[논문리뷰] Diffusion Feedback Helps CLIP See Better
ICLR 2025. [Paper] [Page] [Github]
Wenxuan Wang, Quan Sun, Fan Zhang, Yepeng Tang, Jing Liu, Xinlong Wang
Chinese Academy of Sciences | Beijing Academy of Artificial Intelligence | Beijing Jiaotong University
29 Jul 2024
Introduction
CLIP은 다양한 멀티모달 이해 및 생성 task에 널리 적용되었다. 이러한 광범위한 적용은 대규모 데이터에서 학습한 CLIP의 뛰어난 시각적 표현 능력 때문이다. 따라서 CLIP의 표현 및 능력을 향상시키는 것은 다운스트림 task를 진행하는 데 중요하다.
탁월한 zero-shot 성능에도 불구하고, CLIP은 contrastive learning 패러다임과 학습에 사용되는 노이즈가 많은 이미지-텍스트 쌍으로 인해 한계를 가지고 있다 (ex. 긴 텍스트를 정확하게 이해하고 유사한 이미지에서 미세한 차이를 인식하지 못함). 시각적 디테일을 인식하는 능력은 foundation model에 매우 중요하며, CLIP에서 이러한 능력이 부족한 것은 CLIP을 비전 인코더로 사용하는 비전 및 멀티모달 모델의 성능에 직접적인 영향을 미친다.
따라서 본 논문에서는 self-supervised learning 패러다임을 통해 CLIP이 세밀한 시각적 디테일을 구별하지 못하는 문제를 해결하는 데 중점을 두었다. 많은 디테일이 있는 사실적인 이미지를 생성하는 text-to-image diffusion model을 기반으로, diffusion model에서 생성적 피드백을 활용하여 CLIP 표현을 최적화한다. CLIP의 고밀도 리캡핑된 시각적 특징으로 diffusion model을 컨디셔닝하고 reconstruction loss를 CLIP 최적화에 적용하여 diffusion model을 CLIP의 시각적 보조 도구로 활용한다.
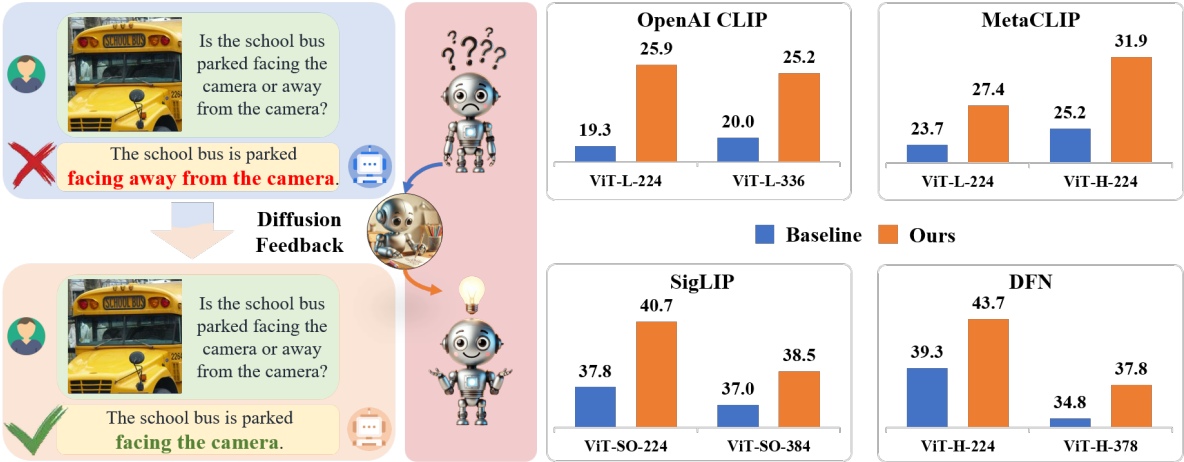
DIVA는 VLM의 시각적 능력을 측정하는 MMVP-VLM 벤치마크에서 CLIP의 성능을 크게 향상시키고, 멀티모달 및 비전 이해 task에서 MLLM과 비전 모델을 개선한다. 또한 DIVA는 29개 이미지 분류 및 검색 벤치마크에서 CLIP의 뛰어난 zero-shot 성능을 유지한다.
DIVA: DIffusion model as a Visual Assistant
Method
1. CLIP’s Visual Deficiencies
방대한 데이터에 대한 사전 학습을 통해 학습한 뛰어난 표현 덕분에 CLIP은 뛰어난 일반화 능력을 보여주며 비전-언어 이해 도메인에 널리 적용되었다. 그러나 CLIP은 인간은 분명히 구별할 수 있는 두 이미지 간의 세부적인 차이점을 구별하는 데 어려움을 겪는다. 이러한 결함은 주로 두 가지 측면에서 비롯된다.
- 학습 패러다임: CLIP의 contrastive learning 전략은 시각적 클래스 토큰과 텍스트 semantic의 positive 쌍 간의 거리를 최소화하고 negative 쌍 간의 거리를 최대화하는 것을 목표로 한다. 이는 주로 높은 수준의 semantic 정보에 초점을 맞추고 방향, 양, 색상, 구조와 같은 시각적 디테일을 간과하는 시각적 인식 편향을 초래한다. 결과적으로 CLIP은 때때로 시각적으로 다른 이미지를 유사한 임베딩으로 인코딩하여 이러한 이미지의 미묘한 변화를 구별하기 어렵게 만든다.
- 데이터 형식: CLIP을 학습하는 데 사용된 이미지-텍스트 쌍의 텍스트는 길이가 제한되어 있다. 텍스트 토큰의 길이는 77로 제한되어 있지만 CLIP의 실제 유효 텍스트 길이는 20 미만이다. 따라서 이러한 이미지-텍스트 쌍의 텍스트 데이터는 본질적으로 해당 positive 샘플 이미지의 시각적 디테일에 대한 설명이 부족하다. 이러한 학습 데이터의 근본적인 한계로 인해 CLIP은 시각적 디테일을 적절히 인식하지 못한다.
2. Overall Structure of DIVA
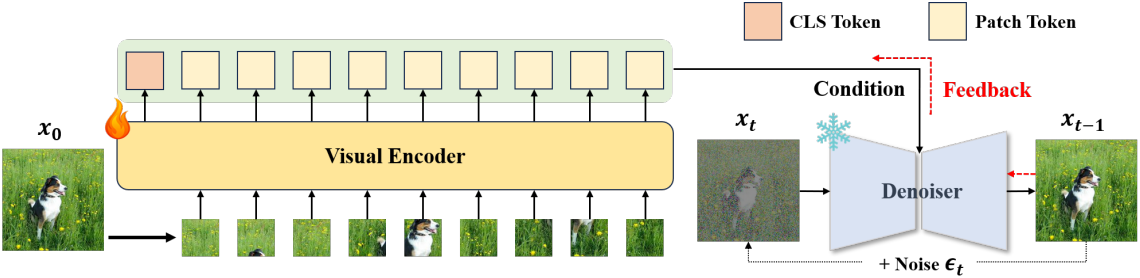
DIVA는 크게 CLIP 모델과 사전 학습된 text-to-image diffusion model로 구성된다. 원본 이미지를 입력으로 사용하여 CLIP 모델은 해당 visual feature를 인코딩하고, 이는 diffusion model의 텍스트 인코더에서 조건에 대한 빈 텍스트의 임베딩과 결합된다. Noise가 추가된 이미지가 주어지면, diffusion model은 이전 timestep에서 현재 timestep에 추가된 noise를 예측하려고 시도한다. 각 이미지에 대해, 최적화를 위해 diffusion model의 전체 timestep에서 $N$개를 무작위로 선택하여 이 프로세스를 $N$번 반복한다. Loss function은 다음과 같다.
CLIP의 비주얼 인코더를 제외한 모든 부분의 가중치를 고정한 상태에서, 이 reconstruction loss를 최소화한다. 이런 방식으로, diffusion model을 제약하여 추가된 noise를 보다 정확하게 예측함으로써, CLIP의 표현은 diffusion 피드백을 통해 더 많은 시각적 디테일이 있는 표현으로 점진적으로 최적화된다.

3. Diffusion’s Condition Design
Visual Dense Recap
DIVA에서 diffusion model의 조건 설계는 CLIP의 visual feature를 향상시키기 위한 상한을 설정하기 때문에 핵심적이다. 저자들은 visual dense recap이라는 간단하면서도 효과적인 전략을 도입하였다. 자연어로 이미지 캡션을 자세히 re-captioning하는 것과 달리, 로컬 패치 토큰의 feature와 클래스 토큰을 조건에 통합하여 시각적 풍부함 수준에서 re-captioning을 수행한다.
클래스 토큰만 있는 경우 CLIP의 visual feature는 주로 강력한 semantic 정보를 포함하며, 이는 원본 이미지를 재구성하기에 충분하지 않다. 결과적으로 적절한 정보가 부족하여 재구성이 어려워지고 CLIP은 크게 향상된 표현을 학습할 수 없다. 로컬 패치 feature를 통합함으로써 조건의 보조 기능이 크게 향상되어 생성 피드백이 CLIP의 시각적 인식 능력을 효과적으로 개선할 수 있다.
Visual Recap Density
Visual Dense Recap은 간단해 보이지만 recap의 밀도는 매우 중요하다. 밀도가 너무 높으면, 즉 로컬 토큰을 너무 많이 도입하면, 조건 정보의 풍부함이 최대치에 가까워져 재구성의 어려움이 크게 줄어든다. 이로 인해 CLIP의 표현은 재구성을 쉽게 완료하기 위해 최소한의 최적화만 필요하게 되어 CLIP의 최적화된 능력의 상한이 제한된다. 반대로 밀도가 너무 낮으면, 즉 클래스 토큰만 유지하거나 로컬 토큰을 거의 도입하지 않으면, CLIP의 최적화 프로세스는 재구성에 높은 어려움을 겪어 자세한 시각적 표현을 적절히 학습하지 못한다.
구체적으로 시각적 클래스 토큰이 항상 조건에 존재하도록 하기 위해 OpenAI CLIP에 대해 224, 336 해상도에서 각각 약 15%, 30% 확률로 무작위로 선택된 로컬 토큰 feature를 도입한다. 224, 384 이미지 크기의 SigLIP ViT-SO-14의 경우, 각각 6, 10의 local window 크기를 사용하여 1D average pooling을 통해 얻은 로컬 토큰 feature를 통합한다. DFN ViT-H-14/378는 조건에 50% 무작위로 선택된 패치 토큰들을 도입하며, 나머지는 조건에 모든 로컬 토큰 feature를 포함한다. 모델들은 inference 중 학습에 사용한 조건과 일치하는 로컬 feature를 클래스 토큰과 결합하여 향상된 CLIP에서 캡처한 세부 표현을 최대한 활용한다.
Experiments
- 데이터셋: Conceptual-3M
- 구현 디테일
- GPU: NVIDIA A100 80GB 8개
- global batch size: 640
- optimizer: SGD (momentum = 0.9)
- learning rate: $1 \times 10^{-4}$
- steps: 4,600 (거의 1 epoch)
1. Fine-grained Visual Perception Evaluation
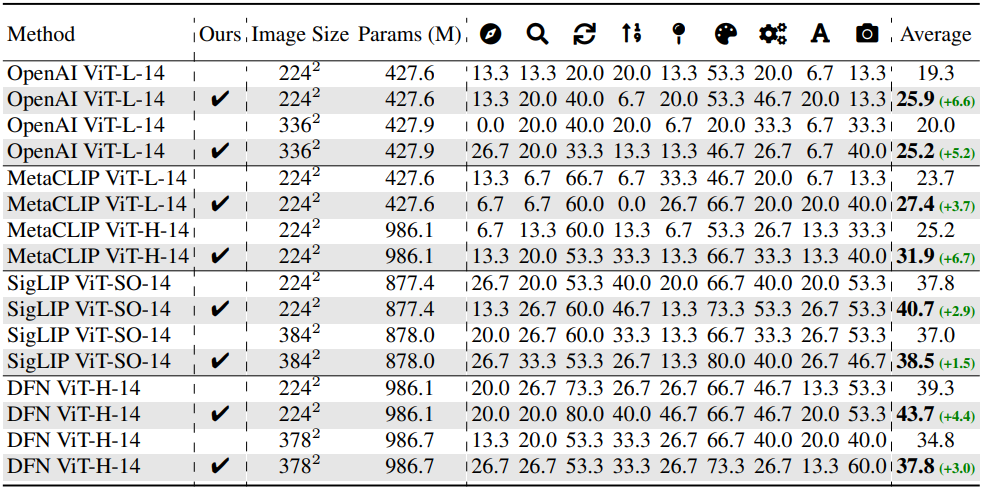
다음은 MMVP-VLM의 다양한 시각적 패턴에 대한 CLIP 기반 모델들의 성능을 비교한 것이다.
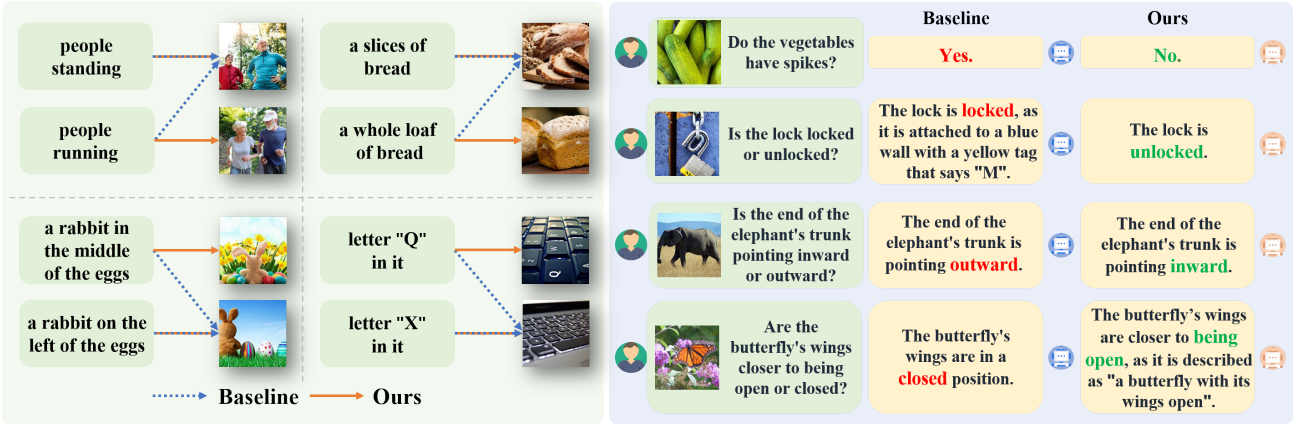
다음은 MMVP-VLM과 MMVP에 대한 정성적 비교 예시이다. 왼쪽은 DIVA를 통합하기 전과 후의 OpenAI ViT-L-14 CLIP의 예측 결과이고, 오른쪽은 DIVA를 사용하기 전과 후의 LLaVA-1.5-7B의 예측 결과이다.
2. Backbone Enhancement Performance Evaluation
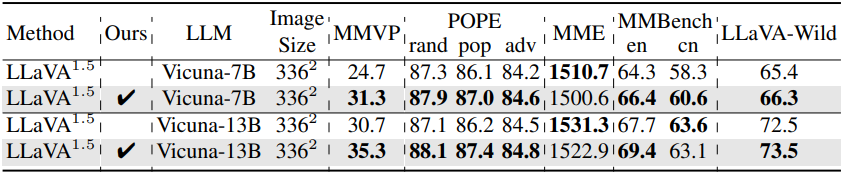
다음은 DIVA 사용 유무에 따른 MLLM의 비전-언어 이해 성능을 비교한 표이다.
다음은 DIVA 사용 유무에 따른 semantic segmentation 성능을 비교한 표이다.

3. Generalization Capability Evaluation
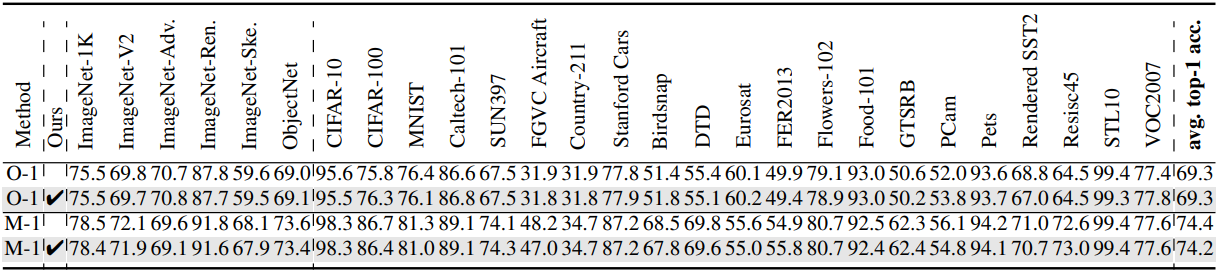
다음은 zero-shot 이미지 분류 성능을 비교한 표이다.
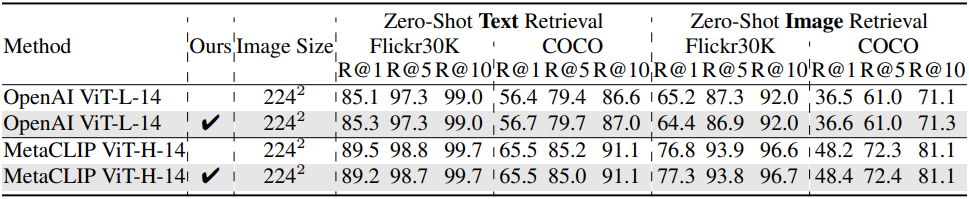
다음은 zero-shot 텍스트 및 이미지 검색 성능을 비교한 표이다.
4. Ablation Study
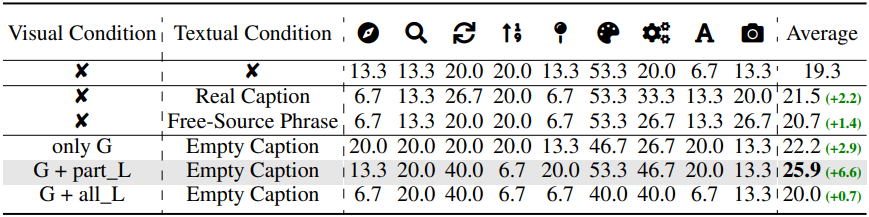
다음은 조건 디자인에 대한 ablation 결과이다.
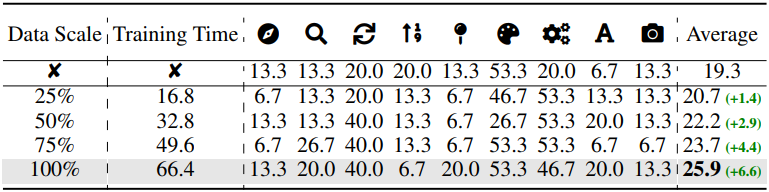
다음은 데이터 스케일에 대한 ablation 결과이다.
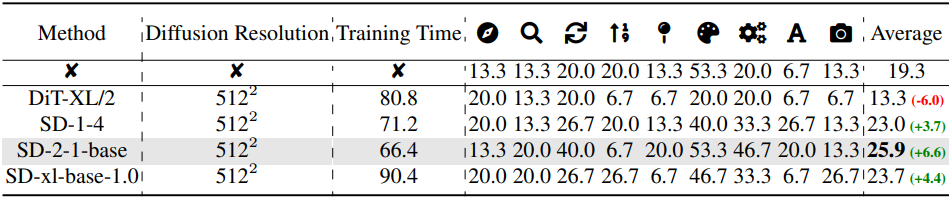
다음은 사용한 diffusion model에 대한 ablation 결과이다.