[논문리뷰] Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
ICCV 2025. [Paper] [Page] [Github]
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, Yuntao Chen
Shanghai AI Lab | Zhejiang University | The Chinese University of Hong Kong | Peking University | SenseTime Research | Tsinghua University | Chinese Academy of Sciences
25 Mar 2025
Introduction
본 논문에서는 scalability를 확보하기 위해 Diffusion Transformer (DiT) Policy인 Dita를 소개한다. 이 아키텍처는 in-context conditioning 메커니즘과 causal transformer를 통합하여 action 시퀀스의 noise를 제거함으로써 이미지 토큰에 대한 action denoising의 직접적인 컨디셔닝을 가능하게 하고, 과거 observation 데이터에서 미묘한 차이를 식별할 수 있도록 한다.
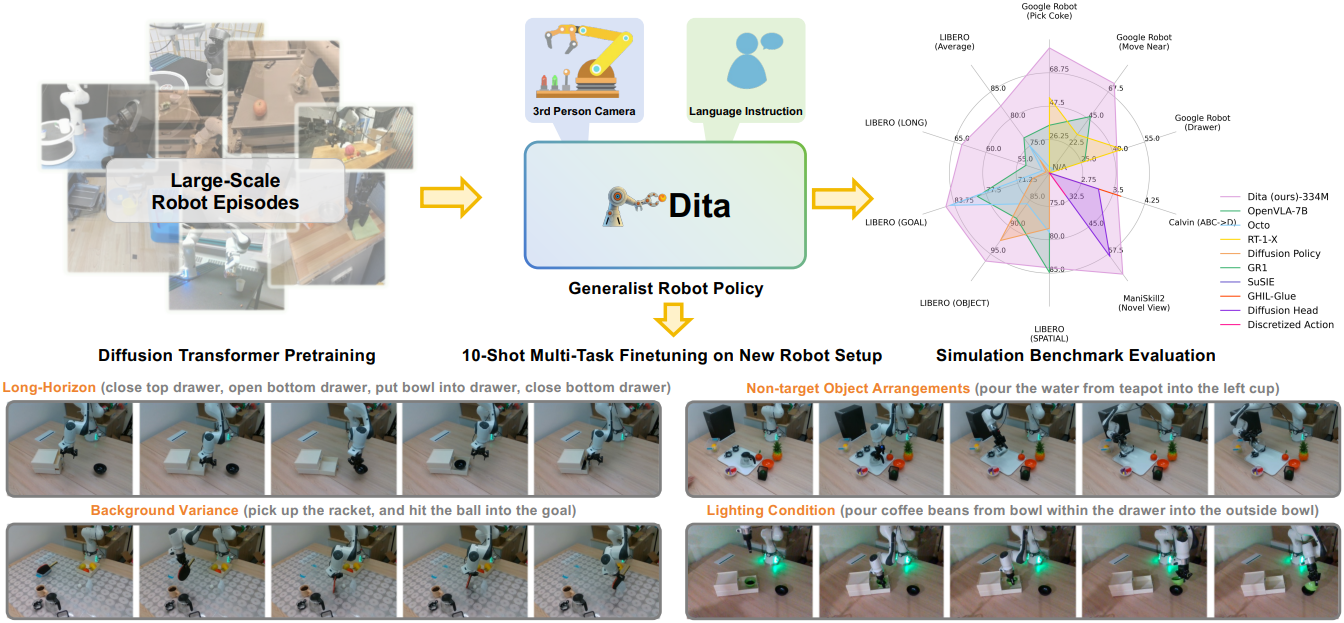
본 논문의 목표는 일반적인 로봇 policy 학습을 위한 깔끔하고 경량화된 (334M) 오픈 소스 baseline 모델을 제공하는 것이다. 이 모델은 단순하면서도 효과적이며, 광범위한 시뮬레이션 벤치마크에서 SOTA 또는 경쟁력 있는 결과를 달성하였다. 또한, 단 10개의 실제 샘플 데이터셋을 사용한 fine-tuning을 통해 새로운 환경 구성에서도 long-horizon task로 성공적으로 일반화된다. 놀랍게도, 이러한 뛰어난 성능은 단 하나의 3인칭 카메라 입력만으로 달성되었으며, 모델의 내재적인 유연성 덕분에 추가적인 입력 방식을 통합하여 추가 연구를 진행할 수 있다.
Method
1. Architecture
Multi-modal Input Tokenization
Dita는 언어 명령과 3인칭 카메라 이미지만을 입력으로 받는다. 언어 명령은 고정된 CLIP 모델을 사용하여 tokenize되고, 이미지 observation은 먼저 DINOv2를 통해 이미지 패치 feature를 추출한다. 특히, DINOv2는 웹 데이터를 기반으로 학습되었으므로 로봇 전용 데이터와는 다르다. 따라서, 본 논문에서는 Dita와 함께 DINOv2 파라미터를 end-to-end 방식으로 공동 최적화하였다. 계산 비용을 줄이기 위해, FiLM conditioning을 사용하는 Q-Former를 사용하여 명령 컨텍스트에 따라 DINOv2 패치 feature에서 이미지 feature를 선택적으로 추출한다.
Action Preprocess
본 논문에서는 end-effector action을 7차원 벡터로 표현한다. 이 벡터는 3차원의 translation 벡터, 3차원의 rotation 벡터, 1차원의 gripper 위치로 구성된다. 이미지 및 언어 토큰과의 차원 정렬을 위해, action 벡터에 0을 채워 넣어 action 표현을 생성한다. 학습 과정에서 noise는 7차원 action 벡터에만 도입된다.
Model Design
본 논문의 핵심 디자인은 여러 개의 action 토큰을 포함하는 action chunk의 noise를 제거하는 DiT 구조이다. 이는 causal transformer를 활용한 in-context conditioning 방식을 통해 이미지 observation과 명령 토큰에 직접 컨디셔닝함으로써 구현된다.
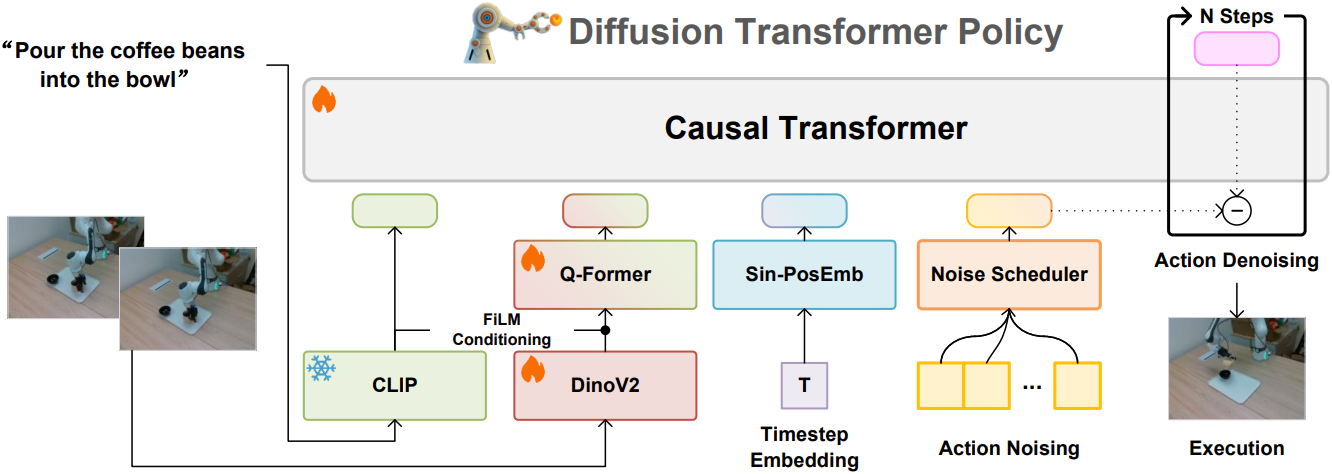
구체적으로, 시퀀스 시작 부분에 언어 토큰, 이미지 feature, 타임스텝 임베딩을 concat하여 noise가 더해진 action을 명령 토큰과 함께 처리한다. 이러한 디자인은 transformer의 scalability를 유지하면서 이미지 패치에 직접 denoising 조건을 적용할 수 있도록 하여, 모델이 과거 observation에 따른 action의 미묘한 변화를 포착할 수 있도록 한다.
기존의 diffusion action head 방식과는 달리, 본 논문에서는 대규모 transformer 모델을 사용하여 action chunk 공간에 diffusion loss를 직접 적용하였다. 특히, DiT는 다양한 데이터셋에 적응 가능한 다목적 및 scalable한 설계로, 사전 학습과 fine-tuning 모두에서 우수한 성능을 달성한다. 또한, 추가적인 observation 토큰과 입력값을 transformer 아키텍처에 원활하게 통합할 수 있다.
2. Training Objective
Denoising network \(mathcal{E}_\theta (c_\textrm{lang}, c_\textrm{obs}, t, \textbf{x}^t)\)는 causal transformer를 기반으로 구축된다. 여기서 \(c_\textrm{obs}\)는 이미지 observation, \(c_\textrm{lang}\)은 언어 명령, $t$는 timestep이다. 학습 과정에서 각 timestep $t$에서 Gaussian noise 벡터 \(\textbf{x}^t \sim \mathcal{N}(\textbf{0}, \textbf{I})\)가 샘플링되어 액션 $\textbf{a}$에 더해져 noise가 포함된 action 토큰 \(\hat{\textbf{a}}\)를 생성한다. \(\mathcal{E}_\theta\)는 랜덤 샘플링된 $t$를 사용하여 noise 벡터 \(\hat{\textbf{x}}\)를 예측하도록 학습된다. Dita의 loss는 \(\textbf{x}^t\)와 \(\hat{\textbf{x}}^t\) 사이의 MSE loss이다.
Inference 절차는 다음과 같이 설명된다.
\[\begin{equation} \textbf{x}^{t-1} = \alpha (\textbf{x}^t - \gamma \mathcal{E}_\theta (c_\textrm{lang}, c_\textrm{obs}, t, \textbf{x}^t) + \mathcal{N} (\textbf{0}, \sigma^2 \textbf{I})) \end{equation}\]Denoising process는 신뢰할 수 있는 action을 도출하기 위해 $N_\textrm{eval}$개의 step을 거쳐 반복된다.
Simulation Experiments
- 사전 학습 데이터: Open X-Embodiment (OXE)
- 사전 학습 디테일
1. Results
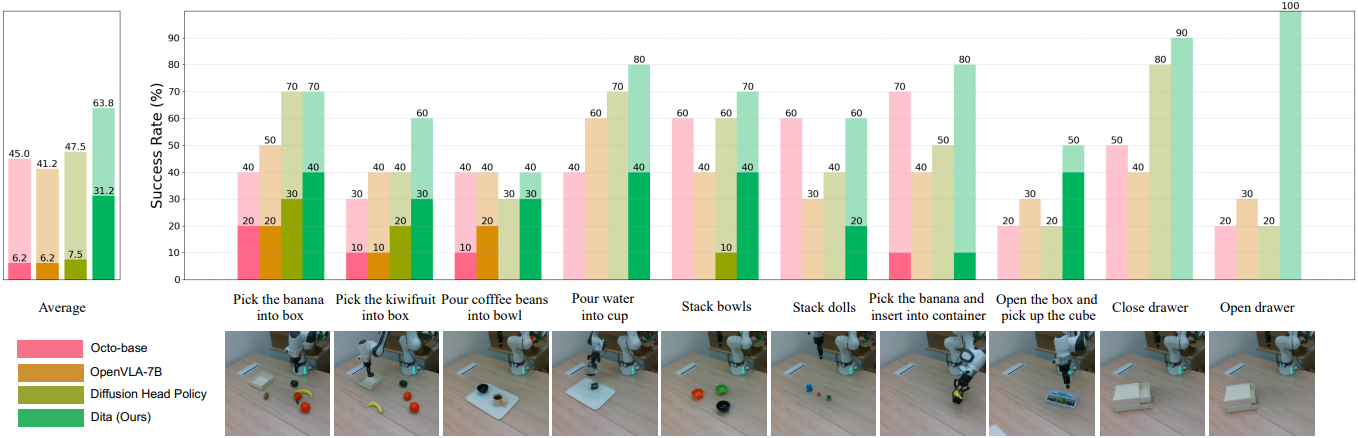
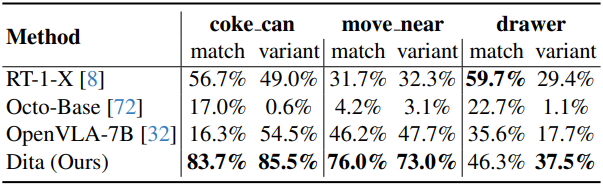
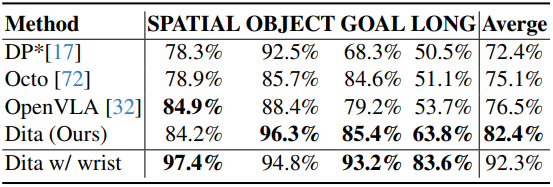
다음은 (왼쪽) SimplerEnv와 (오른쪽) LIBERO에서의 성공률을 비교한 결과이다.
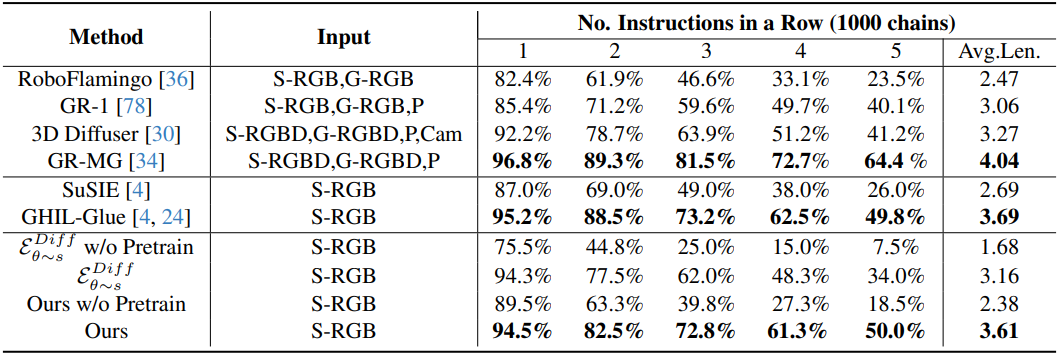
다음은 Calvin에서의 성공률과 평균 성공 길이를 비교한 결과이다. (‘S-‘는 static, ‘G-‘는 gripper를 뜻함)
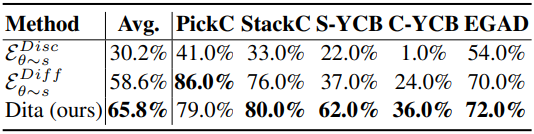
다음은 ManiSkill2에서의 성공률을 비교한 결과이다.
2. Ablation Study
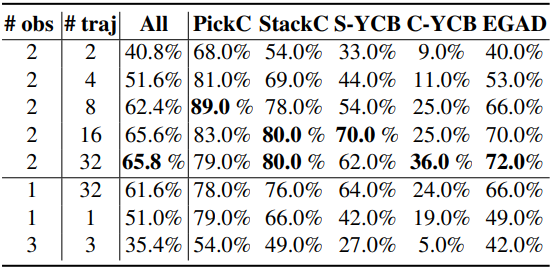
다음은 observation 길이와 trajectory 길이에 따른 성공률을 비교한 결과이다.
Real-Robot Experiments

- Fine-tuning 디테일
- LoRA 사용
- optimizer: AdamW
- steps: 2만
- \(T_\textrm{train} = 100\) (DDPM)
- batch size: 512
다음은 실제 로봇 실험에 대한 결과이다.