[논문리뷰] DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
AAAI 2022. [Paper] [Github]
Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, Peng Liu, Zhou Zhao
Zhejiang University
6 May 2021
Introduction
Singing voice synthesis (SVS)는 악보로부터 자연스럽고 표현력 있는 노래하는 음성을 합성하는 것이 목표이다. SVS의 파이프라인은 일반적으로 악보를 조건으로 하여 음향 feature들을 생성하는 음향 모델과 음향 feature들을 waveform으로 변환하는 vocoder로 구성된다.
기존의 노래하는 음향 모델은 L1이나 L2 같은 간단한 loss로 음향 feature들을 재구성하였다. 반면 이 최적화는 부정확한 unimodal 분포 가정을 기반으로 하므로 흐릿하고 over-smoothing된 출력을 만든다. 기존 방법은 GAN으로 이 문제를 해결하려고 노력하지만, 불안정한 discriminator로 인해 효과적인 GAN 학습이 때때로 실패할 수 있다. 이러한 문제는 합성된 노래의 자연스러움을 방해한다.
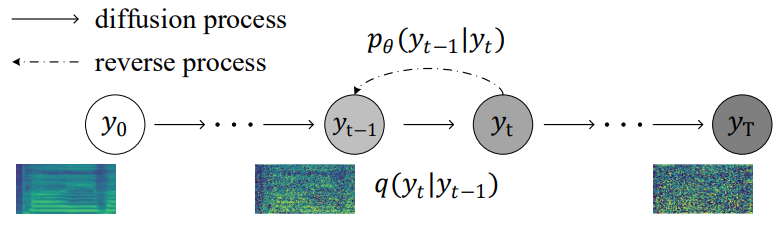
최근에는 매우 유연하고 tractable한 생성 모델인 diffusion model이 등장하였다. Diffusion model은 diffusion process와 reverse process (denoising process)의 두 과정으로 구성된다. Diffusion process는 가우시안 noise를 점진적으로 추가하여 복잡한 데이터를 등방성 가우시안 분포로 변환하는 Markov chain이다. Reverse process는 반복적으로 가우시안 noise에서 원본 데이터를 복원하는 방법을 학습하는 신경망에 의해 구현된 Markov chain이다. 데이터 likelihood에 대한 variational lower bound (ELBO)를 최적화하여 diffusion model을 안정적으로 학습시킬 수 있다. Diffusion model은 이미지 생성과 신경 vocoder 분야에서 유망한 결과를 생성할 수 있음이 입증되었다.
본 논문에서는 diffusion model을 기반으로 하는 SVS를 위한 음향 모델인 DiffSinger을 제안한다. DiffSinger은 악보를 조건으로 하여 noise를 mel-spectrogram으로 변환한다. DiffSinger은 ELBO를 최적화하여 효율적으로 학습시킬 수 있으며 ground truth 분포와 강하게 일치하는 사실적인 mel-spectrogram을 생성할 수 있다.
음성 품질을 더욱 개선하고 inference 속도를 높이기 위해 단순한 loss로 학습된 사전 지식을 더 잘 활용해야 하며, 이를 위해 shallow diffusion mechanism을 도입했다. 구체적으로, 저자들은 ground-truth mel-spectrogram $M$의 diffusion 궤적과 간단한 mel-spectrogram 디코더 $\tilde{M}$에 의해 예측된 diffusion 궤적의 교차점이 있음을 발견했다. 즉, diffusion step이 충분히 클 때 $M$과 $\tilde{M}$이 diffusion process를 거치면 비슷하게 왜곡된 mel-spectrogram이 나올 수 있으며, 왜곡된 mel-spectrogram이 가우시안 noise가 되는 깊은 단계에 도달하지는 않는다.
따라서 inference 단계에서 저자들은
- 간단한 mel-spectrogram 디코더를 활용하여 $\tilde{M}$을 생성하고
- Diffusion process를 통해 얕은 단계 $k$에서 샘플 $\tilde{M}_k$를 계산하고
- 가우시안 noise가 아닌 $\tilde{M}_k$에서 diffusion process를 시작하고 $k$번의 denoising step을 반복하여 process를 완료한다.
추가로 저자들은 경계 예측 (boundary predictor) 신경망을 학습시켜 이 교차점을 찾고 적응적으로 $k$를 결정한다. Shallow diffusion mechanism은 가우시안 noise보다 더 나은 시작점을 제공하고 reverse process의 부담을 완화하여 합성된 오디오의 품질을 향상시키고 inference를 가속화한다.
또한 SVS의 파이프라인은 TTS task와 유사하므로 일반화를 위해 DiffSinger를 조정하여 DiffSpeech도 만들 수 있다.
Diffusion model
DDPM 논문리뷰 참고
DiffSinger
1. Naive Version of DiffSinger
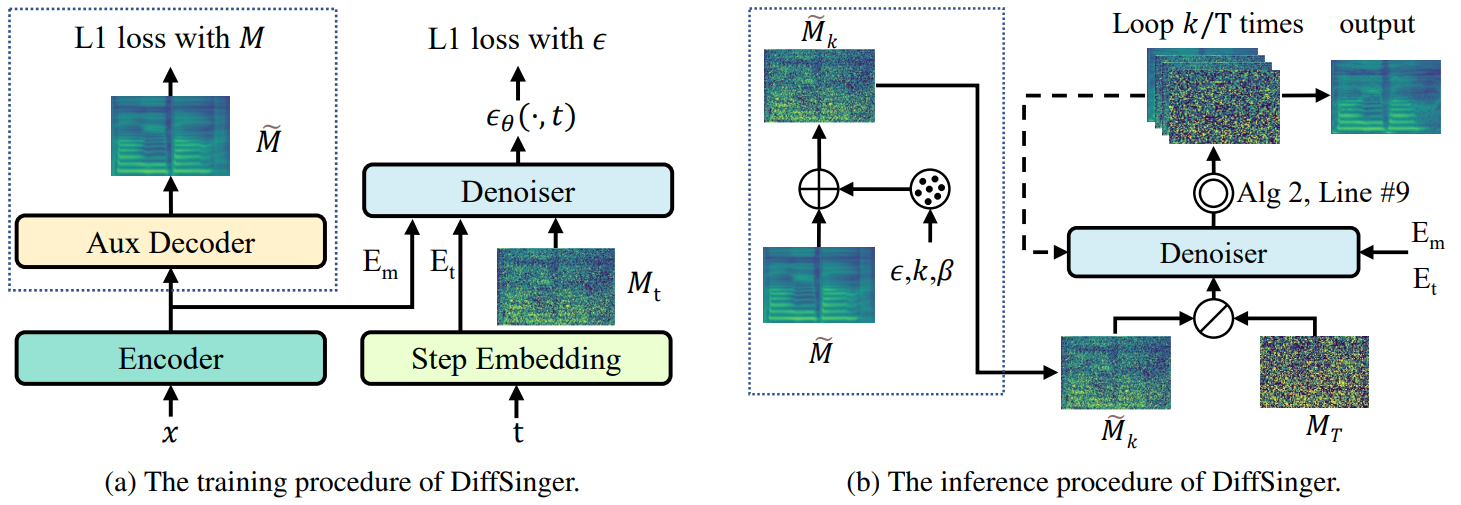
위 그림에서 점선 박스를 제외한 부분이 naive한 버전의 DiffSinger이다. 학습 과정에서 DiffSinger는 $t$번째 step의 mel-spectrogram $M_t$를 입력받아 $t$와 악보 $x$를 조건으로 추가된 random noise $\epsilon_\theta$를 예측한다. Inference 과정은 기존 diffusion model과 같이 $\mathcal{N}(0,I)$에서 샘플링한 가우시안 noise에서 시작하여 다음과 같이 중간 샘플을 denoising하는 것을 $T$번 반복한다.
- Denoiser로 $\epsilon_\theta$를 예측한다.
- 예측한 $\epsilon_\theta$를 사용하여 다음 식으로 $M_t$에서 $M_{t-1}$을 얻는다.
여기서 $t > 1$일 때 $z \sim \mathcal{N} (0,I)$이고 $t = 1$일 때 $z = 0$이다. 최종적으로 $x$에 대응되는 mel-spectrogram $M$이 생성된다.
2. Shallow Diffusion Mechanism
단순한 loss에 의해 학습된 이전 음향 모델에는 tractable하지 않은 단점이 있지만 여전히 DiffSinger에 많은 사전 지식을 제공할 수 있는 ground-truth 데이터 분포에 대한 강력한 연결을 보여주는 샘플을 생성한다. 이 연관성을 탐색하고 사전 지식을 더 잘 활용할 수 있는 방법을 찾기 위해 다음 그림과 같이 diffusion process를 활용한 경험적 관찰을 할 수 있다.
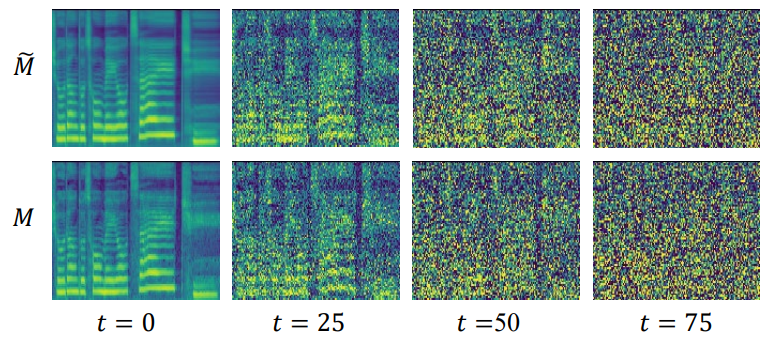
- $t = 0$일 때 $M$은 이웃한 고조파(harmonic) 사이의 풍부한 디테일을 가지며, 이는 합성된 노래하는 음성의 자연스러움에 영향을 준다. 반면, $\tilde{M}$은 over-smoothing된다.
- $t$가 증가함에 따라 두 process의 샘플들은 구분할 수 없게 된다.
이러한 관찰 결과에서 영감을 받아 저자들은 shallow diffusion mechanism을 제안한다. Shallow diffusion mechanism은 가우시안 noise에서 reverse process를 시작하는 대신 다음 그림과 같이 두 궤적의 교차점에서 시작한다.
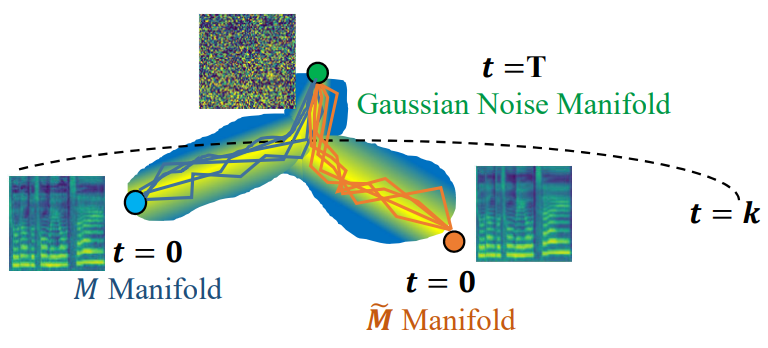
$M_T$를 $M_0$로 변환하는 것보다 $M_k$를 $M_0$로 변환하는 것이 더 쉽기 때문에 reverse process의 부담이 분명히 완화될 수 있다. 특히, inference 단계에서 보조 디코더(auxiliary decoder)를 활용하여 $\tilde{M}$을 생성한다. $\tilde{M}$은 악보 인코더 출력을 조건으로 하여 L1으로 학습된다. 그런 다음 diffusion process를 통해 얕은 단계 $k$에서 중간 샘플을 생성한다.
만일 교차점 범위 $k$가 적절히 선택되면 $\tilde{M}_k$와 $M_k$가 같은 분포에서 온다고 생각할 수 있다. 그런 다음 $\tilde{M}_k$에서 reverse process를 시작하여 $k$번의 denoising을 반복하여 process를 완료한다.
Shallow diffusion mechanism을 사용하는 학습 과정과 inference 과정은 다음과 같이 나타낼 수 있다.


3. Boundary Prediction
본 논문은 교차점을 찾고 적응적으로 $k$를 결정하기 위해 boundary predictor (BP)를 제안한다. BP는 classifier와 mel-spectrogram에 noise를 더하는 모듈로 구성된다. $t \in [0, T]$가 주어지면 $M_t$를 1로 레이블링하고 $\tilde{M}_t$를 0으로 레이블링하여 BP가 입력 mel-spectrogram이 $M$에서 오는지 $\tilde{M}$에서 오는지를 판단하도록 cross-entropy loss를 사용하여 학습시킨다. 학습 loss \(\mathbb{L}_{BP}\)는 다음과 같이 구할 수 있다.
\[\begin{equation} \mathbb{L}_{BP} = - \mathbb{E}_{M \in \mathcal{Y}, t \in [0, T]} [\log BP (M_t, t) + \log (1-BP(\tilde{M}_t, t))] \end{equation}\]$\mathcal{Y}$는 mel-spectrogram에 대한 학습 데이터셋이다. BP의 학습이 끝나면 샘플이 1로 분류될 확률을 나타내는 BP의 예측값을 사용하여 $k$를 결정한다. 모든 $M \in \mathcal{Y}$에 대해 $\textrm{BP}(M_t, t)$와 $\textrm{BP}(\tilde{M}_t, t)$의 차이가 threshold보다 작은 $t$가 $[k’, T]$의 95%가 되도록 $k’$를 찾는다. 그런 다음 $k’$의 평균을 $k$로 선택한다.
저자들은 KL-divergence를 비교하여 경계 예측을 위한 더 쉬운 트릭도 제안한다. 경계 예측은 전체 데이터셋에 대한 하이퍼 매개변수 $k$를 선택하기 위한 데이터셋 전처리 단계로 간주될 수 있다. $k$는 실제로 validation set에 대한 brute force 검색을 통해 수동으로 선택할 수 있다.
4. Model Structures
Encoder
인코더는 악보를 컨디셔닝을 위한 시퀀스로 인코딩한다. 인코더는 세 부분으로 구성된다.
- 음소 ID를 임베딩 시퀀스로 매핑하는 가사 인코더와 이 시퀀스를 언어적 시퀀스로 변환하는 일련의 Transformer block
- Duration 정보로 언어적 시퀀스를 mel-spectrogram의 길이로 확장하는 length regulator
- Pitch ID를 pitch 임베딩 시퀀스로 매핑하는 pitch 인코더
인코더는 언어적 시퀀스와 pitch 시퀀스를 더하여 컨디셔닝을 위한 시퀀스 $E_m$으로 만든다.
Step Embedding
Diffusion step $t$가 $\epsilon_\theta$의 또다른 컨디셔닝으로 주어진다. 이산적인 step $t$를 연속적인 값으로 변환하기 위하여 sinusoidal position embedding과 2개의 FC layer을 사용하며, $C$ 채널의 step 임베딩 $E_t$를 얻는다.
Auxiliary decoder
간단한 mel-spectrogram 디코더를 auxiliary decoder라 부르며, feed-forward Transformer (FFT) block으로 구성된다. Auxiliary decoder는 FastSpeech2의 mel-spectrogram 디코더와 같이 최종 출력으로 $\tilde{M}$을 생성한다.
Denoiser
Denoiser $\epsilon_\theta$는 $M_t$를 입력으로 받아 diffusion process에서 더해진 $\epsilon$를 예측하며, $E_t$와 $E_m$을 조건으로 받는다. Diffusion model에는 아키텍처 제약이 없으므로 denoiser의 디자인으로 여러가지 선택지가 있다. 본 논문에서는 non-causal WaveNet을 사용하였다.
Denoiser는 $H_m$ 채널의 $M_t$를 $C$ 채널의 입력 시퀀스 $\mathcal{H}$로 변환하는 1$\times$1 conv layer와 residual connection이 있는 $N$개의 convolution block으로 구성된다. 각 convolution block은 다음과 같이 구성된다.
- $E_t$를 $\mathcal{H}$에 element-wise하게 더하는 연산
- $\mathcal{H}$를 $C$ 채널에서 $2C$ 채널로 변환하는 non-causal convolution network
- $E_m$을 $2C$ 채널로 변환하는 1$\times$1 conv layer
- 입력과 조건들의 정보를 합치는 gate unit
- 합쳐진 $2C$ 채널의 정보를 각 $C$ 채널의 2개의 branch로 나누는 residual block
(하나의 branch는 다음 $\mathcal{H}$로 사용, 다른 하나는 최종 결과로 수집되는 “skip hidden”)
이러한 구조를 통해 denoiser가 여러 계층 수준의 feature를 통합하여 최종 예측에 사용한다.
Boundary Predictor
Boundary predictor는 $E_t$를 제공하기 위한 step embedding과 ResNet으로 구성되어 $E_t$와 $t$번째 step의 mel-spectrogram을 입력으로 받아 $M_t$인지 $\tilde{M}_t$인지 분류한다.
Experiments
1. Experimental Setup
- 데이터셋: PopCS
- 중국어 팜송 데이터셋, 노래 117개, 총 5.89시간
- 모든 노래는 24kHz, 16bit로 샘플링됨
- 정확한 악보를 얻기 위해 각각의 전체 노래를 DeepSinger로 문장 조각으로 나누고 노래 조각과 대응되는 가사 사이의 음소 레벨의 alignment를 얻기 위하여 Montreal Forced Aligner tool (MFA) 모델을 학습시킴
- Parselmouth로 waveform에서 $F_0$ (fundamental frequency)를 추출하여 pitch 정보로 사용
- 대부분 길이가 10~13초인 노래 조각 1651개로 만들어 사용
- Implementation Details
- 중국어 가사를 음소로 변환하기 위해 pypinyin 사용
- Mel-spectrogram: hop size 128, frame size 512, sample rate 24kHz, mel bin $H_m$은 80
- Mel-spectrogram은 [-1, 1]로 선형적으로 스케일링됨. F0는 평균이 0이고 분산이 1이 되도록 정규화
- 가사 인코더: 임베딩 차원은 256, Transformer block은 FastSpeech2와 동일한 세팅
- Pitch 인코더: look up table 크기는 300, pitch 임베딩은 256, $C = 256$
- Denoiser: conv layer 20개 (kernel size 3, dilation 1), $T = 100$, $\beta$는 $beta_1 = 10^{-4}$에서 $\beta_T$로 선형적으로 증가
- Auxiliary decoder: FastSpeech2의 mel-spectrogram decoder와 동일한 세팅
- Boundary predictor: conv layer 5개, threshold 0.4
- Training: 2단계
- Warmup stage: 악보 인코더와 함께 auxiliary decoder를 16만 step동안 학습시킨 후, auxiliary decoder를 사용하여 boundary predictor를 3만 step동안 학습시켜 $k$를 얻음
- Main stage: DiffSinger을 Algorithm 1로 수렴할 때까지 학습시킴 (16만 step)
- Inference: 사전 학습된 Parallel WaveGAN (PWG)을 vocoder로 사용하여 생성된 mel-spectrogram을 waveform으로 변환
2. Main Results and Analysis
Audio Performance
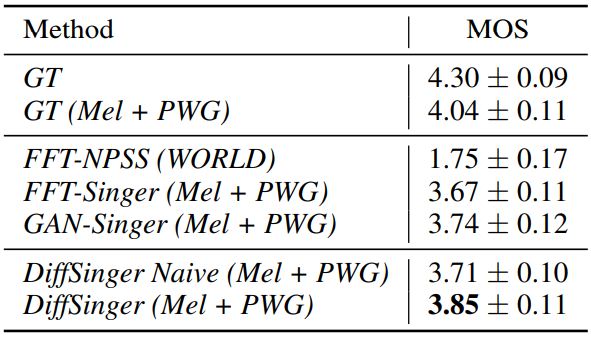
다음은 95% 신뢰도 구간으로 노래 샘플의 MOS를 측정한 것이다. DiffSinger Naive는 shallow diffusion mechanism을 사용하지 않은 버전의 DiffSinger이다.
다음은 같은 악보에 대한 ground truth (GT) mel-spectrogram과 Diffsinger, GAN-singer, FFT-singer가 생성한 mel-spectrogram이다.

Diffsinger와 GAN-singer가 FFT-singer에 비해 고조파(harmonic) 사이의 더 섬세한 디테일을 포함하고 있으며, Diffsinger가 중간과 낮은 주파수 영역에 대하여 고주파수 영역과 비슷한 품질을 유지하므로 Diffsinger의 성능이 GAN-singer의 성능보다 경쟁력 있다.
또한, shallow diffusion mechanism을 사용하였을 때의 RTF는 0.191이고 사용하지 않았을 때의 RTF는 0.348로, inference가 45.1% 빨라지는 것을 확인하였다고 한다. (RTF: 1초의 오디오를 생성하는 데 몇 초 걸리는 지)
Ablation Studies
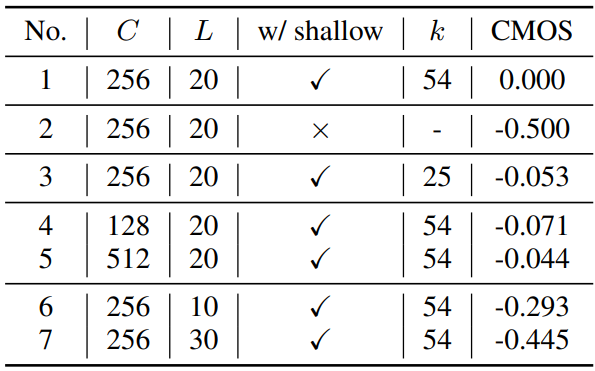
다음은 다양한 hyperparameter의 효과를 설명하기 위한 ablation study 결과이다.
3. Extensional Experiments on TTS
저자들은 TTS task에서 본 논문의 방법의 일반화를 검증하기 위하여 LJSpeech 데이터셋에서 실험을 진행하였다. FastSpeech2의 train-val-test dataset splits, mel-spectrogram 전처리, grapheme-tophoneme tool을 사용하였다. DiffSpeech를 만들기 위하여 FastSpeech2의 pitch predictor와 duration predictor를 사용하였으며, shallow diffusion mechanism의 $k$를 70으로 설정하였다. Vocoder로는 HiFi-GAN을 사용하였다.
다음은 DiffSpeech에 대한 MOS 비교 결과이다.
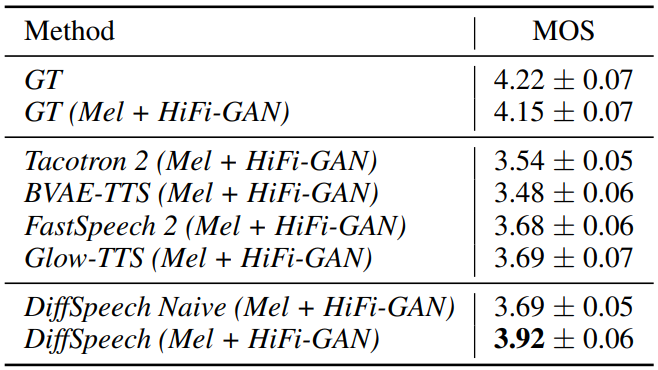
DiffSpeech가 FastSpeech2와 Glow-TTS의 성능을 뛰어 넘는 것을 볼 수 있으며, 마지막 두 행을 보면 shallow diffusion mechanism의 효과를 볼 수 있다.