[논문리뷰] Emergent Correspondence from Image Diffusion
NeurIPS 2023. [Paper] [Page] [Github]
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, Bharath Hariharan
Cornell University
6 Jun 2023

Introduction
본 논문에서는 사전 학습된 diffusion model을 사용하여 실제 이미지에서 correspondence를 추출하는 간단한 방법을 제시하였다. Diffusion model은 핵심에 noise가 포함된 이미지를 입력으로 받아 깨끗한 이미지를 출력하는 U-Net을 가지고 있다. 따라서 입력 이미지에서 correspondence 추출에 사용할 수 있는 feature를 이미 추출하고 있다.
그러나 U-Net은 denoising을 위해 학습되었기 때문에 noise가 포함된 이미지로 학습되었다는 한계가 있다. 이러한 문제를 해결하기 위한 본 논문에서는 입력 이미지를 U-Net에 입력하기 전에 noise를 추가하여 feature map을 추출한다. 이러한 feature map을 DIffusion FeaTure (DIFT)라고 부른다. DIFT는 cosine distance를 이용한 nearest neighbor 검색을 통해 두 이미지에서 일치하는 픽셀 위치를 찾는 데 사용할 수 있다. 결과적으로 얻어진 correspondence는 다양한 카테고리와 이미지 유형에 걸쳐서도 놀라울 정도로 robust하고 정확하다.
Method
1. Problem Setup
두 이미지 $I_1$, $I_2$와 이미지 $I_1$의 픽셀 위치 $p_1$이 주어졌을 때, 이미지 $I_2$에서 대응되는 픽셀 위치 $p_2$를 찾는 것이 목표이다.
픽셀 correspondence를 얻는 가장 간단한 방법은 먼저 두 이미지에서 dense한 이미지 feature를 추출한 다음 이를 매칭하는 것이다. 구체적으로, 이미지 $I_i$에 대한 feature map $F_i$가 주어졌을 때, bilinear interpolation을 통해 픽셀 위치 $p$에 대한 feature 벡터 $F_i (p)$를 추출할 수 있다. 그러면 이미지 $I_1$의 픽셀 $p_1$에 대해 이미지 $I_2$에서 대응하는 픽셀을 다음과 같이 얻을 수 있다.
\[\begin{equation} p_2 = \underset{p}{\arg \min} d (F_1 (p_1), F_2 (p)) \end{equation}\]$d$는 distance metric으로, 본 논문에서는 cosine distance를 사용하였다.
2. Diffusion Features (DIFT)

생성된 이미지의 경우, reverse process 전체에 걸쳐 네트워크의 완전한 내부 state에 접근할 수 있다. Stable Diffusion에서 생성된 이미지가 주어졌을 때, reverse process 중 특정 시점 $t$에서 중간 layer의 feature map을 추출하고, 이를 이용하여 서로 다른 두 생성 이미지 간의 correspondence를 설정할 수 있다. 위 그림 2에서 볼 수 있듯이, 이 간단한 방법을 통해 생성된 이미지가 서로 다른 카테고리나 도메인에 속하더라도 정확한 correspondence를 찾을 수 있다.
실제 이미지에 대해 이 접근 방식을 재현하는 것은 어려운데, 그 이유는 실제 이미지 자체가 U-Net의 학습 분포에 속하지 않고, 이 이미지를 생성하는 동안 생성되었을 noise가 포함된 중간 이미지에 접근할 수 없기 때문이다. 저자들은 forward process를 이용한 간단한 근사법이 충분히 효과적이라는 것을 발견했다. 구체적으로, 먼저 실제 이미지에 timestep $t$의 noise를 추가하여 $x_t$ 분포로 이동시킨 다음, 이를 $t$와 함께 네트워크에 입력하여 중간 layer의 activation들을 DIFT로 추출한다. 이 방법은 실제 이미지에 대해 놀라울 정도로 좋은 correspondence를 보여준다.
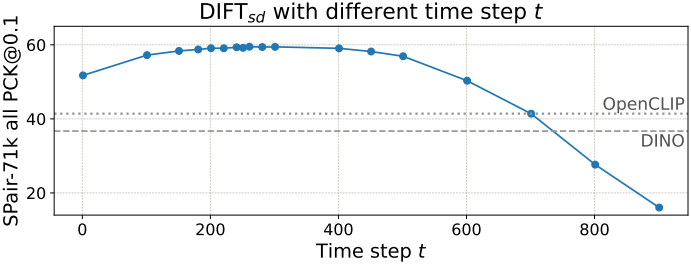
중요한 고려 사항은 timestep $t$와 feature를 추출할 layer의 선택이다. 직관적으로, $t$가 크고 초반 layer일수록 더 semantic을 잘 인식하는 feature를 추출하는 경향이 있는 반면, $t$가 작고 나중 layer일수록 디테일에 더 집중하는 경향이 있다. 최적의 $t$와 layer 선택은 task에 따라 달라지는데, 각 task는 semantic과 디테일 간의 trade-off가 다를 수 있기 때문이다. 따라서 각 task에 대한 이 두 hyperparameter를 결정하기 위해 2D grid search를 사용한다.
마지막으로, 입력 이미지에 추가된 랜덤 noise가 존재하는 상황에서 표현의 안정성을 향상시키기 위해, 서로 다른 noise 샘플을 포함하는 여러 $x_t$에서 feature를 추출하고, 이를 평균하여 최종 표현을 생성한다.
Experiments
평가 지표로는 PCK(percentage of correct keypoints)를 사용한다. PCK는 $\alpha \in [0, 1]$에 대하여 예측된 keypoint가 GT keypoint에서 $\alpha \cdot \max (h, w)$ 내에 있는 비율을 백분율로 나타낸 것이다. $h$와 $w$는 이미지(\(\alpha_\textrm{img}\))나 bounding box(\(\alpha_\textrm{bbox}\))의 높이 및 너비이다.
1. Benchmark Evaluation
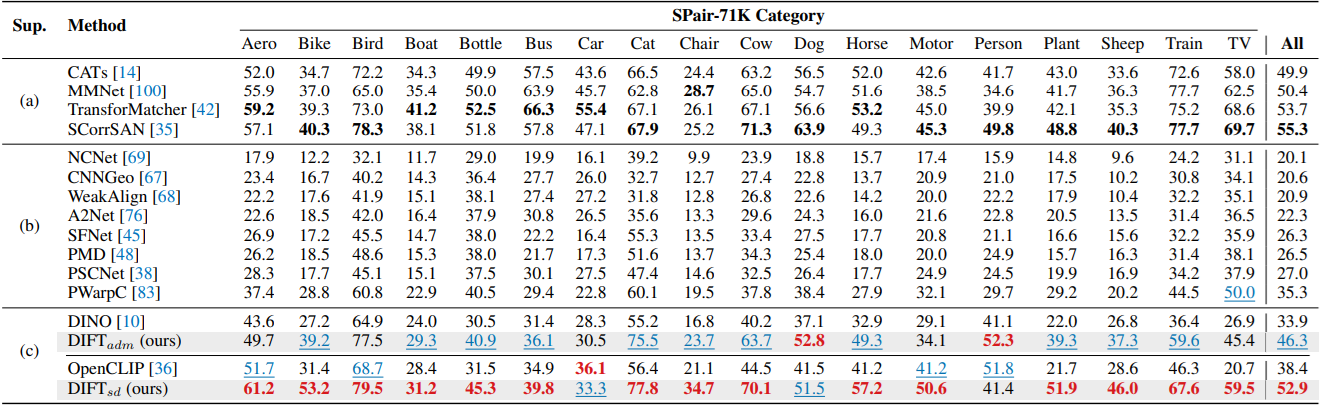
다음은 SPair-71k에서 PCK(\(\alpha_\textrm{bbox} = 0.1\))를 카테고리별로 비교한 결과이다.

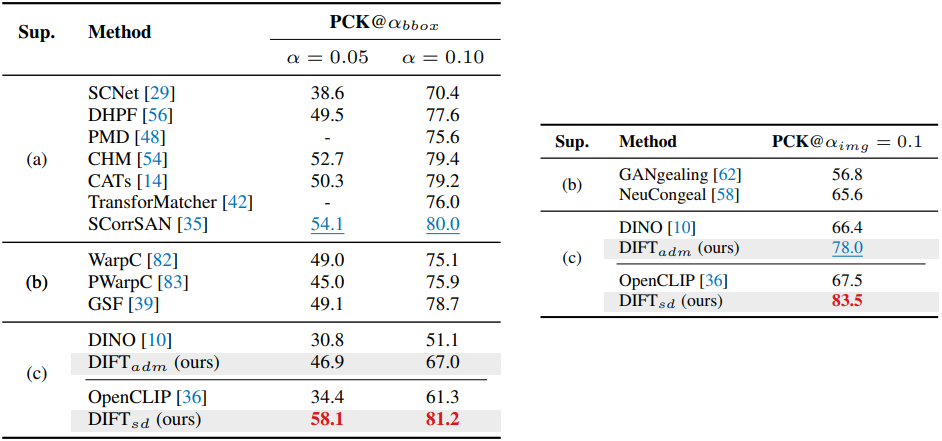
다음은 (왼쪽) PF-WILLOW와 (오른쪽) CUB에서 PCK를 비교한 결과이다.
다음은 다양한 feature로 예측한 semantic correspondence를 시각화한 것이다.

다음은 DIFTsd로 SPair-71k test set에서 가장 가까운 5개의 패치를 검색한 결과이다.

다음은 timestep $t$에 따른 PCK를 비교한 그래프이다. (SPair-71k)
다음은 소스 이미지의 편집한 부분을 전파한 결과이다.

2. Other Correspondence Tasks
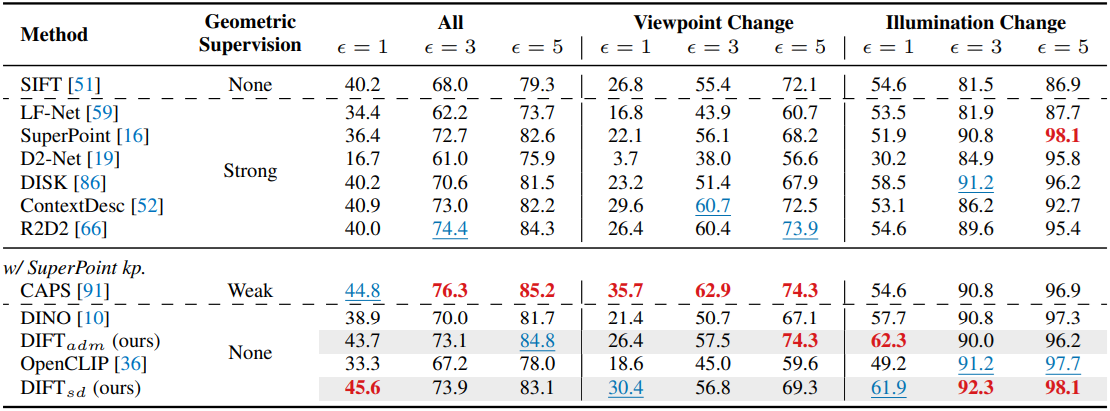
다음은 homography 추정 결과를 비교한 것이다.

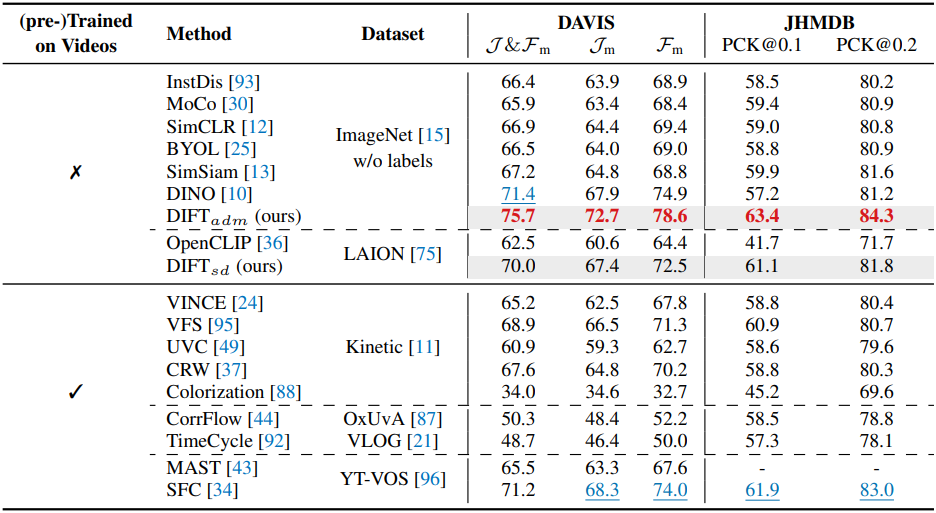
다음은 DAVIS-2017에서의 video label propagation 결과를 비교한 것이다.