[논문리뷰] Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
arXiv 2023. [Paper] [Page]
Michał Stypułkowski, Konstantinos Vougioukas, Sen He, Maciej Zięba, Stavros Petridis, Maja Pantic
University of Wrocław | Imperial College London | Wrocław University of Science and Technology | Tooploox
6 Jan 2023
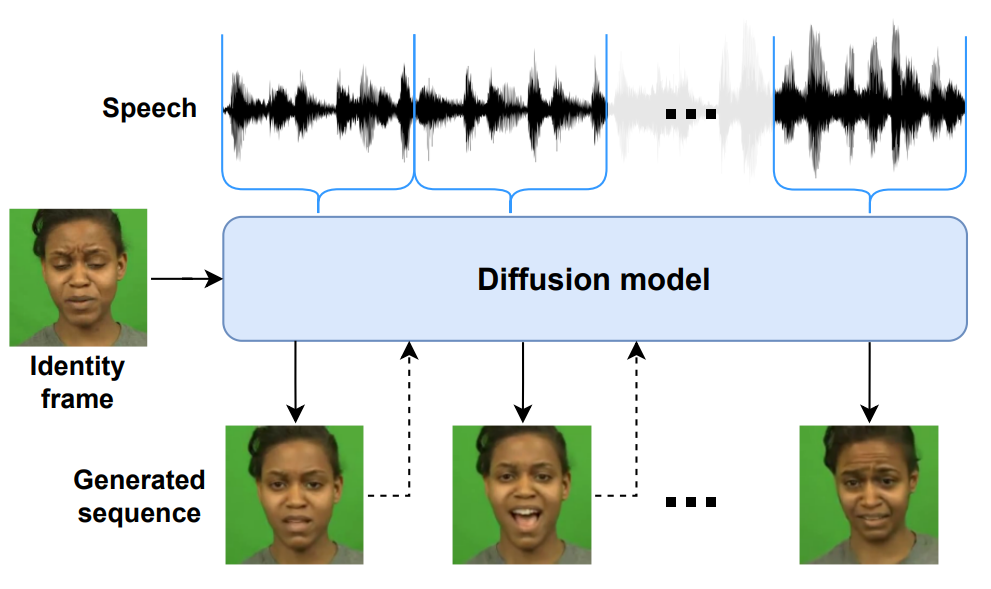
Introduction
음성으로 얼굴의 애니메이션을 생성하는 것은 연결 상태가 좋지 않은 가상 통화 중의 동영상 압축부터 영화, 게임, VR 등의 엔터테인먼트 산업의 예술적인 애니메이션에 이르기까지 광범위한 적용이 가능하다. 그러나 이 task의 수많은 과제를 고려할 때 아직 완벽한 솔루션은 없다. 현재까지의 기존 방법은 생성 과정에서 추가 supervision이 필요하면서도 진정한 표정과 움직임을 유지하는 자연스러운 얼굴을 만드는 데 어려움을 겪고 있다.
GAN의 강력한 능력에도 불구하고 음성 기반 동영상 합성에 적용하는 데는 몇 가지 단점이 있다. 첫째, GAN 학습은 수렴하기 위해 광범위한 아키텍처 탐색과 매개변수 조정이 필요한 경우가 많아 악명이 높다. GAN 기반 얼굴 애니메이션 방법의 학습 안정성은 생성 프로세스를 guide하는 마스크 또는 driving 프레임과 같은 추가 guidance를 사용하여 향상될 수 있다. 그러나 이 방법은 얼굴 재연으로 모델을 제한하고 원래의 머리 움직임과 얼굴 표정을 생성하는 능력을 감소시킨다.
또한 GAN 학습은 종종 mode collapse로 이어질 수 있다. 즉, generator가 데이터 분포의 전체를 포괄하는 샘플을 생성할 수 없고 대신 몇 가지 고유한 샘플만 생성하도록 학습된다.
마지막으로 기존의 one-shot GAN 기반 솔루션은 특히 머리 움직임이 큰 동영상을 생성할 때 생성된 동영상에서 얼굴이 왜곡되는 문제가 있다. 이것은 few shot 접근 방식으로 전환하거나 ID 일관성을 유지하기 위한 oracle 역할을 하는 사전 학습된 얼굴 확인 모델에 의존하여 해결된다.
위의 모든 문제를 해결하여 하나의 ID 프레임과 음성 녹음만으로 사실적인 동영상을 생성하는 프레임 기반 diffusion model인 Diffused Heads를 제안한다. 생성된 머리는 피사체의 ID와 그럴듯한 립싱크를 유지하면서 자연스럽게 움직이고 행동한다. 가장 최근의 접근 방식과 달리 저자들은 적대적 학습 대신 discriminator를 안정화할 필요가 없는 DDPM을 사용한다. 부자연스럽게 보이는 문제를 제거하기 위해 동영상 생성을 반복적으로 guide하는 motion frame을 도입했다. 음성과 생성된 프레임 간의 일관성을 유지하기 위해 새로운 컨디셔닝 접근 방식을 통해 모델에 삽입된 motion audio embedding을 사용한다고 가정한다. 마지막으로 사전 학습된 oracle 모델을 사용하는 대신 입술 움직임의 일관성을 유지하기 위해 손실 함수를 간단하게 수정했다.
Method
Diffused Heads는 전체 생성 프로세스 동안 고정된 ID 프레임과 사전 학습된 오디오 인코더를 사용하여 내장된 음성 녹음을 통해 한 번에 하나의 프레임을 생성한다. 보다 부드럽고 표현력 있는 결과를 얻기 위해 motion frame과 motion audio embedding을 도입하여 과거 움직임과 미래 표현에 대한 추가 정보를 주입한다. 또한 추가 립싱크 손실 함수를 정의하여 모델이 입 부분에 더 많은 주의를 기울이도록 한다.
1. Training
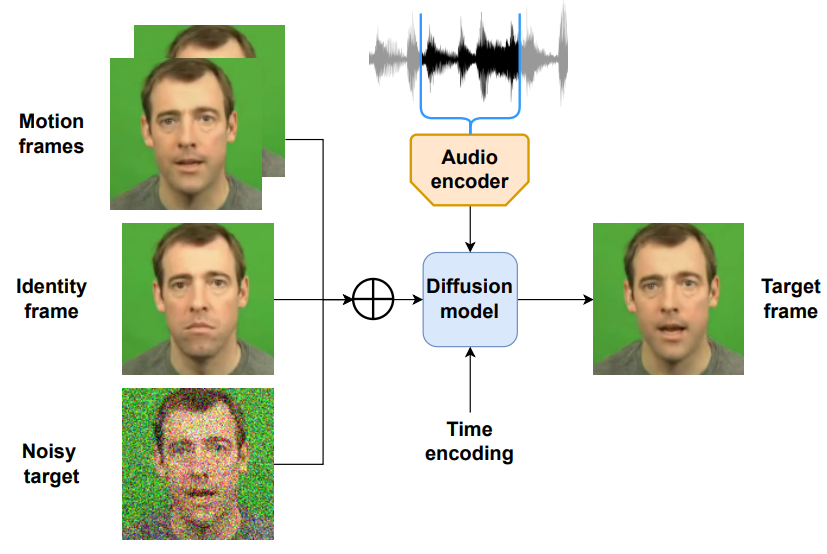
동영상에서 추출한 프레임의 분포를 diffusion model이 학습한다. 학습 과정은 위 그림과 같다. 학습 데이터셋에서 랜덤하게 동영상 \(X = \{x^{(1)}, \cdots, x^{(n)}\}\)을 뽑는다. 그런 다음 forward process로 noise를 추가하여 $x_t^{(k)}$를 얻는다. ID를 유지하기 위하여 $x_t^{(k)}$에 ID frame $x_{Id}$를 channel-wise하게 concat한다.
$x_{Id}$는 $X$에서 랜덤하게 선택된다. ID 프레임을 $x^{(0)}$로 뽑는 대신 랜덤하게 뽑으면 모델이 다양한 프레임을 입력으로 받을 수 있어 결과적으로 생성의 견고성이 개선된다.
시간적 정보를 추가하기 위하여 오디오 시퀀스를 동영상의 프레임 수와 동일하게 나눈다. 그런 다음 LRW 데이터셋에서 사전 학습된 오디오 인코더를 사용하여 오디오를 오디오 임베딩 \(Y = \{y^{1}, \cdots, y^{(n)}\}\)으로 인코딩한다.
2. Motion frames
오디오 인코더를 통해 모델에 시간 정보를 제공하더라도 부드러운 영상을 생성하기에는 역부족이다. 이 문제를 극복하고 움직임을 보존하기 위하여, $x^{(k)}$에 대한 motion frame
\[\begin{equation} x_{Motion}^{(k)} = x^{(k-m_x)} \oplus_c \cdots \oplus_c x^{(k-1)} \end{equation}\]을 도입한다. 여기서 $m_x$는 motion frame의 수이다. Ablation study를 통해 찾은 가장 좋은 $m_x$는 2이다.
$x^{(k)}$ 앞에 프레임이 충분하지 않은 경우 가장 자연스러운 선택은 나머지 motion frame을 x(0)의 복제본으로 채우는 것이다. 그러나 샘플링 중에는 ID 프레임을 제외하고 모든 ground-truth 프레임에 액세스할 수 없다. 또한 생성된 동영상이 ID 프레임에 주어진 정확한 얼굴 표정으로 시작하는 것을 원하지 않는다. 예를 들어, 오디오 녹음이 침묵으로 시작하는 데 ID 프레임의 사람이 이미 입을 벌리고 있는 경우 문제가 된다. 따라서 샘플 초기화 시 모델을 견고하게 만들기 위해 $x_{Id}$를 누락된 motion frame 대신 사용한다.
Motion frame은 channel-wise하게 concat되어 모델에 입력으로 주어진다.
\[\begin{equation} x_{In, t}^{(k)} := x_t^{(k)} \oplus_c x_{Id} \oplus_c x_{Motion}^{(k)} \end{equation}\]3. Speech conditioning
저자들은 AdaGN을 변형한 다음 식을 사용하여 오디오 임베딩의 정보를 주입하는 것을 제안한다.
\[\begin{equation} h_{s+1} = y_s^{(k)} (t_s \textrm{GN} (h_s) + t_b) + y_b^{(k)} \\ (t_s, t_b) = \textrm{MLP} (\psi (t)), \quad (y_s^{(k)}, y_b^{(k)}) = \textrm{MLP} (y^{(k)}) \end{equation}\]이 설정에서는 시간 인코딩뿐만 아니라 오디오 임베딩의 정보를 사용하여 U-Net의 hidden state를 shift하고 확장한다. 이 방법은 쿼리가 오디오 임베딩의 함수인 multi-head attention mechanism을 적용하는 것과 같은 다른 컨디셔닝 방법과 비교하여 더 잘 작동한다고 한다.
샘플링 중에 이미 처리된 프레임에만 사용할 수 있는 motion frame과 달리 전체 음성 녹음을 활용할 수 있다. 이를 위해 과거와 미래의 오디오 세그먼트에서 정보를 가져오는 motion audio embedding을 도입한다. 선택한 오디오 임베딩을 concat하여 생성한 벡터로 motion audio embedding을 정의한다.
\[\begin{equation} y_{Motion}^{(k)} = x^{(k - m_y)} \oplus_c \cdots \oplus_c x^{(k + m_y)} \end{equation}\]$m_y$는 한 쪽으로의 추가 오디오 임베딩의 수이다. Motion frame과 비슷하게, 만일 사용할 임베딩이 없다면 $y_{Motion}^{(k)}$를 $y^{(0)}$이나 $y^{(n)}$으로 채운다.
4. Lip sync loss
다른 방법들과 다르게 명시적인 손실 함수를 사용하여 생성된 샘플들의 립싱크를 더 좋게 만들지 않는다. 사전 학습된 동기화 모델이나 입술 읽기 모델을 기반으로 전용 perceptual loss를 사용하는 솔루션은 입술 동작 정확도를 개선하는 데 효과적이었지만 제안된 모델에는 두 가지 문제가 있다. 첫째, Diffusion Heads는 시퀀스가 아닌 프레임에서 작동하므로 시퀀스 기반 loss를 적용할 수 없다. 두 번째로 더 중요한 것은 difusion model 학습 중에 프레임에서 사용된 noise를 예측하는 것이 목표라는 것이다. Perceptual loss를 적용하는 데 필요한 $x_0$로 돌아가는 것은 단일 step에서 충분히 정확하지 않으며 더 많은 step을 사용한 계산적으로 비효율적이다.
저자들은 더 간단한 솔루션인 lip sync loss $L_{ls}$를 도입하였다. 학습 중에 얼굴 랜드마크를 활용하여 입 주위의 각 프레임을 자르고 이 영역에서 noise 예측을 최소화한다.
\[\begin{equation} L_{ls} := \mathbb{E}_{t, x_0, \epsilon} [\| \tilde{\epsilon} - \tilde{\epsilon}_\theta (x_t, t) \|_2^2 ] \end{equation}\]$\tilde{\epsilon}$와 $\tilde{\epsilon}_\theta$는 ground-truth noise와 예측된 noise의 잘린 버전이다. 이 과정은 아래 그림과 같다.

Lip sync loss를 사용하면 모델이 오디오 임베딩에 입술을 동기화하는 데 더 집중하며, 샘플링된 동영상의 전체적인 perception이 개선된다. $L_{ls}$는 상수 $\lambda_{ls}$를 가중치로 하며, 전체 목적 함수는 다음과 같다.
5. Sampling
샘플링의 경우 음성 녹음에서 추출한 ID 프레임과 오디오 임베딩만 필요하다. ID 프레임의 여러 복사본으로 $x^{(0)}$ 모션을 초기화하여 동영상 생성을 시작한다. 각 프레임은 변이 사후 확률에 의해 정의된 diffusion model의 표준 denoising process에 따라 샘플링된다. 모든 step이 끝나면 motion frame을 합성된 프레임으로 교체한다. $y_{Motion}^{(k)}$는 학습 중에 동일한 과정을 따른다.
단일 프레임 생성에는 모델이 모든 diffusion timestep에 대한 예측을 수행해야 하므로 상당한 시간이 걸린다. 속도를 높이려면 DDIM이나 timestep 간격 재지정과 같은 방법을 사용할 수 있다. 본 논문에서는 후자를 사용하여 샘플링 시간을 5배 줄인다.
저자들은 실험 중에 갑작스러운 머리 움직임을 생성할 때 모델이 때때로 실패하는 것을 관찰했다고 한다. 프레임별로 시퀀스를 합성하므로 발생하는 모든 오차는 이후 step에서 누적된다. 관련 문제 중 하나는 학습 중에 모든 motion frame이 데이터셋에서 나온다는 것이다. 한편, 생성 중에는 약간의 왜곡이 있는 이전에 샘플링된 프레임을 사용한다. 저자들은 이 설정을 통해 motion frame과 ID 프레임이 사람의 속성 추출 측면에서 똑같이 중요하다는 가설을 세웠다.
모델이 ID 프레임에서 사람의 외모에 대한 정보를 최대한 많이 가져오도록 하기 위해 각 motion frame을 grayscale로 변환한다. 이 이면에 있는 인사이트는 모델이 대신 모션 정보를 찾도록 밀어붙이면서 ID feature(ex. 색상)를 추출하는 것을 더 어렵게 만들어야 한다는 것이다. 이 솔루션은 보다 복잡한 데이터셋에서 잘 작동한다고 한다.
Experiments
- 데이터셋: CREMA, LRW
- Implementation Details
- 128$\times$128에서 학습.
- ADM의 U-Net 아키텍처 사용.
- 입력 block의 채널은 256-512-768. 각 block은 2개의 ResNet layer를 사용.
- 실험 초기에 더 많은 attention layer가 생성 품질을 떨어뜨리는 것을 발견하여 중간 block에만 head 4개, head channel 64개의 attention layer 사용.
1. Qualitative results
다음은 CREMA(위)와 LRW(아래) 데이터셋에 대한 결과이다. 빨간 테두리는 나머지 프레임을 생성하는 데 사용한 ID 프레임이다.

2. Quantitative results
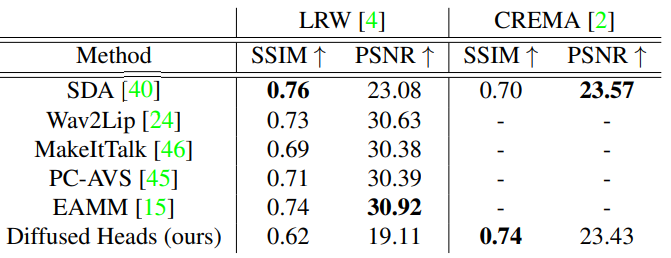
다음은 다른 방법들과의 비교 결과 표이다.
다음은 LRW 데이터셋에 대한 Turing test 결과이다.

저자들은 각 방법마다 10개의 동영상을 샘플링하고 실제 동영상 10개와 섞은 뒤 총 30개의 동영상을 140명에게 보여주었다. 동영상이 실제 동영상 같은 지 아닌지 투표하도록 하였다고 한다.
3. Ablation study
다음은 motion frame에 대한 ablation study 결과로, motion frame을 사용하지 않을 떄(위)와 2개의 motion frame을 사용할 때(아래)의 optical flow의 평균 magnitude와 연속 프레임이다.

Motion frame이 1일 때의 연속 프레임은 2일 때의 연속 프레임과 육안으로 보았을 때 큰 차이가 없어 포함하지 않았다고 한다.
다음은 LRW 데이터셋에서 motion audio embedding의 개수와 grayscale 적용 여부에 대한 ablation study 결과이다.
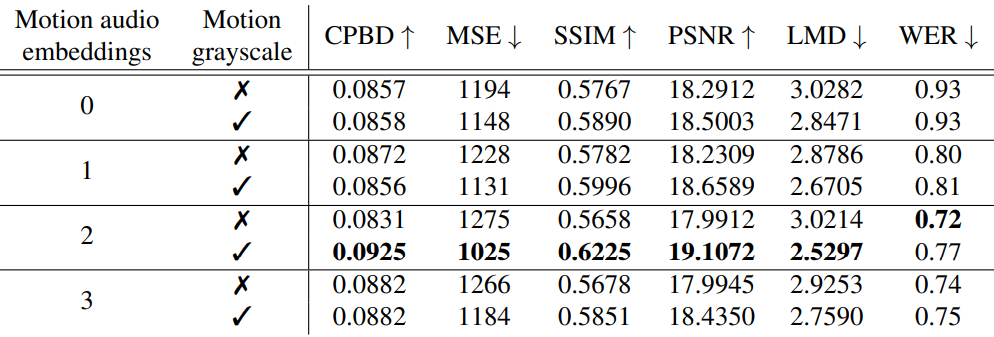
Grayscale 변환을 CREMA와 같은 다양성이 낮은 데이터셋에 사용하는 것은 도움이 되지 않는다고 한다. CREMA 데이터셋은 91명의 동영상만을 포함하기 때문에 새로운 얼굴에 대한 일반화가 어렵다. 그런 이유로 RGB motion frame을 사용하는 것이 ID 프레임과 motion frame에서 더 많은 정보를 얻을 수 있다.
5. Generalization
딥러닝에서 중요한 과제 중 하나는 모델이 보지 못한 데이터를 잘 일반화하는 능력을 가지는 것이다. Diffused Heads의 일반화 능력을 보기 위하여 저자들은 실험을 진행하였고, 그 결과는 아래와 같다.

위에서 부터 영어/여성, 한국어/여성, 독일어/남성, 영어/남성의 오디오 녹음으로 생성한 동영상의 프레임들이다. 위의 2줄은 CREMA로 학습하였으며, 나머지 2줄은 LRW로 학습한 것이다.
6. Limitations
Diffused Heads가 state-of-the-art 성능을 달성했음에도 불구하고 여전히 몇 가지 제한 사항이 있다. 주요 문제는 생성된 비디오의 길이이다. 머리 움직임에 대한 추가 포즈 입력이나 시각적 안내를 제공하지 않고 모델이 autoregressive하게 프레임을 생성하기 때문에 더 긴 시퀀스에 대해 초기 품질을 유지하지 못한다. 또한 diffusion model은 다른 생성 모델에 비해 생성 시간이 길다는 단점이 있다. 지금은 이론적으로 적합하더라도 실시간 응용 프로그램에서 본 논문의 접근 방식을 사용할 수 없다. 말하는 얼굴 생성 task에 적합한 새로운 메트릭도 open problem이다.