[논문리뷰] DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
ICLR 2025. [Paper] [Page] [Github]
Chenguo Lin, Panwang Pan, Bangbang Yang, Zeming Li, Yadong Mu
Peking University | ByteDance
28 Jan 2025
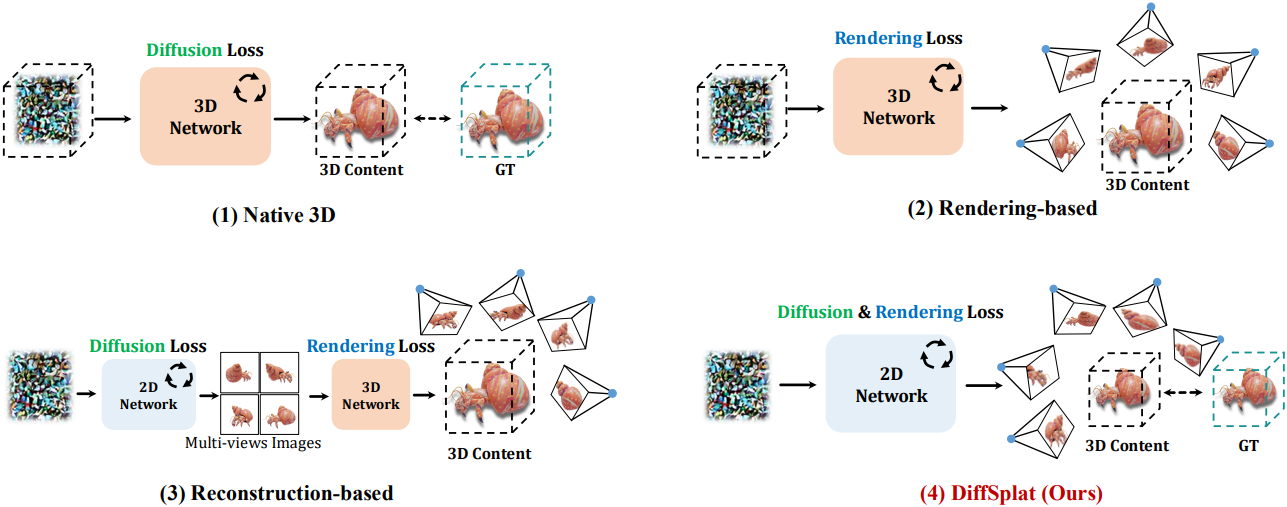
Introduction
Diffusion model의 개발로 최근 연구들은 다양한 3D 표현의 데이터셋에서 직접 3D 생성 네트워크를 학습시키거나, 미분 가능한 렌더링 기술의 도움으로 2D에서만을 학습시켰다. 이러한 모델들은 3D 일관성을 가지지만, 학습 스케일에 의해 제한을 받으며 사전 학습된 모델의 2D prior를 활용할 수 없다. 최신 방법들은 사전 학습된 2D diffusion model로 생성한 멀티뷰 이미지에서 3D 표현을 재구성한다. 이러한 2단계 방법은 멀티뷰 이미지에서 고품질 3D 콘텐츠를 재구성할 수 있지만, 2D diffusion model에서 생성된 이미지의 품질이 좋지 않거나 일관성이 없는 경우 신뢰할 수 있는 결과를 생성하지 못한다.
이전 연구들의 단점을 극복하기 위해, 본 논문은 멀티뷰 일관성을 보이고 대규모 이미지 데이터셋의 generative prior를 효과적으로 활용하는 새로운 3D 생성 프레임워크인 DiffSplat을 제시하였다. DiffSplat은 효율적인 렌더링과 품질 균형을 위해 3D 표현으로 3D Gaussian Splatting (3DGS)을 사용한다.
학습을 위한 3D 데이터셋을 얻기 위해, 시간이 많이 걸리는 인스턴스별 최적화에 의존하는 대신, 잘 구성된 splat 2D grid로 3D 물체를 표현한다. 이러한 그리드는 0.1초 이내에 멀티뷰 이미지에서 즉시 예측되어 scalable하고 고품질의 3D 데이터셋 큐레이션을 용이하게 한다. 2D 그리드의 각 Gaussian splat은 물체의 텍스처와 구조를 암시하는 속성을 보유한다. 웹스케일의 데이터셋으로 학습된 이미지 diffusion model이 3D 구조 추정이 가능하다는 점을 감안하여, 재구성된 Gaussian splat 2D 그리드를 특수 스타일의 이미지로 처리하면 사전 학습된 2D diffusion model의 힘을 활용해 직접 3DGS를 생성할 수 있다.
구체적으로, 웹스케일 이미지 데이터셋에서 학습된 latent diffusion model은 3D 콘텐츠 생성을 위한 Gaussian splat의 속성을 직접 생성하는 데 재활용된다. 재구성된 splat grid가 이미지 diffusion model의 입력 latent와 동일한 모양을 갖도록 하기 위해, VAE를 fine-tuning하여 Gaussian splat 속성을 유사한 latent space로 압축한다. 이를 splat latent라고 한다.
학습하는 동안, 일반적인 이미지 diffusion model과 유사한 diffusion loss 외에도, 생성 모델이 3D 공간에서 작동하고 3D 일관성을 용이하게 하기 위해 렌더링 loss를 통합한다. Gaussian splat 속성은 네트워크에서 처리되고 임의의 뷰에서 미분 가능하게 렌더링될 수 있기 때문이다. 또한, 아키텍처에 대한 최소한의 수정 덕분에 다양한 사전 학습된 text-to-image diffusion model을 DiffSplat의 base model로 사용할 수 있다.
Method
1. Data Curation: Structured Splat Reconstruction
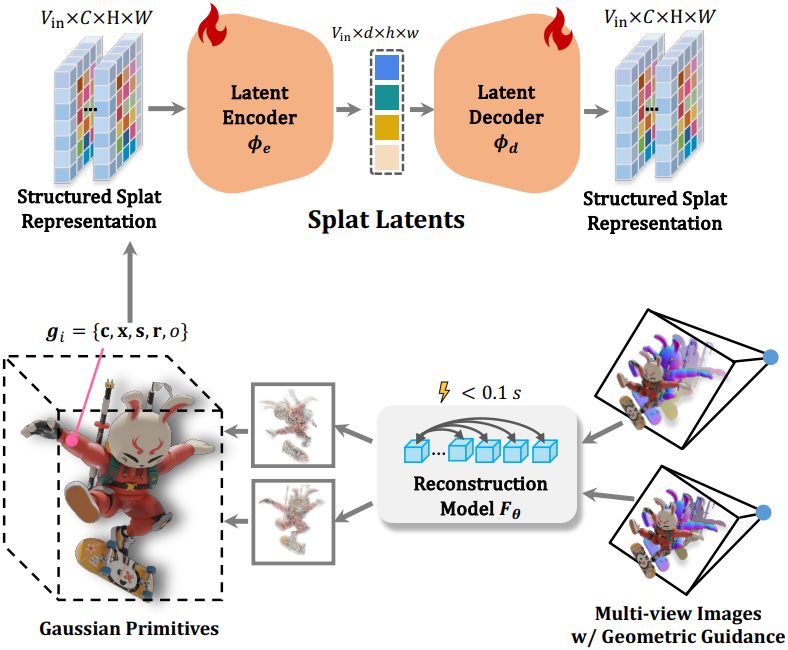
DiffSplat은 구조화된 멀티뷰 Gaussian splat grid 세트를 사용하여 3D 물체를 표현한다. 구체적으로, \(\textrm{V}_\textrm{in}\)개의 이미지가 주어지면, 작은 네트워크 $F_\theta$는 0.1초 이내에 이미지들에서 픽셀별 splat을 예측할 수 있으며, 렌더링 loss \(\mathcal{L}_\textrm{render}\)에 의해 학습된다.
여기서 $I_v$와 $M_v$는 각각 RGB 이미지와 실루엣 마스크로, 예측된 3D Gaussian \(\mathcal{G} = \{\textbf{g}_i\}_{i=1}^N\)에서 rasterization을 통해 $V$개의 무작위 시점에서 미분 가능하게 렌더링되었으며, $N = V_\textrm{in} \times H \times W$이다.
각 Gaussian \(\textbf{g}_i \in \mathbb{R}^{12}\)는 RGB 색상 $\textbf{c} \in \mathbb{R}^3$, 위치 $\textbf{x} \in \mathbb{R}^3$, scale $\textbf{s} \in \mathbb{R}^3$, rotation quaternion $\textbf{r} \in \mathbb{R}^4$, 불투명도 $o \in \mathbb{R}$로 parameterize된다. 이를 단순화하고 Gaussian의 분포를 조절하기 위해 위치 $\textbf{x}$는 깊이 $d \in \mathbb{R}$, intrinsic $\textbf{K} \in \mathbb{R}^{3 \times 3}$, extrinsic $[\textbf{R} \vert \textbf{t}]$에 의해 결정된다.
\[\begin{equation} \textbf{x} = \textbf{R}^\top \textbf{K}^{-1} [\textbf{u} \vert d] - \textbf{t} \end{equation}\]($\textbf{u} \in \mathbb{R}^2$는 homogeneous 픽셀 좌표)
Diffusion 기반 생성을 준비하기 위해 Gaussian splat 속성의 값을 제한하여야 한다. 이를 위해 $F_\theta$의 출력은 $\textbf{r}$을 제외하고 모두 시그모이드 함수 $\sigma (\cdot)$를 통과한다. $\textbf{r}$은 unit quaternion이 되도록 L2-norm을 적용한다. RGB 색상 $c$와 불투명도 $o$는 이미 $[0, 1]$에 있다. Scale $\hat{\textbf{s}}$는 사전 정의된 값 \(s_\textrm{min}\)과 \(s_\textrm{max}\)로 linear interpolation된다.
\[\begin{equation} \textbf{s} = s_\textrm{min} \cdot \sigma (\hat{\textbf{s}}) + s_\textrm{max} \cdot (1 - \sigma (\hat{\textbf{s}})) \end{equation}\]깊이 $\hat{d}$는 이미지 평면을 기준으로 정의되며, 데이터셋의 물체는 $[-1, 1]^3$ 큐브로 정규화될 수 있다.
\[\begin{equation} d = 2 \cdot \sigma (\hat{d}) - 1 + \| \textbf{t} \|_2 \end{equation}\]멀티뷰 RGB 이미지 외에도, 보조 기하학적 가이드를 위한 추가 입력으로 coordinate map과 normal map을 통합한다. 이러한 추가 입력은 Gaussian splat grid의 재구성 품질을 향상시키는 데만 사용되며 생성 단계에서는 필요하지 않다.
2. Splat Latents
앞서 언급한 설계는 이미지와 같은 처리를 위해 멀티뷰 splat grid \(\mathcal{G} = \{\textbf{G}_i\}_{i=1}^{V_\textrm{in}}\)을 사용하여 3D 물체를 고품질로 표현할 수 있도록 한다. Gaussian splat grid를 이미지 diffusion model의 latent space로 인코딩하기 위해 가장 간단한 아이디어는 이를 RGB 이미지에 대한 3개 채널이 있는 여러 feature 그룹으로 분할하고, 이를 개별적으로 처리하는 것이지만, 오토인코딩 품질이 좋지 않다.
대신, 저자들은 사전 학습된 입력 및 출력 convolution 가중치의 열과 행을 각각 4번 복제하여 Gaussian splat grid \(\textbf{G}_i \in \mathbb{R}^{12 \times H \times W}\)의 feature 차원과 일치시켰다. 그런 다음 latent diffusion model의 VAE를 fine-tuning하여 reconstruction loss와 렌더링 loss를 모두 고려하여 각 Gaussian splat grid를 독립적으로 오토인코딩한다.
\[\begin{equation} \mathcal{L}_\textrm{VAE} = \frac{1}{V_\textrm{in}} \sum_{v=1}^{V_\textrm{in}} \left( \mathcal{L}_\textrm{MSE} (\tilde{\textbf{G}}_i, \textbf{G}_i) \right) + \lambda_r \cdot \mathcal{L}_\textrm{render} (\tilde{\mathcal{G}}) \end{equation}\](\(\tilde{\textbf{G}}_i = D_{\phi_d} (E_{\phi_e} (\textbf{G}_i))\)는 VAE의 인코더 \(E_{\phi_e}\)와 디코더 \(D_{\phi_d}\)에 의해 오토인코딩된 \(\textbf{G}_i\))
\(V_\textrm{in}\)개의 입력 뷰에 대해 인코딩된 Gaussian splat grid \(\textbf{z} = \{\textbf{z}_i\}_{i=1}^{V_\textrm{in}} = \{\textbf{z}_i\}_{i=1}^{V_\textrm{in}}\)는 splat latent라고 하며, diffusion process와 denoising process를 거친다.
3. DiffSplat Generative Model
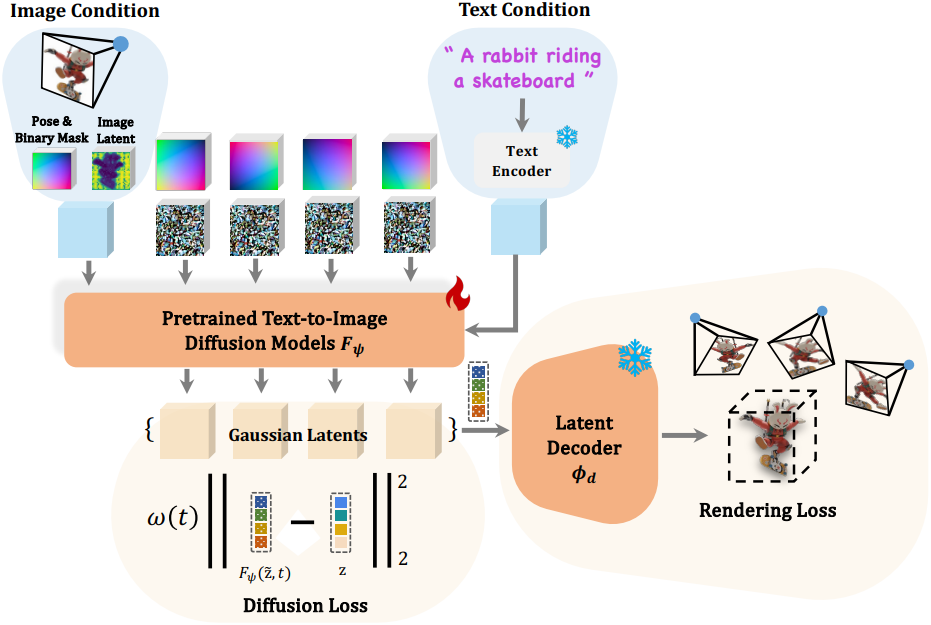
Model Architecture
2D 그리드로 구성된 멀티뷰 splat latent 이미지 세트 \(\textbf{z} = \{\textbf{z}_i\}_{i=1}^{V_\textrm{in}}\)가 주어졌을 때, 멀티뷰 이미지 생성 방법 두 가지를 살펴보자. 이 방법은 텍스트 프롬프트나 단일 뷰 이미지에서 $\textbf{z}$를 전체로 동시에 생성하는 것으로, 각각 view-concat과 spatial-concat이라고 한다.
View-concat 방식의 경우, 각각 모양이 \(\mathbb{R}^{d \times h \times w}\)인 \(V_\textrm{in}\)개의 splat latent들은 동영상 프레임처럼 처리되고 뷰 차원을 따라 \(\mathbb{R}^{V_\textrm{in} \times d \times h \times w}\)로 concat되어 denoising network에서 개별적으로 처리된다. 다만, self-attention 모듈에서는 \(\mathbb{R}^{(V_\textrm{in} \cdot h \cdot w) \times d}\)로 reshape되고 정수 시퀀스로 처리된다.
Spatial concat 방식의 경우, splat latent들은 $r \times c$ 그리드로 구성되어 \(\mathbb{R}^{d \times (r \cdot h) \times (c \cdot w)}\) 모양이 되며, $r \times c = V_\textrm{in}$이다.
두 방식 모두 Plücker embedding을 splat latent들과 함께 feature 차원을 따라 concat하여 상대적 카메라 포즈를 dense하게 인코딩한다. 이는 시점 선택의 유연성을 높이고 멀티뷰 데이터셋에 대한 요구 사항을 줄인다. 사전 학습된 모델에 도입된 유일한 새로운 파라미터는 Plücker embedding을 위한 입력 convolution 가중치의 0으로 초기화된 새로운 열이다. 이러한 모델 디자인은 다양한 text-to-image diffusion model에 대한 최소한의 수정과 일반화를 가능하게 한다.
멀티뷰 이미지 diffusion model과 달리 텍스트 조건부 DiffSplat의 경우 입력 조건(픽셀)과 생성된 출력(splat 속성)이 다른 도메인에 있기 때문에 이미지 조건 생성을 위해 입력 이미지 뷰를 제외한 다른 뷰의 noise를 간단히 제거하는 것은 불가능하다. View-concat의 경우 원래 VAE 인코딩된 입력 이미지가 뷰 차원을 따라 concat되고, 이미지와 splat latent를 구별하기 위해 feature 차원을 따라 추가적인 바이너리 마스크가 concat된다. Spatial-concat의 경우 입력 이미지에 빈 배경을 패딩하여 $r \times c$ 그리드를 형성한 다음 이미지 VAE 인코딩 후 feature 차원을 따라 concat된다.
Training Objectives
DiffSplat $F_\psi$는 diffusion loss \(\mathcal{L}_\textrm{diff}\)로 학습할 수 있으며, 이는 무작위로 샘플링된 noise level $t$로 손상된 splat latent $\tilde{\textbf{z}}$의 noise를 제거하는 것을 목표로 한다.
\[\begin{equation} \mathcal{L}_\textrm{diff} = \omega (t) \cdot \| F_\psi (\tilde{\textbf{z}}, t) - \textbf{z} \|_2^2 \end{equation}\]그러나 \(\mathcal{L}_\textrm{diff}\)로만 최적화하는 것은 3D 일관성을 보장하지 않는다. 이러한 제한은 모델이 본질적으로 Gaussian splat grid의 2D 공간에서 작동하고 $V_\textrm{in}$개의 뷰 사이의 대응 관계가 원래 단일 뷰 이미지에서 학습된 이미지 diffusion model의 fine-tuning 중에 암시적으로 학습되기 때문에 발생한다. 따라서 3D 일관된 학습을 위한 fine-tuning 프로세스가 덜 간단해진다. 또한 가벼운 재구성 모델 이후에 압축된 ground-truth 샘플로 splat latent들을 처리하는 것도 생성 모델의 상한을 제한한다. 실제 멀티뷰 데이터셋이 학습 프로세스에 관여하지 않고 재구성 및 오토인코딩 모델의 결과에 완전히 의존하기 때문이다.
Diffusion process에서 splat latent들이 픽셀이 아니라 임의의 뷰에서 효율적으로 렌더링할 수 있는 자연스러운 3D 표현으로 처리되기 때문에, 추가 렌더링 loss \(\lambda_\textrm{render}\)를 \(\mathcal{L}_\textrm{diff}\)와 함께 통합하고, denoise된 splat latent들을 Gaussian splat 속성으로 다시 디코딩한 후 $V$개의 무작위 시점에서 렌더링하여 ground-truth 멀티뷰 이미지와 비교한다. 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{DiffSplat} = \lambda_\textrm{diff} \cdot \mathcal{L}_\textrm{diff} + \lambda_\textrm{render} \cdot \omega_r (t) \cdot \mathcal{L}_\textrm{render} (D_{\phi_d} (F_\psi (\tilde{\textbf{z}}, t))) \end{equation}\](\(\omega_r (t)\)는 다양한 noise level $t$에서의 렌더링 loss의 가중치 항)
특히, \(\lambda_\textrm{diff} = 0\)으로 설정하면 DiffSplat은 효과적으로 렌더링 기반 모델이 되지만 픽셀 대신 splat latent들을 denoise한다. 반면, \(\lambda_\textrm{render} = 0\)으로 설정하면 DiffSplat은 splat latent들을 ground-truth 3D 표현으로 취급하여 native 3D 모델이 된다.
Experiments
- 데이터셋: G-Objaverse
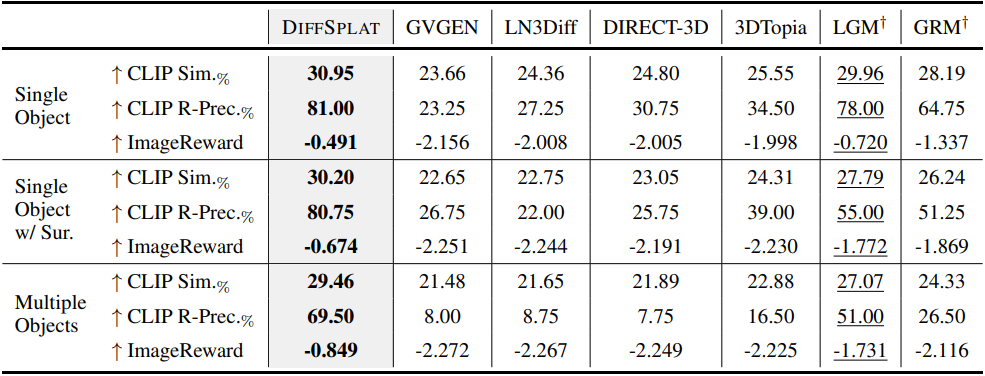
1. Text-conditioned Generation
다음은 텍스트 조건부 생성에 대한 비교 결과이다.

2. Image-conditioned Generation
다음은 이미지 조건부 생성에 대한 비교 결과이다.


3. Application: Controllable Generation
다음은 ControlNet으로 text-to-3D 생성을 제어한 예시들이다.

4. Ablation
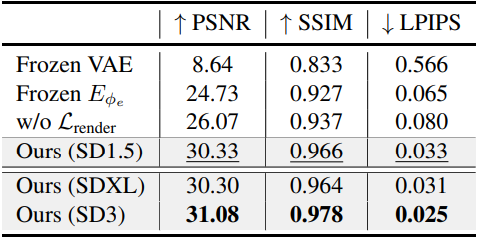
다음은 (왼쪽) 구조화된 splat 재구성과 (오른쪽) 오토인코딩 전략에 대한 ablation 결과이다.

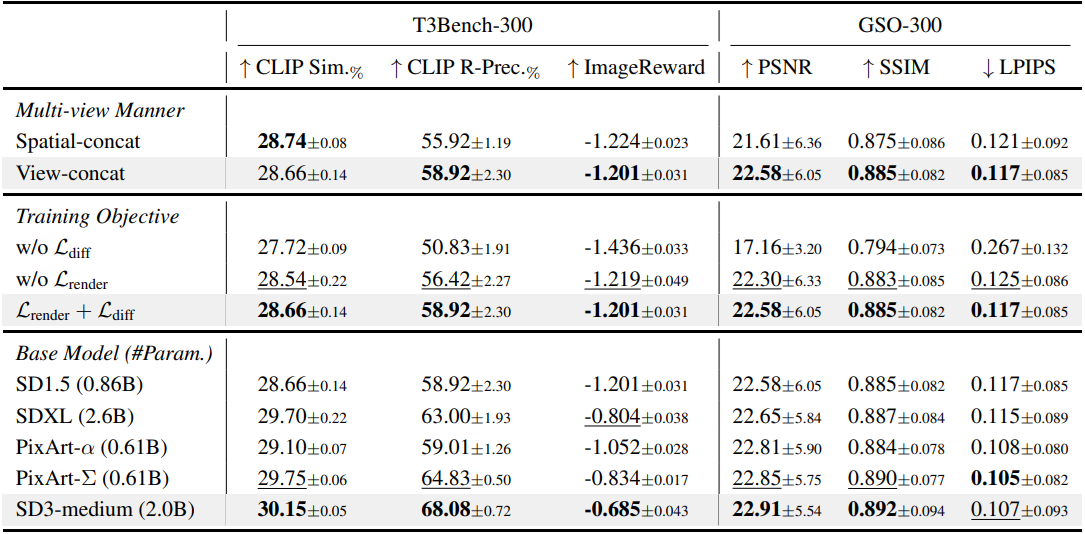
다음은 디자인 선택에 대한 ablation 결과이다.
다음은 \(\mathcal{L}_\textrm{render}\)에 대한 ablation 결과이다.

다음은 splat latent들을 시각화한 것이다.
