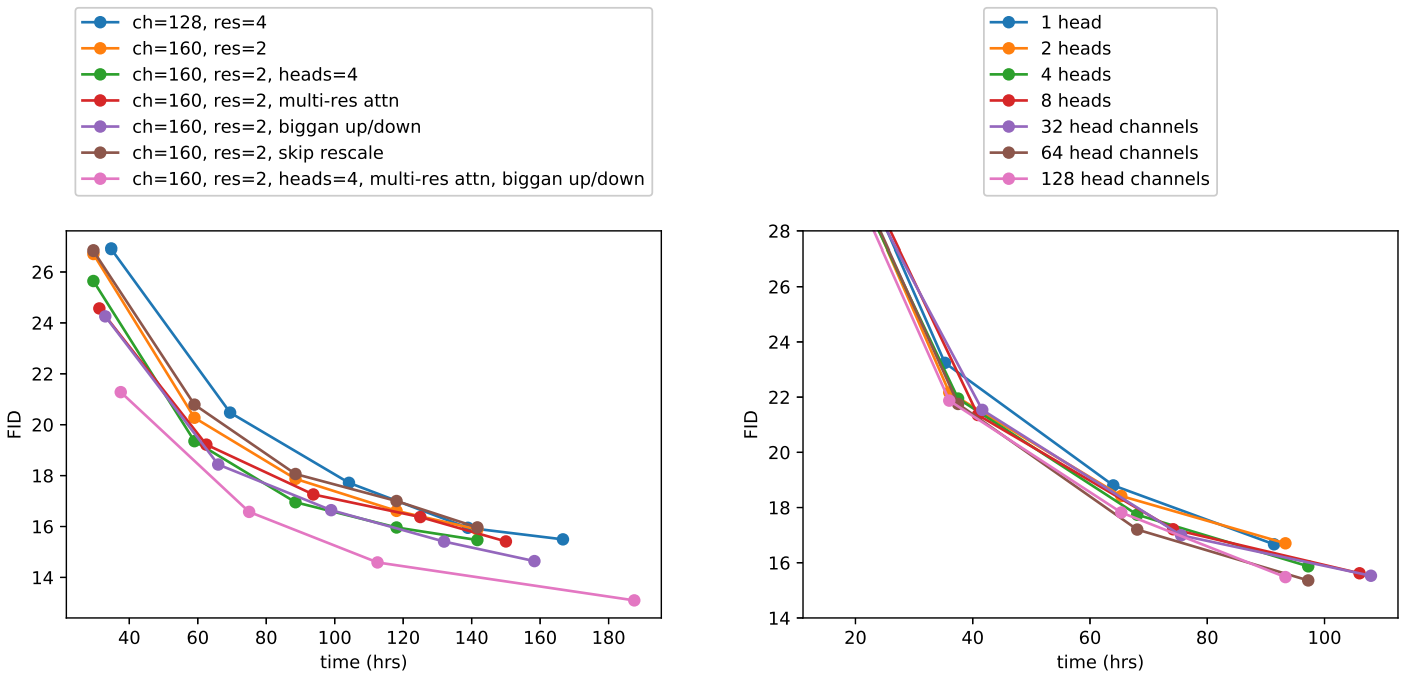
위 그래프에서 볼 수 있듯이 깊이가 증가하면 성능에 도움이 되지만 학습 시간이 늘어나고 더 넓은 모델과 동일한 성능에 도달하는 데 시간이 더 오래 걸리므로 추가 실험에서 이 변경 사항을 사용하지 않기로 결정했다고 한다.
또한 저자들은 Transformer 아키텍처와 더 잘 일치하는 다른 attention 구성을 연구하였다. 이를 위해 attention head를 상수로 고정하거나 head당 채널 수를 고정하는 실험을 했다. 나머지 아키텍처에서는 128개의 기본 채널, resolution당 2개의 residual block, multi-resolution attention, BigGAN up/downsampling을 사용하고 70만 iteration에 대해 모델을 학습한다.

위 표는 head가 많거나 head당 채널 수가 적은 경우 FID가 향상됨을 나타내는 결과를 보여준다. 위 그래프에서 64개 채널이 wall-clock time에 가장 적합하다는 것을 알 수 있으므로 head당 64개 채널을 기본값으로 사용한다. 저자들은 이 선택이 최신 transformer 아키텍처와 더 잘 일치하고 다른 구성과 동등하다는 점에 주목하였다.
Adaptive Group Normalization
저자들은 Adaptive Group Normalization(AdaGN)이라는 layer로도 실험을 진행하였다. 이 layer는 group normalization 연산 후 각 residual block에 timestep embedding과 class embedding을 AdaIN과 같은 방법으로 결합한다.
\[\begin{equation} \textrm{AdaGN}(h, y) = y_s \textrm{GroupNorm}(h) + y_b \end{equation}\]$h$는 residual block 중간의 activation이다. $y = [y_s, y_b]$는 timestep embedding과 class embedding의 linear projection으로 구한다.

위 표에서 AdaGN이 실제로 FID를 개선하는 것을 볼 수 있다. 논문의 나머지 부분에서는 다음의 모델 아키텍처를 기본값으로 사용한다
- Resolution당 2개의 residual block
- 가변 너비
- Head당 64개 채널이 있는 multiple head
- 32, 16, 8 resoltion에서의 attention
- BIGAN의 residual block으로 up/downsampling
- Residual block에 timestep embedding과 class embedding을 주입하기 위한 AdaGN
Classifier Guidance
잘 설계된 아키텍처를 사용하는 것 외에도 조건부 이미지 합성을 위한 GAN은 클래스 레이블을 많이 사용한다. GAN에서는 classifier $p(y \vert x)$처럼 동작하도록 설계된 head가 있는 discriminator를 사용(해당 논문)하거나 class-conditional normalization 방법(해당 논문)을 사용한다. 이전 논문에서는 레이블이 제한된 경우 합성 레이블을 생성하는 것이 도움이 된다는 것을 발견했으며, 이는 클래스 정보가 중요하다는 것을 의미한다.
GAN에서의 이러한 연구들을 생각했을 때 diffusion model을 컨디셔닝하는 다양한 방법이 필요하다. 일단 이미 위에서 클래스 정보를 AdaGN으로 주입하고 있다. 여기에서 diffusion generator를 개선하기 위해 classifier $p(y \vert x)$를 활용하는 다른 접근 방식이 필요하다. Sohl-Dickstein et al.(논문리뷰)와 Song et al.은 classifier의 기울기를 사용하여 pre-trained diffusion model을 컨디셔닝한다. Classifier $p_\phi (y \vert x_t, t)$을 $x_t$에서 학습시킨 뒤, $\nabla_{x_t} \log p_\phi (y \vert x_t, t)$를 임의의 클래스 레이블 $y$로 샘플링을 가이드하는 데 사용한다.
먼저 classifier를 사용하여 conditional sampling processes를 유도하는 두 가지 방법을 설명한다. 그런 다음 이러한 classifier를 실제로 사용하여 샘플 품질을 개선하는 방법을 설명한다. (간결함을 위해 $p_\phi(y \vert xt, t) = p_\phi (y \vert x_t)$와 $\epsilon_\theta (x_t, t) = \epsilon_\theta(x_t)$를 사용한다.)
1. Conditional Reverse Noising Process
Unconditional reverse noising process가 $p_\theta (x_t \vert x_{t+1})$인 diffusion model을 레이블 $y$로 컨디셔닝하면 다음과 같이 샘플링하는 것으로 충분하다.
\[\begin{equation} p_{\theta,\phi} (x_t \vert x_{t+1}, y) = Z p_\theta (x_t \vert x_{t+1}) p_\phi (y \vert x_t) \end{equation}\]$Z$는 확률 분포의 합을 1로 만들기 위한 상수이다. 일반적으로 이 분포에서 정확히 샘플링하기는 어렵지만, Sohl-Dickstein et al.은 이 분포를 perturbed Gaussian distribution로 근사할 수 있음을 보였다.
Diffusion model이 $x_{t+1}$로부터 $x_t$를 가우시안 분포를 사용해서 예측하기 때문에 다음과 같다.
\[\begin{aligned} p_\theta (x_t | x_{t+1}) &= \mathcal{N} (\mu, \Sigma) \\ \log p_\theta (x_t | x_{t+1}) &= -\frac{1}{2} (x_t - \mu)^T \Sigma^{-1} (x_t - \mu) + C \end{aligned}\]$\log p_\phi (y \vert x_t)$가 $\Sigma^{-1}$보다 낮은 곡률을 가진다고 가정할 수 있다. 이 가정은 diffusion step의 수가 무한에 가까워질 때 $|| \Sigma || \rightarrow 0$이 되어 합리적이게 된다. 이 경우, $x_t = \mu$ 근처에서 테일러 전개를 사용하여 $\log p_\phi (y \vert x_t)$를 근사할 수 있다.
\[\begin{aligned} \log p_\phi (y | x_t) & \approx \log p_\phi (y \vert x_t)|_{x_t = \mu} + (x_t - \mu) \nabla_{x_t} \log p_\phi (y | x_t)|_{x_t = \mu} \\ &= (x_t - \mu) g + C_1 \end{aligned}\]여기서 $g = \nabla_{x_t} \log p_\phi (y | x_t)|_{x_t = \mu}$이고 $C_1$은 상수이다. 이를 대입하면 다음과 같다.
\[\begin{aligned} \log (p_\theta (x_t \vert x_{t+1}) p_\phi (y \vert x_t)) & \approx -\frac{1}{2} (x_t - \mu)^T \Sigma^{-1} (x_t - \mu) + (x_t - \mu) g + C_2 \\ &= -\frac{1}{2} (x_t - \mu - \Sigma g)^T \Sigma^{-1} (x_t - \mu - \Sigma g) + \frac{1}{2} g^T \Sigma g + C_2 \\ &= -\frac{1}{2} (x_t - \mu - \Sigma g)^T \Sigma^{-1} (x_t - \mu - \Sigma g) + C_3 \\ &= \log p(z) + C_4, \quad z \sim \mathcal{N}(\mu + \Sigma g, \Sigma) \end{aligned}\]$C_4$는 정규화 상수 $Z$에 해당하기 때문에 무시할 수 있다. 따라서 conditional transition operator를 unconditional transition operator와 유사한 가우시안 분포로 근사할 수 있으며, 이 때 평균이 $\Sigma g$만큼 이동한다. Algorithm 1은 해당 샘플링 알고리즘을 요약한다. 뒤의 섹션에서 기울기에 대한 scale factor $s$를 포함하며 자세히 설명한다.

2. Conditional Sampling for DDIM
조건부 샘플링에 대한 위의 유도는 stochastic한 샘플링에만 유효하며 DDIM과 같은 deterministic한 샘플링 방법에는 적용할 수 없다. 이를 위해 Song et al.에서 사용한 diffusion model과 score matching 사이의 연결을 활용하는 score 기반 컨디셔닝 트릭을 사용한다. 특히 샘플에 추가된 noise를 예측하는 모델 $\epsilon_\theta(x_t)$가 있는 경우 다음과 같이 score function을 도출하는 데 사용할 수 있다.
\[\begin{equation} \nabla_{x_t} \log p_\theta (x_t) = - \frac{1}{\sqrt{1 - \overline{\alpha}_t}} \epsilon_\theta (x_t) \end{equation}\]위 식을 $p(x_t) p(y \vert x_t)$의 score function에 대입하면 다음과 같다.
\[\begin{aligned} \nabla_{x_t} \log (p_\theta (x_t) p_\phi (y | x_t)) &= \nabla_{x_t} \log p_\theta (x_t) + \nabla_{x_t} \log p_\phi (y | x_t) \\ &= - \frac{1}{\sqrt{1 - \overline{\alpha}_t}} \epsilon_\theta (x_t) + \nabla_{x_t} \log p_\phi (y | x_t) \end{aligned}\]결합 분포에 대응되는 새로운 epsilon 예측 $\hat{\epsilon} (x_t)$을 다음과 같이 정의할 수 있다.
\[\begin{equation} \hat{\epsilon} (x_t) := \epsilon_\theta (x_t) - \sqrt{1-\overline{\alpha}_t} \nabla_{x_t} \log p_\phi (y | x_t) \end{equation}\]$\epsilon_\theta (x_t)$ 대신 $\hat{\epsilon} (x_t)$을 사용하면 DDIM에서 사용하는 샘플링 과정을 사용할 수 있다. 이 샘플링 과정을 Algorithm 2와 같다.

3. Scaling Classifier Gradients
저자들은 대규모 생성 task에 classifier guidance를 적용하기 위해 ImageNet에서 classification model을 학습시켰다. Classifier의 아키텍처는 최종 출력을 생성하기 위해 8x8 레이어에 attention pool이 있는 UNet 모델의 downsampling 부분을 사용하였다. 해당 diffusion model과 동일한 noising 분포에서 이러한 classifier를 학습시키고 과적합을 줄이기 위해 random crop을 추가하였다. 학습 후 Algorithm 1에 설명된 대로 classifier를 diffusion model의 샘플링 프로세스에 통합하였다.
저자들은 unconditional ImageNet model을 사용한 초기 실험에서는 classifier gradient를 1보다 큰 상수로 scaling해야 한다는 것을 발견했다. Sclae로 1을 사용하면 classifier가 합리적인 확률(약 50%)을 원하는 클래스에 할당한다. 그러나 실제로 확인해보면 이러한 샘플은 의도한 클래스와 일치하지 않는다. Classifier gradient를 scaling하면 이 문제가 해결되었고 classifier의 클래스 확률이 거의 100%로 증가한다. 아래 그림은 이 효과의 예를 보여준다.

위 그림은 classifier guidance를 사용한 unconditional diffusion model에 “Pembroke Welsh corgi”를 조건으로 주고 샘플링한 결과이다. 왼쪽은 classifier scale로 1.0을 사용하였고 오른쪽은 10.0을 사용하였다. FID는 왼쪽이 33.0, 오른쪽이 12.0으로 클래스에 더 일치하는 이미지가 생성되었다.
Scaling classifier gradient의 효과는
\[\begin{equation} s \cdot \nabla_x \log p (y | x) = \nabla_x \log \frac{1}{Z} p (y | x)^s \end{equation}\]로부터 이해할 수 있다. ($Z$는 임의의 상수) 결과적으로 컨디셔닝 프로세스는 여전히 이론적으로 $p(y \vert x)^s$에 비례하는 re-normalized classifier distribution에 근거한다. $s > 1$일 때 지수에 의해 값이 증폭되기 때문에 $p(y \vert x)^s$는 $p(y \vert x)$보다 더 뾰족해진다. 즉, 더 큰 scale을 사용하면 classifier의 모드들에 더 초점을 맞추며, 이는 더 높은 fidelity의 (그러나 더 낮은 diversity의) 샘플을 생성하는 데 잠재적으로 바람직하다.
위의 식들에서 기본 확산 모델이 $p(x)$를 모델링하고 unconditional이라고 가정했다. 정확히 같은 방식으로 conditional diffusion model $p(x \vert y)$를 학습시키고 classifier guidance를 사용할 수도 있다. 아래 표는 unconditional model과 conditional model 모두의 샘플 품질이 classifier guidance에 의해 크게 향상될 수 있음을 보여준다.
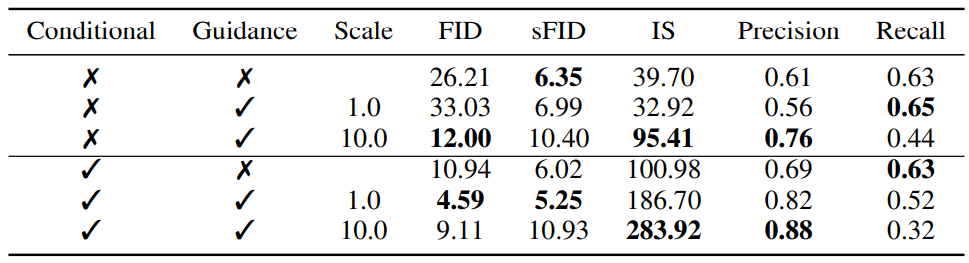
(ImageNet 256$\times$256를 배치 사이즈 256으로 200만 iteration동안 학습)
클래스 레이블을 사용하여 직접 학습시키는 것이 여전히 도움이 되지만 충분히 높은 scale로 guide된 unconditional model이 guide되지 않은 conditional model의 FID에 상당히 근접할 수 있음을 알 수 있다. 물론 conditional model을 guide하면 FID가 더욱 향상된다.
또한 classifier guidance가 recall을 희생시키면서 precision를 향상시켜 샘플의 fidelity와 diversity 사이의 trade-off를 도입함을 보여준다. 아래 그래프에서 gradient scale에 따라 이 trade-off가 어떻게 달라지는지 볼 수 있다.

(ImageNet 128$\times$128)
1.0 이상의 scale을 사용하면 recall (diversity의 척도)을 더 높은 precision과 IS (fidelity의 척도)로 잘 절충된다. FID와 sFID는 fidelity와 diversity 모두에 의존하기 때문에 중간 지점에서 최상의 값을 얻는다.
또한 아래 그림에서 BigGAN의 truncation trick과 classifier guidance를 비교한다.
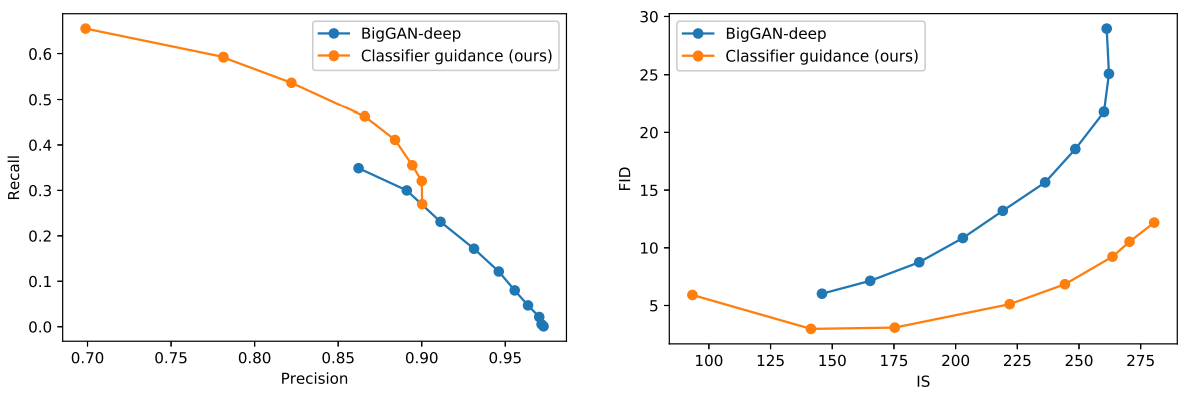
(ImageNet 128$\times$128. BigGAN-deep은 truncation level [0.1, 0.2, 0.3, …, 1.0]에 대하여 실험)
FID를 IS로 절충할 때 classifier guidance가 BigGAN-deep보다 훨씬 낫다는 것을 알 수 있다. Precision/recall trade-off 그래프는 classifier guidance가 특정 precision 값까지만 더 나은 선택이며 그 이후에는 더 나은 precision을 달성할 수 없음을 보여준다.
Results
1. State-of-the-art Image Synthesis
저자들은 unconditional image generation의 평가를 위해 LSUN의 bedroom, horse, cat 데이터셋에서 학습을 진행하였다. Classifier guidance의 평가를 위해 ImageNet의 128$\times$128, 256$\times$256, 512$\times$512 크기에 대하여 conditional diffusion model을 학습시켰다.
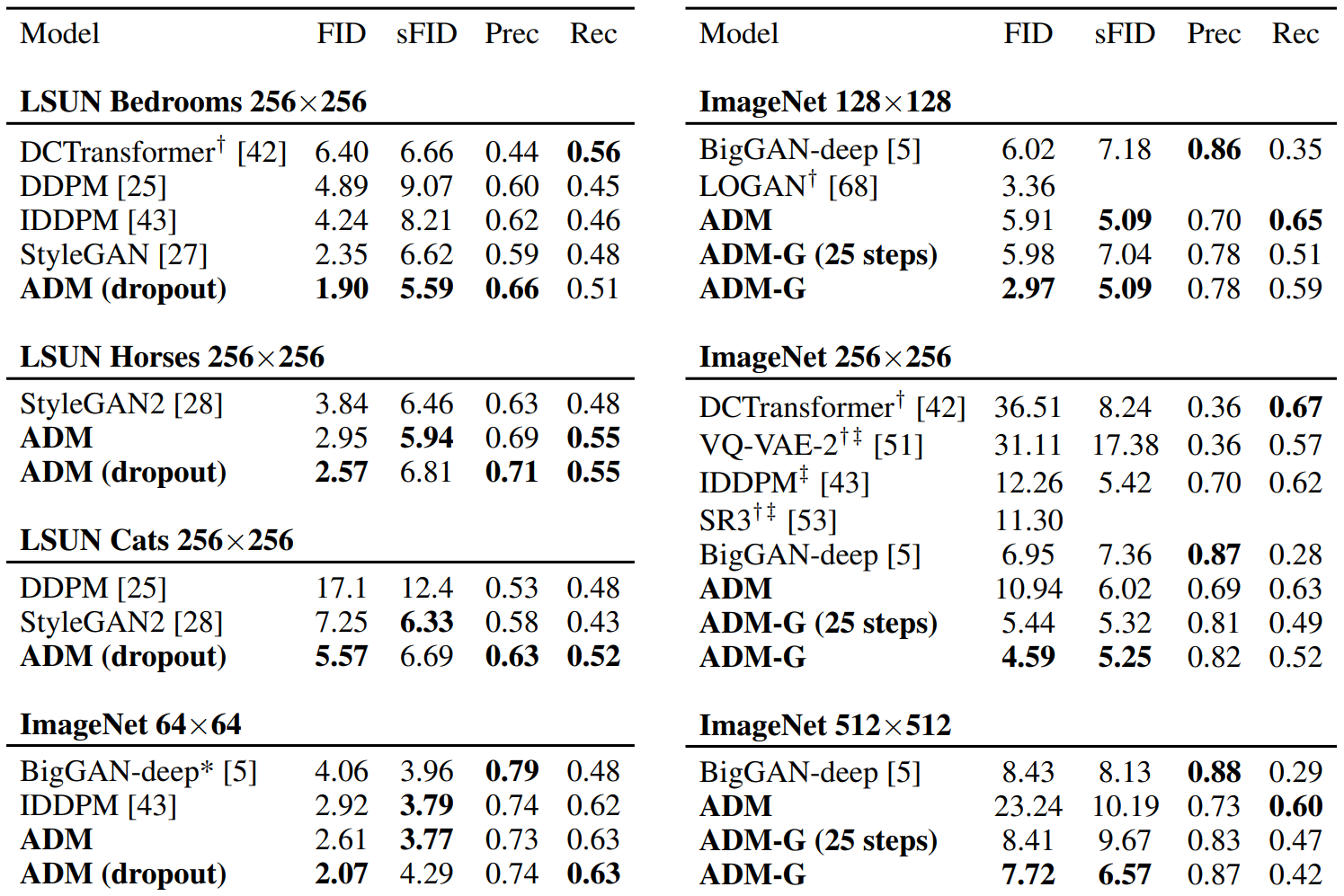
ADM은 ablated diffusion model의 약자이고, ADM-G는 추가로 classifier guidance를 사용한 모델이다. LSUN 모델은 1000 step으로 샘플링되었으며, ImageNet 모델은 250 step으로 샘플링되었다. $\ast$는 해상도에 맞는 BigGAN-deep 모델이 없어 저자들이 직접 학습시킨 모델이고, $\dagger$는 이전 논문에서 가져온 값들이다. $\ddagger$은 two-resolution stack을 사용한 결과이다.
아래는 가장 성능이 좋은 BigGAN-deep 모델과 가장 성능이 좋은 저자들의 diffusion model의 임의의 샘플을 비교한 것이다.

2. Comparison to Upsampling
다음은 guidance와 two-stage upsampling stack의 비교이다. Upsampling model은 training set에서 이미지를 upsampling하고, 간단한 보간법을 사용하여 모델의 입력에 채널별로 연결되는 저해상도 이미지의 조건을 학습한다. 전체 샘플링은 저해상도 모델이 샘플을 생성한 다음 upsampling 모델이 이 샘플을 조건으로 사용하는 방식이다. 위의 표에서도 볼 수 있듯이, 이러한 방법을 사용하는 모델들은 ImageNet 256$\times$256에서 FID가 개선되었지만 BigGAN-deep의 성능을 따라잡지 못하였다.
아래 표는 upsampling model과 guidance model을 비교한 표이다. Upsampling model은 Improved DDPM의 upsampling stack을 ADM에 적용한 것으로, ADM-U라 표기한다. Classifier guidance와 upsampling을 결합하는 경우 해상도가 더 낮은 모델만 guide하였다.
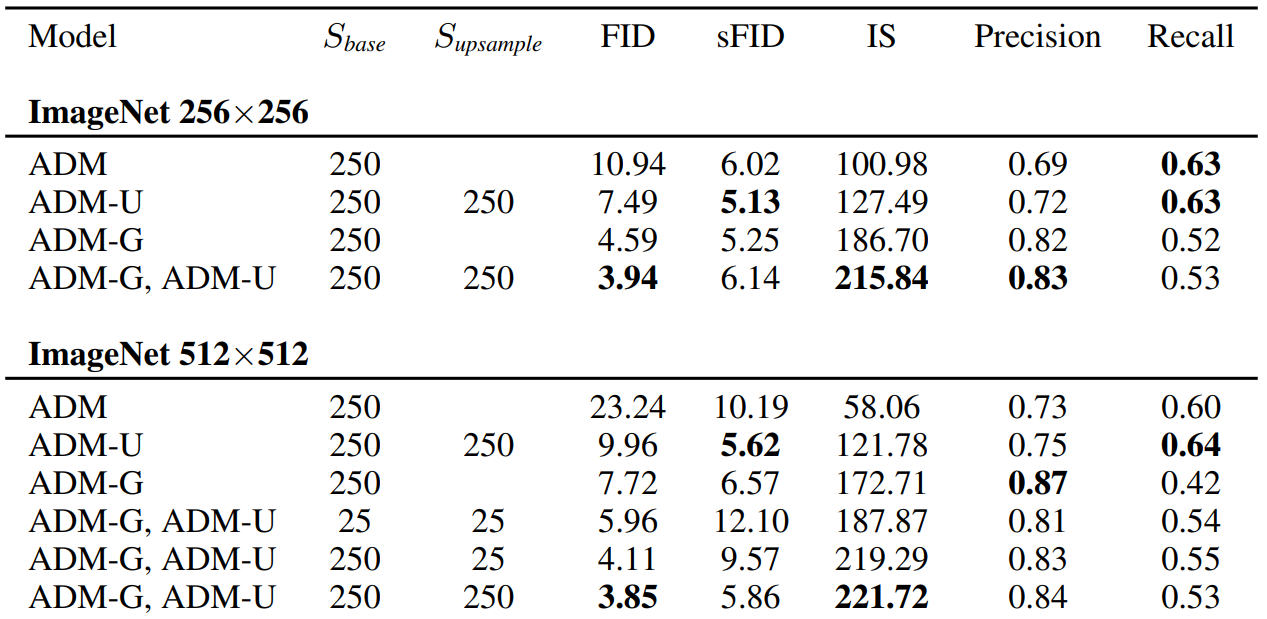
표에서 guidance와 upsampling이 서로 다른 방향으로 샘플의 품질을 향상시키는 것을 알 수 있다. Upsampling은 recall을 높게 유지한 채로 precision을 개선하며, guidance는 훨씬 더 높은 precision을 위해 diversity를 절충할 수 있도록 한다.
Limitations
-
여러 개의 denoising step을 사용하기 때문에 샘플링 시간에서 여전히 GAN보다 느리다. 이 방향에서 의미있는 논문 중 하나는 DDIM 샘플링 프로세스를 single step model로 distillation하는 방법을 연구한 Luhman과 Luhman의 논문이다. Single step model의 샘플은 아직 GAN과 경쟁력이 없지만 이전의 single-step likelihood-based model보다 훨씬 낫다.
-
제안된 classifier guidance는 레이블이 있는 데이터셋에서만 사용할 수 있으며, 레이블이 없는 데이터셋의 fidelity를 위해 diversity를 교환하는 효과적인 전략은 아직 없다.