[논문리뷰] Training on Thin Air: Improve Image Classification with Generated Data (Diffusion Inversion)
arXiv 2023. [Paper] [Page] [Github]
Yongchao Zhou, Hshmat Sahak, Jimmy Ba
University of Toronto
24 May 2023
Introduction
실제 세계에서 데이터를 수집하는 것은 복잡하고 비용이 많이 들고 시간이 많이 소요될 수 있다. 전통적인 기계 학습 데이터셋은 종종 선별되지 않고 잡음이 있거나 수동으로 선별되지만 크기가 부족하다. 결과적으로 고품질 데이터를 얻는 것이 중요하지만 효과적인 예측 시스템을 개발하는 것은 여전히 어려운 측면이다. 최근에는 방대한 양의 잡음이 있는 인터넷 데이터에 대해 학습되는 GPT-3, DALL-E, Imagen, Stable Diffusion 등의 대규모 기계 학습 모델들이 강력한 생성 기능을 보여주는 성공적인 “foundation model”로 등장했다. 광범위한 지식을 감안할 때 다음과 같은 질문을 할 수 있다.
대규모의 사전 학습된 생성 모델이 판별적 모델 (discriminative model)을 위한 고품질 학습 데이터를 생성하는 데 도움이 될 수 있는가?
컴퓨터 비전에서 생성 모델은 data augmentation을 위해 오랫동안 고려되어 왔다. 이전 연구들에서는 VAE, GAN, diffusion model을 사용하여 zero-shot 또는 few-shot 학습과 같은 데이터 부족 설정에서 모델 성능을 향상시키거나 적대적 공격 또는 자연 분포 변화에 대한 견고성(robustness)을 향상시키는 방법을 탐색하였다.
그러나 이전 접근 방식으로 생성된 샘플의 다양성이 제한되어 있기 때문에 이러한 샘플은 원래 데이터셋에서 학습된 것과 비교하여 더 높은 정확도로 classifier를 학습시키는 데 사용할 수 없다고 널리 믿어지고 경험적으로 관찰되었다. 그럼에도 불구하고 SOTA diffusion 기반 text-to-image 모델이 다양한 이미지를 높은 시각적 충실도로 합성하는 놀라운 능력을 보여주기 때문에 generator 품질 문제는 더 이상 방해가 되지 않을 수 있다.
원래 데이터셋을 보강하기 위해 이러한 모델을 활용하는 자연스러운 접근 방식에는 인간 언어의 개입이 포함된다. 프롬프트 엔지니어링을 적용하면 타겟 도메인에 대한 도메인 전문 지식을 여러 프롬프트 세트로 추출할 수 있다. 언어 향상 기술과 결합하면 다양한 고화질 이미지를 생성할 수 있다.
그러나 다양성에도 불구하고 프롬프트 기반 생성은 종종 타겟 도메인에서 주제를 벗어나고 관련 없는 이미지를 생성하여 품질이 낮은 데이터셋을를 생성한다. 프롬프트에 의해 생성된 저품질 이미지 문제를 완화하기 위해 CLIP 필터링이 도입되어 프롬프트의 다양성과 품질 사이에서 보다 유리한 균형을 이룰 수 있다.
그럼에도 불구하고 생성 프로세스는 학습 데이터셋의 분포를 계속 무시하여 원본 데이터와 비교하여 분포적으로 다른 이미지를 생성하여 실제 데이터셋과 합성 데이터셋 사이에 상당한 차이가 발생한다. 또한 in-distribution 예제는 무한히 생성될 수 있지만 생성된 데이터는 여전히 최적의 성능을 내기 위해 원래 데이터셋의 충분한 범위를 제공해야 한다.
본 논문은 이러한 문제를 해결하고 생성된 데이터와 실제 데이터 간의 성능 격차를 좁히기 위해 사전 학습된 범용 이미지 generator인 Stable Diffusion을 활용하는 간단하면서도 효과적인 방법인 Diffusion Inversion을 제시한다. 원본 데이터 분포를 캡처하고 데이터 커버리지를 보장하기 위해 먼저 각 학습 이미지를 텍스트 인코더의 출력 공간으로 반전시켜 임베딩 벡터 세트를 얻는다. 다음으로 이러한 벡터의 noisy한 버전에서 Stable Diffusion을 컨디셔닝하여 초기 데이터셋을 넘어 확장되는 다양한 새로운 학습 이미지의 샘플링을 가능하게 한다.
결과적으로 최종 생성된 이미지는 사전 학습된 이미지 generator에 내장된 풍부한 지식에서 비롯된 가변성을 통합하면서 semantic 의미를 유지한다. 또한 조건 벡터를 학습하여 저해상도 이미지를 고해상도로 생성한 후 다운샘플링하는 대신 직접 생성하여 샘플링 효율성을 높인다. 이 전략은 diffusion model의 생성 속도를 6.5배 증가시켜 data augmentation 도구로 더 적합하게 만든다.
Method
수십억 개의 이미지-텍스트 쌍에 대해 학습된 모델인 Stable Diffusion은 일반화할 수 있는 풍부한 지식을 자랑한다. 본 논문은 특정 Classification task에 대한 이 지식을 활용하기 위해 사전 학습된 generator $G$를 타겟 도메인 데이터셋으로 안내하는 2-stage 방법을 제안하였다. 첫 번째 stage에서는 각 이미지를 모델의 latent space에 매핑하여 latent 임베딩 벡터의 데이터셋을 생성한다. 그런 다음 이러한 벡터의 noisy한 버전에 따라 reverse diffusion process를 실행하여 새로운 이미지 변형을 생성한다. 아래 그림은 이 접근 방식을 설명한다.
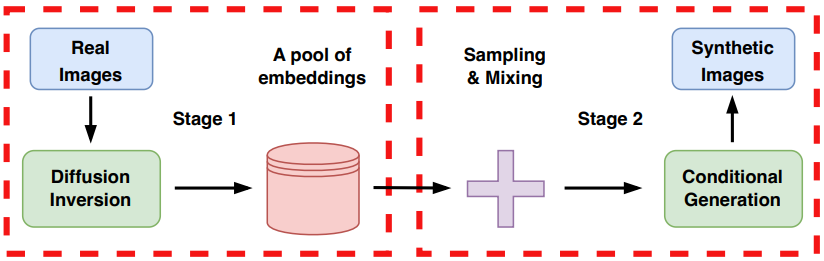
1. Stage 1 - Embedding Learning
Stable Diffusion
Stable Diffusion은 Latent Diffusion Model(LDM)의 한 유형이다. LDM은 오토인코더의 latent space에서 작동하며 두 가지 주요 구성 요소가 있다.
첫째, 오토인코더는 KL-divergence loss 또는 vector quantization의 정규화를 사용하여 reconstruction loss를 최소화하기 위해 큰 이미지 데이터셋에서 사전 학습된다. 이를 통해 인코더 $\mathcal{E}$는 이미지 \(x \in \mathcal{D}_x\)를 latent code $z = \mathcal{E}(x)$로 매핑할 수 있으며, 디코더 $\mathcal{D}$는 이러한 잠재 코드를 $\mathcal{D}(\mathcal{E}(x)) \approx x$가 되는 이미지로 다시 변환할 수 있다.
둘째, 클래스 레이블, segmentation mask, 텍스트 토큰 등의 선택적 조건부 정보를 통합하여 파생된 latent space에서 denoising 목적 함수를 최소화하도록 diffusion model을 학습한다.
\[\begin{equation} L_\textrm{LDM} := \mathbb{E}_{z \sim \mathcal{E} (x), y, \epsilon \sim \mathcal{N}(0, 1), t} [\| \epsilon - \epsilon_\theta (z_t, t, c_\theta (y)) \|_2^2] \end{equation}\]여기서 $t$는 timestep을 나타내고, $z_t$는 시간 $t$에서의 latent noise, $\epsilon$은 스케일링되지 않은 noise 샘플, $\epsilon_\theta$는 denoising network, $c_\theta (y)$는 입력 $y$를 벡터에 매핑하는 모델 매핑이다. Inference 과정에서 임의의 noise 벡터를 컨디셔닝 벡터로 반복적으로 denoising하여 새로운 이미지 latent $z_0$를 생성하고, latent code를 사전 학습된 디코더 $x’ = \mathcal{D} (z_0)$를 사용하여 이미지로 변환한다.
Diffusion Inversion
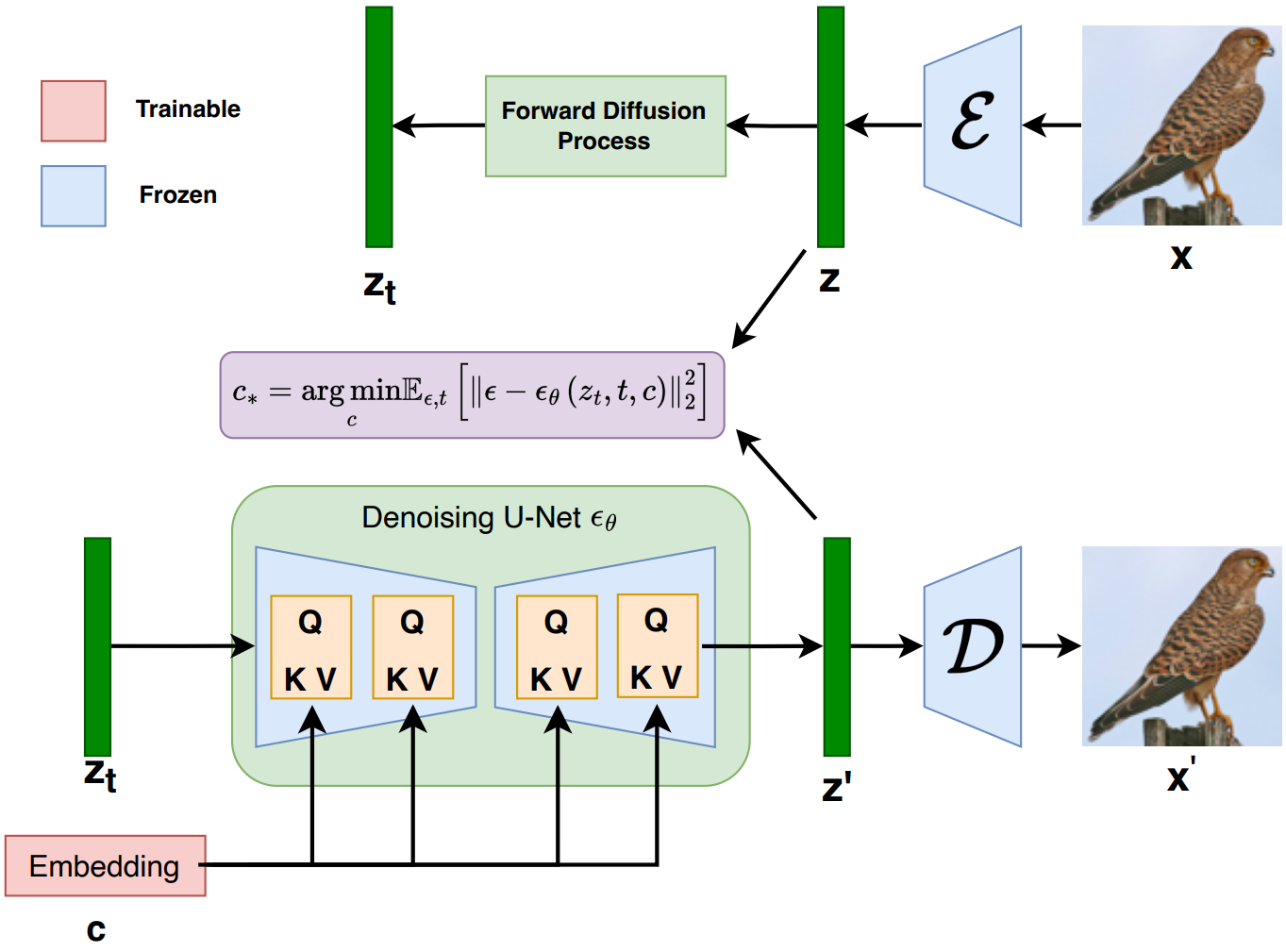
이전 연구들에서는 이미지를 텍스트 인코더 $c_\theta$의 입력 토큰으로 다시 반전시키려고 시도했다. 그러나 이 접근 방식은 텍스트 modality의 표현력에 의해 제한되고 모델의 원래 출력 도메인으로 제한된다. 이 한계를 극복하기 위해 $c_\theta$를 ID 매핑으로 취급하고 LDM loss를 최소화하여 실제 데이터셋의 각 이미지 latent $z$에 대한 조건 벡터 $c$를 직접 최적화한다.
최적화 프로세스 전반에 걸쳐 원래 LDM 모델의 학습 체계를 유지하고 denoising model $\epsilon_\theta$를 변경하지 않고 유지하여 사전 학습 지식을 최적으로 유지한다. 또한 고해상도 이미지를 생성한 후 다운샘플링하는 대신 타겟 해상도 이미지를 생성하도록 맞춤화된 조건 벡터를 학습하여 샘플링 효율성을 개선하고, 이를 통해 전체 생성 시간을 상당히 단축한다.
2. Stage 2 - Sampling
Classifier-free Guidance
Classifier-free guidance는 가중치 파라미터 $w \in \mathbb{R}$을 사용하여 Stable Diffusion, GLIDE, Imagen과 같은 대규모 모델에서 일반적으로 사용되는 클래스 조건 diffusion model에서 샘플 품질과 다양성의 균형을 맞춘다. 샘플 생성 중에 조건부 diffusion model $\epsilon_\theta (z_t, t, c)$와 unconditional model $\epsilon_\theta (z_t, t)$가 모두 평가된다. Stable Diffusion에서 컨디셔닝 벡터는
\[\begin{equation} \hat{\epsilon} = (1 + w) \epsilon_\theta (z_t, t, c) - w \epsilon_\theta (z_t, t) \end{equation}\]로 주어진 각 denoising step에서의 모델 출력과 함께 빈 문자열에 대한 텍스트 인코더의 출력에 의해 결정된다. 그러나 조건 입력으로 빈 문자열을 사용하는 것은 데이터 분포가 학습 분포에서 크게 벗어날 때, 특히 이미지 해상도가 다를 때 타겟 도메인에 대해 비효율적이다. 이 분포 이동을 해결하기 위해 unconditional model에 대한 클래스 조건 입력으로 모든 학습된 벡터의 평균 임베딩을 대신 활용한다.
Sample Diversity
샘플 다양성은 합성 데이터에 대한 다운스트림 classifier를 학습시키는 데 중요하다. 이를 위해 다양한 classifier-free guidance scale을 사용하고 다양한 랜덤 노이즈로 denoising process를 시작하여 뚜렷한 이미지 변형을 생성한다. 또한 Gaussian noise pertubation과 latent interpolation이라는 두 가지 컨디셔닝 벡터 섭동 방법을 사용할 수 있다.
Gaussian 방식에서는 Gaussian noise를 컨디셔닝 벡터에 추가하여 새로운 벡터
\[\begin{equation} \hat{c} = c + \lambda \epsilon, \quad \epsilon \sim \mathcal{N} (0, 1) \end{equation}\]를 생성한다. 여기서 $\lambda$는 섭동 강도를 나타낸다.
Latent interpolation 방식에서는 두 컨디셔닝 벡터 $c_1$과 $c_2$ 사이를 선형 보간하여 새 벡터를 생성한다.
\[\begin{equation} \hat{c} = \alpha c_1 + (1 - \alpha) c_2 \end{equation}\]Experimental Results
- 데이터셋
- CIFAR10/100, STL10, ImageNette
- MedMNISTv2 (PathMNIST, BloodMNIST, DermaMNIST), EuroSAT
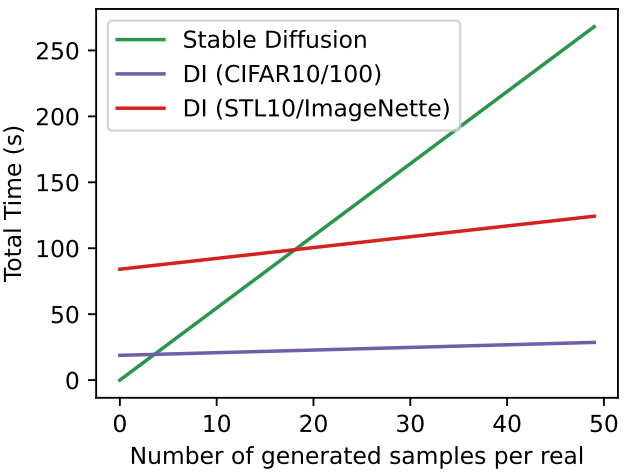
전체 런타임, 즉 임베딩 학습과 샘플링에 소요되는 시간은 아래 그래프와 같다.
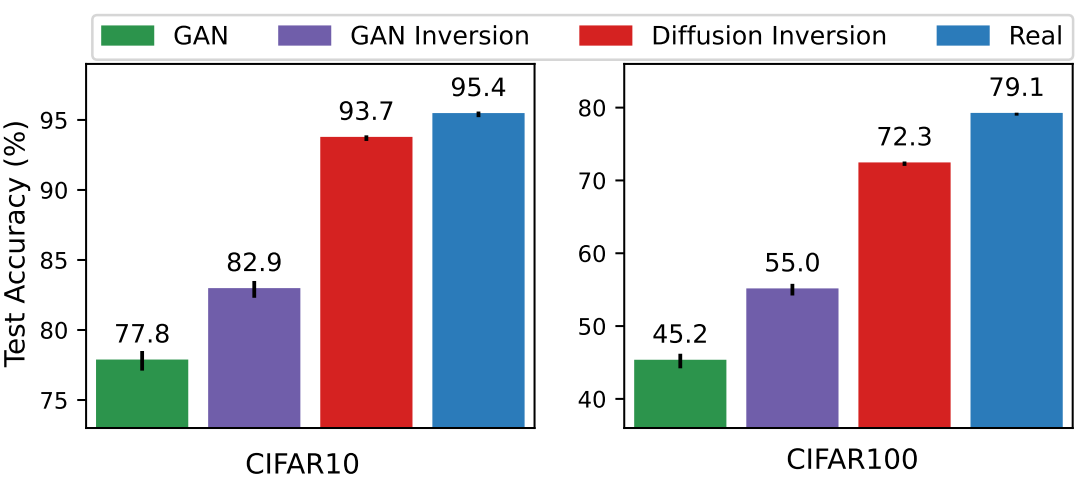
1. Generator Quality and Data Size Matter
다음은 generator의 품질을 비교한 그래프이다.
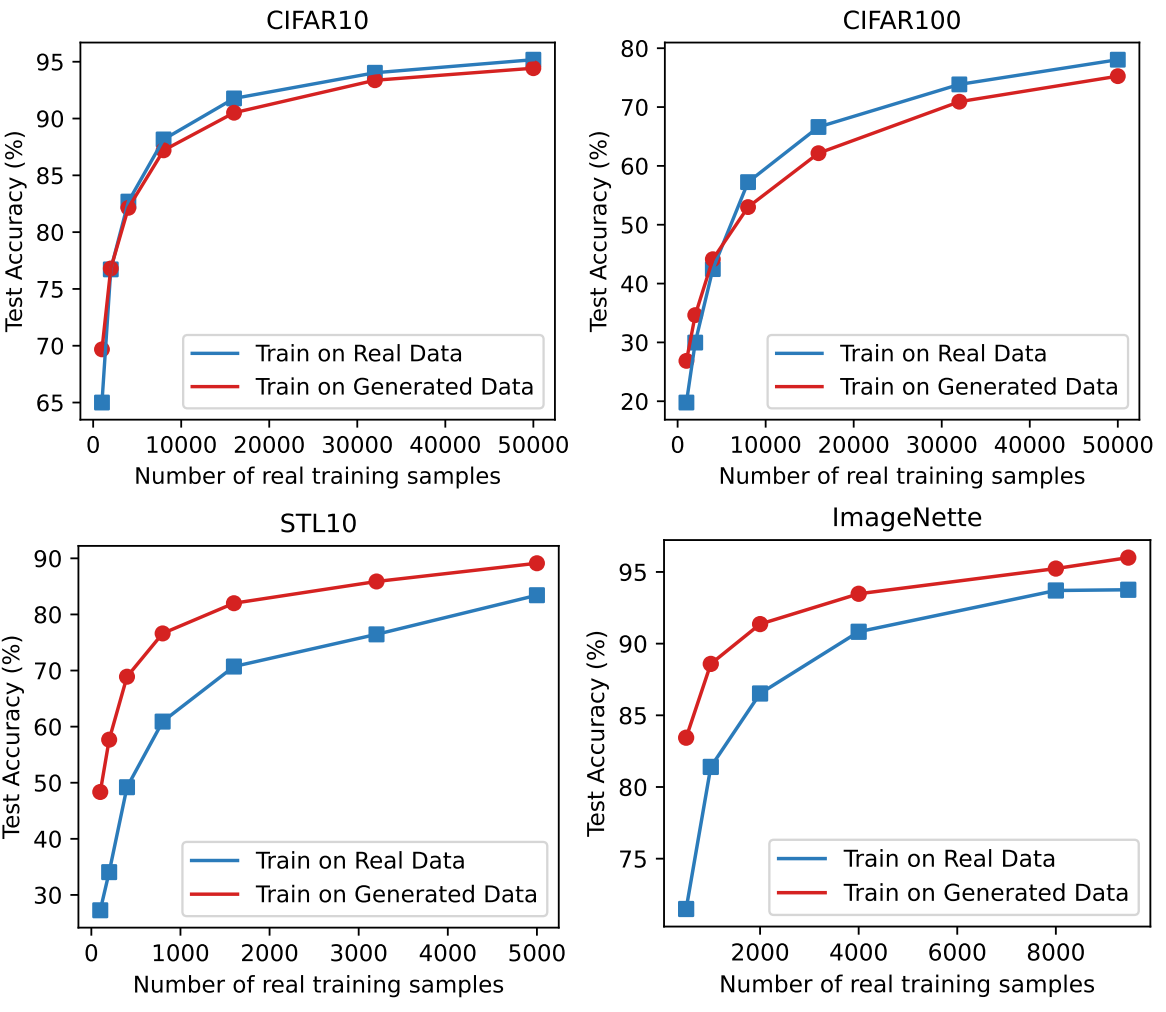
다음은 실제 데이터 포인트 수에 따른 성능을 나타낸 그래프이다.
다음은 다양한 해상도에서 오토인코딩된 이미지로 학습된 ResNet18의 성능을 비교한 표이다.
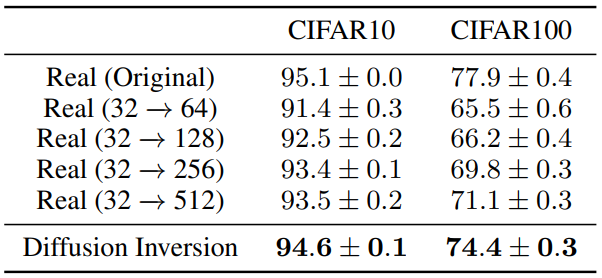
가장 높은 해상도인 512도 원본 이미지로 학습한 것보다 성능이 좋지 못하다. 이는 오토인코딩 중 상당한 정보 손실이 있거나 재구성된 이미지와 실제 이미지 사이의 분포 이동이 있음을 뜻한다.
다음은 생성된 데이터의 수에 따른 정확도를 나타낸 그래프이다.
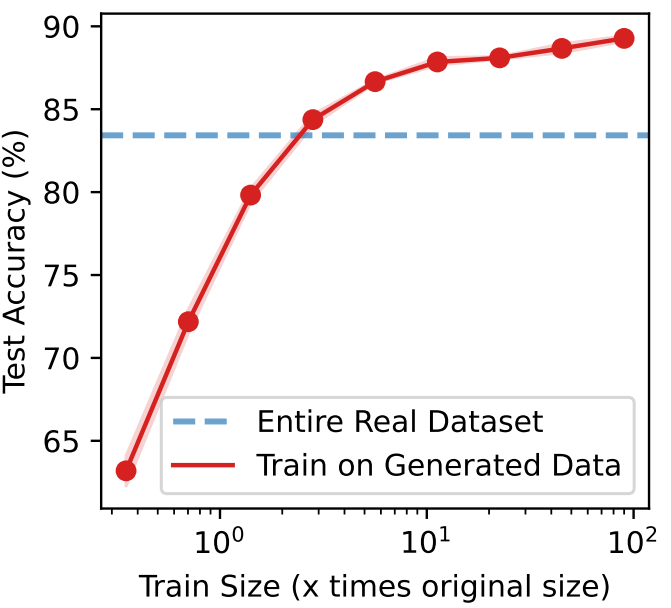
2. Data Distribution and Data Coverage Matter
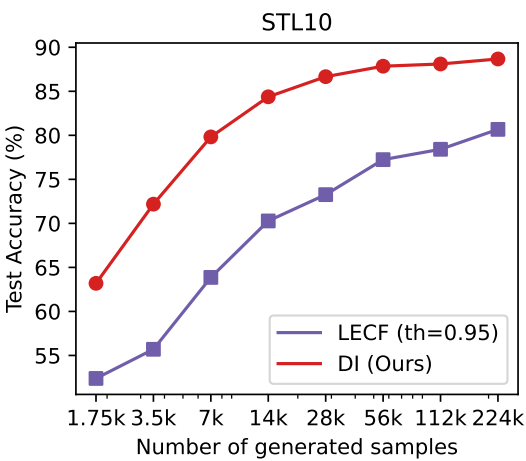
다음은 Language Enhancement with Clip Filtering (LECF)과 비교한 표와 그래프이다.
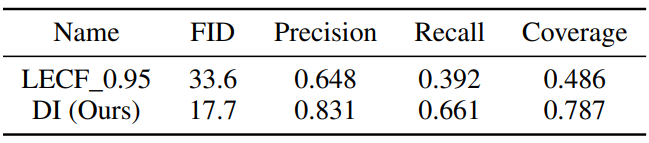
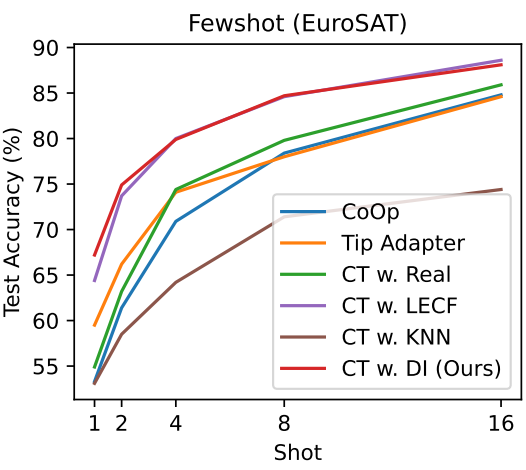
다음은 EuroSAT 데이터셋으로 few-shot learning 성능을 평가한 것이다.
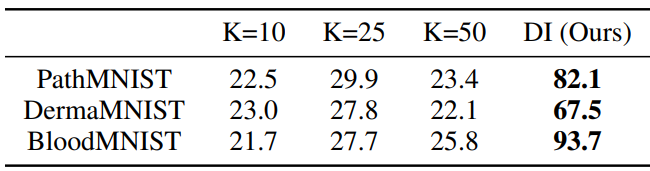
다음은 LAION-5B에서의 KNN 검색 성능을 비교한 표이다.
다음은 다양한 데이터셋에 대하여 Diffusion Inversion으로 합성한 이미지들이다.

3. Evaluation on Various Architectures
다음은 다양한 classifier 아키텍처에 대한 평가 결과이다.
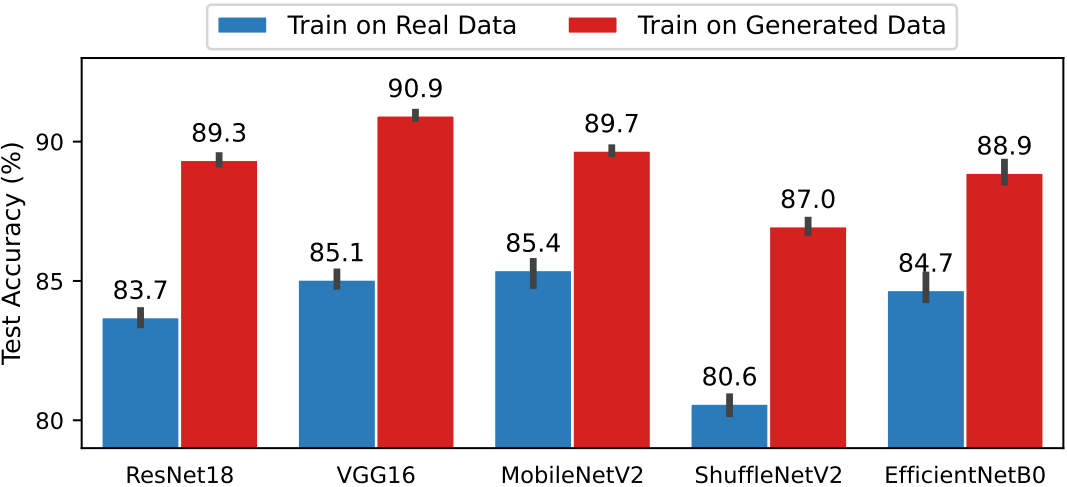
4. Comparison against Image Data Augmentation Methods
다음은 다양한 data augmentation 방법을 사용하였을 때의 정확도를 비교한 표이다.

Quantitative Analysis
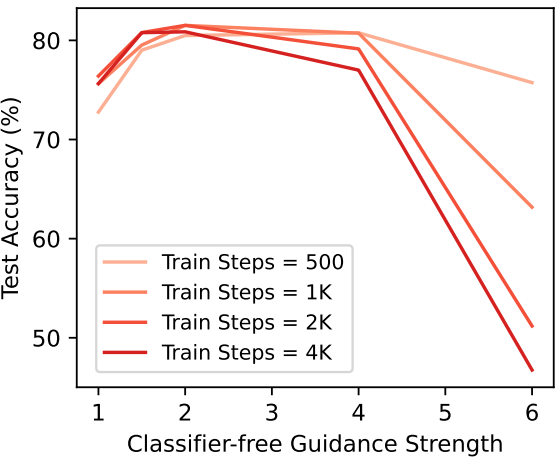
다음은 classifier-free guidance 강도와 학습 step에 따른 정확도를 나타낸 그래프이다.
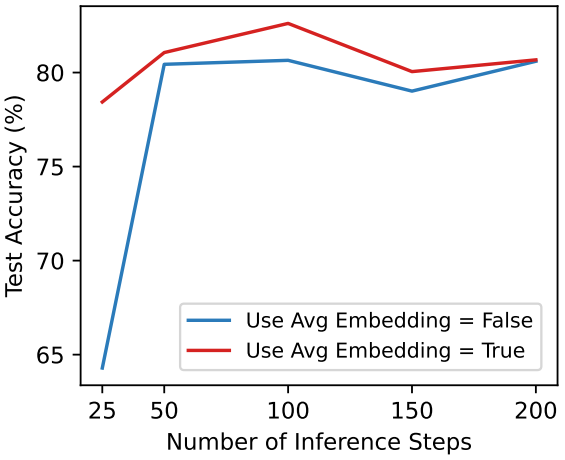
다음은 inference step과 unconditional embedding에 따른 정확도를 나타낸 그래프이다.
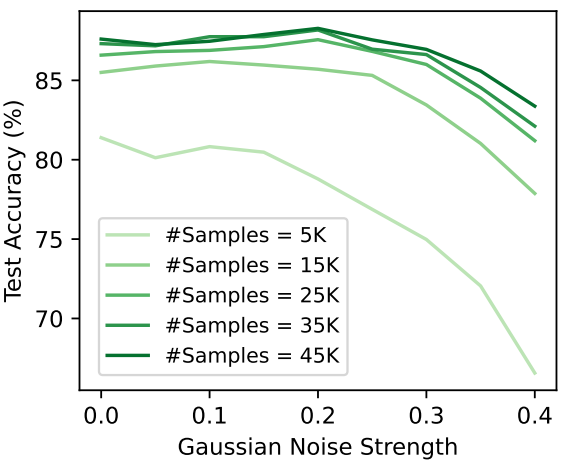
다음은 Gaussian noise 강도와 데이터 생성 수에 따른 정확도를 나타낸 그래프이다.
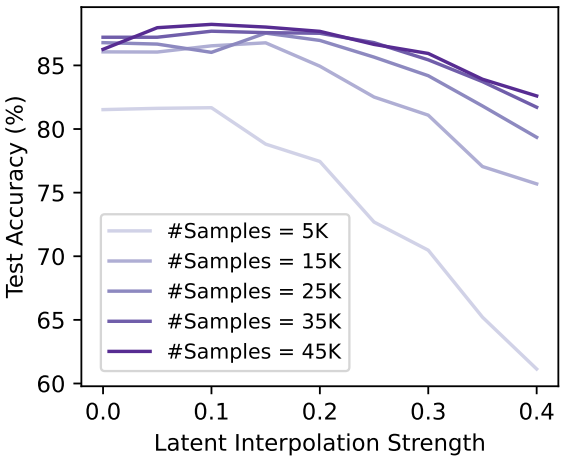
다음은 latent interpolation 강도와 데이터 생성 수 따른 정확도를 나타낸 그래프이다.
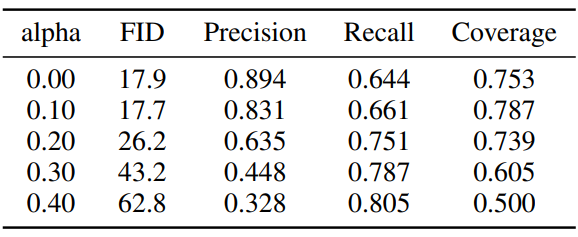
다음은 interpolation 강도에 따른 영향을 나타낸 표이다.
다음은 두 임베딩 벡터를 다양한 interpolation 강도 $\alpha$로 보간하여 생성한 이미지의 예시이다. ($\alpha$는 왼쪽부터 0.0, 0.1, 0.2, 0.3, 0.5, 0.7, 0.8, 0.9, 1.0)

Limitations
ImageNet과 같은 대규모 데이터셋으로 확장하면 상당한 스토리지 요구량과 Stable Diffusion의 비효율적인 샘플링으로 인해 문제가 발생한다.