[논문리뷰] DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
ECCV 2024. [Paper] [Github]
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Ben Fei, Bo Dai, Wanli Ouyang, Yu Qiao, Chao Dong
Shenzhen Institute of Advanced Technology | Shanghai AI Laboratory
29 Aug 2023

Introduction
이미지 복원은 낮은 품질의 관찰로부터 높은 품질의 이미지를 재구성하는 것을 목표로 한다. Image denoising, deblurring, super-resolution과 같은 일반적인 이미지 복원 문제는 일반적으로 degradation process가 간단하고 알려진 제한된 설정에서 정의된다 (ex. Gaussian noise, bicubic downsampling). 그들은 수많은 우수한 복원 알고리즘을 성공적으로 이끌었지만 일반화 능력은 제한되어 있다. 실제 degrade된 이미지를 처리하기 위해 blind image restoration (BIR)이 주목받고 있으며 유망한 방향이 되고 있다. BIR의 궁극적인 목표는 일반적인 degradation이 적용된 일반 이미지에 대한 사실적인 이미지 재구성을 실현하는 것이다. BIR은 고전적인 이미지 복원 task의 범위를 확장할 뿐만 아니라 실제 적용 분야도 넓다 (ex. 오래된 사진/필름 복원).
BIR에 대한 연구는 아직 초기 단계이므로 현재 상태에 대한 더 많은 설명이 필요하다. 문제 설정에 따라 기존 BIR 방법은 크게 blind image super-resolution (BSR), zero-shot image restoration (ZIR), blind face restoration (BFR)의 세 가지 연구 주제로 분류할 수 있다. 모두 눈부신 발전을 이루었지만 분명한 한계도 있다.
BSR은 처음에는 저해상도 이미지에 알 수 없는 degradation이 포함된 실제 super-resolution 문제를 해결하기 위해 제안되었다. 최근 가장 널리 사용되는 솔루션은 BSRGAN과 Real-ESRGAN이다. 그들은 BSR을 대규모의 supervised degradation overfitting 문제로 공식화했다. 실제 degradation을 시뮬레이션하기 위해 degradation shiffle 전략과 high-order degradation 모델링이 별도로 제안되었다. 그런 다음 end-to-end 방식으로 재구성 프로세스를 학습하기 위해 adversarial loss가 통합되었다. 실제로 일반 이미지의 degradation을 대부분 제거했지만 사실적인 디테일을 생성할 수는 없다. 또한 degradation 설정은 $\times 4$/$\times 8$ super-resolution으로 제한되어 BIR 문제에 대해서는 완전하지 않다.
두 번째 그룹인 ZIR은 새롭게 등장한 방향이다. 대표작으로는 DDRM, DDNM, GDP가 있다. 강력한 diffusion model을 추가 prior 모델로 통합하여 GAN 기반 방법보다 생성 능력이 뛰어나다. 적절한 degradation 가정을 통해 기존 이미지 복원 task에서 인상적인 zero-shot 복원을 달성할 수 있다. 그러나 ZIR의 문제 설정은 BIR과 일치하지 않는다. 그들의 방법은 명확하게 정의된 degradation (선형 또는 비선형)만 처리할 수 있지만 알려지지 않은 degradation에 대해서는 일반화할 수 없다. 즉, 일반적인 이미지에 대해서는 사실적인 재구성이 가능하지만 일반적인 degradation에 대해서는 그렇지 않다.
세 번째 그룹은 인간의 얼굴 복원에 중점을 둔 BFR이다. SOTA 방법은 CodeFormer와 VQFR가 있다. BSR 방법과 유사한 솔루션 파이프라인을 가지고 있지만 degradation model과 생성 네트워크가 다르다. 이미지 공간이 더 작기 때문에 이러한 방법은 VQGAN과 Transformer를 활용하여 실제 얼굴 이미지에서 놀랍도록 좋은 결과를 얻을 수 있다. 그럼에도 불구하고 BFR은 BIR의 하위 도메인일 뿐이다. 일반적으로 고정된 입력 크기와 제한된 이미지 공간을 가정하므로 일반적인 이미지에는 적용할 수 없다.
위의 분석에 따르면 기존 BIR 방법은 일반적인 degradation이 포함된 일반 이미지에 대한 사실적인 이미지 재구성을 동시에 달성할 수 없음을 알 수 있다. 따라서 이러한 한계를 극복하기 위한 새로운 BIR 방법이 필요하다.
본 논문에서는 이전 연구들의 장점들을 통합된 프레임워크로 통합하기 위해 DiffBIR을 제안하였다. 구체적으로 DiffBIR은
- 실제 degradation으로 일반화할 수 있는 확장된 degradation model을 채택하였다.
- 생성 능력을 향상시키기 위해 잘 학습된 Stable Diffusion을 사전 모델로 활용하였다.
- 현실성과 충실도 모두를 보장하기 위해 2단계 솔루션 파이프라인을 도입하였다.
또한 저자들은 이러한 전략을 실현하기 위해 전용 디자인을 만들었다.
- 일반화 능력을 높이기 위해 BSR의 다양한 degradation 유형과 BFR의 넓은 degradation 범위를 결합하여 보다 실용적인 degradation model을 공식화하였다. 이는 DiffBIR이 다양하고 극단적인 degradation 사례를 처리하는 데 도움이 된다.
- Stable Diffusion을 활용하기 위해 특정 task에 최적화할 수 있는 injective modulation sub-network인 LAControlNet을 도입하였다. ZIR과 유사하게 사전 학습된 Stable Diffusion은 생성 능력을 유지하기 위해 fine-tuning 중에 고정된다.
- 충실하고 사실적인 이미지 재구성을 실현하기 위해 먼저 복원 모듈 (ex. SwinIR)을 적용하여 대부분의 degradation을 줄인 다음 생성 모듈 (ex. LAControlNet)을 fine-tuning하여 새로운 텍스처를 생성한다. 이 파이프라인이 없으면 모델은 지나치게 평활화된 결과를 생성하거나 잘못된 디테일을 생성할 수 있다. 또한, 사용자의 다양한 요구 사항을 충족하기 위해 1단계 복원 결과와 2단계 생성 결과 사이의 지속적인 전환 효과를 달성할 수 있는 제어 가능한 모듈을 제안하였다. 이는 재학습 없이 denoising process에서 latent image guidance를 도입함으로써 달성된다. latent image distance에 적용되는 기울기 스케일을 조정하여 현실성과 충실도를 절충할 수 있다.
위의 구성 요소를 갖춘 제안된 DiffBIR은 합성 및 실제 데이터셋에 대한 BSR과 BFR task 모두에서 탁월한 성능을 보여준다. DiffBIR은 기존 BSR과 BFR 방법을 능가하여 일반 이미지 복원에서 큰 성능 도약을 달성했다. 저자들은 몇 가지 측면에서 이러한 방법들의 차이점을 관찰할 수 있었다. 복잡한 텍스처의 경우 BSR 방법은 비현실적인 디테일을 생성하는 경향이 있는 반면 DiffBIR은 시각적으로 만족스러운 결과를 생성한다. Semantic 영역의 경우 BSR 방법은 지나치게 평활화된 효과를 달성하는 경향이 있는 반면 DiffBIR은 semantic 디테일을 재구성할 수 있다. 작은 줄무늬의 경우 BSR 방법은 이러한 디테일을 지우는 경향이 있는 반면 DiffBIR은 여전히 구조를 향상시킬 수 있다. 또한 DiffBIR은 극심한 degradation을 처리하고 현실적이고 생생한 semantic 콘텐츠를 재생성할 수 있다. 이 모든 것은 DiffBIR이 기존 BSR 방법의 한계점을 성공적으로 해결했음을 보여준다. BFR의 경우, DiffBIR은 다른 개체에 의해 가려진 얼굴 영역에 대한 우수한 충실도 유지, 얼굴 영역 너머의 성공적인 복원과 같은 일부 어려운 사례를 처리하는 데 우월성을 보여준다. 결론적으로 DiffBIR은 처음으로 통합 프레임워크에서 BSR과 BFR task 모두에 대해 경쟁력 있는 성능을 얻을 수 있었다.
Methodology
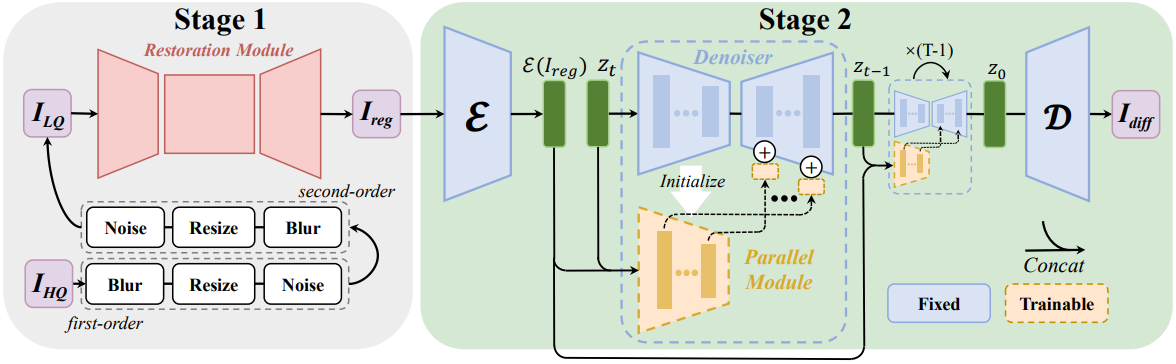
본 논문에서는 일반적인 이미지와 얼굴 이미지 모두에 대한 blind resolution 문제를 해결하기 위해 강력한 생성적 prior인 Stable Diffusion을 활용하는 것을 목표로 한다. 본 논문이 제안한 프레임워크는 효과적이고 강력하며 유연한 2단계 파이프라인을 채택한다. 먼저, regression loss를 사용하여 잡음이나 왜곡 아티팩트와 같은 손상을 제거하기 위해 복원 모듈을 사용한다. 손실된 로컬 텍스처와 대략적인/미세한 디테일이 아직 없기 때문에 Stable Diffusion을 활용하여 정보 손실을 해결한다. 전체 프레임워크는 위 그림에 설명되어 있다. 특히, 먼저 대규모 데이터셋에서 SwinIR을 사전 학습하여 다양한 degradation 전반에 걸쳐 예비 degradation 제거를 달성한다. 그런 다음 생성적 prior 분석을 활용하여 현실적인 복원 결과를 생성한다. 또한 현실성과 충실도 사이의 절충을 위해 latent image guidance 기반의 제어 가능한 모듈이 도입되었다.
1. Pretraining for Degradation Removal
Degradation Model
BIR은 알 수 없고 복잡한 degradation이 있는 저품질 (LQ) 이미지에서 깨끗한 이미지를 복원하는 것을 목표로 한다. 일반적으로 blur, noise, 압축 아티팩트, 저해상도가 관련되는 경우가 많다. LQ 이미지의 degradation space를 더 잘 커버하기 위해 다양한 degradation과 high-order degradation을 고려하는 포괄적인 degradation model을 사용한다. 모든 degradation 중에서 blur, resize, noise는 실제 시나리오의 세 가지 핵심 요소이다. 본 논문에는 다양한 degradation이 포함된다.
- blur: isotropic Gaussian kernel, anisotropic Gaussian kernel
- resize: area resize, bilinear interpolation, bicubic resize
- noise: additive Gaussian noise, Poisson noise, JPEG compression noise
High-order degradation의 경우, Real-ESRGAN을 따라 전통적인 degradation model인 blur-resize-noise 프로세스를 두 번 반복하는 2차 degradation을 사용한다. 본 논문의 degradation model은 이미지 복원을 위해 설계되었으므로 모든 degrade된 이미지의 크기가 원래 크기로 다시 조정된다.
Restoration Module
강력한 생성 이미지 복원 파이프라인을 구축하기 위해 먼저 LQ 이미지에서 대부분의 degradation (특히 noise와 압축 아티팩트)을 제거한 다음 후속 생성 모듈을 사용하여 손실된 정보를 재생함으로써 보수적이면서도 실행 가능한 솔루션을 채택했다. 이 디자인은 latent diffusion model을 사용하여 noise 손상 없이 텍스처/디테일 생성에 더 집중하고 잘못된 디테일 없이 보다 현실적이고 선명한 결과를 달성한다. 복원 모듈로 SwinIR을 수정한다. 구체적으로, 픽셀 unshuffle 연산을 활용하여 원래의 저품질 입력 \(I_\textrm{LQ}\)를 scale factor 8로 다운샘플링한다. 그런 다음 얕은 feature 추출을 위해 3$\times$3 convolutional layer를 사용한다. 모든 후속 transformer 연산은 latent diffusion model과 유사하게 저해상도 공간에서 수행된다. 깊은 feature 추출에는 여러 Residual Swin Transformer Block (RSTB)이 사용되며, 각 RSTB에는 여러 Swin Transformer Layer (STL)이 있다. 저주파 정보와 고주파 정보를 모두 유지하기 위해 얕은 feature와 깊은 feature가 더해진다. 깊은 feature를 원래 이미지 공간으로 다시 업샘플링하기 위해 가장 가까운 nearest interpolation을 세 번 수행하고 각 interpolation 뒤에 하나의 convolutional layer와 하나의 Leaky ReLU 레이어가 이어진다. L2 pixel loss를 최소화하여 복원 모듈의 파라미터를 최적화한다.
\[\begin{equation} I_\textrm{reg} = \textrm{SwinIr} (I_\textrm{LQ}), \quad \mathcal{L}_\textrm{reg} = \| I_\textrm{reg} - I_\textrm{HQ} \|_2^2 \end{equation}\]여기서 \(I_\textrm{HQ}\)와 \(I_\textrm{LQ}\)는 각각 고품질 이미지와 저품질 이미지이다. \(I_\textrm{reg}\)는 회귀 학습을 통해 얻어지며 latent diffusion model의 fine-tuning에 사용된다.
2. Leverage Generative Prior for Image Reconstruction
LAControlNet
1단계에서는 대부분의 degradation을 제거할 수 있지만 획득된 \(I_\textrm{reg}\)는 종종 과도하게 매끄러워 고품질 자연 이미지의 분포와는 거리가 멀다. 2단계에서는 획득한 \(I_\textrm{reg}\)-\(I_\textrm{HQ}\) 쌍을 사용하여 이미지 재구성을 위해 사전 학습된 Stable Diffusion을 활용한다. 먼저 Stable Diffusion의 사전 학습된 VAE 인코더를 활용하여 \(I_\textrm{reg}\)를 latent space에 매핑하고 조건 latent \(\mathcal{E}(I_\textrm{reg})\)를 얻는다. UNet denoiser는 인코더, 중간 블록, 디코더를 포함하는 latent diffusion을 수행한다. 특히 디코더는 인코더로부터 feature를 받고 이를 다양한 스케일로 융합한다. 여기서 저자들은 UNet denoiser와 동일한 인코더와 중간 블록을 포함하는 병렬 모듈을 생성하였다. 그런 다음 조건 latent \(\mathcal{E}(I_\textrm{reg})\)를 랜덤하게 샘플링된 noisy한 $z_t$와 concat한 후 병렬 모듈의 입력으로 사용한다. 이 concatenation 연산은 병렬 모듈의 첫 번째 convolutional layer의 채널 수를 증가시키기 때문에 새로 추가된 파라미터를 0으로 초기화한다. 여기서 다른 모든 가중치는 사전 학습된 UNet denoiser 체크포인트에서 초기화된다. 병렬 모듈의 출력은 원래 UNet 디코더에 추가된다. 또한 각 스케일에 대한 추가 연산 전에 하나의 1$\times$1 convolutional layer가 적용된다. Fine-tuning 중에 병렬 모듈과 이 1$\times$1 convolutional layer가 동시에 최적화되며 프롬프트 조건은 비어 있음으로 설정된다. 다음과 같은 latent diffusion 목적 함수를 최소화하는 것을 목표로 한다.
\[\begin{equation} \mathcal{L}_\textrm{Diff} = \mathbb{E}_{z_t, c, t, \epsilon, \mathcal{E}(I_\textrm{reg})} [\| \epsilon - \epsilon_\theta (z_t, c, t, \mathcal{E} (I_\textrm{reg})) \|_2^2] \end{equation}\]이 단계에서 얻은 결과를 \(I_\textrm{diff}\)라고 표시한다. 요약하면, UNet denoiser의 skip-connected feature만 특정 task에 맞게 조정되었다. 이 전략은 소규모 학습 데이터셋의 overfitting을 완화하고 Stable Diffusion의 고품질 생성을 상속할 수 있다. 더 중요한 것은 조건 정보를 인코딩하기 위해 처음부터 학습된 추가 조건 네트워크를 활용하는 ControlNet에 비해 컨디셔닝 메커니즘이 이미지 재구성 task에 더 간단하고 효과적이라는 것이다. LAControlNet에서 잘 학습된 VAE의 인코더는 조건 이미지를 latent 변수와 동일한 표현 공간에 투영할 수 있다. 이 전략은 latent diffusion model의 내부 지식과 외부 조건 정보 간의 정렬에 대한 부담을 크게 완화한다. 실제로 이미지 재구성을 위해 ControlNet을 직접 활용하면 심각한 색상 변화가 발생한다.
3. Latent Image Guidance for Fidelity-Realness Trade-off
위의 2단계 접근 방식을 통해 이미 좋은 복원 결과를 얻을 수 있었음에도 불구하고 다양한 사용자 선호도로 인해 현실성과 충실도 사이의 trade-off가 여전히 필요하다. 따라서 본 논문은 1단계에서 획득된 \(I_\textrm{reg}\)에 대한 denoising process를 가이드하여 현실적 결과와 원활한 결과 사이의 조정을 얻을 수 있는 제어 가능한 모듈을 제안한다. Classifier guidance는 noisy한 이미지에 대해 학습된 classifier를 활용하여 생성을 타겟 클래스로 가이드한다. 대부분의 경우 guidance 역할을 하는 사전 학습된 모델은 일반적으로 깨끗한 이미지에 대해 학습된다. 이러한 상황을 처리하기 위해 이전 연구들에서는 중간 변수 \(\tilde{x}_0\)을 가이드하여 diffusion model의 생성 프로세스를 제어하였다. 구체적으로 샘플링 과정에서 $x_t$의 noise를 추정하여 $x_t$에서 깨끗한 이미지 $x_0$를 추정한다. 본 논문에서는 diffusion process와 denoising process가 latent space르 기반으로 한다. 따라서 다음 방정식을 통해 깨끗한 latent $z_0$를 얻는 것을 목표로 한다.
\[\begin{equation} \tilde{z}_0 = \frac{z_t}{\sqrt{\vphantom{1} \bar{\alpha}_t}} - \frac{\sqrt{1 - \bar{\alpha}_t} \epsilon_\theta (z_t, c, t, \mathcal{E}(I_\textrm{reg}))}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \end{equation}\]그러면, latent 기반 loss \(\mathcal{D}_\textrm{latent}\)는 latent image guidance \(\mathcal{E}(I_\textrm{reg})\)와 추정된 깨끗한 latent \(\tilde{z}_0\) 사이의 L2 거리로 정의된다.
\[\begin{equation} \mathcal{D}_\textrm{latent} (x, I_\textrm{reg}) = \mathcal{L} (\tilde{z}_0, \mathcal{E}(I_\textrm{reg})) = \sum_j \frac{1}{C_j H_j W_j} \| \tilde{z}_0 - \mathcal{E} (I_\textrm{reg}) \|_2^2 \end{equation}\]위의 guidance는 latent feature 사이의 공간 정렬과 색상 일관성을 반복적으로 강제하고 생성된 latent를 가이드하여 레퍼런스 latent의 콘텐츠를 보존할 수 있다. 따라서 레퍼런스 이미지 \(I_\textrm{reg}\)에서 얼마나 많은 정보가 유지되는지 제어할 수 있으므로 생성된 출력에서 보다 원활한 결과로 전환할 수 있다. Latent image guidance의 전체 알고리즘은 Algorithm 1에 설명되어 있다.

Experiments
- 데이터셋
- BIR: ImageNet 512$\times$512
- BFR: FFHQ 512$\times$512
- BSR: RealSRSet
- 구현 디테일
- 복원 모듈
- residual Swin Transformer block (RSTB): 8개
- 각 RSTB의 Swin Transformer Layer (STL): 6개
- head 수: 6
- window 크기: 8
- iteration: 15만
- batch size: 96
- 생성 prior
- Stable Diffusion 2.1-base를 fine-tuning
- batch size: 192
- iteration: 2.5만
- optimizer: Adam
- learning rate: $10^{−4}$
- 8개의 NVIDIA A100 GPU를 사용
- Inference: 50 timestep의 DDPM 샘플링
- 복원 모듈
1. Comparisons with State-of-the-Art Methods
BSR on real-world dataset
다음은 SOTA BSR 및 ZIR 방법들과 4배 업샘플링한 현실 데이터셋에 대하여 비교한 표이다.

다음은 4배 업샘플링한 현실 데이터셋에 대하여 시각적으로 비교한 것이다.

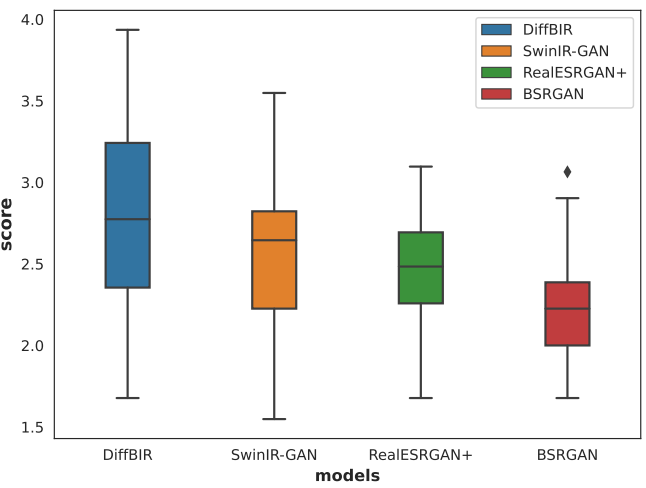
다음은 user study의 점수 분포이다.
BFR on both synthetic and real-world datasets
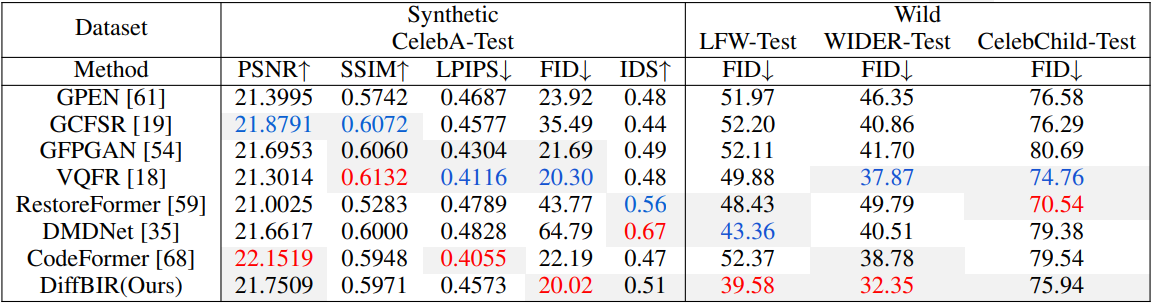
다음은 SOTA BFR 방법들과 합성 데이터셋과 현실 데이터셋에 대하여 비교한 표이다.
다음은 합성 데이터셋에서 여러 BFR 방법들을 정량적으로 비교한 것이다.

다음은 현실 데이터셋에서 여러 BFR 방법들을 정량적으로 비교한 것이다.

2. Ablation Studies
The Importance of Restoration Module
다음은 복원 모듈 유무에 따른 결과를 비교한 것이다.


The Necessity of Finetuning Stable Diffusion
다음은 Stable Diffusion fine-tuning 유무에 따른 결과를 비교한 것이다.

The Effectiveness of LAControlNet
다음은 ControlNet을 사용한 결과와 LAControlNet을 사용한 결과를 비교한 것이다.

The Flexibility of Controllable Module
다음은 latent image guidance의 scale에 따른 결과들이다.

Limitations
- 텍스트 기반 이미지 복원의 잠재력은 탐구되지 않았다.
- 낮은 품질의 이미지를 복원하기 위해 50개의 샘플링 step이 필요하므로 다른 이미지 복원 방법에 비해 훨씬 더 많은 계산 리소스 소비와 더 많은 inference 시간이 필요하다.