[논문리뷰] DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
CVPR 2023. [Paper] [Page] [Github]
Zheng Ding, Xuaner Zhang, Zhihao Xia, Lars Jebe, Zhuowen Tu, Xiuming Zhang
UC San Diego | Adobe
13 Apr 2023

Introduction
사람의 아이덴티티(ID)와 고주파 얼굴 특성을 유지하면서 인물 사진의 조명, 표정, 머리 포즈 등을 사실적으로 변경하는 것은 컴퓨터 비전 및 그래픽 분야의 오랜 문제이다. 이 문제의 어려움은 근본적으로 제약이 없는 특성에서 비롯되며, 이전 연구들에서는 일반적으로 신경망이 서로 다른 ID의 대규모 데이터셋에서 학습되고 새로운 ID에서 테스트되는 zero-shot 학습으로 이 문제를 해결한다. 이러한 방법은 일반적인 얼굴 prior가 종종 테스트 ID의 고주파수 얼굴 특징을 캡처하지 못하고 동일한 사람의 여러 사진이 쉽게 사용할 수 있다는 사실을 무시한다.
본 논문에서는 조명, 표정, 머리 포즈와 같은 사람의 얼굴 모양을 설득력 있게 편집할 수 있는 동시에 자신의 ID와 기타 고주파 얼굴 디테일을 보존할 수 있다. 먼저 대규모 얼굴 데이터셋에서 일반적인 얼굴 prior를 학습한 다음 테스트 ID를 캡처하는 약 20장의 사진을 사용하여 이러한 일반 prior를 개인화된 것으로 fine-tuning할 수 있다.
얼굴 외모 편집과 관련하여 자연스러운 질문은 조명, 표정, 머리 포즈, 헤어스타일, 액세서리 등을 변경하기 위해 어떤 표현을 사용하는지이다. DECA와 같은 기존 3D 얼굴 estimator는 이미지에서 조명(spherical harmonics), 표정, 머리 포즈에 대한 파라미터로 구성된 파라메트릭 3D 얼굴 모델을 이미 추출할 수 있다. 그러나 이러한 물리적 속성을 다시 이미지로 직접 렌더링하면 CGI 모양의 결과가 나타난다. 이유는 적어도 세 가지이다.
- 추정된 3D 얼굴 모양이 얼굴 윤곽이 일치하지 않아 거칠다.
- 반사율(Lambertian)과 조명(spherical harmonics)에 대한 가정은 현실을 재현하는 데 제한적이고 불충분하다.
- 3D morphable model (3DMM)은 단순히 헤어 스타일과 액세서리를 포함한 모든 외관 측면을 모델링할 수 없다.
그럼에도 불구하고 이러한 3DMM은 spherical harmonics (SH) 계수를 변경하여 조명뿐만 아니라 단순히 3DMM 파라미터를 변경하여 얼굴 표정과 머리 포즈를 수정할 수 있기 때문에 “모양 리깅”이 가능한 유용한 표현을 제공한다.
한편, diffusion model은 최근 이미지 생성을 위한 GAN의 대안으로 인기를 얻고 있다. Diff-AE는 오토인코딩 task에 대해 학습을 받을 때 diffusion model이 모양 편집을 위한 latent code를 제공할 수 있음을 보여준다. 또한 diffusion model은 픽셀 정렬된 feature (ex. diffusion model의 noise map)를 사실적인 이미지에 매핑할 수 있다. Diff-AE는 예를 들어 웃는 것에서 웃지 않는 것까지 보간할 수 있지만 semantic 레이블을 사용하여 이동 방향을 찾은 후 3D 이해가 필요하고 간단한 이진 semantic 레이블로 표현할 수 없는 편집을 수행할 수 없다. 조명과 머리 포즈의 변경을 포함한 이러한 3D 편집이 본 논문의 초점이다.
본 논문은 두 세계의 장점을 결합하기 위해 3DMM의 모양 (ex. 조명과 머리 포즈)을 편집하거나 “리깅”한 다음 3D 편집을 조건으로 사실적인 편집 이미지를 생성할 수 있는 모델인 DiffusionRig를 제안한다. 구체적으로, DiffusionRig는 먼저 기존 방법을 사용하여 단일 인물 사진에서 대략적인 물리적 특성을 추출하고, 3DMM space에서 원하는 3D 편집을 수행하고, 마지막으로 diffusion model을 사용하여 편집된 “물리적 버퍼”(표면 법선, 알베도, Lambertian 렌더링)을 사실적인 이미지로 변환한다.
편집된 이미지는 ID와 고주파수 얼굴 특성을 보존해야 하므로 먼저 CelebA 데이터셋에서 DiffusionRig를 학습시켜 일반적인 얼굴 prior를 학습시키고, 이를 통해 DiffusionRig가 표면 법선과 Lambertian 렌더링을 사실적인 이미지에 매핑하는 방법을 알 수 있도록 한다. 물리적 버퍼가 거칠고 충분한 ID 정보를 포함하지 않기 때문에 이 “Stage 1 모델”은 ID 보존을 보장하지 않는다. 두 번째 stage에서는 관심 있는 한 사람의 약 20개 이미지로 구성된 작은 데이터셋에서 DiffusionRig를 fine-tuning하여 물리적 버퍼를 이 사람의 사진에 매핑하는 개인별 diffusion model을 생성한다.
헤어스타일과 액세서리를 포함하되 이에 국한되지 않는 3DMM에 의해 모델링되지 않은 외관 측면이 있다. 모델에 이 추가 정보를 제공하기 위해 입력 이미지를 글로벌 latent code (출력 이미지와 픽셀 정렬되어 “로컬”인 물리적 버퍼와 대조적으로 “글로벌”)로 인코딩하는 인코더 분기를 추가한다. 이 code는 헤어스타일이나 안경과 같이 3DMM에서 모델링되지 않은 측면만 캡처하기 위해 저차원으로 선택된다.
Preliminaries
1. 3D Morphable Face Models
3D Morphable Face Model (3DMM)은 머리 자세, 얼굴 형상, 얼굴 표정 등을 표현하기 위해 컴팩트한 latent space를 사용하는 파라메트릭 모델이다. 본 논문에서는 정점(vertex) 기반 linear blend skinning과 올바른 blendshape를 사용하고 포즈, 모양, 표현 파라미터로 얼굴 mesh를 나타내는 3DMM인 FLAME을 사용한다.
FLAME은 얼굴 형상에 대해 작고 물리적으로 의미 있는 공간을 제공하지만 모양에 대한 설명은 제공하지 않는다. 이를 위해 DECA는 FLAME을 사용하고 Lambertian 반사율과 spherical harmonics (SH) 조명으로 얼굴 모양을 추가로 모델링한다. 대규모 데이터셋에서 학습된 DECA는 단일 초상화 이미지에서 알베도, SH 조명, FLAME 파라미터를 예측한다. DECA를 활용하여 FLAME 파라미터, 알베도, SH 조명을 편집하여 손쉬운 “리깅”을 지원하는 대략적인 3D 표현을 생성한다. DECA 렌더링과 실제 사진 사이의 사실감 차이는 상당하며 사후 편집 측정이 필요하다.
2. Denoising Diffusion Probabilistic Models
DDPM은 랜덤 noise 이미지를 입력으로 사용하고 이미지의 noise를 점진적으로 제거하여 사실적인 이미지를 생성하는 생성 모델 클래스이다. 이 생성 프로세스는 이미지에 noise를 점차적으로 추가하는 diffusion process의 역 과정으로 볼 수 있다. DDPM의 핵심 구성 요소는 denoising network $f_\theta$이다. 학습하는 동안 noisy한 이미지 $x_t$와 timestep $t$ ($1 \le t \le T$)를 사용하여 시간 $t$에서 noise $\epsilon_t$를 예측한다.
시간 $t$에서 예측된 noise는 \(\hat{\epsilon}_t = f_\theta (x_t, t)\)이며, 여기서 $x_t = \alpha_t x_0 + \sqrt{1 - \alpha_t^2} \epsilon_t$이고, $\epsilon_t$는 임의의 정규 분포 noise 이미지이고, $\alpha_t$는 hyperparameter이다. Forward process의 각 step에서 $x_t$의 noise 레벨을 점차적으로 증가시킨다. Loss는 $\epsilon_t$와 \(\hat{\epsilon}_t\) 사이의 거리로 계산된다. 따라서 학습된 모델은 임의의 noise 이미지를 입력으로 사용하고 점진적으로 noise를 제거하여 사진과 같은 이미지를 생성할 수 있다.
Method
개인화된 외모 편집을 가능하게 하려면 DiffusionRig라고 하는 모델이
- 새로운 조명과 같은 다양한 모양 조건을 기반으로 이미지를 생성하고
- 편집 중에 사람의 ID가 변경되지 않도록 개인적인 우선순위를 학습해야 한다.
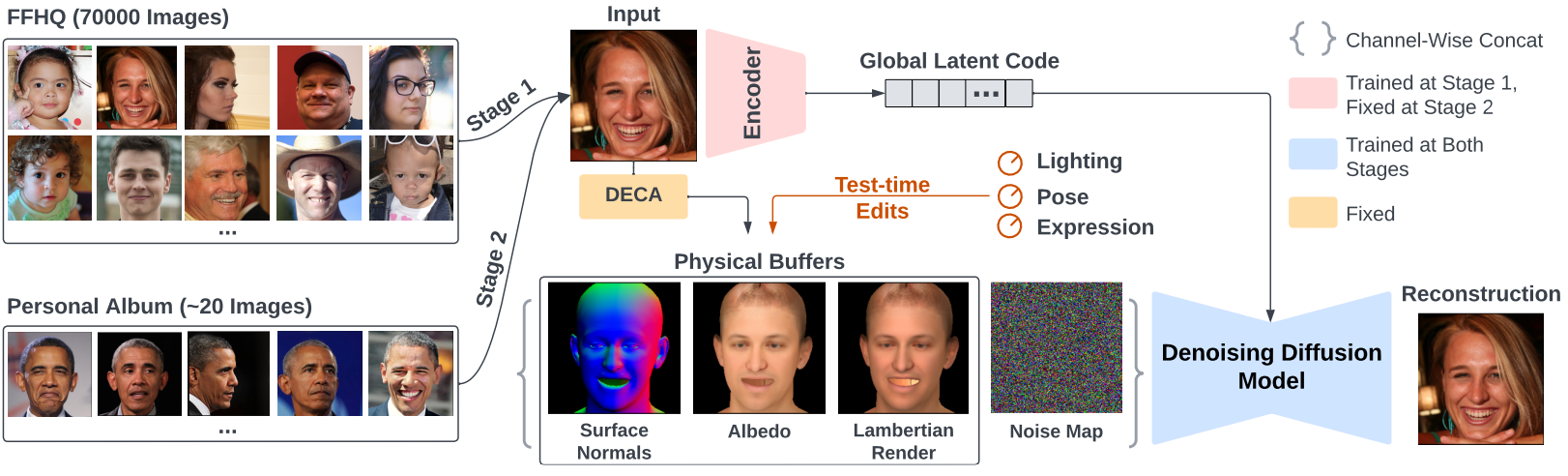
이를 위해 위 그림과 같이 2 stage 학습 파이프라인을 설계한다. 첫 번째 stage에서 모델은 기존 estimator를 사용하여 자동으로 추출된 물리적 버퍼로 표현되는 기본 “외관 조건”이 주어진 초상화 이미지를 재구성하도록 학습되어 일반적인 얼굴 prior를 학습한다. 두 번째 stage에서는 한 사람의 초상화 사진을 사용하여 모델을 fine-tuning하여 모델이 외모 편집 중 ID 이동을 방지하는 데 필요한 개인화된 prior를 학습하도록 한다.
1. Learning Generic Face Priors
첫 번째 stage는 조명과 같은 물리적 제약 조건에 따라 사실적인 이미지 합성을 가능하게 하는 얼굴 prior를 학습하도록 설계되었다. 물리적 조건의 경우 DECA를 사용하여 FLAME 파라미터 (형상 $\beta$, 표현 $\psi$, 포즈 $\theta$), 알베도 $\alpha$, (직교) 카메라 $c$, SH 조명 $l$ 등의 물리적 파라미터를 입력 초상화 이미지에서 생성한다. 그런 다음 Lambertian 반사율을 사용하여 이러한 물리적 속성을 표면 법선, 알베도, Lambertian 렌더링의 세 가지 버퍼로 렌더링한다. 이러한 물리적 버퍼는 얼굴 형상, 알베도, 조명에 대한 픽셀 정렬된 설명을 제공하지만 다소 거칠고 사실적인 이미지에 가깝지 않다. 그래도 이러한 버퍼를 사용하여 DECA 파라미터를 변경하여 생성 모델을 disentangle되고 물리적으로 의미 있는 방식으로 조작할 수 있다. 사실적인 이미지 합성의 경우 DDPM을 generator로 사용한다. DDPM은 생성 프로세스를 구동하기 위해 자연스럽게 픽셀 정렬된 조건을 취할 수 있기 때문이다.
픽셀 정렬된 물리적 버퍼 외에도 생성 중에 stochasticity를 설명하기 위해 랜덤 noise 이미지를 DDPM에 보관한다. 픽셀 정렬된 버퍼와 noise 맵 외에도 머리카락, 모자, 안경, 이미지 배경과 같은 물리적 버퍼에 의해 모델링되지 않는 글로벌 외모 정보 (로컬 표면 법선과 같은 로컬 정보와 반대)를 인코딩하려면 다른 조건이 필요하다. 따라서 diffusion model은 이미지 합성을 위한 조건으로 물리적 버퍼와 학습된 글로벌한 latent code를 모두 사용한다.
모델은 \(\hat{\epsilon}_t = f_\theta ([x_t, z], t, \phi_\theta (x_0))\)로 설명할 수 있다. 여기서 $x_t$는 timestep $t$에서의 noisy한 이미지, $z$는 물리적 버퍼, $x_0$는 원본 이미지, \(\hat{\epsilon}_t\)는 예측된 noise, $f_\theta$와 $\phi_\theta$는 각각 denoising model과 글로벌 latent 인코더이다.
이론적으로 글로벌 latent code가 로컬한 형상, 알베도, 조명 정보를 인코딩하는 것이 가능하며, 이는 물리적 버퍼를 완전히 무시하는 diffusion model로 이어질 수 있다. 경험적으로 네트워크는 로컬 정보에 물리적 버퍼를 사용하는 방법을 학습하고 글로벌 latent code에 의존하지 않는다. 아마도 이러한 버퍼가 ground-truth와 픽셀 정렬되어 모델에서 더 쉽게 활용되기 때문일 것이다.
2. Learning Personalized Priors
첫 번째 stage에서 일반적인 얼굴 prior를 학습한 후 DiffusionRig는 대략적인 물리적 버퍼가 주어진 사실적인 이미지를 생성할 수 있다. 다음 단계는 외모 편집 중에 ID 이동을 피하기 위해 주어진 사람에 대한 개인화된 prior를 학습하는 것이다. 개인 prior는 ID와 고주파 얼굴 특성을 보존하는 데 매우 중요하다. 약
20개 이미지의 특정 사람 사진 앨범에서 denoising model을 fine-tuning하여 이를 달성한다. Fine-tuning stage에서 denoising model은 사람의 ID 정보를 학습한다. 물리적 버퍼에 의해 모델링되지 않은 글로벌한 이미지 정보를 인코딩하는 방법을 학습했기 때문에 이전 stage에서 글로벌 인코더를 수정한다. 이 접근 방식은 신중한 튜닝이 필요한 GAN과 비교하여 간단하면서도 효과적이다.
이 작은 개인화 데이터셋의 경우 DECA 파라미터도 먼저 추출한다. 그러나 DECA는 단일 이미지 estimator이므로 그 출력은 극단적인 포즈나 표정에 민감하다. 사람 얼굴의 일반적인 모양이 합리적인 시간 내에 크게 변하지 않는다는 가정하에 앨범의 모든 이미지에 대해 FLAME의 모양 파라미터의 평균을 계산하고 DiffusionRig를 컨디셔닝할 때 평균 모양을 사용한다.
3. Model Architecture
DiffusionRig는 denoising model $f_\theta$와 글로벌 인코더 $\phi_\theta$의 두 가지 학습 가능한 부분으로 구성된다. Denoising model의 아키텍처는 계산 비용을 줄이고 추가 글로벌 latent code를 입력으로 사용하도록 수정된 ADM을 기반으로 한다. 글로벌 code의 경우 ADM이 시간 임베딩에 사용하는 것과 동일한 방법을 사용한다. 글로벌 latent code를 사용하여 각 레이어의 feature를 확장하고 shift한다. 인코더는 단순히 ResNet-18이며 출력 feature를 글로벌 latent code로 사용한다.
Loss function은 예측 noise와 ground-truth noise 사이의 거리를 계산하는 P2 weight loss이다.
\[\begin{equation} \mathcal{L} = \lambda'_t \| \hat{\epsilon}_t - \epsilon_t \|_2^2 \end{equation}\]경험적으로 P2 weight loss는 학습 과정을 가속화하고 고품질 이미지를 생성한다.
Experiments
- 구현 디테일
- 첫 번째 stage
- 데이터셋: FFHQ
- Optimizer: Adam
- Learning rate: $10^{-4}$
- Batch size: 256
- Iteration: 50,000
- 8개의 A100 GPU를 사용하여 약 15시간이 소요
- 두 번째 stage
- 한 사람의 이미지만 10~20개 사용
- 각 작은 데이터셋에서 batch size 4, iteration 5,000으로 fine-tuning
- Learning rate: $10^{-5}$
- 단일 V100 GPU에서 30분 이내에 완료
- 첫 번째 stage
1. Rigging Appearance With Physical Buffers
다음은 물리적 버퍼로 외모를 편집한 결과이다.

2. Rigging Appearance With Global Latent Code
다음은 물리적 버퍼와 글로벌 latent code를 섞어 외모를 편집한 결과이다.

3. Identity Transfer With Learned Priors
다음은 개인화된 모델을 스와핑한 결과이다.

4. Baseline Comparisons
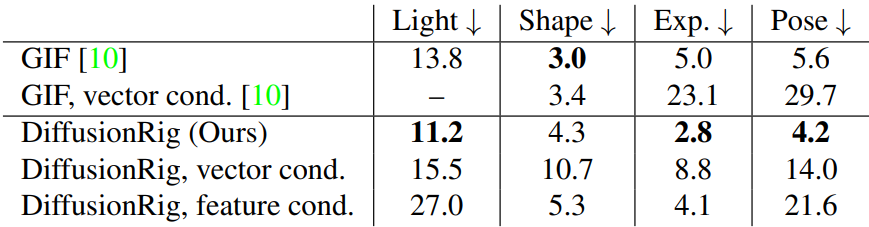
다음은 DECA re-inference의 RMSE를 측정한 표이다.
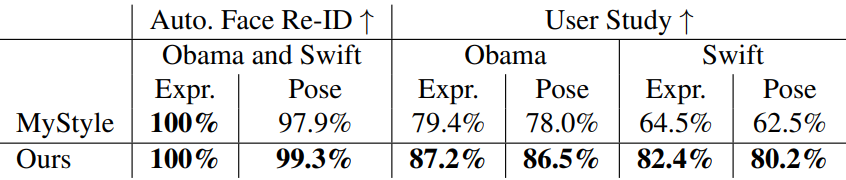
다음은 DiffusionRig와 MyStyle을 비교한 표이다.
5. Ablation Study
다음은 개인화된 prior를 사용한 / 사용하지 않은 재구성 결과이다.

다음은 Stage 2 이미지 개수에 따른 이미지 품질을 비교한 것이다.

다음은 조건의 형태에 대한 ablation study 결과이다.

Limitations
- Fine-tuning을 위해 작은 초상화 데이터셋에 의존하므로 대규모의 사용자를 위한 확장성이 제한된다.
- 편집에 극적인 머리 포즈 변경이 포함된 경우 원래 배경에 충실하지 않을 수 있다. 머리 포즈 변경으로 인해 가끔 가려졌던 부분이 드러나 배경 인페인팅이 필요하기 때문이다.
- 물리적 버퍼를 얻기 위해 DECA에 의존하기 때문에 DECA의 제한된 추정 능력의 영향도 받는다.
(ex. 극단적인 표현은 일반적으로 잘 예측할 수 없음. 추정 조명은 때때로 피부 톤과 결합됨.)