[논문리뷰] DINOv3
arXiv 2025. [Paper] [Page] [Github]
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien Mairal, Hervé Jégou, Patrick Labatut, Piotr Bojanowski
Meta AI Research | WRI | Inria
13 Aug 2025
Introduction
Self-supervised learning (SSL)을 위하여 제약 없는 대량의 데이터를 활용해 임의로 크고 강력한 모델을 만드는 것은 대규모로 scaling할 때 여전히 도전적인 과제로 남아 있다. DINOv2는 제안한 휴리스틱들로 모델 불안정성과 붕괴 문제를 완화하였지만, 더 큰 규모로 scaling할 경우 새로운 문제가 나타난다.
- 레이블이 없는 데이터 집합에서 어떻게 유용한 데이터를 수집할 수 있는지는 불분명하다.
- 일반적인 학습 관행에서 사용하는 cosine schedule은 최적화의 학습 종료 시점을 사전에 알아야 하는데, 이는 대규모 이미지 데이터셋을 학습할 때는 어렵다.
- Feature 표현의 성능은 초기 학습 이후 점차 감소한다. 이러한 현상은 ViT-Large (3OOM) 이상의 모델을 더 오랜 시간 학습할 때 나타나며, 이로 인해 DINOv2의 scalability가 떨어진다.
저자들은 위의 문제들을 해결하여 대규모 SSL 학습을 발전시키는 DINOv3를 도출했다.
먼저, 자동 데이터 큐레이션 분야의 최근 발전을 바탕으로 대용량 백그라운드 학습 데이터셋을 확보하고, 이를 ImageNet-1k와 같은 특수 데이터와 신중하게 혼합하였다. 이를 통해 제약 조건이 없는 대용량 데이터를 활용하여 모델 성능을 향상시켰다.
저자들은 ViT 아키텍처를 수정하여 기본 모델 크기를 7B 파라미터로 늘렸다. 최신 위치 임베딩인 axial RoPE를 포함하고 위치 아티팩트를 방지하기 위한 정규화 기법을 개발하였다. DINOv2의 다중 cosine schedule 대신, 100만 iteration의 상수 hyperparameter schedule을 사용하여 학습시켰다. 이를 통해 더 강력한 성능의 모델을 생성하였다.
위의 기법들을 통해 DINOv2 알고리즘을 따르는 모델을 대규모로 학습할 수 있다. 그러나 scaling은 dense feature의 저하로 이어진다. 이 문제를 해결하기 위해, 본 논문에서는 Gram anchoring 학습 단계를 도입하여 파이프라인의 핵심적인 개선을 제안하였다. 이를 통해 feature map의 노이즈를 제거하고, 인상적인 유사도 맵을 생성하며, dense task에서 성능을 크게 향상시켰다.
또한, 저자들은 고해상도 사후 학습 후, 다양한 크기의 고성능 모델로 distillation하였다. Distillation을 위해, 하나의 teacher와 여러 student를 대상으로 하는 새롭고 효율적인 distillation 절차를 개발하였다.
Training at Scale Without Supervision
1. Data Preparation
데이터 스케일링은 대규모 foundation model 성공의 원동력 중 하나이다. 그러나 단순히 학습 데이터 크기를 늘리는 것이 반드시 모델 품질 향상과 다운스트림 벤치마크 성능 향상으로 이어지지는 않는다. 성공적인 데이터 스케일링 노력은 일반적으로 신중한 데이터 큐레이션 파이프라인을 포함한다. 저자들은 DINOv3 개발을 위해, 모델의 일반화 가능성과 성능을 모두 향상시키기 위해 두 가지 상호 보완적인 접근 방식을 결합하여 두 목표 간의 균형을 맞추었다.
Data Collection and Curation
저자들은 인스타그램의 공개 게시물에서 수집한 대규모 웹 이미지 데이터 풀을 활용하여 대규모 사전 학습 데이터셋을 구축하였다. 이 이미지들은 유해 콘텐츠 방지를 위해 플랫폼 수준의 콘텐츠 검열을 이미 거쳤으며, 약 170억 개의 이미지로 구성된 초기 데이터 풀을 확보했다. 이 초기 데이터 풀을 사용하여 세 가지 데이터셋을 생성하였다.
- 계층적 k-means 기반 자동 큐레이션 방법을 적용: DINOv2를 이미지 임베딩으로 사용하고, 클러스터 개수를 최하위부터 최상위까지 각각 2억, 8백만, 80만, 10만, 2만 5천 개로 5단계 클러스터링을 사용하였다. 그 결과, 웹에 나타나는 모든 시각적 개념에 대한 균형 잡힌 커버리지를 보장하는 약 16억 8,900만 개의 이미지로 구성된 데이터셋이 생성되었다. (LVD-1689M라고 부름)
- DINOv2가 제안한 절차와 유사한 검색 기반 큐레이션 시스템을 적용: 선택된 시드 데이터셋과 유사한 이미지를 데이터 풀에서 검색하여 후속 task에 필요한 시각적 개념을 포함하는 데이터셋을 생성하였다.
- ImageNet1k, ImageNet22k, Mapillary Street-level Sequences를 포함한 공개적으로 사용 가능한 컴퓨터 비전 데이터셋
Data Sampling
사전 학습 과정에서 샘플러를 사용하여 서로 다른 데이터 데이터셋을 혼합한다. 데이터를 혼합하는 데에는 여러 가지 옵션이 있다.
- homogeneous batch: 각 iteration에서 무작위로 선택된 하나의 데이터셋으로 구성한 batch
- heterogeneous batch: 특정 비율로 각 데이터셋에서 가져온 데이터로 구성한 batch
저자들은 ImageNet1k로 구성한 homogeneous batch를 10%, 모든 데이터를 혼합한 heterogeneous batch를 90%로 샘플링하여 사용하였다.
Data Ablation
다음은 클러스터링 또는 검색 기반 기법만으로 큐레이션된 데이터셋 및 초기 데이터 풀과 LVD-1689M을 비교한 ablation study 결과이다.

모든 벤치마크에서 하나의 큐레이션 기법만 사용하는 것이 가장 효과적인 것은 아니며, 전체 파이프라인을 통해 두 가지 장점을 모두 얻을 수 있음을 알 수 있다.
2. Large-Scale Training with Self-Supervision
Learning Objective
저자들은 글로벌 및 로컬 loss 항을 모두 갖는 여러 self-supervised loss의 혼합인 discriminative self-supervised 전략으로 모델을 학습시켰다.
\[\begin{equation} \mathcal{L}_\textrm{Pre} = \mathcal{L}_\textrm{DINO} + \mathcal{L}_\textrm{iBOT} + 0.1 \mathcal{L}_\textrm{DKoleo} \end{equation}\]- \(\mathcal{L}_\textrm{DINO}\): DINO의 image-level loss
- \(\mathcal{L}_\textrm{iBOT}\): iBOT의 patch-level latent reconstruction loss
- \(\mathcal{L}_\textrm{Koleo}\): batch 내의 feature들이 균일하게 분포하도록 하는 Koleo regularizer
Updated Model Architecture
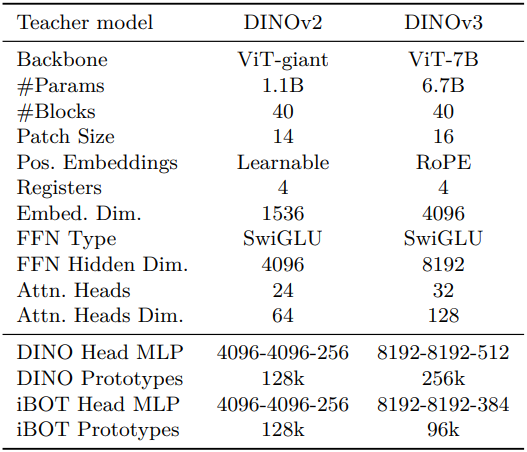
저자들은 모델의 크기를 7B로 늘렸으며, DINOv2의 1.1B 모델과의 hyperparameter 비교는 아래 표와 같다.
또한 RoPE의 커스텀 변형을 사용하였다. 기본 구현은 각 패치에 정규화된 $[-1, 1]$ 박스의 좌표를 할당한 다음 두 패치의 상대적 위치에 따라 multi-head attention 연산에 편향을 적용한다. 해상도, 크기, 종횡비에 대한 모델의 robustness를 개선하기 위해 RoPE-box jittering을 사용하였다. 좌표 박스 $[-1, 1]$은 무작위로 $[-s, s]$로 확장되며, $s \in [0.5, 2]$이다.
Optimization
모델 용량과 학습 데이터 복잡도 간의 상호작용을 사전에 평가하기 어렵기 때문에 적절한 최적화 범위를 추측하는 것은 불가능하다. 이를 극복하기 위해, 저자들은 모든 파라미터 스케줄링을 제거하고 일정한 learning rate, weight decay, teacher EMA momentum을 사용하여 학습시켰다. 이는 두 가지 주요 이점을 제공한다.
- 다운스트림 성능이 지속적으로 향상되는 한 학습을 계속할 수 있다.
- 최적화 hyperparameter의 수가 줄어들어 적절한 hyperparameter를 더 쉽게 선택할 수 있다.
학습 디테일은 다음과 같다.
- optimizer: AdamW
- 총 batch sizes는 이미지 4,096개, GPU 256개에 분할
- learning rate와 teacher temperature에 linear warmup 사용
- 이미지당 2개의 global crop $256^2$과 8개의 local crop $112^2$을 사용
- batch당 총 시퀀스 길이: 약 370만 토큰
Gram Anchoring: A Regularization for Dense Features
1. Loss of Patch-Level Consistency Over Training
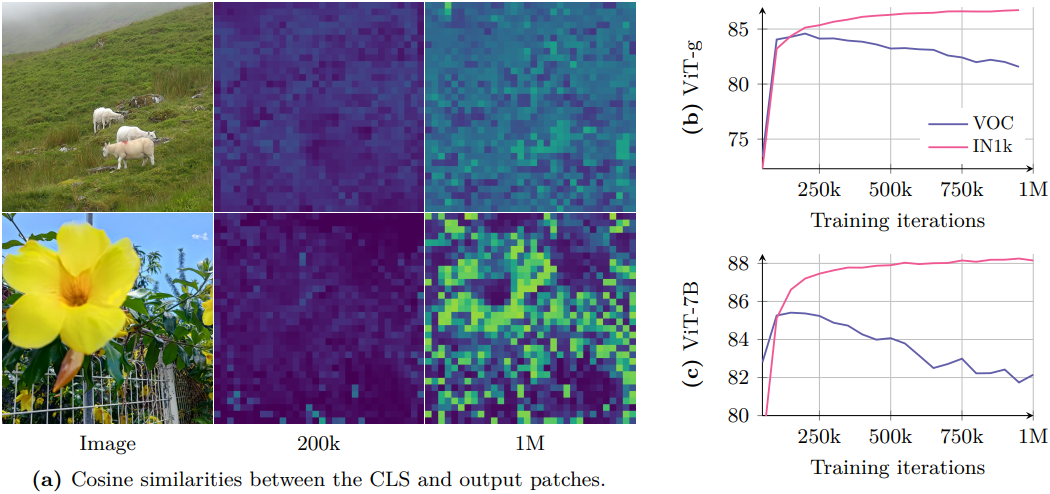
대규모 학습의 이점을 최대한 활용하기 위해, 7B 모델을 잠재적으로 무한정 학습할 수 있다는 전제 하에 장기간 학습하는 것을 목표로 하였다. 장기간 학습은 글로벌 벤치마크에서 향상을 가져오지만 (ex. ImageNet1k), 학습이 진행됨에 따라 dense task에서의 성능은 저하된다 (ex. Pascal VOC). 이러한 현상은 feature 표현에서 패치 수준의 불일치가 생겨 발생하며, 장기간 학습의 중요성을 약화시킨다.
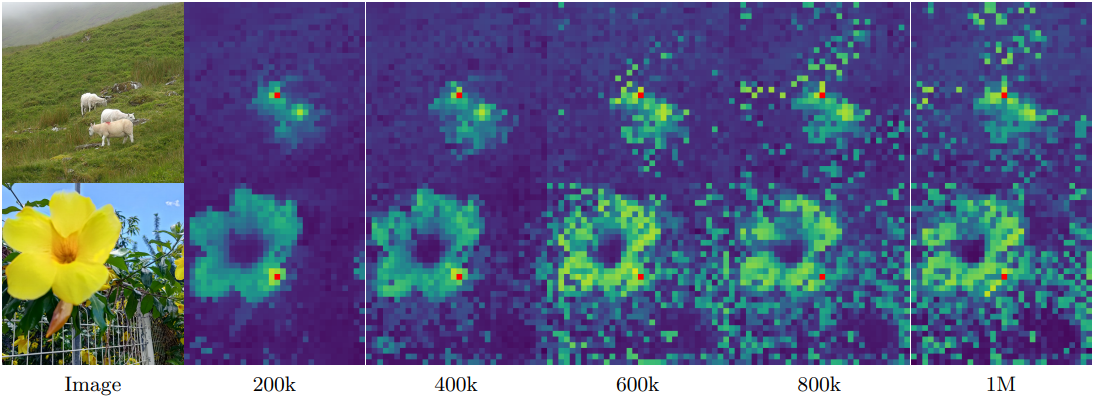
저자들은 이러한 현상을 더 잘 이해하기 위해 패치 간 코사인 유사도를 시각화하여 패치 feature의 품질을 분석하였다. 위 그림은 backbone 출력 패치 feature와 레퍼런스 패치 (빨간색 강조 표시) 간의 코사인 유사도 맵을 보여준다. 200k에서 유사도 맵은 매끄럽고 잘 localize되어 패치 수준에서 일관된 표현을 나타낸다. 그러나 600k 이후에는 맵의 품질이 크게 저하되어 레퍼런스 패치와 높은 유사도를 가진 관련 없는 패치의 수가 증가한다. 이러한 패치 수준의 일관성 저하는 dense task 성능 저하와 상관관계가 있다.
저자들은 dense task에서의 성능 저하를 완화하기 위해, 높은 글로벌 성능을 유지하면서 패치 feature를 정규화하고 우수한 패치 수준 일관성을 보장하도록 새로운 Gram anchoring objective를 제안하였다.
2. Gram Anchoring Objective
강력한 판별적인 feature 학습과 로컬 일관성 유지 사이에 상대적인 독립성이 존재한다. 이는 글로벌 성능과 dense task 성능 간의 상관관계 부족에서 관찰되었다. 글로벌 DINO loss와 로컬 iBOT loss를 결합하여 이 문제를 해결하기 시작했지만, 학습이 진행됨에 따라 글로벌 표현이 우세해지면서 균형이 불안정해진다.
저자들은 패치 수준 일관성의 품질을 강화하여 feature 자체에는 영향을 주지 않으면서 패치 수준 일관성의 저하를 완화하는 새로운 loss를 도입하였다. 이 새로운 loss function은 Gram matrix에서 작동한다. Gram matrix는 이미지 내 패치 feature들의 모든 쌍별 내적 행렬이다.
Student의 Gram matrix를 Gram teacher라고 불리는 이전 모델의 Gram matrix로 이동시키고자 한다. 우수한 dense 특성을 보이는 teacher 네트워크의 초기 iteration으로 Gram teacher를 선택한다. Feature 자체가 아닌 Gram matrix에서 작동함으로써, 유사성 구조가 동일하게 유지되는 한 로컬 feature들은 자유롭게 이동할 수 있다.
$P$개의 패치로 구성된 이미지와 차원 $d$에서 작동하는 네트워크가 있다고 가정하자. Student와 Gram teacher의 $L_2$ 정규화된 로컬 feature들의 $P \times d$ 행렬을 각각 \(\textbf{X}_S\)와 \(\textbf{X}_G\)라 하면, \(\mathcal{L}_\textrm{Gram}\)은 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{Gram} = \| \textbf{X}_S \cdot \textbf{X}_S^\top - \textbf{X}_G \cdot \textbf{X}_G^\top \|_F^2 \end{equation}\]이 loss는 global crop에 대해서만 계산된다. 학습의 효율성을 위해 100만 iteration 이후에 \(\mathcal{L}_\textrm{Gram}\)를 적용한다. 흥미롭게도, \(\mathcal{L}_\textrm{Gram}\)을 늦게 적용해도 심하게 저하된 로컬 feature들이 복구된다. 성능을 더욱 향상시키기 위해, Gram teacher가 EMA teacher와 동일해지는 1만 iteration마다 Gram teacher를 업데이트한다. 이 두 번째 학습 단계를 refinement step이라 부르며, 이는 \(\mathcal{L}_\textrm{Ref}\)를 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{Ref} = w_\textrm{D} \mathcal{L}_\textrm{DINO} + \mathcal{L}_\textrm{iBOT} + w_\textrm{DK} \mathcal{L}_\textrm{DKoleo} + w_\textrm{Gram} \mathcal{L}_\textrm{Gram} \end{equation}\]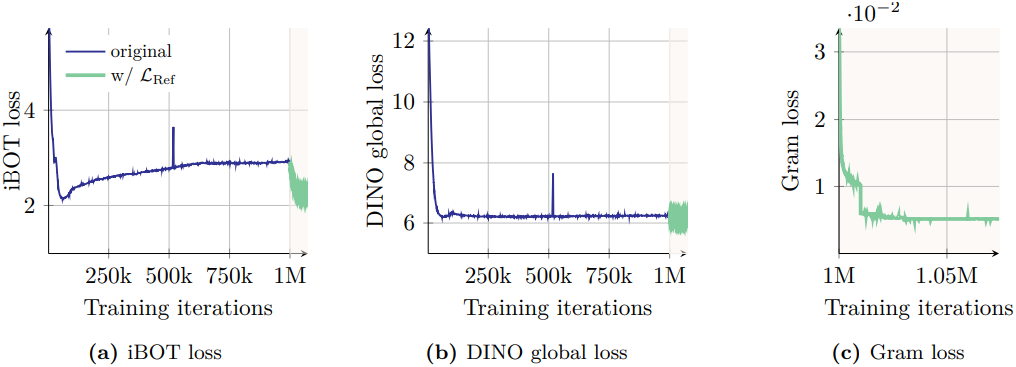
위의 loss 그래프에서 볼 수 있듯이, Gram loss를 적용하면 iBOT loss에 상당한 영향을 미쳐 loss가 더 빠르게 감소한다. 이는 안정적인 Gram teacher가 도입한 안정성이 iBOT loss에 긍정적인 영향을 미친다는 것을 시사한다. 반면, Gram loss는 DINO loss에 유의미한 영향을 미치지 않는다. 이는 Gram loss와 iBOT loss가 feature에 유사한 방식으로 영향을 미치는 반면, DINO loss는 feature에 서로 다른 영향을 미친다는 것을 의미한다.
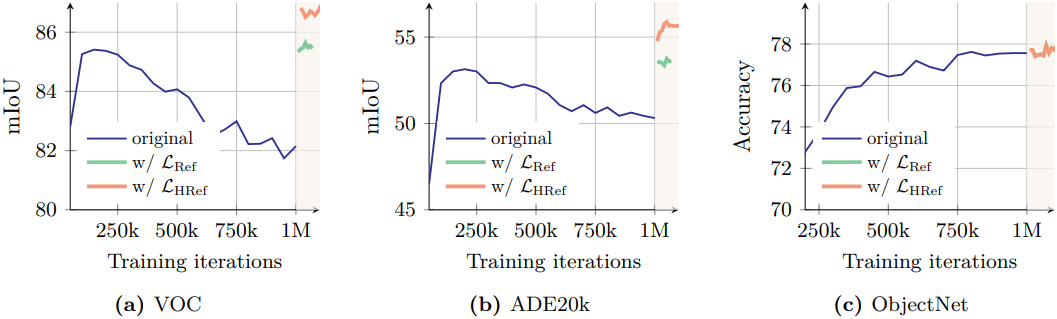
성능 측면에서, 새로운 loss의 영향은 거의 즉각적으로 나타났다. 위 그래프에서 볼 수 있듯이, Gram anchoring을 적용하면 dense task 성능이 크게 향상된다. 또한, Gram teacher 업데이트 이후 ADE20k 벤치마크에서도 눈에 띄는 향상이 확인되었다. 또한, 학습 시간이 길어질수록 ObjectNet 벤치마크 성능에 더욱 도움이 되었으며, 다른 글로벌 벤치마크에서도 새로운 loss의 영향이 미미한 것으로 나타났다.
3. Leveraging Higher-Resolution Features
CLIP-DINOiser에 따르면 패치 feature의 가중 평균은 outlier 패치들을 smoothing하고 패치 수준 일관성을 향상시켜 더 강력한 로컬 표현을 생성할 수 있다. 반면, 고해상도 이미지를 backbone에 입력하면 더 세밀하고 상세한 feature map이 생성된다. 두 가지 관찰 결과의 이점을 활용하여 Gram teacher를 위한 고품질 feature를 계산한다.
구체적으로, 먼저 일반 해상도의 두 배 이미지를 Gram teacher에 입력한 다음, bicubic interpolation을 사용하여 결과 feature map을 2배 다운샘플링하여 student 출력 크기에 맞는 원하는 부드러운 feature map을 얻는다. 고해상도 feature의 우수한 패치 수준 일관성은 다운샘플링을 통해 유지되어 더 부드럽고 일관된 패치 수준 표현을 얻도록 도와준다. 모델이 RoPE를 채택하였기 때문에 다양한 해상도의 이미지를 원활하게 처리할 수 있다.

다운샘플링된 feature의 Gram matrix를 계산하고 이를 \(\mathcal{L}_\textrm{Gram}\)의 \(\textbf{X}_G\)를 대체하여 데 사용한다. \(\mathcal{L}_\textrm{Ref}\)를 대체하는 이 새로운 loss를 \(\mathcal{L}_\textrm{HRef}\)로 표시한다. 이 접근법을 통해 Gram loss는 smoothing된 고해상도 feature의 향상된 패치 일관성을 student 모델로 효과적으로 추출할 수 있다. 이러한 추출은 dense task에 대한 더 나은 예측으로 이어져 \(\mathcal{L}_\textrm{Ref}\)가 가져오는 이점에 더해 추가적인 이득을 가져온다. 흥미롭게도 100k 또는 200k iteration의 Gram teacher를 선택하는 것은 결과에 큰 영향을 미치지 않지만, 1M iteration의 Gram teacher를 사용하는 것은 해당 teacher의 패치 수준 일관성이 떨어지기 때문에 해롭다.
다음은 Gram anchoring의 효과를 시각화한 예시이다.

Post-Training
1. Resolution Scaling
저자들은 속도와 효과성 간에 좋은 균형을 이루는 256의 비교적 작은 해상도에서 모델을 학습시켰다. 그러나 많은 컴퓨터 비전 애플리케이션은 복잡한 공간 정보를 포착하기 위해 512$\times$512 픽셀 이상의 상당히 높은 해상도에서 이미지를 처리해야 한다. Inference 이미지 해상도도 실제로 고정되어 있지 않으며 사용 사례에 따라 달라진다.
이를 해결하기 위해, 저자들은 고해상도 적응 단계로 학습 체계를 확장하였다. 다양한 해상도에서 높은 성능을 보장하기 위해 혼합 해상도를 사용하여 mini-batch당 서로 다른 크기의 global crop 및 local crop 쌍을 샘플링한다. 구체적으로, {512, 768}의 global crop 크기와 {112, 168, 224, 336}의 local crop 크기를 고려하여 추가 1만 iteration에 대해 모델을 학습시켰다.
메인 학습과 마찬가지로, 이 고해상도 적응 단계의 핵심은 7B teacher를 Gram teacher로 사용하는 Gram anchoring을 추가하는 것이다. Gram anchoring이 없으면 dense task에서 모델 성능이 크게 저하된다. Gram anchoring은 모델이 공간적 위치 전반에 걸쳐 일관되고 견고한 feature 상관관계를 유지하도록 지원하며, 이는 고해상도 입력의 복잡성 증가를 처리할 때 매우 중요하다.
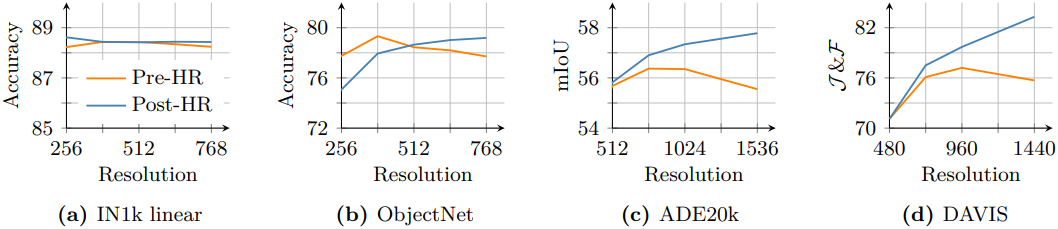
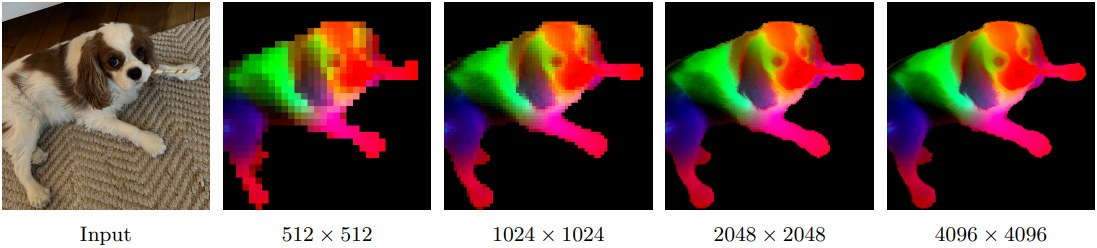
위 그림은 고해상도 적응 전후의 7B 모델을 비교한 결과이다. 고해상도 적응은 이미지 크기에 따라 로컬 feature가 향상되도록 하여, 더 높은 해상도에서 사용 가능한 더 풍부한 공간 정보를 활용하고 고해상도 추론을 효과적으로 가능하게 한다. 흥미롭게도, 적용된 모델은 최대 학습 해상도인 768을 훨씬 뛰어넘는 해상도를 지원한다. 4k 이상의 해상도에서 안정적인 feature map을 시각적으로 관찰할 수 있다.
2. Model Distillation
A Family of Models for Multiple Use-Cases
저자들은 ViT-7B 모델을 더 작은 ViT로 knowledge distillation하였다. Distillation 방식은 첫 번째 학습 단계와 동일한 loss를 사용하여 학습 신호의 일관성을 보장한다. 하지만 모델 가중치의 EMA에 의존하는 대신, 7B 모델을 teacher로 직접 사용하여 더 작은 student 모델을 가이드하였다. 이 경우 teacher 모델은 고정된다. 패치 수준의 일관성 문제는 관찰되지 않으므로 Gram anchoring 기법을 적용하지 않는다. 이 전략을 통해 distillation된 모델은 대규모 teacher 모델의 풍부한 표현력을 계승하면서도 더 실용적이다.
Distillation된 ViT-S, ViT-B, ViT-L은 각각 21M, 86M, 0.3B이며, 저자들은 추가로 커스텀 ViT-S+ (29M)와 커스텀 ViT-H+ (0.8B) 모델로도 distillation하였다. 모델들은 각각 100만 iteration으로 학습된 후, Gram anchoring 없이 25만 iteration동안 cosine schedule에 따라 learning rate 쿨다운을 하였다. 그런 다음, Gram anchoring 추가하여 고해상도 적응 단계를 적용하였다.
Efficient Multi-Student Distillation
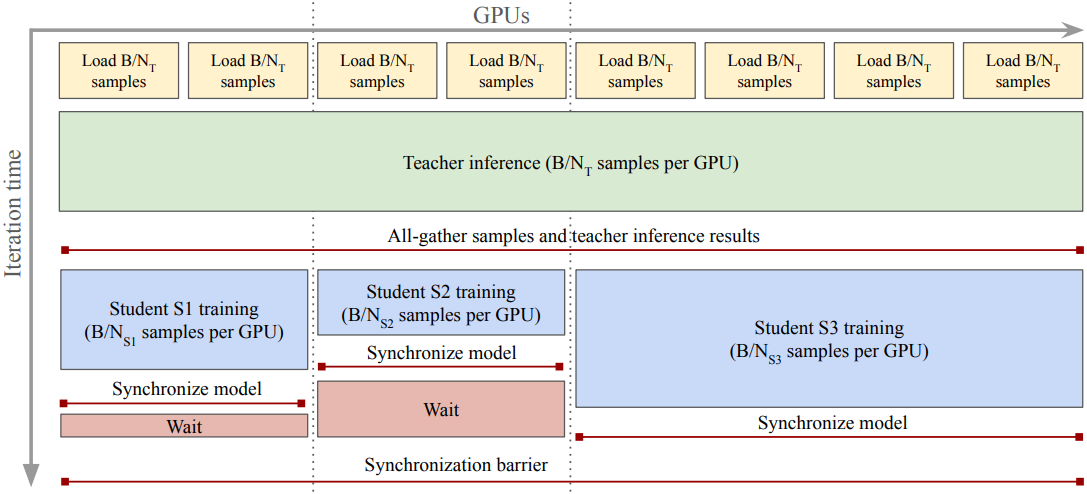
큰 teacher 모델의 inference 비용이 student 모델의 inference 비용보다 훨씬 높을 수 있으므로, 저자들은 여러 student를 동시에 학습시키고 학습에 관련된 모든 노드에서 teacher inference를 공유할 수 있는 병렬 distillation 파이프라인을 설계하였다. 이 파이프라인을 통해 각 iteration에서 GPU당 컴퓨팅이 줄어들어 distillation 속도가 전반적으로 향상되며, 전체 teacher inference 비용이 고정되므로 새 student의 학습 비용만큼만 전체 컴퓨팅이 증가한다.
3. Aligning DINOv3 with Text
저자들은 DINOv2 meets text에서 제안된 학습 전략을 채택하여 텍스트 인코더를 DINOv3 모델에 맞추었다. 이 접근법은 LiT 학습 패러다임을 따르며, vision encoder를 고정시킨 상태에서 contrastive loss를 사용하여 이미지를 캡션과 일치시키도록 텍스트 표현을 처음부터 학습시킨다. 비전 측면에서 어느 정도 유연성을 허용하기 위해 두 개의 transformer layer가 고정된 vison backbone 위에 도입된다. 이 방법의 핵심은 텍스트 임베딩과 일치시키기 전에 mean pooling된 패치 임베딩을 출력 CLS 토큰과 concat하는 것이다. 이를 통해 글로벌 feature와 로컬 시각적 feature를 텍스트에 맞출 수 있으므로 추가적인 휴리스틱이나 트릭이 필요하지 않고 dense task에서 성능이 향상된다.
Results
1. DINOv3 provides Exceptional Dense Features
다음은 PCA를 사용하여 dense feature map을 RGB로 매핑한 결과이다.

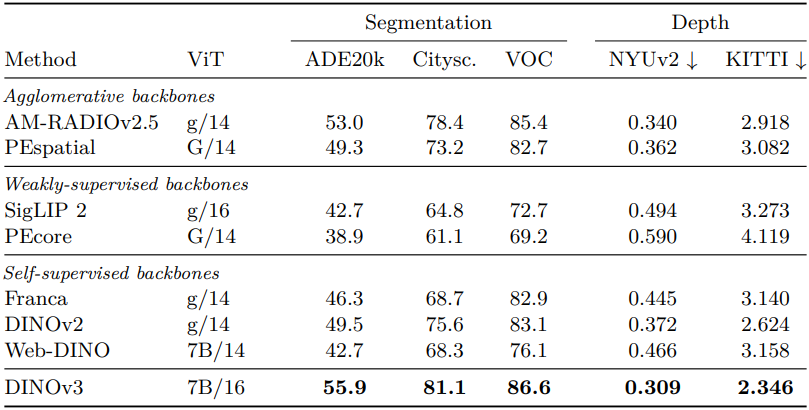
다음은 semantic segmentation과 monocular depth estimation에 대한 dense linear probing 결과를 비교한 것이다.
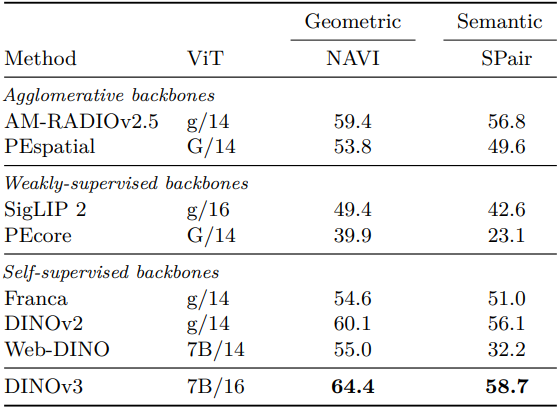
다음은 표현의 3D 일관성을 비교한 결과이다.
다음은 unsupervised object discovery 결과이다.
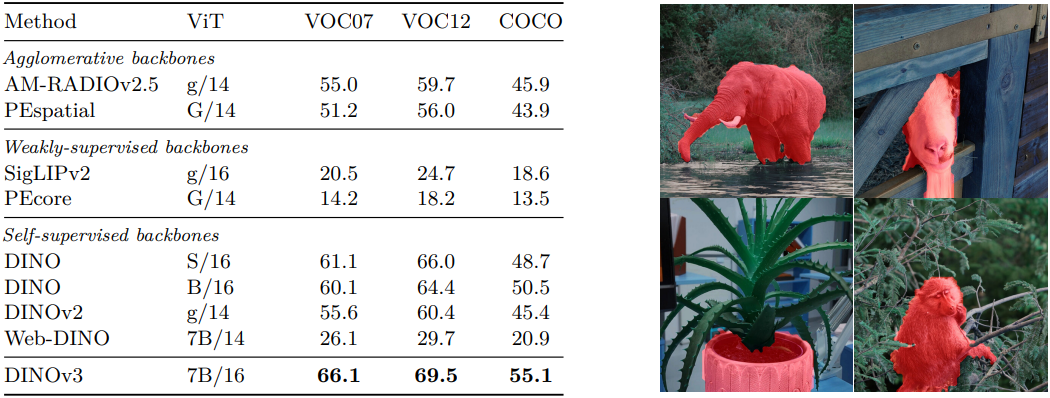
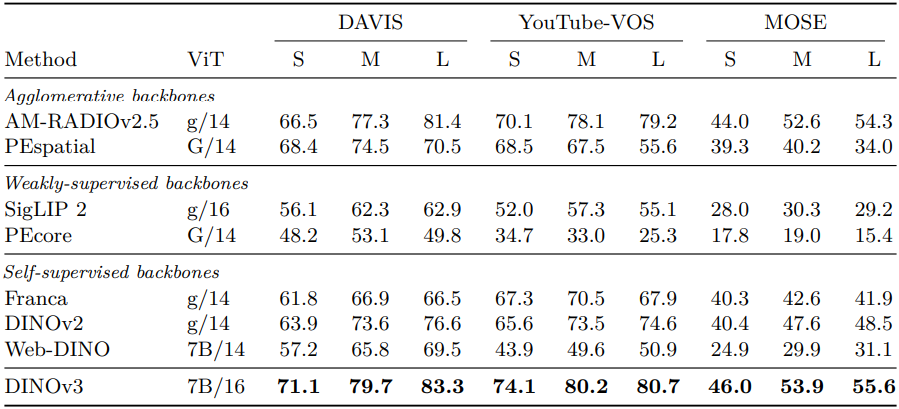
다음은 video segmentation tracking 결과이다.

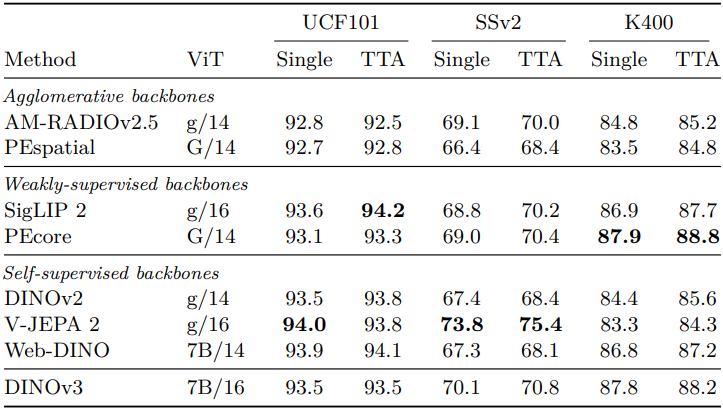
다음은 attentive probe를 사용한 video classification 결과이다.
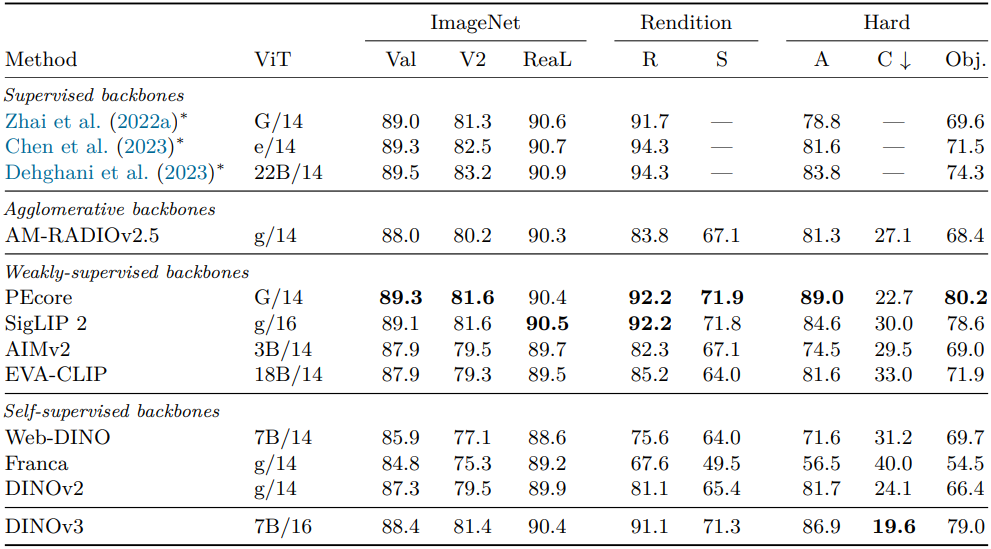
2. DINOv3 has Robust and Versatile Global Image Descriptors
다음은 ImageNet1k로 학습된 linear probe에 대한 classification 정확도를 다른 데이터셋에 대하여 평가한 결과이다.
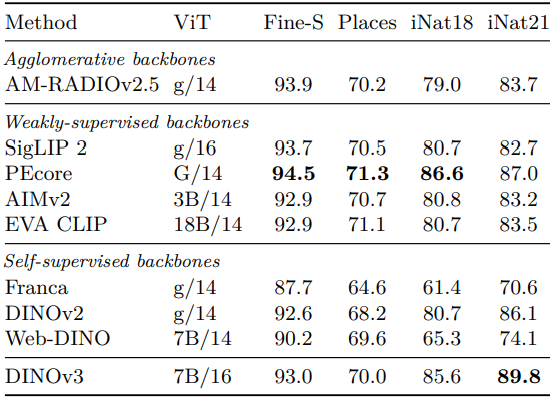
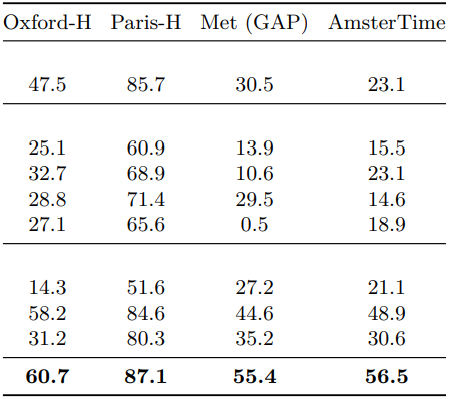
다음은 (왼쪽) finegrained classification과 (오른쪽) instance recognition 결과이다.
3. DINOv3 is a Foundation for Complex Computer Vision Systems
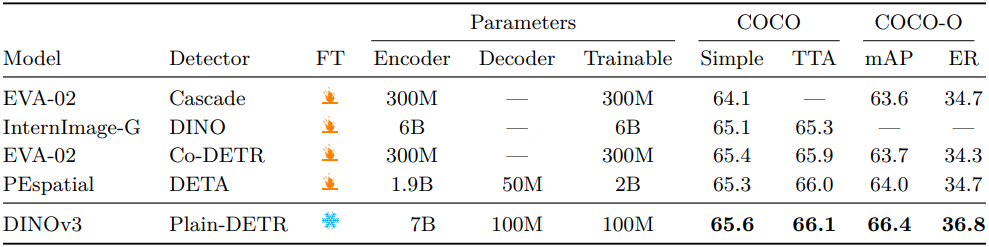
다음은 COCO에서 object detection 성능을 비교한 결과이다.
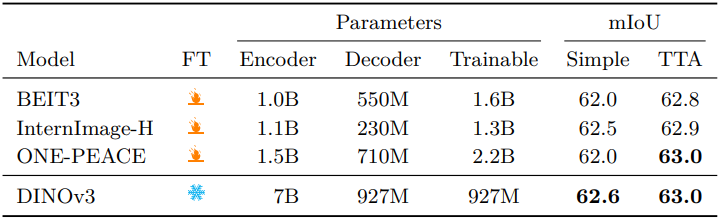
다음은 ADE20k에서 semantic segmentation 성능을 비교한 결과이다.
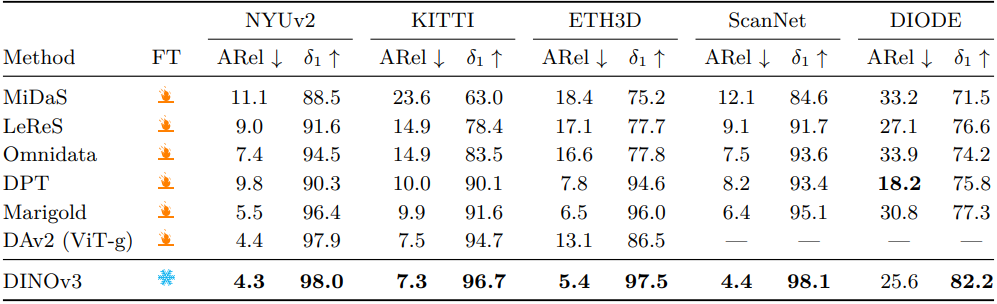
다음은 monocular depth estimation 성능을 비교한 결과이다.
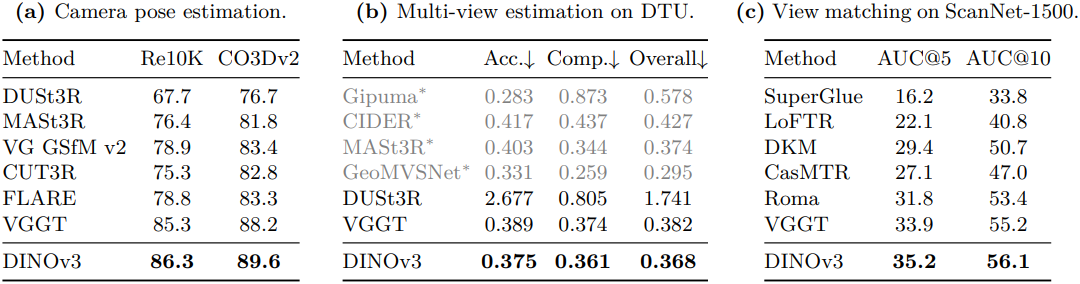
다음은 VGGT를 사용한 3D 이해 성능을 비교한 결과이다.