[논문리뷰] Imitating Human Behaviour with Diffusion Models
ICLR 2023. [Paper]
Tim Pearce, Tabish Rashid, Anssi Kanervisto, Dave Bignell, Mingfei Sun, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Ida Momennejad, Katja Hofmann, Sam Devlin
Microsoft Research
25 Jan 2023
Introduction
인간-AI 협업을 가능하게 하려면 에이전트는 모든 가능한 인간 행동에 가장 잘 대응하는 방법을 배워야 한다. 단순한 환경에서는 가능한 모든 인간 행동을 생성하는 것으로 충분하지만 환경의 복잡성이 증가함에 따라 이 접근 방식은 확장하기 어려울 것이다. 대신 인간 행동 데이터를 엑세스할 수 있다고 가정하면 인간 행동 모델을 사용한 학습을 통해 협업 에이전트를 개선할 수 있다.
원칙적으로 인간 행동은 observation과 action 튜플의 오프라인 데이터셋에서 시연자의 행동을 모방하도록 에이전트를 학습시키는 모방 학습 접근 방식을 통해 모델링할 수 있다. 보다 구체적으로 Behavior Cloning(BC)은 이론적으로는 제한적이지만 자율주행, 로봇공학, 게임 플레이와 같은 영역에서 경험적으로 효과적이었다.
BC에 대한 인기 있는 접근 방식은 학습을 더 간단하게 만들기 위해 모델링할 수 있는 분포 유형을 제한한다. 연속 동작에 대한 일반적인 접근 방식은 평균 제곱 오차(MSE)를 통해 최적화된 점 추정치를 학습하는 것이다. 이는 무시할 수 있는 분산의 등방성 가우시안으로 해석될 수 있다. 또 다른 대중적인 접근 방식은 action space를 분류 문제로서 한정된 수의 bin과 frame으로 이산화하는 것이다. 둘 다 그들이 만드는 근사치로 인해 어려움을 겪는다. 에이전트가 평균 policy를 배우도록 장려하거나 action 차원을 독립적으로 예측하여 조정되지 않은 행동을 초래한다.
이러한 단순한 모델링 선택은 demonstating policy 자체가 제한된 표현일 때 성공적일 수 있다(ex. 간단한 모델로 표현되는 사전 학습된 단일 policy의 궤적을 사용하는 경우). 그러나 다양한 궤적과 decision point에서의 multi-modality를 포함하는 BC의 경우 단순한 모델은 행동의 전체 범위와 fidelity를 포착하기에 충분히 표현력이 없을 수 있다.
이러한 이유로 저자들은 관찰된 action의 전체 분포를 모델링하려고 한다. 특히, 본 논문은 현재 이미지, 동영상, 오디오 생성을 주도하고 있는 diffusion model에 초점을 맞추고 GAN의 학습 불안정성 문제나 에너지 기반 모델의 샘플링 문제를 피한다. BC에 대한 diffusion model을 사용하여 다음을 수행할 수 있다.
- 복잡한 action 분포를 보다 정확하게 모델링한다.
- 시뮬레이션된 로봇 벤치마크에서 state-of-the-art 방법을 훨씬 능가한다.
- Counter-Strike: Global Offensive에서 인간 게임플레이를 모델링하도록 스케일링할 수 있다.
Observation-to-Action Diffusion Models

1. Diffusion Model Overview
Diffusion mode은 Gaussian noise를 반복적인 방식으로 일부 대상 분포에 매핑하는 생성 모델이며, 선택적으로 일부 컨텍스트로 컨디셔닝할 수 있다. $a_T \sim \mathcal{N} (0, I)$부터 시작하여 시퀀스 $a_{T -1}, a_{T -2}, \cdots, a_0$은 깨끗한 샘플인 $a_0$과 함께 각각 이전 버전의 약간 denoise된 버전으로 예측된다. 여기서 $T$는 denoising step의 총 수이다.
본 논문은 DDPM을 사용한다. 학습 중에 noisy한 입력은 다음과 같이 생성될 수 있다.
\[\begin{equation} a_\tau = \sqrt{\vphantom{1} \bar{\alpha}_\tau} a + \sqrt{1 - \bar{\alpha}_\tau} z \end{equation}\]$z \sim \mathcal{N}(0, I)$은 random noise이고, $\bar{\alpha}_\tau$는 분산 schedule이다. 신경망 $\epsilon(\cdot)$은 다음을 최소화하여 입력에 추가된 noise를 예측하도록 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{DDPM} := \mathbb{E}_{o, a, \tau, z} [\| \epsilon(o, a_\tau, \tau) - z \|_2^2] \\ o, a \sim \mathcal{D}, \quad \tau \sim \mathcal{U}[1,T] \end{equation}\]샘플링 시, 추가 분산 schedule 파라미터 $\alpha_\tau$와 $\sigma_\tau$와 함께 입력은 반복적으로 denoise된다.
\[\begin{equation} a_{\tau - 1} = \frac{1}{\sqrt{\alpha_\tau}} \bigg( a_\tau - \frac{1 - \alpha_\tau}{\sqrt{1 - \bar{\alpha}_\tau}} \epsilon (o, a_\tau, \tau) \bigg) + \sigma_\tau z \end{equation}\]2. Architectural Design
Observation-to-action diffusion model의 신경망 아키텍처는 noisy한 action $a_{\tau-1} \in \mathbb{R}^{\vert a \vert}$, timestep $\tau$, observation $o$를 입력으로 받고, 예측된 noise mask $\hat{z} \in \mathbb{R}^{\vert a \vert}$을 출력한다.
U-Net은 text-to-image diffusion model의 표준 구성 요소가 되었지만 U-Net의 사용은 큰 공간적 입력과 출력에만 의미가 있으며 적당한 차원의 action 벡터 생성이 필요하다. 따라서 다양한 복잡성을 지닌 세 가지 아키텍처를 설명한다.
Basic MLP
이 아키텍처는 모든 관련 입력을 직접 concat한다 ($[a_{\tau-1}, o, \tau]$). 이 입력은 MLP에 입력돤다.
MLP Sieve
3개의 인코딩 네트워크를 사용하여 observation, timestep, action의 임베딩을 생성한다
\[\begin{equation} o^e, t^e, a_{\tau-1}^e \in \mathbb{R}^\textrm{embed dim} \end{equation}\]이들은 denoising network에 대한 입력으로 함께 concat된다 ($[o^e, t^e, a_{\tau-1}^e]$). Denoising network는 residual skip connection이 있고 timestep $\tau$와 action $a_{\tau-1}$이 각 hidden layer 후에 반복적으로 concat되는 fully-connected 아키텍처이다. 더 긴 observation 기록을 포함하기 위해 이전 observation이 동일한 임베딩 네트워크를 통과하고 임베딩이 함께 concat된다.
Transformer
MLP Sieve와 같은 임베딩이 생성된다. 그런 다음 multi-head attention 아키텍처가 denoising network로 사용된다. 최소 3개의 토큰 $o^e$, $t^e$, $a_{\tau - 1}^e$가 입력으로 사용되며 이는 더 긴 observation 기록을 포함하도록 확장될 수 있다 (diffusion process가 Markovian이기 때문에 현재 $t^e$, $a_{\tau-1}^e$만 필요함).
Sampling rate
MLP Sieve와 Transformer는 신중하게 설계되어 observation 인코더가 denoising network와 분리된다. 테스트 시 이는 observation 인코더에 대해 단일 forward pass만 필요하고 더 가벼운 denoising network를 통해 여러 forward pass가 실행됨을 의미한다. 그 결과 샘플링 시간을 관리할 수 있다.
3. Why Classifier-Free Guidance Fails
Classifier-Free Guidance(CFG)는 text-to-image model의 핵심 요소가 되어 이미지의 전형성(typicality)과 다양성을 trade-off할 수 있다. CFG에서 신경망은 conditional 및 unconditional 생성 모델로 학습된다. 샘플링 중에 ‘guidance weight’ $w$를 도입하여 일부 컨텍스트(여기서는 $o$)에 따라 예측에 더 높은 가중치($w > 0$)를 부여하고 unconditional 예측에 음의 가중치를 부여한다.
\[\begin{equation} \hat{z}_\tau = (1 + w) \epsilon_\textrm{cond.} (a_{\tau-1}, o, \tau) - w \epsilon_\textrm{uncond.} (a_{\tau-1}, \tau) \end{equation}\]CFG는 $w$가 클수록 다양성을 희생시키면서 더 높은 likelihood의 궤적을 생성하므로 순차적 설정에서 유익할 것이라고 예상할 수 있다. 놀랍게도 저자들은 CFG가 실제로 덜 일반적인 궤적을 조장하고 성능을 저하시킬 수 있음을 발견했다.
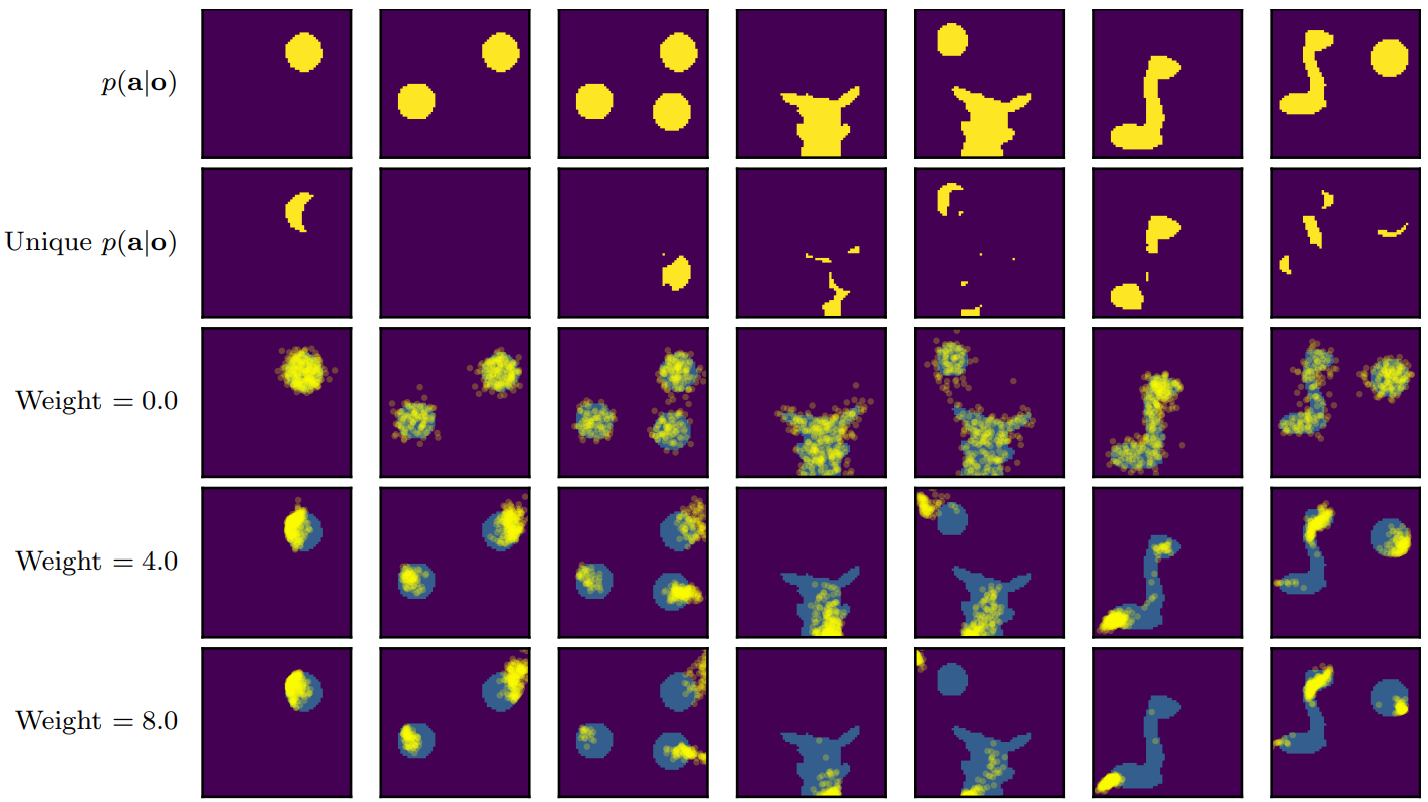
위 그림에서 다양한 guidance 강도 $w$에서 claw machine game에 대한 $\hat{p}(a \vert o)$를 시각화한다. CFG의 해석은 암시적 classifier $p(o \vert a)$를 최대화하는 action의 샘플링을 권장한다는 것이다. 따라서 CFG는 특정 observation에 고유한 action을 선택하도록 권장한다. 이는 text-to-image model에 유용하지만, 순차적 환경에서는 일부 observation과 쌍을 이루는 덜 일반적인 action을 선호하여 에이전트가 likelihood가 높은 action을 거부하게 된다.
4. Reliable Sampling Schemes
Text-to-image diffusion에서는 일반적으로 여러 샘플이 병렬로 생성되어 사용자가 좋아하는 것을 선택하고 모든 실패를 무시할 수 있다. 그러나 observation-to-action diffusion model을 roll-out할 때 이러한 수동 스크리닝은 실현 가능하지 않다. Roll-out 중에 잘못된 action이 선택될 수 있는 위험이 남아 있으며, 이로 인해 에이전트가 out-of-distribution 상태로 보내질 수 있다. 따라서 저자들은 샘플링 중에 likelihood가 더 높은 action을 장려하여 이 스크리닝 프로세스를 반영하는 Diffusion BC의 변형으로 ‘Diffusion-X’와 ‘Diffusion-KDE’를 제안한다. 두 방법 모두 학습 절차는 변경되지 않는다 (모델의 조건부 버전만 필요함).
Diffusion-X
샘플링 프로세스는 $T$ timestep에 대해 정상적으로 실행된다. 그런 다음 timestep이 고정되고 $\tau = 1$이고 추가 denoising iteration이 $M$ timestep 동안 계속 실행된다. 이것의 이면에 있는 직관은 샘플이 더 높은 likelihood 영역으로 계속 이동한다는 것이다.
Diffusion-KDE
평소와 같이 diffusion model에서 여러 action 샘플을 생성한다 (병렬로 수행할 수 있음). 모든 샘플에 간단한 kernel-density estimator (KDE)를 적용하고 각각의 likelihood를 점수화한다. Likelihood가 가장 높은 action을 선택한다.

이러한 샘플링 수정의 효과는 위 그림에 설명되어 있다. Diffusion BC는 실제 $p(a \vert o)$ 영역을 벗어나는 소수의 action을 생성하지만 Diffusion-X와 Diffusion-KDE는 이러한 잘못된 action을 방지한다. 그림의 두 가지 고유한 모드는 두 가지 샘플링 방법 모두에 의해 복구되어 각 모드 내의 다양성이 감소하더라도 multimodality가 손상되지 않음을 나타낸다.
Experiments
- Baselines
- MSE: 모델을 MSE로 학습
- Discretised: 각 action 차원을 20개의 균등한 bin으로 discretise한 다음 cross-entropy로 독립적으로 학습
- K-means: 모든 action에서 먼저 K-means를 실행하여 $K$개의 후보 action들을 생성하고, action들을 가장 가까운 bin으로 discretise한 다음 cross-entropy로 독립적으로 학습
- K-means+Residual: K-means에 추가로 각 bin 예측에 연속적인 residual을 MSE로 학습
1. Learning Robotic Control from Human Demonstration
이 환경에서 에이전트는 시뮬레이션된 주방 내부에서 로봇 팔을 제어한다. 전자레인지를 열거나 스토브를 켜는 등 관심 있는 7가지 task를 수행할 수 있다. 데모 데이터셋에는 566개의 궤적이 포함되어 있다. 이들은 인간의 움직임이 로봇 관절 작동으로 변환되는 가상 현실 설정을 사용하여 수집되었다. 각 데모 궤적은 4개의 미리 결정된 task을 수행했다. 대략 동일한 비율로 데이터셋에 25개의 서로 다른 task 시퀀스가 있다.
Kitchen environment의 observation space는 물체의 위치와 로봇 관절에 대한 정보를 포함하는 연속적인 30차원 벡터이다. Action space는 관절 작동의 연속적인 9차원 벡터이다. 모든 모델은 에이전트가 속도를 추론할 수 있도록 이전 두 observation 값을 입력으로 받는다. Diffusion model의 경우 $T = 50$으로 설정한다.
Kitchen environment은 여러 가지 이유로 어렵다.
- Action 차원 간에 강력한 (때로는 비선형적인) 상관관계가 존재한다.
- 에이전트가 다음에 완료할 task를 선택하는 시점과 완료 방법에 있어서 $p(a \vert o)$에는 multimodality가 있다.
Main Results
다음은 로봇 제어 결과를 나타낸 표이다.
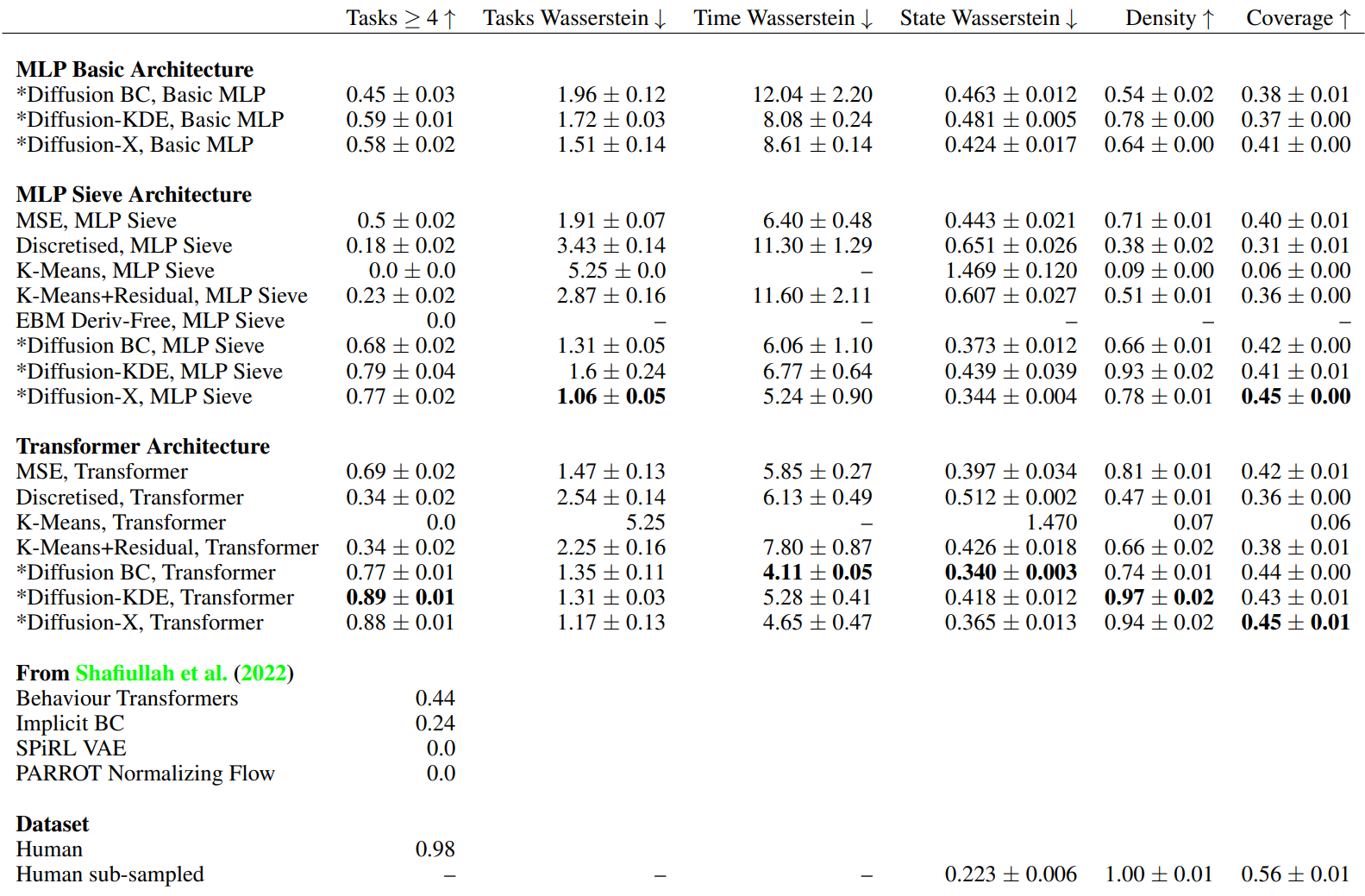
다음은 kitchen task에서 로봇 제어를 완료하는 데 걸리는 시간을 나타낸 그래프이다. 색칠된 부분은 인간 시연을 나타낸 것이고, 왼쪽은 MSE Transformer, 오른쪽은 Diffusion-X Transformer의 결과이다.
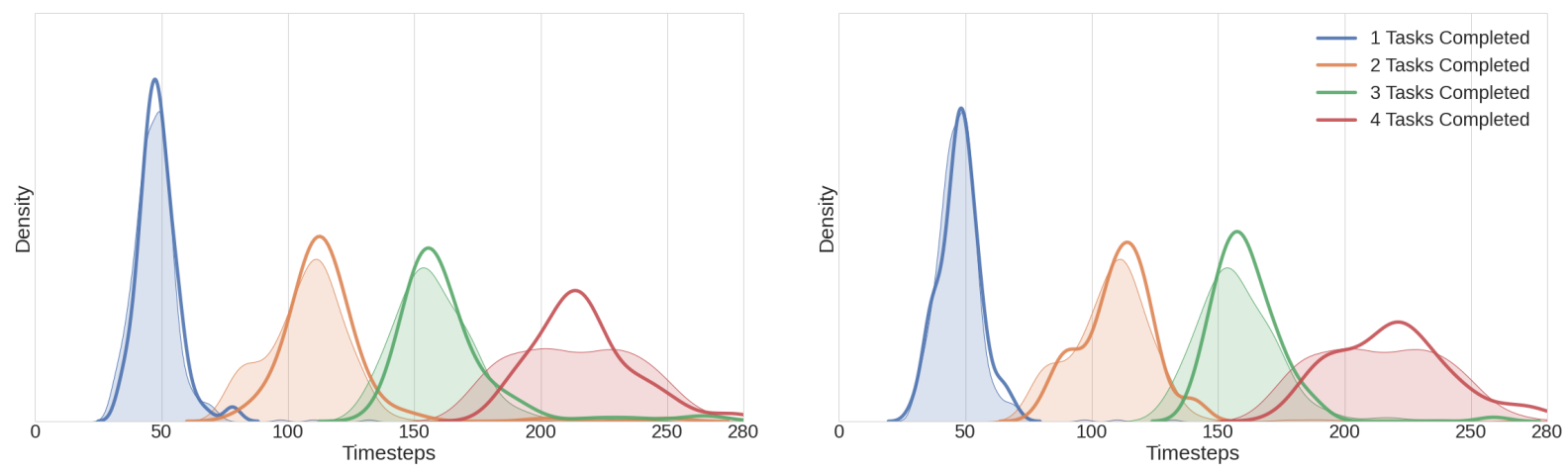
Classifier Free Guidance Analysis
다음은 Diffusion BC에 대한 CFG의 효과를 나타낸 표이다.
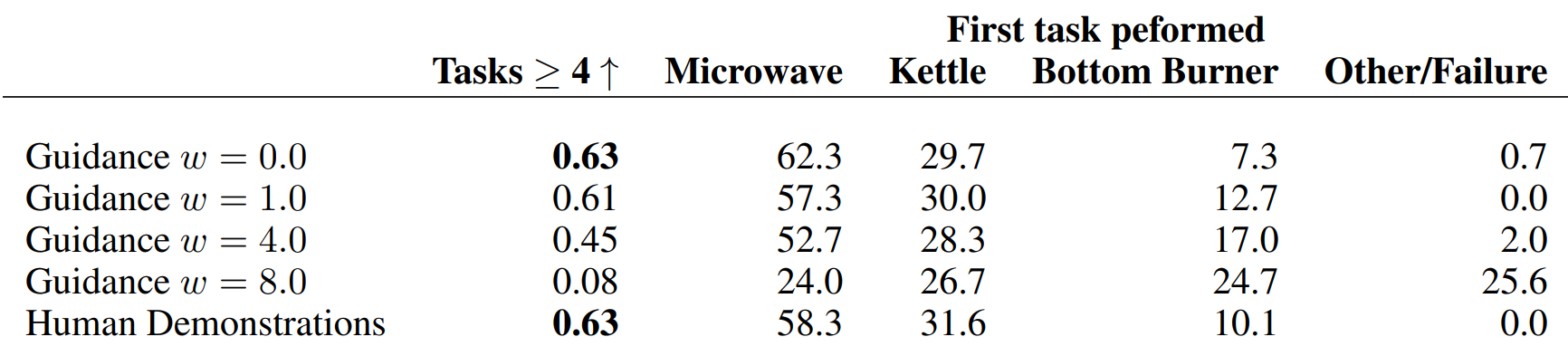
Guidance가 없을 때($w = 0$)보다 강력한 guidance가 있을 때 ($w = 8$) 완료율이 크게 떨어지는 것을 볼 수 있다. 한편, CFG는 첫번째 task로 Bottom Burner를 선택하는 데 강한 bias를 생성한다. 이는 인간 시연자가 시간의 10%만 Bottom Burner를 선택하지만 CFG가 강해지면 25%까지 증가하여 CFG가 덜 일반적인 궤적을 권장함을 보여준다.
2. Modelling Human Gameplay in a Video Game
저자들은 추가로 ‘Counter-Strike: Global Offensive’ (CSGO) 환경에서 본 논문의 모델을 테스트하였다. 저자들은 ‘aim train’ 환경을 사용하였다. ‘aim train’ 환경은 플레이어가 맵 중앙의 플랫폼에 고정되어 있으며 플레이어를 향해 돌진하는 AI 적으로부터 자신을 방어해야 한다. 성공하려면 혼합된 연속 및 불연속 action space에 대한 정확하고 조정된 제어뿐만 아니라 대상 선택 및 조준에서 multimodality를 처리해야 한다.
데모 데이터셋에는 숙련된 인간 플레이어가 기록한 45,000개의 observation/action 튜플이 포함되어 있다. 관찰은 280$\times$150 RGB 이미지이고 action space는 3차원(마우스 x $\in \mathbb{R}$, 마우스 y $\in \mathbb{R}$, 좌클릭 \(\in \{0, 1\}\))이다. 환경은 고정 속도로 비동기식으로 실행되어 모델의 샘플링 속도에 대한 엄격한 테스트를 제공한다. 이러한 제약으로 인해 저자들은 inference 속도와 성능 사이에 적절한 균형을 제공하는 MLP Sieve 아키텍처만 테스트한다. 약간 느린 Diffusion-KDE 샘플링 방법도 제외한다. $T$는 20으로 설정되었다.
다음은 10분의 rollout을 평균한 결과이다.
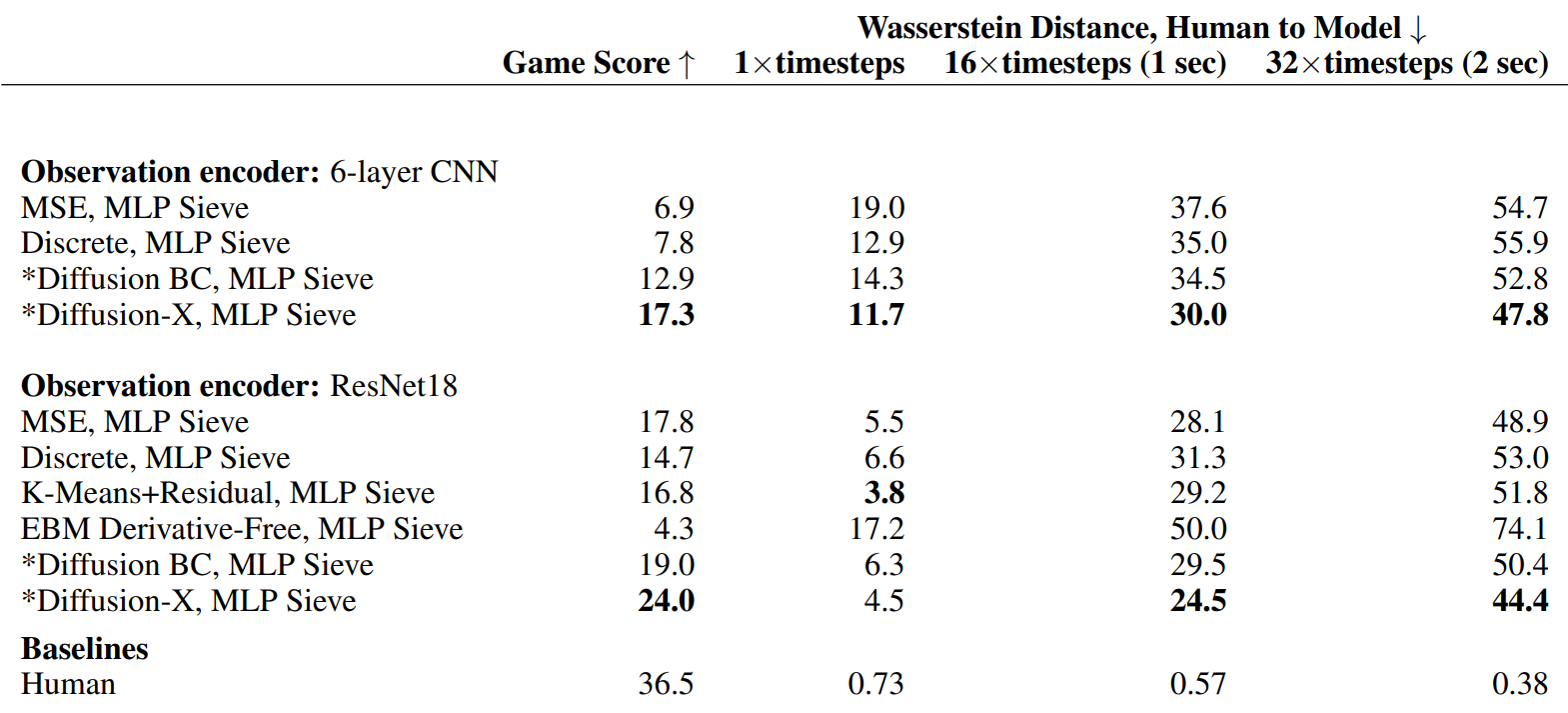
Diffusion-X는 예측된 action에 대한 Wasserstein 거리로 측정된 인간 분포에 대한 거리와 게임 점수 측면에서 observation 인코더 모두에서 가장 잘 수행되었다. MSE가 200Hz로 실행된 것에 비해 Diffusion-X는 18Hz로 실행되었다. 학습 시간은 비슷하다고 한다.