[논문리뷰] Diffusion Curriculum: Synthetic-to-Real Data Curriculum via Image-Guided Diffusion
ICCV 2025. [Paper] [Page] [Github]
Yijun Liang, Shweta Bhardwaj, Tianyi Zhou
University of Maryland
17 Oct 2024
Introduction
Data augmentation 및 합성은 실제 데이터의 한계를 극복하기 위한 연구 분야이다. 그러나 이러한 기존 방법들은 데이터 분포가 매우 불균형하고, 다양하며, 예측 불가능한 실제 데이터에 적용할 때 여전히 한계를 보인다. Text-to-image 합성은 데이터의 질과 양을 향상시키지만, 생성된 합성 데이터는 텍스트 프롬프트에만 의존하기 때문에 원본 이미지와의 시각적 유사성이 부족하여 원본 데이터와의 분포 격차를 초래하고 일반화 성능을 저하시킨다.
어려운 실제 데이터를 학습하는 데 합성 데이터의 장점을 극대화하고 합성 데이터와 실제 데이터 간의 격차를 해소하기 위해, 본 논문에서는 diffusion model에서 이미지 guidance를 활용하여 합성 데이터와 실제 데이터 사이의 다양한 interpolation들을 생성하였다. 각 interpolation들의 합성 데이터는 텍스트 프롬프트와 실제 이미지 모두의 guidance에 따라 생성된다. 이미지 guidance가 강할수록 원본 이미지와의 시각적 유사성이 유지되는 반면, 이미지 guidance를 약하게 적용하면 고품질의 다양하고 잠재적으로 학습이 용이한 데이터를 생성할 수 있다. 따라서, 합성 데이터를 실제 데이터로 변환하는 interpolation은 새로운 합성 데이터 공간을 생성하여, 미리 정의된 schedule이나 학습 역학에 따라 수준을 선택함으로써 다양한 학습 단계에 맞춰 데이터의 품질, 다양성, 난이도를 조정할 수 있는 generative curriculum을 설계할 수 있게 한다.
본 논문에서는 까다로운 실제 이미지를 사용하는 두 가지 유형의 응용 분야, 즉 long-tail classification과 저품질 이미지 학습을 위한 새로운 generative curriculum 학습 방식을 개발하였다. Long-tail classification의 경우, tail 클래스는 데이터 부족과 주요 클래스에 비해 다양성이 부족하기 때문에 feature 학습이 어렵다. 원본 데이터의 다양성과 양을 향상시키기 위해 tail 클래스에 대해 낮은 이미지 guidance를 적용한 합성 이미지를 먼저 학습하는 커리큘럼을 제안하였다. 그런 다음 커리큘럼은 guidance level을 점진적으로 높여 원본 이미지에 더 가까운 합성 이미지를 학습함으로써 합성 이미지와 실제 이미지 간의 격차를 점진적으로 줄여나간다.
저품질 이미지 학습의 경우, 원본 이미지의 타겟 클래스에 대한 핵심 feature를 포착하는 것이 어렵다. 반면, 낮은 이미지 guidance로 생성된 이미지는 일반적으로 학습하기 쉬운 전형적인 feature를 포함하고 있다. 그러나 guidance level이 지나치게 높거나 낮으면 학습 데이터와 타겟 데이터 간의 도메인 격차가 커질 수 있다. 도메인 차이로 인한 부정적인 transfer를 방지하고 합성 데이터의 장점을 극대화하기 위해, 각 학습 단계에서 가장 큰 진전을 가져올 수 있는 합성 데이터의 guidance level을 선택하는 적응형 커리큘럼을 개발했다.
저자들은 두 가지 DisCL 커리큘럼을 각각 검증했다. 저품질 이미지 학습의 경우, out-of-distribution 정확도와 in-distribution 정확도를 각각 2.7%와 2.1% 향상시켰다. Long-tail classification의 경우, 소수 클래스의 정확도를 19.24% 향상시키고 전체 정확도를 4.02% 향상시켰다.
Method
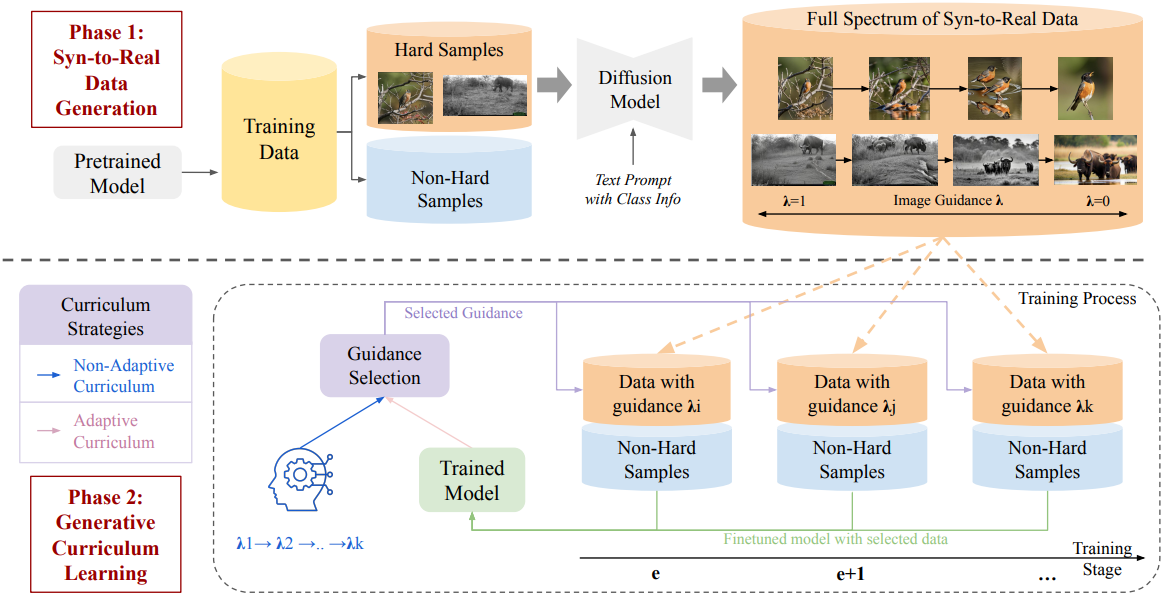
1. Synthetic-to-Real Data Generation
까다로운 샘플 식별
먼저, 모델이 classification에 유용한 feature를 추출하는 데 어려움을 겪는 까다로운 샘플들을 식별한다. 난이도 추정은 task별로 다를 수 있다. 예를 들어, 데이터가 부족한 long-tail classification의 경우, 각 샘플의 난이도는 해당 샘플이 꼬리 클래스에 속하는지 여부에 따라 달라진다. 데이터 품질이 낮은 task의 경우, 정답 클래스에 대한 loss 또는 신뢰도를 활용하여 난이도를 측정할 수 있다. 이러한 샘플들은 모델 학습 과정에서 중요한 역할을 한다는 것을 강조하기 위해 hard samples로 표시된다.
이미지 guidance를 활용한 합성 데이터 생성
Diffusion model에서 classifier 없이 denoising process에 조건 정보를 주입하기 위해 classifier-free guidance이 도입되었다. 원본 이미지의 latent 표현을 \(z_\textrm{real}\)이라 할 때, denoising process는 다음과 같이 정의된 초기값 $z_t$를 사용하여 임의의 step $t$에서 시작할 수 있다.
\[\begin{equation} z_t = \sqrt{\vphantom{1} \bar{\alpha}_t} z_\textrm{real} + \sqrt{1 - \bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N} (0,I) \end{equation}\]나머지 denoising step에서는 각 step $t$에서 noise 추정 프로세스를 반복적으로 적용하여 noise가 적은 \(\textbf{z}_{t-1}\)을 생성하고, $t = 0$이 될 때까지 이 과정을 반복하여 합성 이미지 $z_0$을 생성한다.
\[\begin{equation} \hat{\epsilon}_t = (1 + w) \epsilon_\theta (z_t, t \vert c) - w \epsilon_\theta (z_t, t) \\ z_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( z_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \hat{\epsilon}_t \right) + \sqrt{\beta_t} \epsilon^\prime \end{equation}\](\(\epsilon^\prime \sim \mathcal{N}(0,I)\)은 $\epsilon$과 독립적인 noise, \(\epsilon_\theta\)는 noise 추정 모델, $w$는 guidance 강도)
\(\bar{\alpha}_t\)는 $t$에 따라 단조 감소하므로, 초기 $t$의 선택은 denoising process에서 원본 \(z_\textrm{real}\)의 영향을 제어하며, 작은 $t$에서 초기화할수록 \(z_\textrm{real}\)의 시각적 정보가 $z_0$에 더 많이 보존되는 경향이 있다.
저자들은 실제 이미지 \(z_\textrm{real}\)과 $c$로 표현되는 합성 이미지 사이의 전체 interpolation 범위를 얻기 위해 초기 step $t$를 $t(\lambda) = \lfloor (1 − \lambda)T \rfloor$로 수정하였다. 여기서 $\lambda \in [0, 1)$는 이미지 guidance level을 정의한다.
\[\begin{equation} z_{t (\lambda)} = \sqrt{\bar{\alpha}_{t (\lambda)}} z_\textrm{real} + \sqrt{1 - \bar{\alpha}_{t (\lambda)}} \epsilon \end{equation}\]따라서, guidance level $\lambda$ 값이 클수록 생성된 이미지 $z_0$가 원본 \(z_\textrm{real}\)에 더 가깝게 표현되는 반면, $\lambda$ 값이 작을수록 텍스트 프롬프트 $c$에 의해 묘사된 전형적인 이미지가 생성된다. $\lambda = 0$인 경우에는 텍스트만을 기반으로 이미지가 생성된다.
생성된 이미지들의 Synthetic-to-Real 스펙트럼
본 논문에서는 Stable Diffusion을 사용하여 식별된 까다로운 샘플에 대한 합성 이미지를 생성하였다. Guidance level $\lambda$를 조정함으로써, denoising process는 텍스트만으로 가이드되는 합성 이미지와 실제 이미지 사이의 부드러운 전환을 구현할 수 있다. 저자들은 guidance level $\lambda$의 변화가 생성된 합성 이미지에 미치는 영향을 분석하였다.
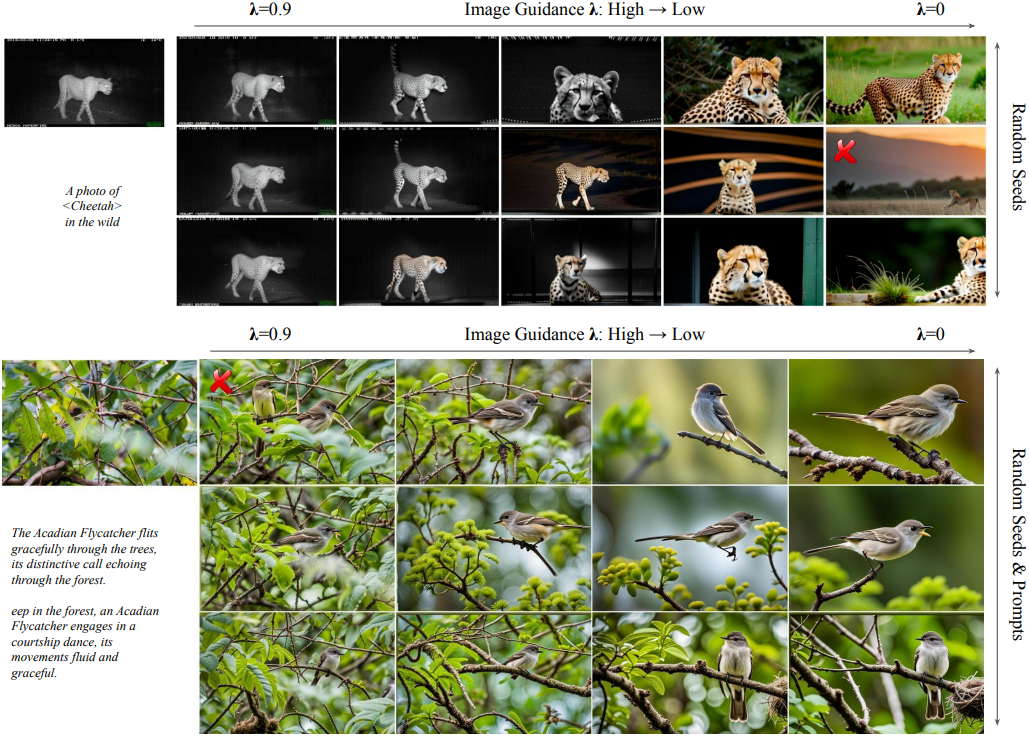
위 그림에서 볼 수 있듯이, $\lambda$를 변화시키면 합성 이미지의 난이도와 다양성이 달라진다. $\lambda$ 값이 작을 경우, diffusion model은 주로 프롬프트 $c$에 제공된 텍스트 정보에 의존하여 원본 이미지와 현저히 다른 합성 이미지를 생성하며, $c$에 제시된 클래스의 전형적인 feature에 더 집중한다. $\lambda$ 값이 증가함에 따라 합성 이미지는 원본 이미지에 점점 더 가까워지며, 다양성은 감소하고 원본 이미지와의 유사성은 증가한다.
원본 이미지의 품질이 낮을 경우, 큰 $\lambda$ 값은 classifier가 합성 이미지에서 feature를 학습하는 데 어려움을 초래한다. 따라서, 광범위한 합성 데이터는 다양성, 난이도, 실제 데이터와의 유사성 등 다양한 특성을 제공하여 curriculum learning을 위한 새로운 design space를 제시한다.
낮은 정확도의 합성 데이터 필터링
일부 합성 이미지는 품질이 떨어지고 텍스트 프롬프트 $c$에 대한 충실도가 낮을 수 있다. 이러한 문제를 완화하기 위해, 합성 이미지와 텍스트 프롬프트 간의 CLIP cosine similarity를 측정하는 CLIP 기반 필터링을 적용하여 이러한 이미지를 걸러낸다. 학습을 시작하기 전에 미리 정의된 CLIPScore threshold 미만의 이미지는 제거된다.
2. Generative Curriculum with Synthetic Data
합성 데이터에서 실제 데이터로의 전 스펙트럼을 아우르는 생성 데이터를 통해, 전형적인 feature와 높은 다양성을 지닌 이미지에서 실제 이미지와 매우 유사한 task별 feature로의 매끄러운 전환을 구현할 수 있다. 이를 통해 데이터의 다양성과 feature 유형을 기반으로 학습 단계별로 적합한 데이터를 선택하는 커리큘럼을 설계할 수 있다. 풍부한 합성 데이터로 구성된 커리큘럼을 활용하면 실제 데이터만으로는 해결하기 어려운 까다롭고 다양한 사례에서 모델 성능을 향상시킬 수 있다. 또한, 이 접근 방식은 원본 데이터와의 분포 차이를 제어할 수 있도록 해준다.
Long-tail classification
소수 클래스의 데이터 부족으로 인해 모델이 이러한 클래스에 대한 유용한 feature를 추출하기 어렵고, 이는 균형 잡힌 test set에서 일반화 성능이 저하되는 결과를 초래한다. 극소수 클래스의 경우, 먼저 전체 스펙트럼의 합성 데이터를 생성한다. 이를 위해 다양한 텍스트 프롬프트를 사용한다. 생성된 스펙트럼은 다양한 수준의 데이터 다양성을 제공하는데, 이를 한꺼번에 사용하면 합성 데이터와 실제 데이터 간의 분포 차이가 발생할 수 있다. 이러한 차이를 완화하기 위해, 먼저 모델을 극소수 클래스의 다양한 합성 이미지에 노출시킨 다음, 점진적으로 원본 이미지와 유사한 task 전용 분포로 전환한다. 이를 통해 낮은 guidance level의 합성 데이터에서 시작하여 점차 높은 guidance level의 데이터로 이동하는 비적응형 Diverse-to-Specific 커리큘럼을 구현할 수 있다.
저품질 이미지로부터 학습
본 논문에서는 이러한 시나리오에서 효과적인 학습을 가능하게 하는 DisCL의 응용 사례로 야생 동물 관찰을 조사하였다. 저품질 카메라 이미지의 경우, 학습을 위한 warm-up 및 더 어려운 케이스에 대한 일반화를 위해 더 단순하고 전형적인 동물 이미지를 생성하는 것을 목표로 한다.
저자들은 사전 학습된 classifier를 사용하여 어려운 샘플을 식별하였다. 정답 클래스 확률이 낮을수록 난이도가 높다는 것을 나타낸다. 저자들은 텍스트 프롬프트의 클래스 정보를 활용하여 이러한 샘플에 대한 전체 스펙트럼 데이터를 합성하였다. 이는 diffusion model이 관련 동물 및 서식지에 대한 feature를 향하도록 유도한다. Long-tail classification과 달리, 저품질 학습의 어려운 샘플은 전형적인 feature와 일반화 가능한 feature가 모두 부족한 경우가 많다. 결과적으로, 낮은 guidance로 생성된 합성 데이터는 종종 전형적인 것처럼 보이지만 분포에서 벗어난 feature를 나타낸다. 이러한 합성 데이터를 초기에 도입하는 비적응형 커리큘럼은 분포 왜곡이나 outlier feature에 대한 과도한 강조의 위험을 초래할 수 있다.
본 논문에서는 적응형 커리큘럼을 제안하였다. 이 커리큘럼은 각 epoch에서 진행률을 기반으로 $\lambda$를 선택한다. 진행률은 각 $\lambda$에 해당하는 validation set에서 정답 클래스 신뢰도 향상으로 정의된다. 가장 높은 진행률을 보인 $\lambda$가 다음 epoch에 선택된다. 이를 통해 모델은 각 단계에서 가장 유용한 데이터를 학습할 수 있으며, 단순한 패턴에서 복잡한 패턴으로의 원활한 전환을 가능하게 하고 실제 데이터 분포에 대한 개선을 극대화한다.
Experiments
1. Long-Tail Classification
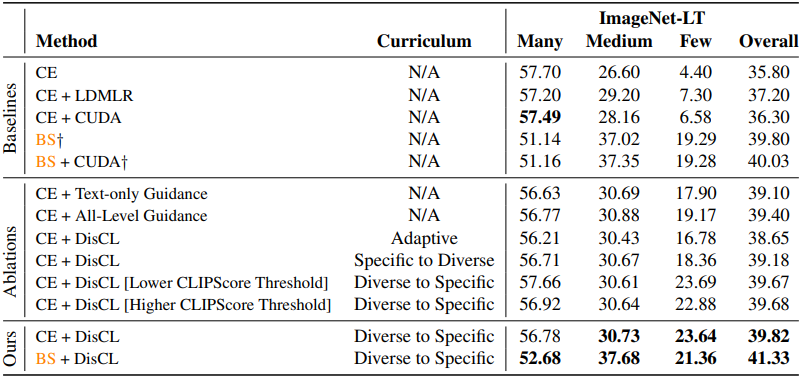
다음은 ImageNet-LT에서의 long-tail classification 정확도이다. (Base model은 ResNet-10)
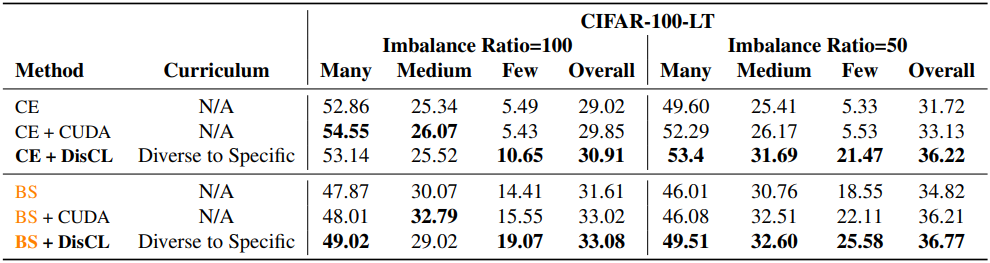
다음은 CIFAR-100-LT에서의 long-tail classification 정확도이다. (Base model은 ResNet-10)
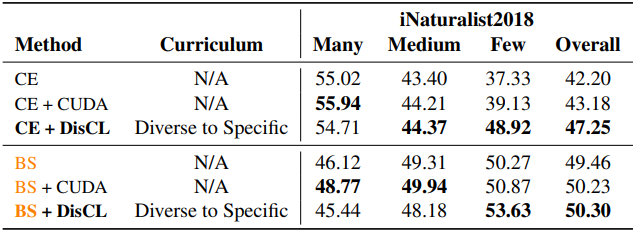
다음은 iNaturalist2018에서의 long-tail classification 정확도이다. (Base model은 ResNet-10)
2. Learning from Low-quality Data
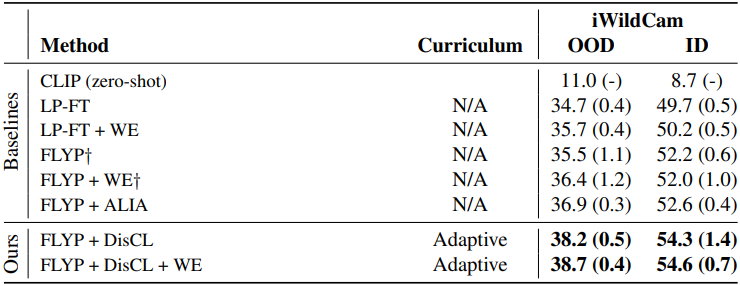
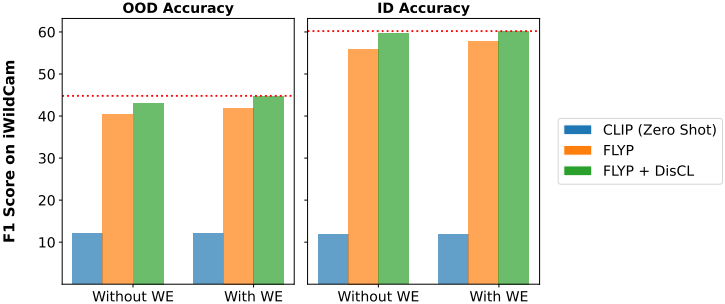
다음은 iWildCam에 대한 in-distribution (ID) 및 out-of-distribution (OOD) F1 score이다.
3. Ablation Study and Analysis
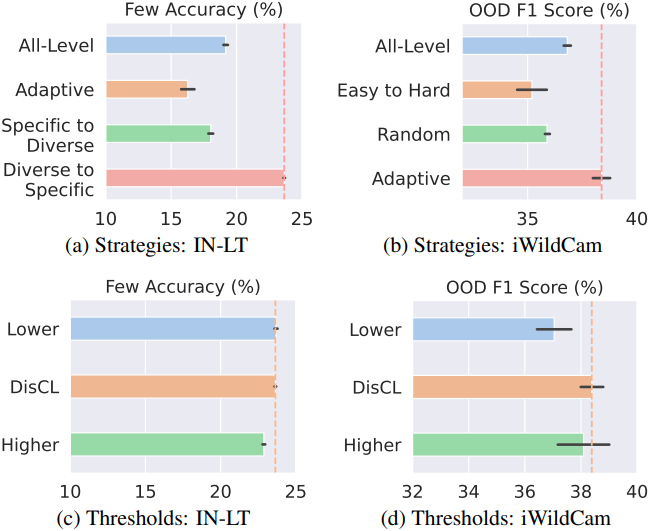
다음은 (a,b) 커리큘럼 전략과 (c,d) CLIPScore threshold에 대한 ablation study 결과이다.
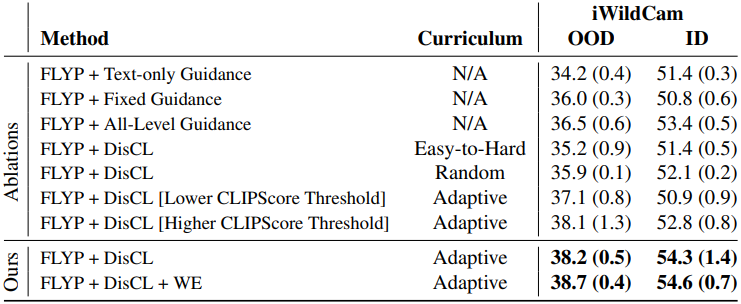
다음은 iWildCam에 대한 ablation study 결과이다.
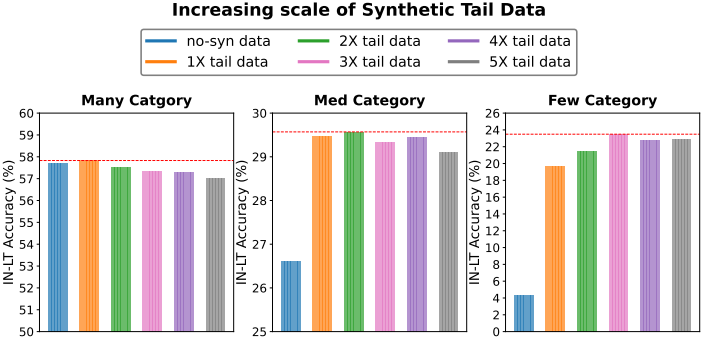
다음은 합성 데이터 스케일에 대한 ablation study 결과이다.