[논문리뷰] DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
CVPR 2022. [Paper] [Github]
Gwanghyun Kim, Taesung Kwon, Jong Chul Ye
KAIST
6 Oct 2021

Introduction
Contrastive Language-Image Pretraining (CLIP)과 결합된 GAN inversion 방법이 텍스트 프롬프트에 따라 zero-shot 이미지 조작 능력으로 인해 인기를 얻고 있다. 그럼에도 불구하고 다양한 유형의 이미지에 대한 실제 적용은 제한된 GAN inversion 성능으로 인해 여전히 까다롭다.
특히 이미지를 성공적으로 조작하려면 입력 콘텐츠를 의도치 않게 변경하지 않고 이미지 속성을 타겟 속성으로 변환해야 한다. 안타깝게도 현재의 SOTA 인코더 기반 GAN inversion 접근 방식은 종종 새로운 포즈, 뷰, 디테일로 이미지를 재구성하지 못한다. 예를 들어, e4e와 pSp 인코더가 있는 ReStyle은 학습 과정에서 손을 얼굴에 대고 있는 이미지를 본 적이 거의 없었기 때문에 이를 재구성하지 못하여 의도하지 않은 변화를 유발한다. 이 문제는 LSUNChurch와 ImageNet 데이터셋과 같이 분산이 높은 데이터셋의 이미지의 경우 더욱 악화된다.
최근에는 DDPM과 score 기반 생성 모델과 같은 diffusion model이 이미지 생성 task에서 큰 성공을 거두었다. Diffusion model은 VAE, flow model, autoregressive model, GAN에 비해 훨씬 더 높은 품질의 이미지 합성 능력을 보여주었다. 또한 DDIM은 샘플링 절차를 더욱 가속화하고 거의 완벽한 반전(inversion)을 가능하게 한다.
이에 영감을 받아 본 논문은 diffusion model에 의한 CLIP 기반의 강력한 이미지 조작 방법인 DiffusionCLIP을 제안하였다. 여기서, 입력 이미지는 먼저 forward diffusion을 통해 latent noise로 변환된다. DDIM의 경우 reverse diffusion에 대한 score function이 forward diffusion의 score function과 동일하게 유지되면 reverse diffusion을 사용하여 latent noise를 원본 이미지로 거의 완벽하게 반전시킬 수 있다. 따라서 DiffusionCLIP의 핵심 아이디어는 텍스트 프롬프트를 기반으로 생성된 이미지의 속성을 제어하는 CLIP loss를 사용하여 reverse process에서 score function을 fine-tuning하는 것이다.
따라서 DiffusionCLIP은 학습된 도메인과 처음 보는 도메인 모두에서 이미지 조작을 성공적으로 수행할 수 있다. 처음 보는 도메인의 이미지를 처음 보는 다른 도메인으로 변환하거나 스트로크를 통해 처음 보는 도메인에 이미지를 생성할 수도 있다. 또한, 여러 개의 fine-tuning 모델에서 예측된 noise를 간단히 결합함으로써 단 한 번의 샘플링 프로세스를 통해 여러 속성을 동시에 변경할 수 있다. 또한, DiffsuionCLIP은 나쁜 재구성으로 인해 GAN inversion으로 거의 탐색되지 않은 매우 다양한 ImageNet 데이터셋의 이미지를 조작하여 일반적인 애플리케이션을 향해 한 단계 더 나아갔다.
또한, 저자들은 고품질과 빠른 이미지 조작으로 이어지는 최적의 샘플링 조건을 찾기 위한 체계적인 접근 방식을 제안하였다. DiffsuionCLIP은 강력하고 정확한 이미지 조작을 제공하여 SOTA baseline을 능가할 수 있다.
DiffusionCLIP
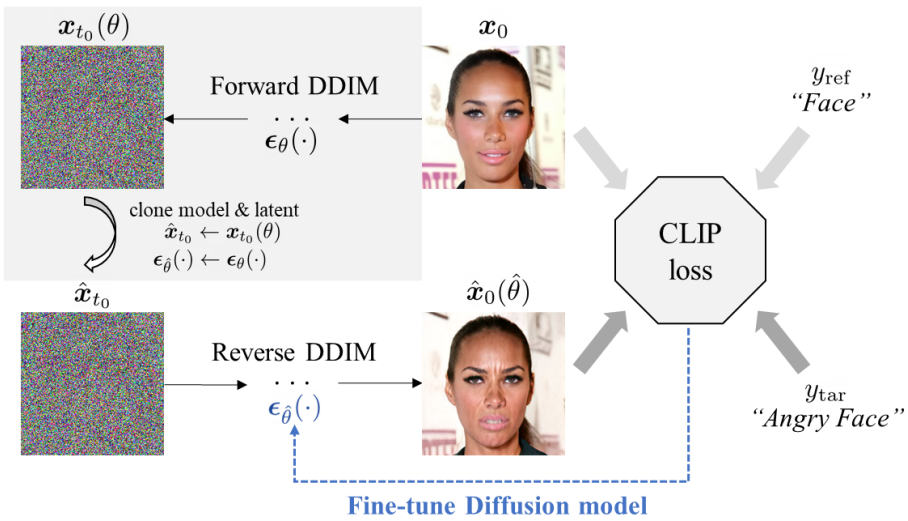
이미지 조작을 위해 제안된 DiffusionCLIP의 전체 개요는 위 그림에 나와 있다. 여기서 입력 이미지 $x_0$는 먼저 사전 학습된 diffusion model $\epsilon_\theta$를 사용하여 latent $x_{t_0} (\theta)$로 변환된다. 그런 다음 CLIP loss에 따라 역방향 경로의 diffusion model이 fine-tuning되어 타겟 텍스트 $y_\textrm{tar}$에 맞는 샘플을 생성한다. 결정론적 forward process는 DDIM을 기반으로 한다. 처음 보는 도메인 간 변환의 경우에도 forward DDPM process를 통해 latent 생성이 수행된다.
1. DiffusionCLIP Fine-tuning
Fine-tuning 측면에서 latent 또는 diffusion model 자체를 수정할 수 있다. 저자들은 직접 모델을 fine-tuning하는 것이 더 효과적이라는 것을 발견한다. 특히 diffusion model $\epsilon_\theta$를 fine-tuning하기 위해 directional CLIP loss \(\mathcal{L}_\textrm{direction}\)과 identity loss \(\mathcal{L}_\textrm{ID}\)로 구성된 다음 목적 함수를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{direction} (\hat{x}_0 (\hat{\theta}), y_\textrm{tar}; x_0, y_\textrm{ref}) + \mathcal{L}_\textrm{id} (\hat{x}_0 (\hat{\theta}), x_0) \end{equation}\]여기서 $x_0$는 원본 이미지, \(\hat{x}_0 (\hat{\theta})\)는 최적화된 파라미터 $\hat{\theta}$를 사용하여 latent $x_{t_0}$에서 생성된 이미지, $y_\textrm{ref}$는 레퍼런스 텍스트, $y_\textrm{tar}$는 이미지 조작을 위해 제공된 타겟 텍스트이다.
여기서 CLIP loss는 최적화를 supervise하는 핵심 구성 요소이다. 위에서 설명한 두 가지 유형의 CLIP loss 중에서 directional CLIP loss를 guidance로 사용한다. 텍스트 프롬프트의 경우 directional CLIP loss에는 학습 중에 레퍼런스 텍스트 $y_\textrm{ref}$와 타겟 텍스트 $y_\textrm{tar}$가 필요하다. 예를 들어, 주어진 얼굴 이미지의 표정을 화난 표정으로 변경하는 경우 ‘얼굴’을 레퍼런스 텍스트로, ‘화난 얼굴’을 타겟 텍스트로 사용할 수 있다.
원치 않는 변경을 방지하고 객체의 identity를 보존하기 위해 identity loss \(\mathcal{L}_\textrm{id}\)가 사용된다. 일반적으로 $\ell_1$ loss를 identity loss로 사용하며, 사람의 얼굴 이미지 조작의 경우 얼굴 identity loss가 추가된다.
\[\begin{equation} \mathcal{L}_\textrm{id} (\hat{x}_0 (\hat{\theta}), x_0) = \lambda_\textrm{L1} \| x_0 - \hat{x}_0 \hat{\theta} \| + \lambda_\textrm{face} \mathcal{L}_\textrm{face} (\hat{x}_0 (\hat{\theta}), x_0) \end{equation}\]여기서 \(\mathcal{L}_\textrm{face}\)는 얼굴 identity loss이고, \(\lambda_\textrm{L1} \ge 0\)와 \(\lambda_\textrm{face} \ge 0\)는 각 loss에 대한 가중치 파라미터이다. Identity loss의 필요성은 제어의 유형에 따라 다르다. 일부 제어의 경우 픽셀 유사도와 사람의 identity (ex. 표정, 머리 색깔)의 보존이 중요한 반면 다른 제어에서는 모양과 색상 변경을 선호한다.
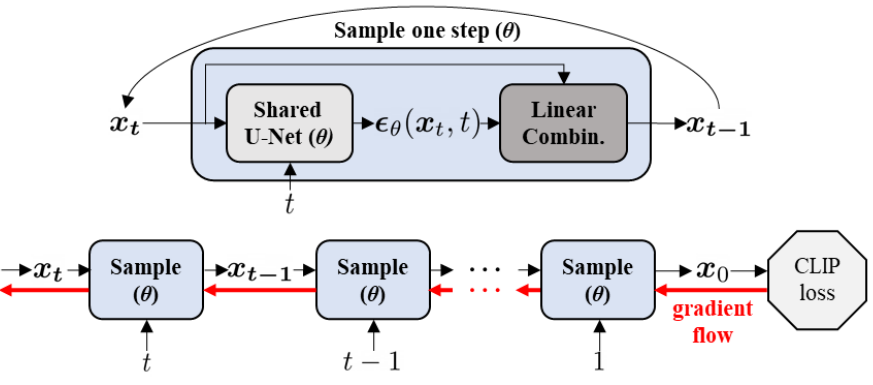
기존 diffusion model은 Transformer에서 사용된 sinusoidal 위치 임베딩을 사용하여 $t$의 정보를 삽입하는 모든 $t$에 대한 공유 U-Net 아키텍처를 채택한다. 이 아키텍처를 사용하면 DiffusionCLIP fine-tuning 중 기울기 흐름이 위 그림과 같으며 이는 RNN을 학습시키는 과정과 유사하다.

Diffusion model이 fine-tuning되면 사전 학습된 도메인의 모든 이미지를 위 그림과 같이 타겟 텍스트 \(y_\textrm{tar}\)에 해당하는 이미지로 조작할 수 있다.
2. Forward Diffusion and Generative Process
DDPM 샘플링 프로세스는 확률론적이므로 동일한 latent에서 생성된 샘플들이 매번 다르다. 샘플링 프로세스가 결정론적이라고 하더라도 DDPM의 forward process에서는 확률론적인 랜덤 Gaussian noise가 추가되므로 원본 이미지의 재구성이 보장되지 않는다. 이미지 조작을 목적으로 diffusion model의 이미지 합성 성능을 최대한 활용하려면 사전 학습된 diffusion model을 사용하여 forward 및 reverse 모두에서 결정론적 프로세스가 필요하다. 반면, 처음 보는 도메인 간 이미지 변환의 경우 DDPM에 의한 확률론적 샘플링이 도움이 되는 경우가 많다.
생성 프로세스로 결정론적 reverse DDIM process를 채택하고 forward process로 inversion의 ODE 근사를 채택한다. 특히 latent를 얻기 위한 결정론적 forward DDIM process는 다음과 같다.
\[\begin{equation} x_{t+1} = \sqrt{\alpha_{t+1}} f_\theta (x_t, t) + \sqrt{1 - \alpha_{t+1}} \epsilon_\theta (x_t, t) \end{equation}\]얻은 latent에서 샘플을 생성하는 결정론적 reverse DDIM process는 다음과 같다.
\[\begin{equation} x_{t-1} = \sqrt{\alpha_{t-1}} f_\theta (x_t, t) + \sqrt{1 - \alpha_{t-1}} \epsilon_\theta (x_t, t) \end{equation}\]DiffusionCLIP의 또 다른 중요한 부분은 빠른 샘플링 전략이다. 구체적으로, 마지막 timestep $T$까지 forward process를 수행하는 대신, $t_0 < T$까지 수행함으로써 forward process를 가속화할 수 있으며, $t_0$를 ‘return step’이라고 부른다. Forward process와 생성 프로세스에 대해 각각 \(S_\textrm{for}\)와 \(S_\textrm{gen}\)으로 표시되는 $[1, t_0]$ 사이의 더 적은 discretization step들을 사용하여 학습을 더욱 가속화할 수 있다. 저자들은 정성적 및 정량적 분석을 통해 $t_0$, \(S_\textrm{for}\), \(S_\textrm{gen}\)에 대한 최적의 hyperparameter 그룹을 찾았다. 예를 들어, $T$를 1000으로 설정하면 $t_0 \in [300, 600]$과 \((S_\textrm{for}, S_\textrm{gen}) = (40, 6)\)을 선택한다. \(S_\textrm{gen} = 6\)은 불완전한 재구성을 제공할 수 있지만 학습에 필요한 객체의 identity가 충분히 보존된다.
여러 latent가 미리 계산된 경우 latent를 재활용하여 다른 속성을 합성함으로써 fine-tuning 시간을 더욱 줄일 수 있다. 이렇게 설정하면 NVIDIA Quadro RTX 6000에서 1~7분 안에 fine-tuning이 완료된다.
3. Image Translation between Unseen Domains
DiffusionCLIP을 통해 fine-tuning된 모델을 활용하여 추가적인 새로운 이미지 조작을 수행할 수 있다.

먼저, 위 그림과 같이 처음 보는 도메인에서 다른 처음 보는 도메인으로 이미지 변환을 수행하고 처음 보는 도메인에서 스트로크 조건에 따른 이미지 합성을 수행할 수 있다. 이 어려운 문제를 해결하기 위한 핵심 아이디어는 상대적으로 수집하기 쉬운 데이터샛에 대해 학습된 diffusion model을 삽입하여 두 도메인 사이를 연결하는 것이다. 특히, ILVR과 SDEdit에서는 사전 학습된 diffusion model을 사용하여 처음 보는 도메인에서 학습된 이미지가 학습된 도메인의 이미지로 변환될 수 있음을 발견했다. 이 방법을 DiffsuionCLIP과 결합하면 이제 소스 및 타겟 도메인 모두에 대해 zero-shot으로 이미지를 변환할 수 있다.
구체적으로, 처음 보는 도메인의 소스 이미지 $x_0$는 도메인 관련 구성 요소가 흐려지지만 객체의 identity 또는 semantic이 보존되는 충분한 timestep $t_0$까지 forward DDPM process를 통해 교란된다. $t_0$는 일반적으로 500으로 설정된다. 다음으로 사전 학습된 도메인의 이미지 $x_0^\prime$는 reverse DDIM process를 사용하여 원래 사전 학습된 모델 $\epsilon_\theta$로 샘플링된다. 그런 다음, $x_0^\prime$은 fine-tuning된 모델 \(\epsilon_{\hat{\theta}}\)를 사용하여 처음 보는 도메인의 이미지 \(\hat{x}_0\)로 조작된다.
4. Noise Combination
Multi-attribute transfer

저자들은 샘플링 중에 여러 fine-tuning 모델 \(\{\epsilon_{\hat{\theta}_i}\}_{i=1}^M\)에서 예측된 noise가 결합되면 위 그림과 같이 단 한 번의 샘플링 프로세스를 통해 여러 속성이 변경될 수 있음을 발견했다. 따라서 여러 속성을 정의하는 타겟 텍스트로 새 모델을 fine-tuning할 필요 없이 여러 단일 속성 fine-tuning 모델을 다양한 조합으로 유연하게 혼합할 수 있다.
먼저 원래의 사전 학습된 diffusion model을 사용하여 이미지를 반전시키고 다음과 같은 샘플링 규칙에 따라 여러 diffusion model을 사용한다.
\[\begin{equation} x_{t-1} = \sqrt{\alpha_{t-1}} \sum_{i=1}^M \gamma_i (t) f_{\hat{\theta}_i} (x_t, t) + \sqrt{1 - \alpha_{t-1}} \sum_{i=1}^M \gamma_i (t) \epsilon_{\hat{\theta}_i} (x_t, t) \end{equation}\]여기서 \(\{\gamma_i (t)\}_{t=1}^T\)는 \(\sum_{i=1}^M \gamma_i (t) = 1\)을 만족하는 각 fine-tuning 모델 \(\epsilon_{\hat{\theta}_i}\)의 가중치 시퀀스로, 각 속성의 정도를 제어하는 데 사용할 수 있다. 이 샘플링 프로세스를 다음과 같이 조건부 분포의 결합 확률을 증가시키는 것으로 해석할 수 있다.
\[\begin{equation} \sum_{i=1}^M \gamma_i (t) \epsilon_{\hat{\theta}_i} (x_t, t) \propto - \nabla_{x_t} \log \prod_{i=1}^M p_{\hat{\theta}_i} (x_t \vert y_{\textrm{tar}, i})^{\gamma_i (t)} \end{equation}\]여기서 \(y_{\textrm{tar}, i}\)는 각 fine-tuning 모델 \(\epsilon_{\hat{\theta}_i}\)의 대상 텍스트이다.
기존 연구들에서는 사용자가 수작업으로 까다로운 task별 loss 디자인 또는 데이터셋 준비를 해야 하는 반면, DiffsuionCLIP은 그러한 노력 없이 자연스러운 방식으로 작업을 가능하게 한다.
Continuous transition
단일 속성을 조작하는 동안 변화 정도를 제어하기 위해 위의 noise 조합 방법을 적용할 수도 있다. 원본 사전 학습 모델 $\epsilon_\theta$와 fine-tuning 모델 \(\epsilon_{\hat{\theta}}\)의 noise를 변화 정도 $\gamma \in [0, 1]$에 따라 혼합함으로써 원본 이미지와 조작된 이미지 간의 보간을 원활하게 수행할 수 있다.
Experiments
- 데이터셋: CelebA-HQ, AFHQ-Dog, LSUN-Bedroom, LSUN-Church
- Fine-tuning 디테일
- optimizer: Adam
- learning rate: $4 \times 10^{-6}$
- $\lambda_\textrm{L1} = 0.3, \lambda_\textrm{ID} = 0.3$
1. Comparison and Evaluation
Reconstruction
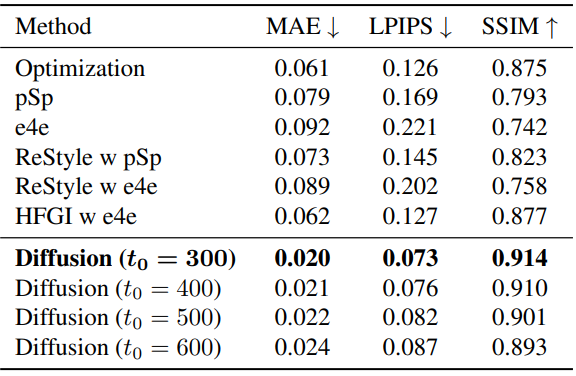
다음은 얼굴 이미지 재구성에 대하여 정량적으로 비교한 표이다.
Qualitative comparison
다음은 SOTA 텍스트 기반 이미지 조작 방법들과 비교한 결과이다.

User study
다음은 CelebA-HQ에서 실제 이미지 조작에 대한 user study 결과이다.

Quantitative evaluation
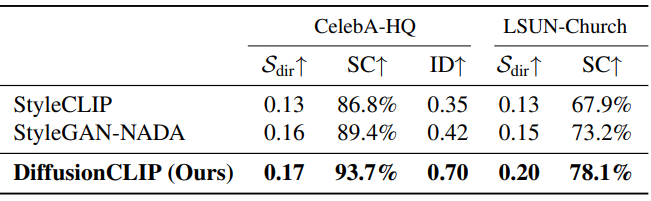
다음은 정량적 평가 결과이다.
2. More Manipulation Results on Other Datasets
다음은 DiffsuionCLIP을 사용한 실제 이미지에 대한 조작 결과이다.

3. Image Translation between Unseen Domains
다음은 처음 보는 도메인들 사이의 이미지 변환 결과이다.

4. Noise Combination
다음은 multi-attribute transfer 결과이다.

다음은 continuous transition 결과이다.
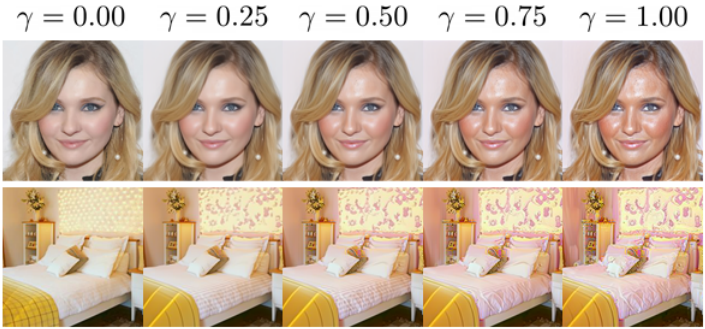
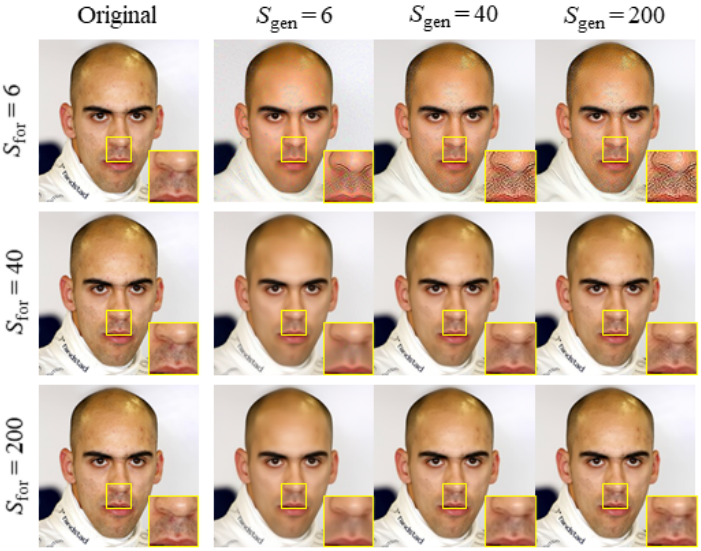
5. Dependency on Hyperparameters
다음은 $S_\textrm{for}$과 $S_\textrm{gen}$에 따른 재구성 결과를 비교한 것이다.
다음은 $t_0$에 따른 조작 결과를 비교한 것이다.
