[논문리뷰] DiffiT: Diffusion Vision Transformers for Image Generation
ECCV 2024. [Paper] [Page]
Ali Hatamizadeh, Jiaming Song, Guilin Liu, Jan Kautz, Arash Vahdat
NVIDIA
4 Dec 2023

Introduction
Diffusion model은 DALL·E 3, Imagen, Stable Diffusion, eDiff-I와 같은 성공적인 프레임워크를 통해 생성 학습 도메인에 혁명을 일으켰다. 이전 모델들에서는 불가능하다고 여겨졌던 다양하고 복잡한 장면을 높은 충실도로 생성할 수 있게 되었다. 특히, diffusion model의 합성은 이미지 모양의 랜덤 Gaussian noise가 현실적인 샘플을 향해 점차적으로 denoise되는 반복 프로세스로 공식화된다. 이 프로세스의 핵심 빌딩 블록은 noisy한 이미지를 가져와 score function과 동일하게 denoising 방향을 예측하는 denoising autoencoder 네트워크이다. Denoising process의 여러 timestep에 걸쳐 공유되는 이 네트워크는 self-attention 레이어와 convolution residual block으로 구성된 U-Net의 변형이다. Self-Attention 레이어는 장거리 공간 의존성을 캡처하는 데 중요한 것으로 나타났지만 이를 통합하는 방법에 대한 표준 디자인 패턴이 부족하다. 실제로 대부분의 denoising network는 높은 계산 복잡도를 피하기 위해 저해상도 feature map에서만 self-attention 레이어를 활용하는 경우가 많다.
최근 여러 연구들에서 diffusion model이 생성 중에 독특한 시간적 역학을 나타내는 것으로 관찰되었다. Denoising process가 시작될 때 이미지에 강한 Gaussian noise가 포함되어 있으면 이미지의 고주파 콘텐츠가 완전히 교란되고 denoising network는 주로 저주파 콘텐츠를 예측하는 데 중점을 둔다. 그러나 대부분의 이미지 구조가 생성되는 denoising이 끝날 무렵 네트워크는 고주파 디테일 예측하는 데 초점을 맞추는 경향이 있다. Denoising network의 시간 의존성은 여러 residual block에 공급되는 간단한 시간적 위치 임베딩을 통해 구현되는 경우가 많다. 실제로, denoising network의 convolution 필터는 시간 의존적이지 않으며 시간 임베딩은 채널별 shift와 scaling만 적용한다. 따라서 이러한 간단한 메커니즘은 전체 denoising process 동안 네트워크의 시간 의존성을 최적으로 포착하지 못할 수도 있다.
본 논문에서는 denoising model에서 self-attention 모듈의 시간 의존 성분 캡처에 대한 세밀한 제어가 부족한 문제를 해결하는 것을 목표로 한다. CIFAR10, FFHQ-64, ImageNet-256, ImageNet-512에서 SOTA FID를 달성하는 DiffiT라는 새로운 ViT 기반 이미지 생성 모델을 소개한다. 구체적으로 DiffiT는 시간적 의존성이 timestep별로 key, query, value 가중치가 적용되는 self-attention 레이어에만 통합되는 새로운 패러다임을 제안하였다. 이를 통해 denoising model은 여러 denoising step에 대한 attention 메커니즘을 동적으로 변경할 수 있다. 아키텍처 디자인 패턴을 통합하기 위한 노력의 일환으로 latent space 합성 task를 위한 계층적 Transformer 기반 아키텍처도 제안하였다.
DiffiT

Time-dependent Self-Attention
모든 레이어에서 Transformer 블록은 입력의 2D 그리드에 공간적으로 배열된 토큰 집합인 \(\{x_s\}\)를 받는다. 또한 timestep을 나타내는 시간 토큰인 $x_t$도 받는다. DDPM과 비슷하게 swish activation을 통해 작은 MLP에 시간 임베딩을 공급하여 시간 토큰을 얻는다. 이 시간 토큰은 denoising network의 모든 레이어에 전달된다. 공유된 공간에 feature와 시간 토큰 임베딩을 project하여 공간적 및 시간적 장거리 의존성을 모두 캡처하는 time-dependent multi-head self-attention (TMSA)을 도입한다. 특히, 공유된 공간의 시간 의존 query $q$, key $k$, value $v$는 다음 식을 통해 공간 및 시간 임베딩 $x_s$와 $x_t$의 linear projection으로 계산된다.
\[\begin{aligned} q_s &= x_s W_{qs} + x_t W_{qt} \\ k_s &= x_s W_{ks} + x_t W_{kt} \\ v_s &= x_s W_{vs} + x_t W_{vt} \end{aligned}\]여기서 $W_{qs}$, $W_{qt}$, $W_{ks}$, $W_{kt}$, $W_{vs}$, $W_{vt}$는 각각 해당 query, key, value에 대한 공간적 및 시간적 linear projection 가중치를 나타낸다.
이 연산들은 시간 토큰과 concatenate된 각 공간 토큰의 linear projection과 동일하다. 결과적으로 key, query, value는 모두 시간 및 공간 토큰의 선형 함수이며 여러 timestep에 대한 attention 동작을 적응적으로 수정할 수 있다. 행렬의 행에 query, key, value가 쌓인 형태인 \(Q := \{q_s\}\), \(K := \{k_s\}\), \(V := \{v_s\}\)를 정의하면 self-attention은 다음과 같이 계산된다.
\[\begin{equation} \textrm{Attention} (Q, K, V) = \textrm{Softmax} \bigg( \frac{QK^\top}{\sqrt{d}} + B \bigg) V \end{equation}\]여기서 $d$는 $K$에 대한 scaling factor이고 B는 relative position bias에 해당한다. Attention을 계산하기 위해 relative position bias을 통해 각 attention head 전체에 걸쳐 정보를 인코딩할 수 있다. Relative position bias는 입력 시간 임베딩에 의해 암시적으로 영향을 받지만 이를 이 구성 요소와 직접 통합하면 공간 정보와 시간 정보를 모두 캡처해야 하므로 성능이 최선이 아닐 수 있다.
DiffiT Block
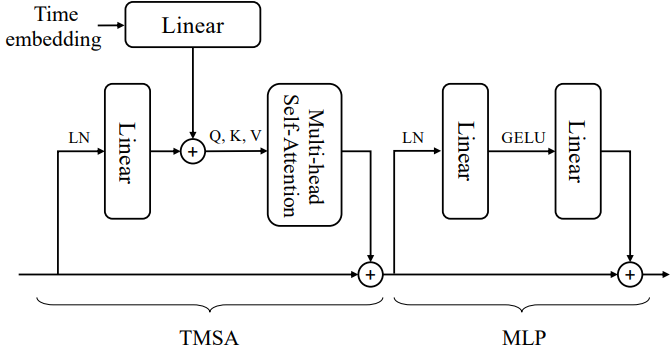
DiffiT Transformer block은 제안된 아키텍처의 핵심 빌딩 블록이며 다음과 같이 정의된다.
여기서 TMSA는 time-dependent multi-head self-attention이고, $x_t$는 시간 임베딩 토큰, $x_s$는 공간 토큰, LN과 MLP는 각각 Layer Norm과 MLP이다.
1. Image Space
DiffiT Architecture
DiffiT는 수축 및 확장 경로가 모든 해상도에서 skip connection을 통해 서로 연결되는 대칭 U자형 인코더-디코더 아키텍처를 사용한다. 특히, 인코더 또는 디코더 경로의 각 해상도는 time-dependent self-attention 모듈을 포함하는 $L$개의 연속되는 DiffiT 블록으로 구성된다. 인코더와 디코더 모두에 대해 feature map의 수를 일치시키기 위해 각 경로의 시작 부분에는 convolution layer가 사용된다. 또한 각 해상도 간 전환에는 convolutional upsampling 또는 downsampling layer도 사용된다. 저자들은 이러한 convolution layer를 사용하면 성능을 더욱 향상시킬 수 있는 inductive bias가 포함되어 있다고 추측하였다.
DiffiT ResBlock
제안된 DiffiT Transformer block과 추가 convolution layer를 결합하여 다음과 같이 최종 residual cell을 정의한다.
\[\begin{aligned} \hat{x}_s &= \textrm{Conv}_{3 \times 3} (\textrm{Swish} (\textrm{GN} (x_s))) \\ x_s &= \textrm{DiffiT-Block} (\hat{x}_s, x_t) + x_s \end{aligned}\]여기서 GN은 group normalization 연산이다. 이미지 공간에서 작동하는 diffusion model을 위한 residual cell은 convolution layer와 Transformer 블록을 모두 결합한 하이브리드 셀이다.
2. Latent Space
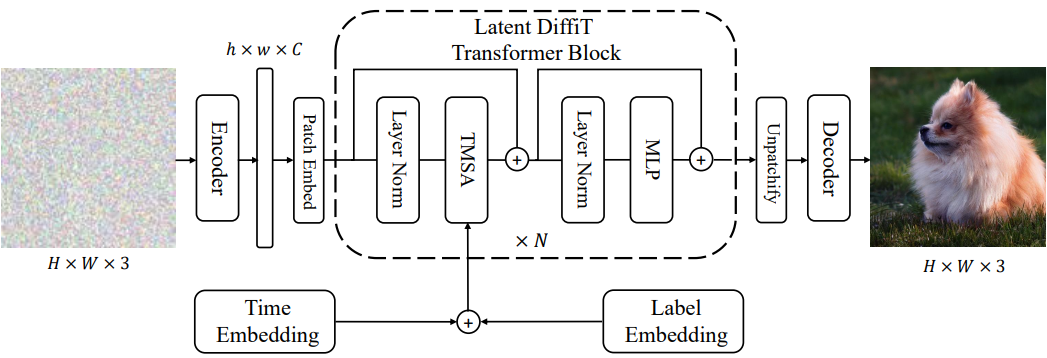
최근에는 latent diffusion model이 고품질 고해상도 이미지 생성에 효과적인 것으로 나타났다. 위 그림은 latent DiffiT 모델의 아키텍처이다. 먼저 사전 학습된 VAE 네트워크를 사용하여 이미지를 인코딩한다. 그런 다음 feature map은 겹치지 않는 패치로 변환되어 새로운 임베딩 공간에 project된다. DiT 모델과 유사하게 latent space의 denoising network로 업샘플링 또는 다운샘플링 레이어 없이 ViT를 사용한다. 또한 생성된 샘플의 품질을 향상시키기 위해 3채널 classifier-free guidance도 활용한다. 아키텍처의 마지막 레이어는 출력을 디코딩하는 간단한 linear layer이다.
Results
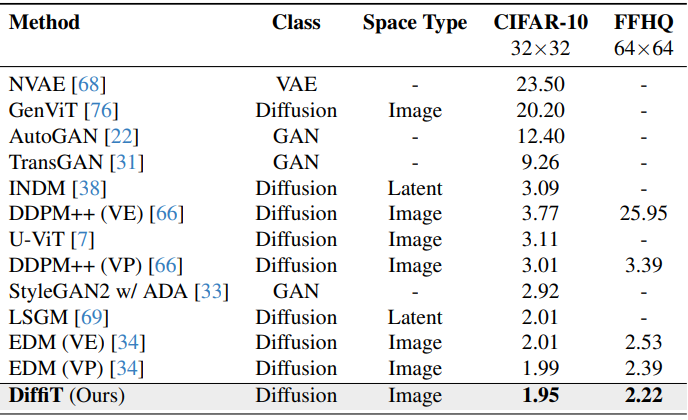
1. Image Space
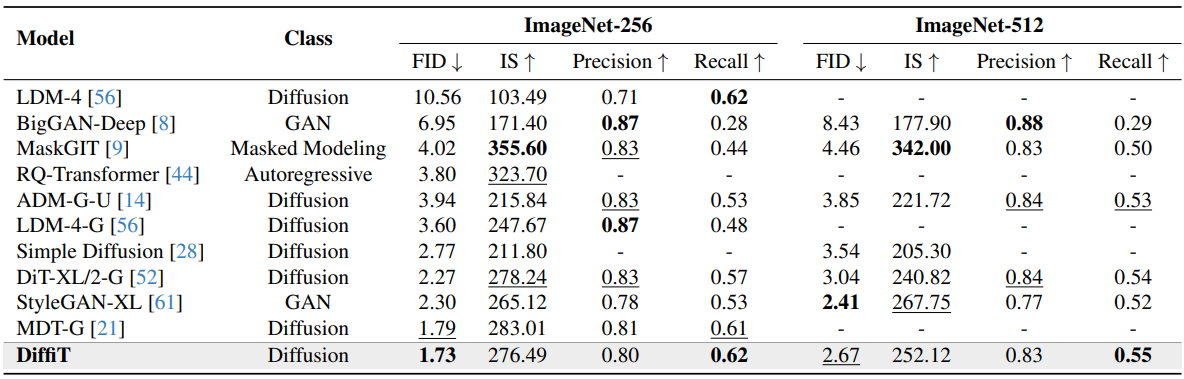
다음은 다양한 모델들과 이미지 생성 성능을 비교한 표이다.
다음은 FFHQ-64에서 DiffiT가 생성한 이미지들이다. (선별하지 않음)

2. Latent Space
다음은 SOTA 모델들과 이미지 생성 성능을 비교한 표이다.
다음은 ImageNet-256과 ImageNet-512에서 latent DiffiT 모델이 생성한 이미지들이다. (선별하지 않음)

Ablation
1. Time and Feature Token Dimensions
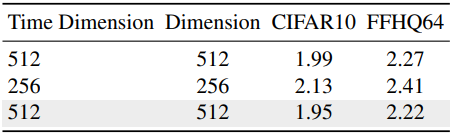
다음은 시간 차원과 feature 차원에 대한 ablation study 결과이다.
2. Effect of Architecture Design
다음은 인코더와 디코더 아키텍처에 대한 ablation study 결과이다.

3. Time-Dependent Self-Attention
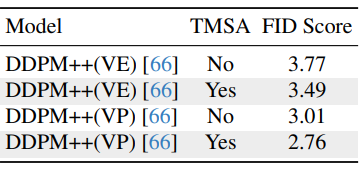
다음은 DDPM++에서의 TMSA의 효과를 비교한 표이다.
4. Impact of Self-Attention Components
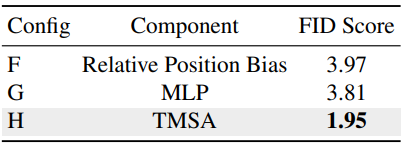
다음은 self-attention 종류에 따른 FID를 비교한 표이다.
5. Visualization of Self-Attention Maps
다음은 TMSA 유무에 따른 attention map을 비교한 것이다.

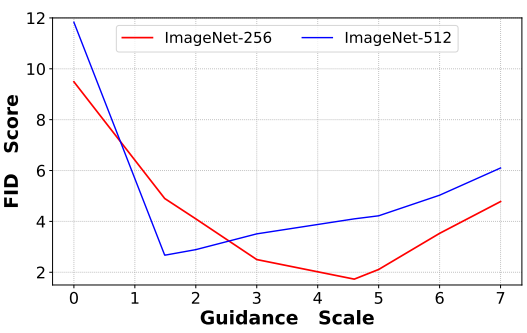
6. Effect of Classifier-Free Guidance
다음은 classifier-free guidance scale에 따른 FID를 비교한 그래프이다.