[논문리뷰] DiffSim: Taming Diffusion Models for Evaluating Visual Similarity
ICCV 2025. [Paper] [Github]
Yiren Song, Xiaokang Liu, Mike Zheng Shou
National University of Singapore
19 Dec 2024

Introduction
본 논문의 목적은 사전 학습된 diffusion model을 사용하여 시각적 유사성을 평가하는 것이다. Self-attention layer와 cross-attention layer의 feature들은 일관된 시각적 외형을 가진 샘플을 생성하는 데 매우 중요하므로, 저자들은 이러한 feature들이 시각적 외형과 개념을 대표하며 시각적 유사성을 평가하는 데 사용될 수 있다고 생각하였다.
하지만 feature map 간의 단순 MSE 또는 코사인 유사도 계산은 다음과 같은 이유로 실용적이지 않다.
- Noise가 포함된 이미지로 학습된 U-Net은 feature 추출 전에 입력 이미지에 noise를 추가해야 한다.
- 코사인 유사도를 계산하기 위해 고차원 semantic feature를 사용하는 CLIP 및 DINO와 달리, Stable Diffusion U-Net의 feature는 공간 정보가 매우 밀집되어 있어 픽셀 수준에서 오정렬이 발생한다.
이러한 문제를 해결하기 위해, 본 논문에서는 U-Net의 self-attention layer에서 이미지 A와 B의 feature를 정렬하기 위해 attention 메커니즘을 혁신적으로 활용하고, 정렬된 feature 간의 코사인 거리를 계산하는 Aligned Attention Score (AAS)를 제안하였다.
또한, 본 논문에서는 denoising U-Net 내에서 다양한 layer와 denoising timestep에 따른 feature 변화를 살펴보았다. 그 결과, 얕은 layer와 높은 timestep은 저수준 및 스타일 유사성 평가에 적합하고, 깊은 layer와 낮은 timestep은 semantic 유사성 평가에 탁월하다는 것을 발견했다. 이는 DiffSim이 간단한 설정 조정을 통해 다양한 유사도 측정 방식을 구현할 수 있음을 시사한다.
저자들은 self-attention layer에서의 유사도 계산 외에도, cross-attention layer에서 IP-Adapter Plus를 사용하여 시각적 유사성을 평가하는 방법을 탐구했다. 더 나아가, 이 기법을 CLIP 및 DINO와 같은 다른 아키텍처에도 적용하여 성능을 향상시킬 수 있음을 확인했으며, 이를 통해 CLIP AAS와 DINO ASS metric을 도입하여 특정 task에서 성능을 크게 개선했다.
Method
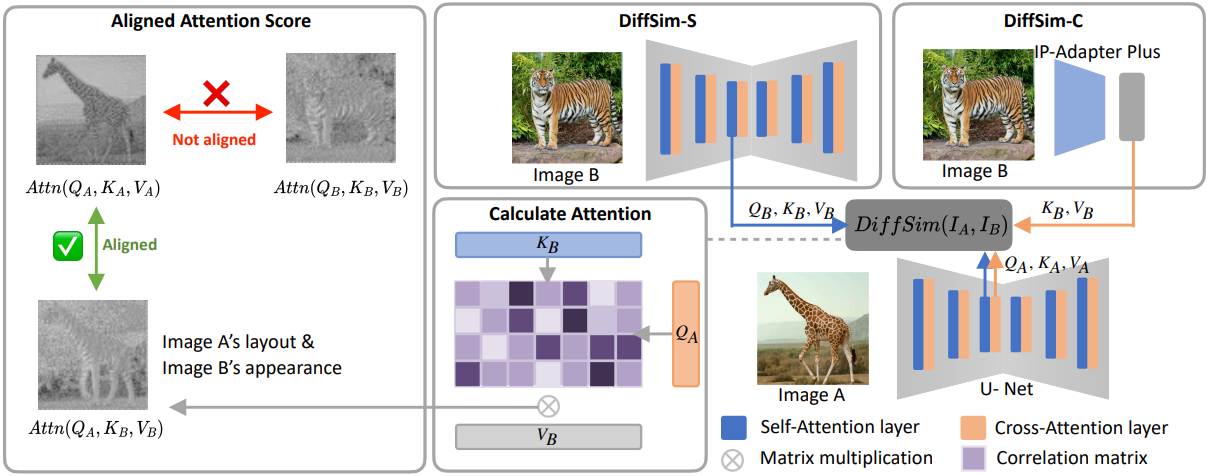
1. Aligned Attention Score
본 논문은 semantic 컨텐츠 및 스타일과 같은 다양한 측면을 측정하면서 이미지 간의 암시적인 정렬을 제공하도록 설계된 새로운 metric인 Aligned Attention Score (AAS)를 도입하였다. MSE나 코사인 유사도와 같은 기존 유사도 평가 방법은 이미지의 latent feature가 픽셀 단위로 정렬되어 있다고 가정하는 경우가 많다. 그러나 이러한 가정은 실제 응용 분야에서 자주 실패하여 부정확한 유사도 측정으로 이어진다. 또한 CLIP 및 DINO와 같은 널리 사용되는 방법은 MLP를 사용하여 고차원 feature를 저차원 feature로 압축하고 이러한 단순화된 표현에 대해 코사인 유사도를 계산한다. Semantic 수준의 비교에는 효과적이지만, 이러한 압축 과정은 중요한 디테일을 손실하여 미묘한 차이를 포착하지 못할 수 있다.
AAS는 사전 학습된 U-Net 또는 Transformer 기반 모델의 attention 메커니즘을 활용하여 오정렬 문제를 해결한다. 이미지 $I_A$와 $I_B$의 latent 표현을 각각 $L_A$와 $L_B$라 하자. AAS는 신경망의 attention 함수 $\textrm{attn}(Q, K, V)$를 사용하여 이러한 표현을 동적으로 정렬한다.
\[\begin{aligned} \textrm{AAS}(L_A, L_B) &= \textrm{cos}(\textrm{attn}(Q_A, K_A, V_A), \textrm{attn}(Q_A, K_B, V_B)) \\ \textrm{AAS}(L_B, L_A) &= \textrm{cos}(\textrm{attn}(Q_B, K_B, V_B), \textrm{attn}(Q_B, K_A, V_A)) \end{aligned}\]AAS는 attention layer에서 dense한 latent 표현을 정렬함으로써 각 이미지의 feature가 다른 이미지의 feature에 대해 query와 key로 모두 평가되도록 한다. 이 방법은 픽셀 정렬 부족을 보완할 뿐만 아니라 feature space의 풍부함을 보존하여 인간의 시각적 판단과 더욱 밀접하게 일치하는 지각적 유사성 측정 방법을 제공한다.
\[\begin{equation} \textrm{Similarity} (L_A, L_B) = \textrm{AAS}(L_A, L_B) + \textrm{AAS}(L_B, L_A) \end{equation}\]이 평가 방식은 사전 학습된 모델이 제공하는 다양한 세분화 수준의 표현을 활용하여 이미지 정렬 불량 및 정보 손실 처리를 효과적으로 개선한다.
2. DiffSim Metric
Stable Diffusion의 attention 메커니즘을 최대한 활용하기 위해, 저자들은 Stable Diffusion의 self-attention과 cross-attention을 AAS에 맞게 재구성하여 DiffSim-S와 DiffSim-C라는 두 가지 방법을 개발했다.
DiffSim-S
U-Net의 self-attention layer에 있는 feature들이 이미지 외형의 일관성을 반영할 수 있다는 것은 잘 알려져 있다. 기존 연구들은 이러한 특성을 활용하여 높은 일관성을 가진 이미지 및 동영상을 생성해 왔다.
따라서 저자들은 U-Net의 self-attention layer에 있는 feature들이 이미지 외형의 일관성을 반영할 수 있다고 가정하였다. 본 논문에서는 DiffSim-S는 다음과 같다.
\[\begin{equation} \textrm{DiffSim-S}(I_A, I_B, n, t) = \frac{1}{2} (\textrm{AAS}(z_{t,\textrm{self},n}^A, z_{t,\textrm{self},n}^B) + \textrm{AAS}(z_{t,\textrm{self},n}^B, z_{t,\textrm{self},n}^A)) \end{equation}\](\(z_{t,\textrm{self},n}^A\)와 \(z_{t,\textrm{self},n}^B\)는 각각 timestep $t$에서 U-Net의 $n$번째 self-attention layer 내의 이미지 $I_A$와 $I_B$의 latent 표현)
DiffSim-C
Stable Diffusion은 텍스트 임베딩을 cross-attention layer의 조건으로 통합하여 text-to-image 생성 성능을 향상시킨다. 기존 연구들에서는 cross-attention layer를 fine-tuning하는 것만으로도 새로운 개념을 학습할 수 있음을 보여주었다. 이러한 맥락에서, 본 논문에서는 cross-attention layer feature를 활용하여 이미지 유사성을 평가하는 가능성을 탐구했다. 그러나 기존의 cross-attention layer는 이미지 latent들과 텍스트 임베딩 간의 attention 계산만을 지원했다.
이를 확장하기 위해, CLIP 이미지 인코더의 패치 feature를 활용하고 IP 토큰 수를 16개로 늘린 IP-Adapter Plus를 U-Net의 cross-attention layer에 도입했다. 이를 통해 이미지 latent들과 강화된 IP 토큰 간의 상호 작용을 포함하는 보다 미묘한 attention 계산이 가능해졌다.
이미지 $I_A$와 $I_B$는 각각 IP-Adapter Plus와 denoising U-Net에 입력된다. Attention 기반 유사도 점수는 한 이미지의 latent와 다른 이미지에서 파생된 IP 토큰을 비교하고, 그 반대의 경우도 마찬가지로 비교하여 계산한다.
\[\begin{equation} \textrm{DiffSim-C}(I_A, I_B, n, t) = \frac{1}{2} (\textrm{AAS}(z_{t,\textrm{cross},n}^A, \textrm{IP}_B) + \textrm{AAS}(z_{t,\textrm{cross},n}^B, \textrm{IP}_A)) \end{equation}\](\(z_{t,\textrm{scrosself},n}^A\)와 \(z_{t,\textrm{cross},n}^B\)는 각각 timestep $t$에서 U-Net의 $n$번째 cross-attention layer 내의 latent 표현, \(\textrm{IP}_A\)와 \(\textrm{IP}_B\)는 IP 토큰)
다양한 프레임워크에 맞춘 DiffSim 적용
DiffSim 방법은 광범위하게 적용 가능하며, attention layer에서 feature 유사도를 계산하여 이미지 feature를 분석할 수 있게 해준다. 본 논문에서는 DiffSim 접근 방식을 CLIP 이미지 인코더와 DINO v2 아키텍처로 확장했다.
CLIP은 contrastive learning을 통해 이미지와 텍스트 인코더를 학습시켜 이미지와 텍스트 간의 관계를 이해하고, 이미지-텍스트 쌍의 유사도를 최대화하는 것을 목표로 한다. 이미지 인코더로는 일반적으로 ViT 또는 ResNet을 사용한다. DINO는 Teacher-student 네트워크 아키텍처를 기반의 self-supervised learning 방식으로 작동하며, 두 네트워크 모두 ViT를 활용한다.
저자들은 CLIP 및 DINO v2 모델의 특정 self-attention layer에 대해 AAS를 계산하고, CLIP AAS와 DINO v2 AAS라는 새로운 metric을 도입했다.
3. New Benchmarks

Sref Bench
스타일은 주관적이므로 효과적인 스타일 유사도 측정 방법은 인간의 스타일 인식 및 정의와 일치해야 한다. 따라서 저자들은 Midjourney의 Sref 모드를 사용하여 생성한 508개의 스타일을 수집했다. 각 스타일은 인간이 직접 선정했으며, 각각 주제별로 구별되는 4개의 레퍼런스 이미지를 특징으로 한다. Midjourney의 스타일 참조 기능은 사용자가 프롬프트에 외부 이미지나 스타일 시드를 사용하여 생성된 이미지의 스타일 또는 미적 방향을 지정할 수 있도록 한다.
IP Bench
인스턴스 수준의 일관성은 커스터마이징된 생성에서 가장 중요한 것 중 하나지만, 그러나 캐릭터 일관성을 평가하기 위한 고품질 벤치마크가 부족하다. 본 연구에서는 299개의 IP 캐릭터 이미지를 수집하고, Flux 모델과 IP-Adapter를 사용하여 각 캐릭터에 대해 서로 다른 일관성 가중치를 적용한 여러 변형을 생성했다.
Experiments
1. Quantitative Evaluation
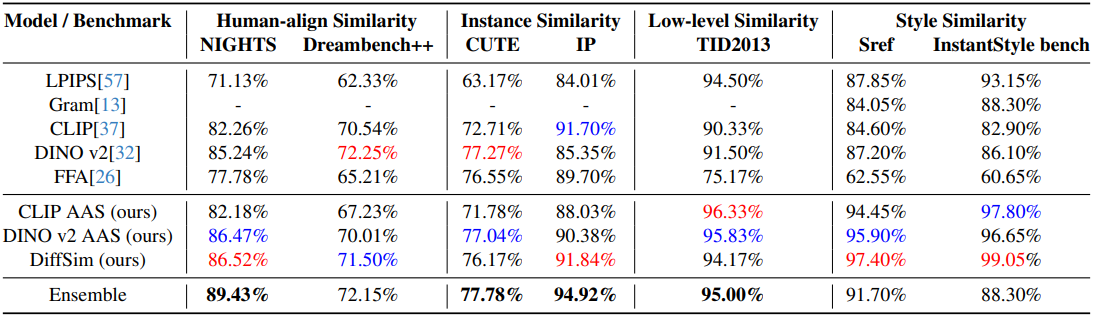
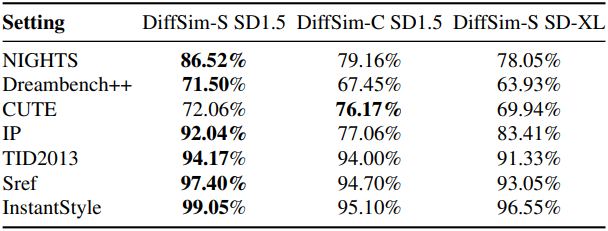
다음은 다양한 벤치마크에서의 성능을 비교한 결과이다.
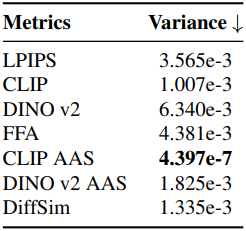
다음은 동영상에서의 외형 일관성을 평가한 결과이다.
2. Performance Analysis
다음은 다양한 timestep, block, 해상도에 대한 평가 결과이다.
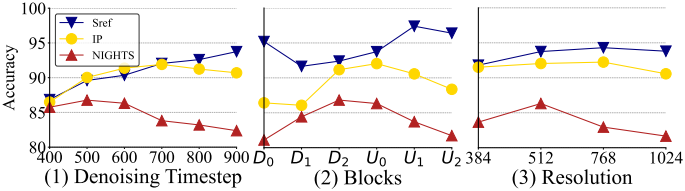
다음은 다양한 아키텍처에 대한 평가 결과이다.
3. Ablation Study
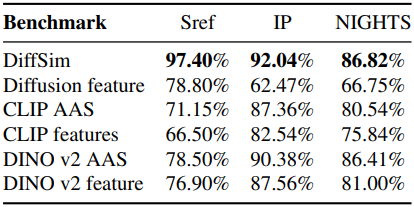
다음은 ablation study 결과이다.
4. Image Retrieval
다음은 가장 가까운 이미지 4개를 검색한 결과이다.
