[논문리뷰] DINOv2: Learning Robust Visual Features without Supervision
arXiv 2023. [Paper] [Blog] [Github]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski
Meta AI Research | Inria
14 Apr 2023
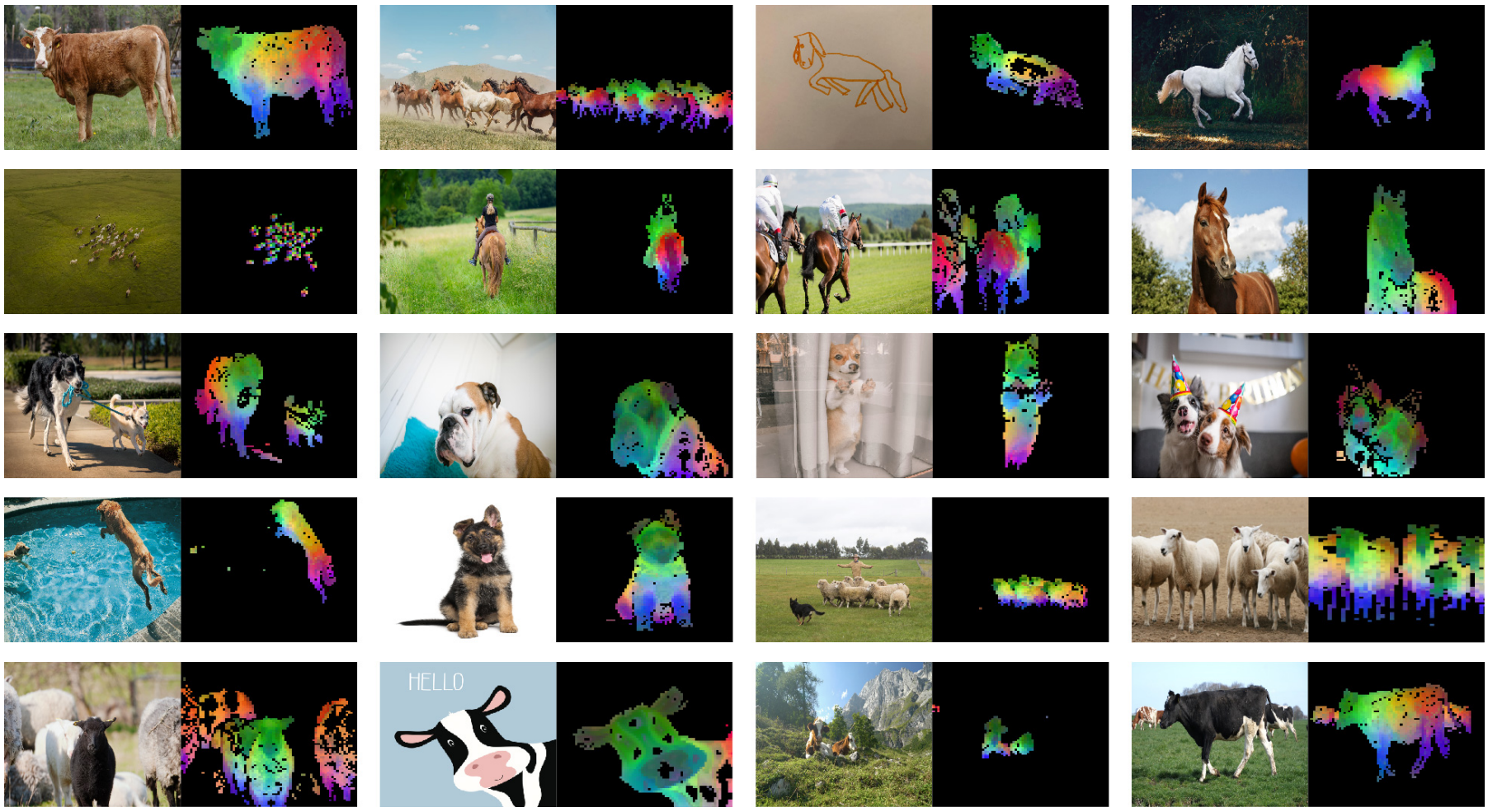
 (첫번째 PCA 성분의 시각화)
(첫번째 PCA 성분의 시각화)
Introduction
학습 task에 구애받지 않는 사전 학습된 표현은 자연어 처리(NLP)의 표준이 되었다. 즉, fine-tuning 없이 이러한 feature들을 “있는 그대로” 사용할 수 있으며 task별 모델에서 생성된 것보다 훨씬 우수한 downstream task에 대한 성능을 달성할 수 있다. 이러한 성공은 supervision이 필요하지 않은 언어 모델링 또는 word vector와 같은 pretext 목적 함수를 사용하여 대량의 텍스트에 대한 사전 학습을 통해 이루어졌다.
저자들은 NLP의 이러한 패러다임 변화에 따라 유사한 “기초” 모델이 컴퓨터 비전에 나타날 것으로 예상하였다. 이러한 모델은 모든 task에서 이미지 레벨 및 픽셀 레벨 모두에서 기본적으로 작동하는 시각적 feature를 생성해야 한다. 이러한 기본 모델에 대한 가장 유망한 노력은 텍스트 안내 사전 학습에 중점을 둔다. 이러한 형식의 텍스트 안내 사전 학습은 캡션이 이미지의 풍부한 정보에 근접하기 때문에 이미지에 대해 유지할 수 있는 정보를 제한하고 복잡한 픽셀 레벨 정보는 이 supervision으로 표시되지 않을 수 있다. 또한 이러한 이미지 인코더는 텍스트-이미지 corpus를 필요로 하므로 원시 데이터만으로 학습할 수 있는 텍스트 인코더의 유연성을 제공하지 않는다.
텍스트 안내 사전 학습의 대안은 이미지만으로 feature를 학습하는 self-supervised learning이다. 이러한 접근 방식은 개념적으로 언어 모델링과 같은 pretext task에 더 가깝고 이미지 및 픽셀 레벨에서 정보를 캡처할 수 있다. 그러나 다목적 feature를 학습할 수 있는 잠재력에도 불구하고 self-supervised learning의 발전 대부분은 소규모 큐레이팅된 데이터셋인 ImageNet-1k에 대한 사전 학습의 맥락에서 이루어졌다. ImageNet-1k 이상으로 이러한 접근 방식을 확장하려는 일부 노력이 시도되었지만 일반적으로 feature의 품질이 크게 저하되는 선별되지 않은 데이터셋에 중점을 두었다. 이는 우수한 feature를 생성하는 데 필수적인 데이터 품질과 다양성에 대한 제어 부족으로 설명된다.
본 논문에서는 self-supervised learning이 대량의 선별된 데이터에 대해 사전 학습된 경우 다목적의 시각적 feature을 학습할 수 있는 잠재력이 있는지 탐색한다. iBOT과 같이 이미지와 패치 레벨 모두에서 feature를 학습하는 기존의 discriminative self-supervised 접근 방식을 재검토하고 더 큰 데이터셋의 관점에서 일부 디자인 선택을 재고한다. 본 논문의 기술적 기여는 대부분 모델과 데이터 크기를 확장할 때 discriminative self-supervised learning을 안정화하고 가속화하는 데 맞춰져 있다. 이러한 개선 사항은 본 논문의 접근 방식을 약 2배 더 빠르게 만들고 유사한 discriminative self-supervised 방법보다 3배 더 적은 메모리를 필요로 하므로 더 큰 batch size로 더 긴 학습을 활용할 수 있다.
저자들은 사전 학습 데이터와 관련하여 선별되지 않은 광범위한 이미지 컬렉션에서 데이터셋을 필터링하고 재조정하는 자동 파이프라인을 구축했다. 이 파이프라인은 외부 메타데이터 대신 데이터 유사성이 사용되고 수동 주석이 필요하지 않은 NLP에서 사용되는 파이프라인에서 영감을 받았다. 이미지를 다룰 때 가장 어려운 점은 개념의 균형을 재조정하고 몇 가지 주요 mode에서 overfitting을 피하는 것이다. 본 논문에서 naive한 클러스터링 접근 방식은 이 문제를 해결하는 데 합리적으로 잘 작동한다. 저자들은 접근 방식을 검증하기 위해 작지만 다양한 1억 4200만 개의 이미지 corpus를 수집했다.
마지막으로 저자들은 데이터에 대해 다양한 Vision Transformers (ViT) 아키텍처로 학습된 DINOv2라는 다양한 사전 학습된 모델을 제공한다. 저자들은 self-supervised 사전 학습만으로도 공개적으로 사용 가능한 weakly-supervised 모델과 경쟁할 수 있는 transfer 가능한 고정 feature을 학습하기에 좋은 후보라고 결론지었다.
Data Processing
선별된 여러 데이터셋의 이미지에 가까운 이미지를 선별되지 않은 대규모 데이터 풀에서 검색하여 LVD-142M 데이터셋을 모았다. 본 논문의 파이프라인은 메타데이터나 텍스트가 필요하지 않으며 아래 그림과 같이 이미지와 직접 작동한다.
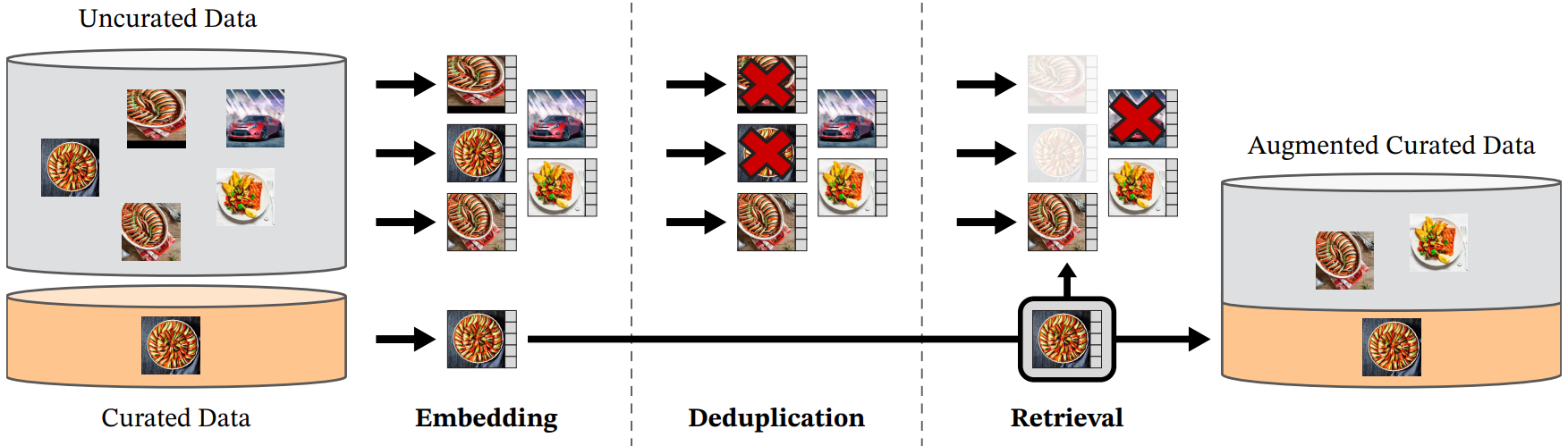
Data sources
선별된 데이터셋은 ImageNet-22k, ImageNet-1k의 train split, Google Landmarks 및 여러 세분화된 데이터셋를 포함한다. 선별되지 않은 데이터 원본의 경우 크롤링된 웹 이미지의 필터링되지 않은 원시 데이터셋을 수집한다. Repository의 각 웹 페이지에서 $\langle \textrm{img} \rangle$ 태그의 이미지 URL 링크를 추출한다. 안전하지 않거나 도메인에 의해 제한되는 URL을 삭제하고 다운로드한 이미지를 후처리한다 (PCA 해시 중복 제거, NSFW 필터링, 식별 가능한 얼굴 흐리게 처리). 그 결과 12억개의 고유 이미지가 생성되었다.
Deduplication
정리되지 않은 데이터에 SSCD의 복사 감지 파이프라인을 적용하고 중복에 가까운 이미지를 제거한다. 이는 중복성을 줄이고 이미지 간의 다양성을 높인다. 또한 이 작업에 사용된 모든 벤치마크의 test 또는 validation set에 포함된 거의 중복된 이미지를 제거한다.
Self-supervised image retrieval
선별된 소스 이미지에 가까운 선별되지 않은 데이터 원본에서 이미지를 검색하여 선별된 사전 학습 데이터셋을 구축한다. 이를 위해 먼저 ImageNet-22k에서 사전 학습된 self-supervised ViT-H/16 네트워크를 사용하여 이미지 임베딩을 계산하고 cosine similarity를 이미지 간의 거리 측정에 사용한다. 그런 다음 선별되지 않은 데이터의 k-mean clustering을 수행한다. 검색을 위한 쿼리 데이터셋이 충분히 크면 각 쿼리 이미지에 대해 $N$(일반적으로 4)개의 nearest neighbor를 검색한다. 쿼리 데이터셋이 작은 경우 각 쿼리 이미지에 해당하는 클러스터에서 $M$개의 이미지를 샘플링한다. 검색 결과를 직접 검사하여 $N$과 $M$을 조정한다.
Implementation Details
파이프라인의 중복 제거 및 검색 단계는 가장 가까운 임베딩의 batch 검색을 효율적으로 인덱싱하고 계산하기 위해 Faiss 에 의존한다. 전체 처리는 8개의 V100-32GB GPU가 장착된 20개 노드의 컴퓨팅 클러스터에 분산되며 LVD-142M 데이터셋을 생성하는 데 2일도 채 걸리지 않았다고 한다.
Discriminative Self-supervised Pre-training
SwAV를 중심으로 DINO와 iBOT loss의 조합으로 볼 수 있는 discriminative self-supervised 방법으로 feature를 학습한다. 또한 regularizer를 추가하여 feature와 짧은 고해상도 학습 단계를 확장한다.
Image-level objective
Teacher 네트워크와 student 네트워크에서 추출한 feature 간의 cross-entropy loss를 고려한다. 두 feature 모두 동일한 이미지의 다른 crop에서 얻은 ViT의 클래스 토큰에서 나온다. Student의 파라미터를 학습하고 이전 iteration의 exponential moving average (EMA)로 teacher를 구축한다.
Patch-level objective
Student에게 제공된 일부 입력 패치는 임의로 마스킹하지만 teacher의 경우 마스킹하지 않는다. 그런 다음 각 마스킹된 패치에서 두 네트워크의 패치 feature 사이의 cross-entropy loss를 추가한다. 이 loss는 이미지 레벨 loss와 결합된다.
Untying head weights between both objectives
저자들은 두 목적 함수와 관련된 가중치를 묶으면 모델이 패치 레벨에서 underfit되고 이미지 레벨에서 overfit되는 것을 관찰하였다. 이러한 가중치를 풀면 이 문제가 해결되고 두 레벨 모두에서 성능이 향상된다.
Sinkhorn-Knopp centering
Weighted Ensemble Self-Supervised Learning 논문은 SwAV의 Sinkhorn-Knopp(SK) batch normalization로 DINO와 iBot의 Teacher softmax-centering 단계를 대체할 것을 권장하였다. Sinkhorn-Knopp 알고리즘 단계를 3회 반복 실행한다. Student를 위해 softmax normalization을 적용한다.
KoLeo regularizer
KoLeo regularizer는 Kozachenko-Leonenko differential entropy estimator에서 파생되며 batch 내에서 feature의 균일한 범위를 권장한다. $n$개의 벡터들의 집합 $(x_1, \cdots, x_n)$이 주어지면
\[\begin{equation} \mathcal{L}_\textrm{koleo} = - \frac{1}{n} \sum_{i=1}^n \log (d_{n,i}) \\ d_{n,i} = \min_{j \ne i} \|x_i - x_j \| \end{equation}\]로 정의된다. 또한 이 regularizer를 계산하기 전에 feature에 $l_2$-normalization을 적용한다.
Adapting the resolution
이미지 해상도를 높이는 것은 작은 물체가 낮은 해상도에서 사라지는 segmentation 또는 detection과 같은 픽셀 레벨 downstream task의 핵심이다. 그러나 고해상도로 학습시키는 것은 시간과 메모리를 많이 요구하기 때문에 사전 학습이 끝나는 짧은 시간 동안 이미지의 해상도를 518$\times$518로 높인다.
Efficient implementation
저자들은 더 큰 규모의 학습 모델에 대한 몇 가지 개선 사항을 고려하였다. A100 GPU에서 모델을 학습하며, 동일한 하드웨어로 iBOT 구현과 비교하여 DINOv2 코드는 메모리의 1/3만 사용하여 약 2배 빠르게 실행된다.
Fast and memory-efficient attention
저자들은 self-attention layer에서 메모리 사용량과 속도를 개선하기 위해 자체 버전의 FlashAttention을 구현했다. 본 논문의 버전은 고려된 모든 케이스에서 원본과 동등하거나 더 우수하며 더 많은 사용 사례와 하드웨어를 포함한다. GPU 하드웨어 특성으로 인해 head당 임베딩 차원이 64의 배수일 때 효율성이 가장 좋고 전체 임베딩 차원이 256의 배수일 때 행렬 연산이 훨씬 더 좋다. 결과적으로 ViT-g 아키텍처는 Scaling vision transformers 논문이 제안한 아키텍처와 약간 다르다. 컴퓨팅 효율성을 극대화하기 위해 16개 헤드(88 dim/head)가 있는 1408 임베딩 차원이 아닌 24개 헤드(64 dim/head)가 있는 1536 임베딩 차원을 사용한다. 최종 정확도에서 큰 차이를 보이지 않았으며 ViT-g backbone은 11억 개의 파라미터를 계산한다.
Nested tensors in self-attention
또한 본 논문의 버전은 global crop과 local crop을 동일한 forward pass에서 실행할 수 있으므로 이전 구현에서와 같이 별도의 forward 및 backward pass를 사용하는 것과 비교하여 상당한 컴퓨팅 효율성 향상을 가져온다.
Efficient stochastic depth
저자들은 결과를 마스킹하는 대신 drop된 residual의 계산을 건너뛰는 stochastic depth의 개선된 버전을 구현하였다. 이렇게 하면 특정 fused kernel 덕분에 drop rate와 거의 같은 비율로 메모리와 컴퓨팅이 절약된다. Drop rate가 높으면 (본 논문에서는 $d = 0.4$) 컴퓨팅 효율성과 메모리 사용량을 크게 개선할 수 있다. 구현은 batch 차원에서 $B$개의 샘플을 랜덤하게 섞고 블록의 계산을 위해 첫 번째 $(1 − d) \times B$개의 샘플을 슬라이싱하는 것으로 구성된다.
Fully-Sharded Data Parallel (FSDP)
AdamW optimizer로 목적 함수를 최소화하려면 float32 정밀도의 4개 모델 복제본(student, teacher, optimizer의 momentum 2개)이 필요하다. 이는 ViT-g와 같은 10억 파라미터 모델의 경우 16GB 메모리에 해당한다. 저자들은 GPU당 이 메모리 공간을 줄이기 위해 모델 복제본을 여러 GPU로 분할했다. 즉, FSDP의 PyTorch 구현을 사용하여 여러 GPU에서 16GB를 샤딩했다. 결과적으로 모델 크기는 단일 GPU의 메모리가 아니라 컴퓨팅 노드 전체의 총 GPU 메모리 합계로 제한된다.
FSDP의 Pytorch 구현은 GPU 간 통신 비용을 절감하는 두 번째 이점을 제공한다. 가중치 샤드는 optimizer에서 요구하는 대로 float32 정밀도로 저장되지만 가중치 브로드캐스팅 및 기울기 감소는 backbone에 대해 float16 정밀도로 수행된다. 이는 다른 self-supervised 사전 학습 방법에서 사용되는 DistributedDataParallel (DDP)에서 사용되는 float32 기울기 all-reduce 연산에 비해 통신 비용이 약 50% 감소한다. 결과적으로 학습 절차는 GPU 노드 수를 확장할 때 float16 자동 캐스트를 사용하는 DDP보다 더 효율적으로 확장된다. 전반적으로 Pytorch-FSDP 혼합 정밀도는 거의 모든 경우에서 자동 캐스팅을 사용하는 DDP보다 우수하다.
Model distillation
학습 루프에 대한 대부분의 기술적 개선 사항은 대량의 데이터에 대한 대형 모델의 학습 개선을 목표로 한다. 더 작은 모델의 경우 처음부터 학습하는 대신 가장 큰 모델인 ViT-g에서 distill한다. Knowledge distillation은 주어진 입력 집합에 대해 두 출력 사이의 거리를 최소화하여 더 작은 모델로 큰 모델의 출력을 재생산하는 것을 목표로 한다. 목적 함수는 teacher 네트워크에서 student 네트워크로의 distillation 형태이므로 몇 가지 예외를 제외하고는 동일한 학습 루프를 활용한다. 더 큰 모델을 고정된 teacher로 사용하고 student의 여분의 EMA를 유지한다. 최종 모델에서 마스킹 및 stochastic depth를 제거하고 두 개의 global crop에 iBOT loss를 적용한다. 저자들은 ablation에서 이 접근 방식이 ViT-L의 경우에도 처음부터 학습하는 것보다 더 나은 성능을 달성한다는 것을 관찰했다. Distillation 방법은 RoB 논문이 설명한 것과 거의 비슷하지만, distillation에 대한 loss 항을 수정하지 않고 student의 EMA를 평가하지 않는다.
Ablation Studies
1. Improved Training Recipe
다음은 iBOT와 DINOv2의 학습 차이점에 대한 ablation 결과이다.
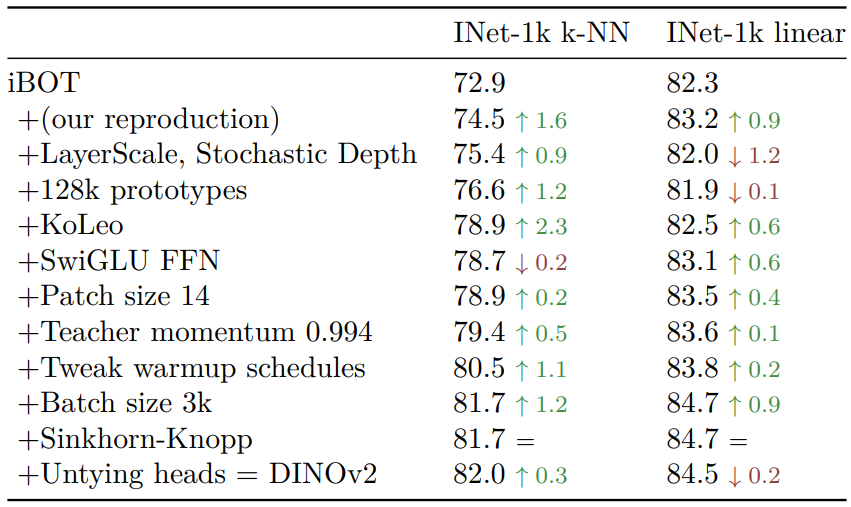
대부분의 경우 각 구성 요소가 k-NN과 linear probing에서 성능을 향상시킨다. LayerScale과 Stochastic Depth만이 linear probing에서 성능 저하를 일으키지만 경험상 학습 안정성을 크게 향상시킨다고 한다.
2. Pretraining Data Source
다음은 사전 학습 데이터의 출처에 대한 ablation 결과이다.
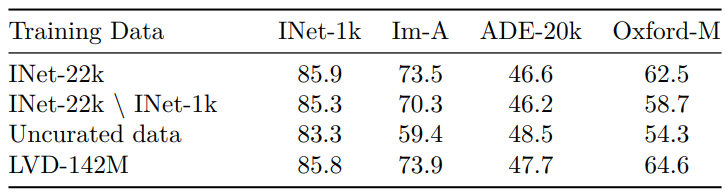
가장 눈에 띄는 점은 선별된 이미지 셋에 대한 학습이 선별되지 않은 데이터에 대한 학습보다 대부분의 벤치마크에서 더 잘 작동한다는 것이다. 이는 self-supervised 사전 학습의 경우에도 데이터 선별의 이점을 확인시켜준다. ImageNet-22k에서 학습된 모델과 비교할 때 LVD-142M에서 학습한 것이 ImageNet-1k를 제외한 모든 벤치마크에서 우수하다. 이는 보다 다양한 이미지 셋에 대한 학습이 이 데이터셋에서 다루지 않는 도메인의 feature 품질을 향상시킨다는 것을 확인시켜준다.
3. Model Size and Data
다음은 모델 크기로 데이터 스케일링의 중요성을 정량화한 그래프이다.

모델 크기가 커짐에 따라 LVD-142M에 대한 학습이 ImageNet-22k에 대한 학습보다 더 유리해진다.
4. Loss Components
다음은 (a) KoLeo loss 항의 영향과 (b) iBOT Masked Image Modeling (MIM) loss 항의 영향을 나타낸 표이다.
KoLeo loss를 사용하면 인스턴스 검색 성능이 8% 이상 향상되어 출력 space에서 feature을 퍼지게 하는 데 도움이 된다는 것을 확인할 수 있다. 동시에 다른 메트릭은 이러한 정규화로 인해 어려움을 겪지 않는다. iBOT MIM loss는 조밀한 예측 작업에 매우 중요하며 거의 3%의 성능 향상을 가져온다.
5. Impact of Knowledge Distillation
다음은 knowledge distillation의 영향력을 확인하기 위한 ablation 결과이다.
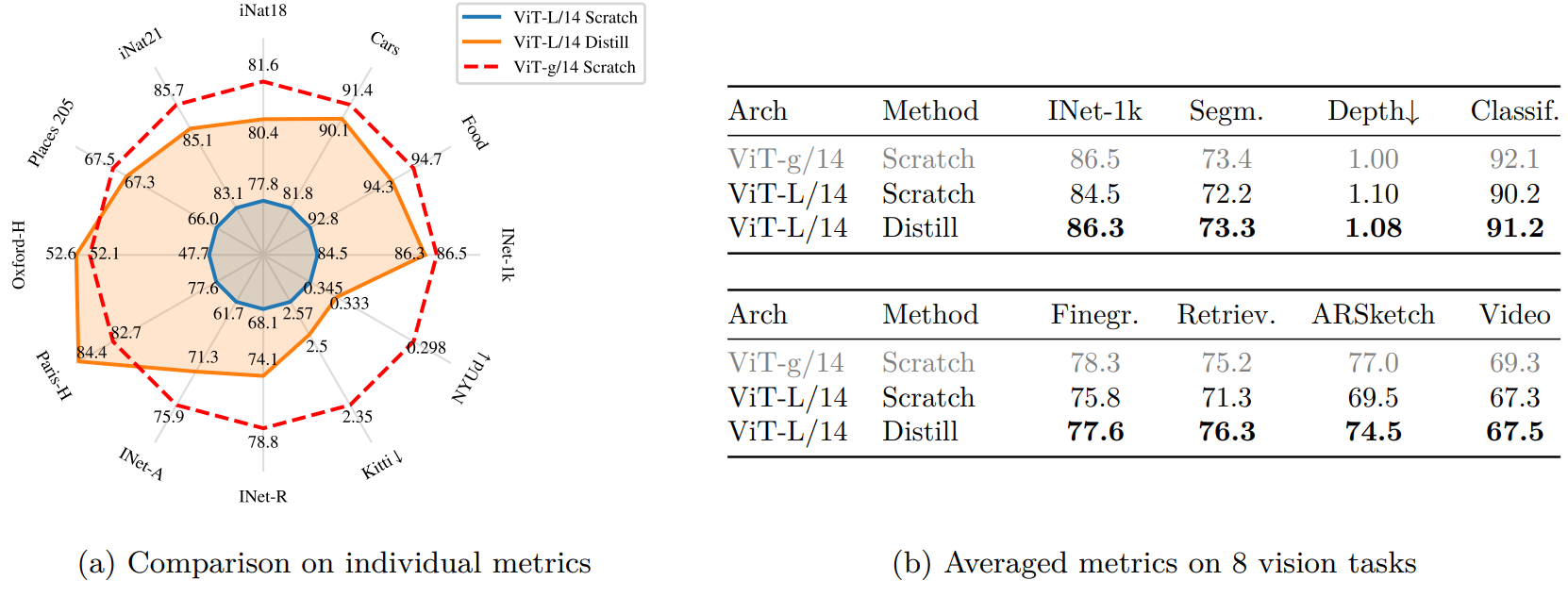
Distill된 모델은 12개 벤치마크 중 10개에서 처음부터 학습된 모델보다 성능이 우수하여 소규모 모델에 대한 사전 학습 접근 방식을 검증한다.
6. Impact of Resolution
다음은 다양한 해상도에서 평가된 ImageNet-1k와 ADE-20k의 linear probing 성능이다.
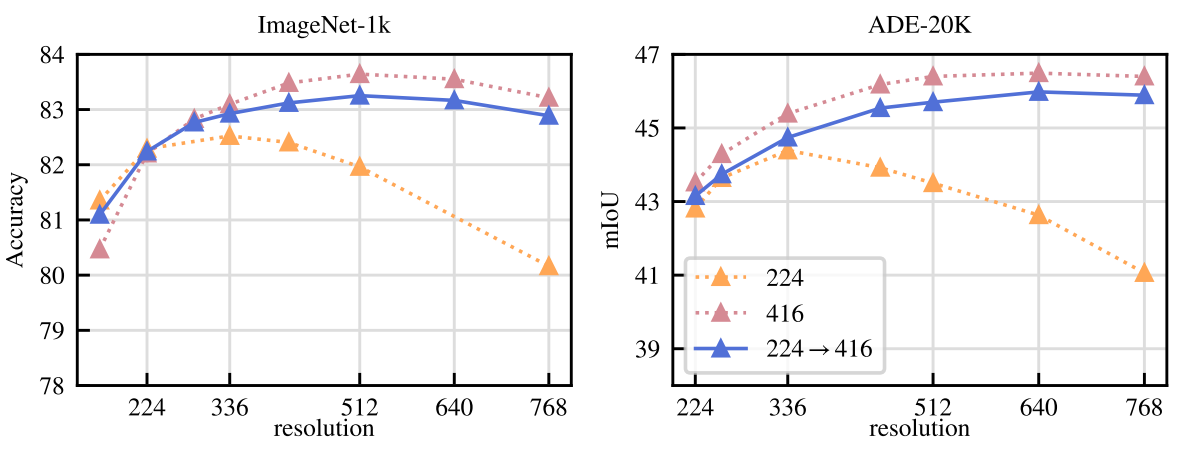
고해상도 이미지에서 학습된 모델은 모든 해상도에서 가장 잘 수행되지만 비용이 많이 든다. 416에서 학습하는 것은 224에서 학습하는 것보다 약 3배 더 계산 집약적이다. 반면에 고해상도에서 학습시키는 것은 1만 iteration에 불과하다. 학습이 끝날 때 거의 비슷하고 컴퓨팅의 일부만 필요하다. 결과적으로 처음부터 고해상도로 학습하는 대신 학습 마지막에 이 단계를 포함한다.
Results
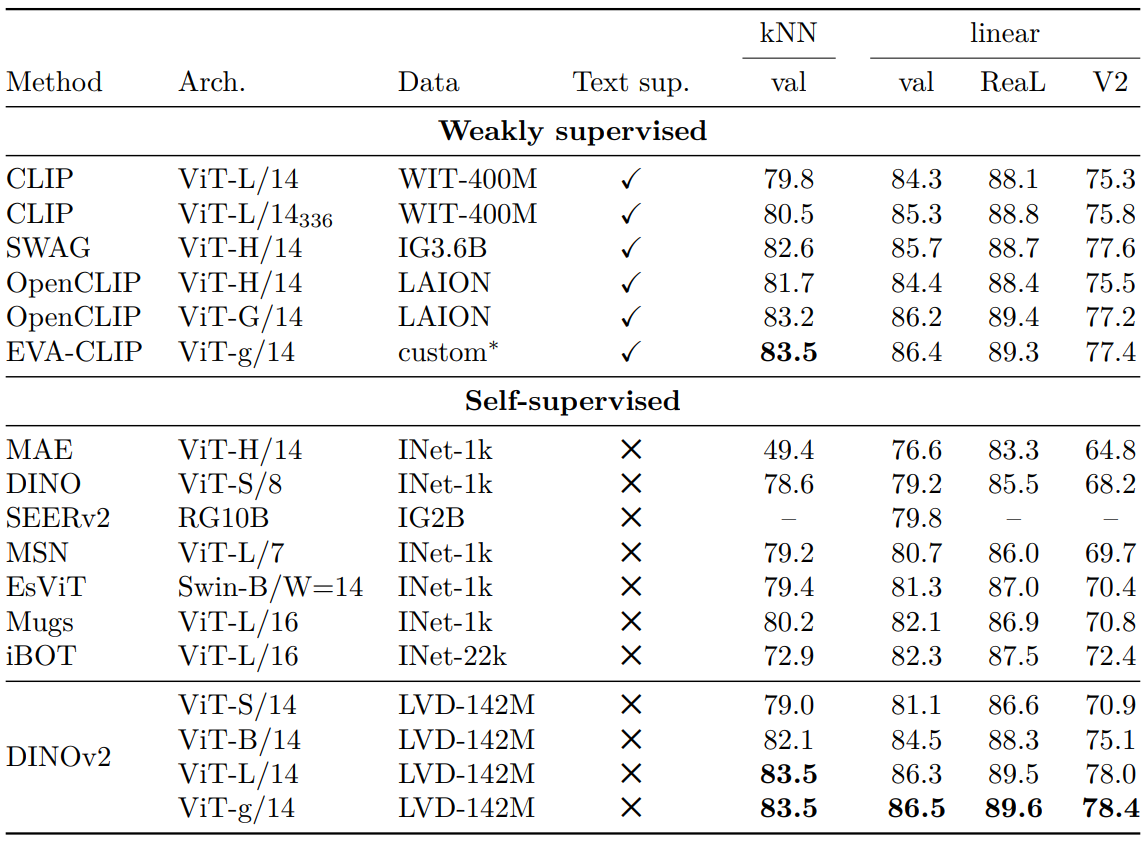
1. ImageNet Classification
다음은 ImageNet-1k의 고정된 사전 학습된 feature에 대한 linear evaluation 결과이다. (244$\times$244)
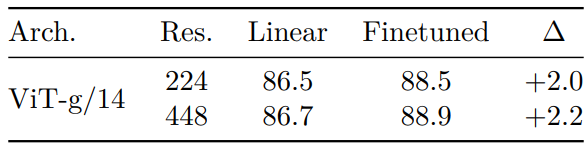
다음은 ImageNet-1k에서 supervised finetuning한 결과이다.
다음은 linear probing으로 도메인 일반화를 평가한 결과이다.
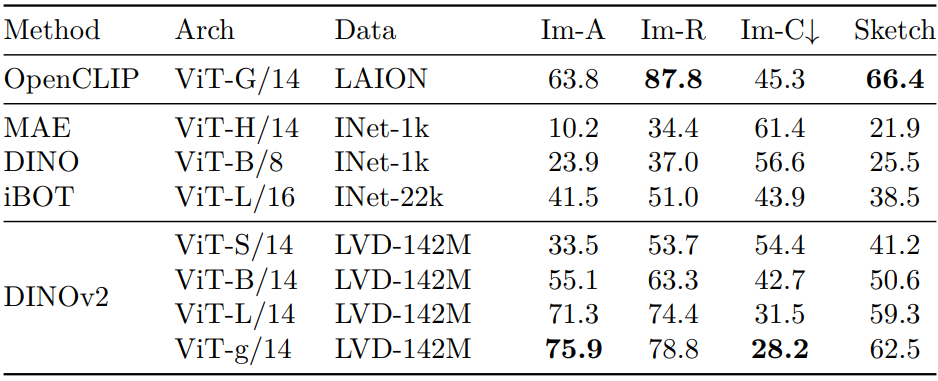
2. Additional Image and Video classification Benchmarks
다음은 다른 이미지 및 동영상 classification에 대한 linear evaluation 결과이다.
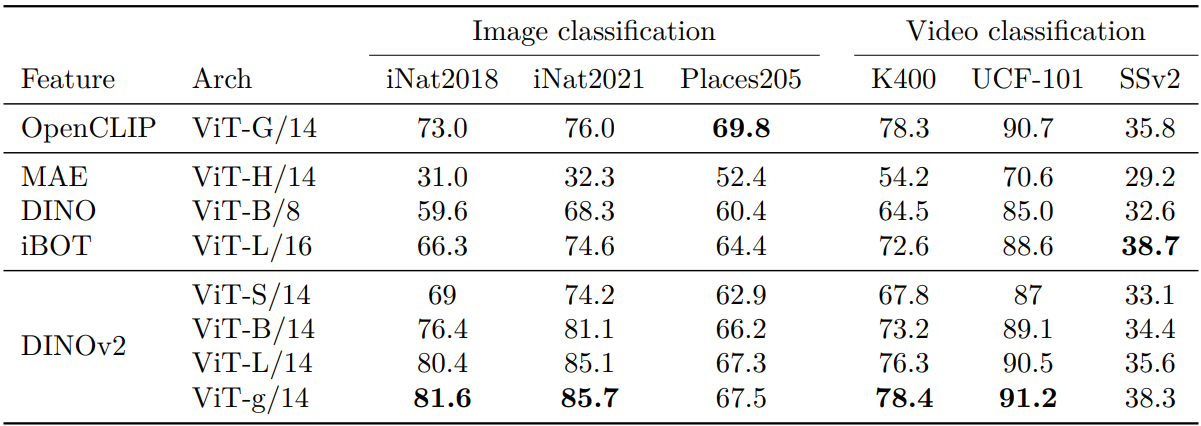
다음은 세분화된 벤치마크에 대한 linear evaluation 결과이다.
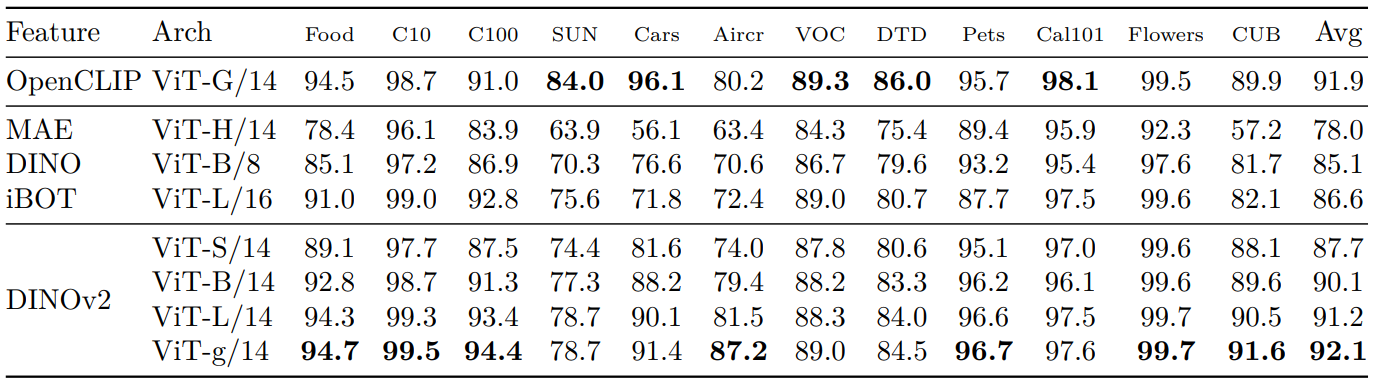
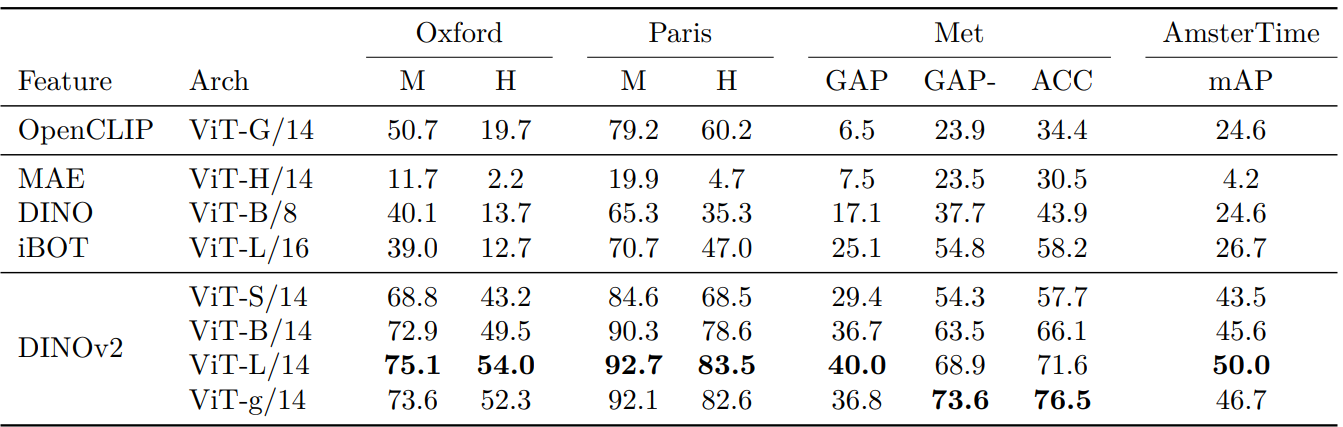
3. Instance Recognition
다음은 instance-level recognition을 mean average precision (mAP)로 평가한 결과이다.
4. Dense Recognition Tasks
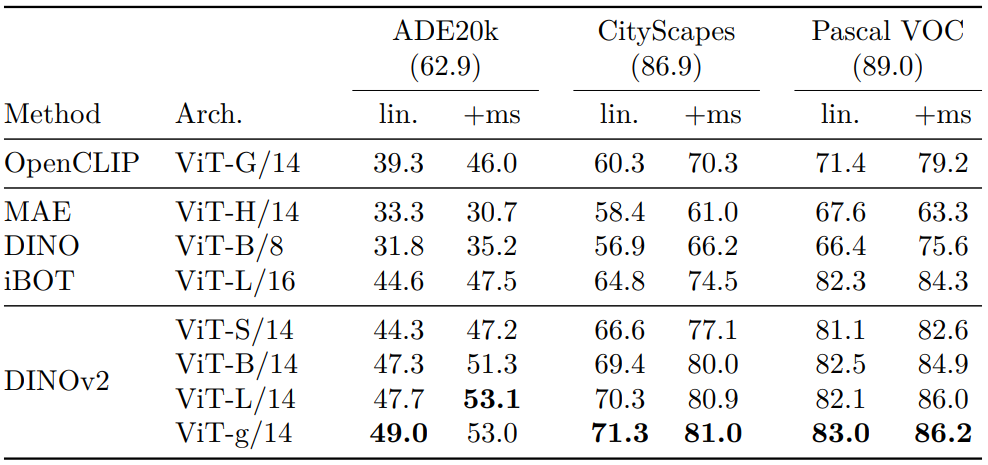
다음은 segmentation segmentation을 mIoU로 평가한 결과이다. “lin.”은 linear classifier를 사용한 것이고, “+ms”는 multiscale로 부스팅한 것이다. 절대적인 state-of-the-art 성능은 각 데이터셋 이름 아래에 표시되어 있다.
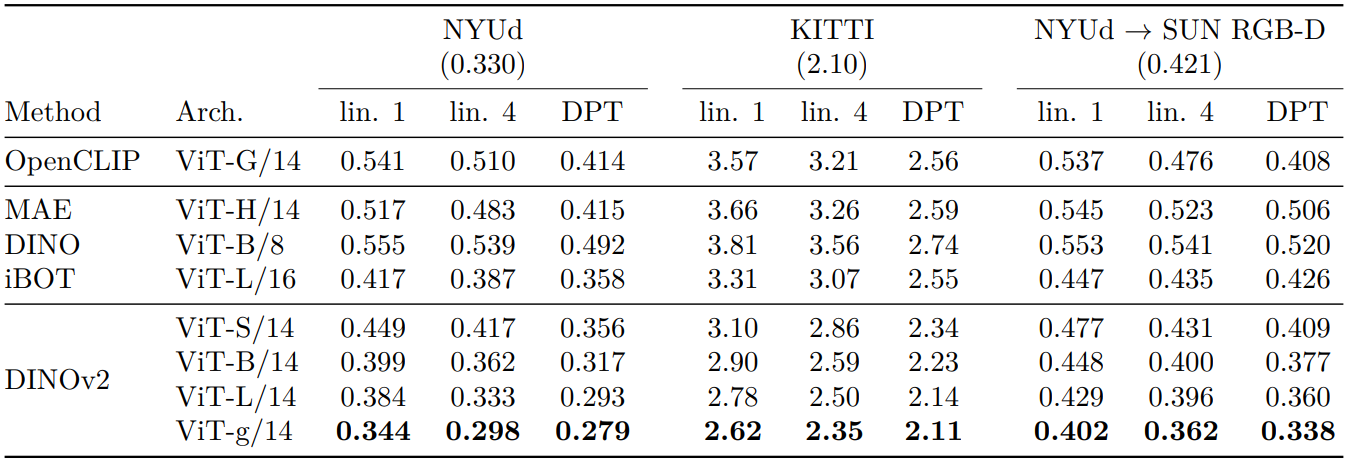
다음은 depth estimation을 RMSE로 평가한 결과이다. “lin. 1”과 “lin. 4”는 각각 1개와 4개의 transformer layer 위에 linear classifier를 학습한 것이고, “DPT”는 DPT decoder를 사용한 것이다.
5. Qualitative Results
다음은 linear classifier로 segmentation과 depth estimation을 수행한 예시들이다.

다음은 out-of-distribution에 대한 일반화를 보여주는 예시들이다.

다음은 첫번째 PCA 성분을 시각화한 것이다.