[논문리뷰] Diff-TTSG: Denoising probabilistic integrated speech and gesture synthesis
ISCA SSW 2023. [Paper] [Page] [Github]
Shivam Mehta, Siyang Wang, Simon Alexanderson, Jonas Beskow, Éva Székely, Gustav Eje Henter KTH Royal Institute of Technology
15 Jun 2023
Introduction
대면 인간 의사소통에는 음성 및 비언어적 측면이 모두 포함된다. 후자는 시선, 얼굴 표정, 말과 동시에 발생하는 머리, 팔, 손, 신체 움직임과 같은 말과 함께 하는 제스처를 포함한다. 음성과 제스처 modality는 밀접하게 연결되어 있으며 speaker가 전달하려는 메시지의 공유된 표현에서 비롯된다. 제스처는 말한 단어를 보완하거나 보완할 수 있으며 단어를 완전히 대체할 수도 있다. 결정적으로, 제스처의 존재는 인간-인간과 인간-기계 소통 모두를 향상시킨다. 이러한 이유로 음성과 제스처의 자동 합성은 가상 아바타와 소셜 로봇과 같은 Embodied Conversational Agent (ECA)의 핵심 구현 기술로 간주된다.
인간의 음성과 비언어적 의사소통의 공통 기원에도 불구하고, 음성 합성과 제스처 생성은 지금까지 겹치지 않는 별도의 문제로 취급되었다. TTS 연구와 데이터는 역사적으로 성우가 큰 소리로 읽어주는 음성에 초점을 맞추는 반면, 인간의 몸짓은 대화에서 말하는 자발적인 음성과 관련된다. 읽기 스타일의 TTS와 자발적 음성 제스처 변환(STG)을 결합하여 일반적으로 서로 다른 연기자의 데이터에 대해 학습된 두 가지 시스템을 사용하면 ECA에서 일관되지 않은 표현이 생성된다. 또한 STG 학습 중에 사용되는 자연 음성 오디오와 합성 시간에 제스처를 구동하는 데 사용되는 합성 오디오 간의 불일치로 인해 제스처 품질이 저하될 수 있다.
위의 불일치에 주목하면서 두 modality의 합성을 하나의 단일 텍스트 기반 시스템으로 통합하기 위한 몇 가지 제안이 있었다. 이 문제는 통합 음성 및 제스처 합성 또는 ISG라고 한다. 이것은 인간의 의사소통 행동이 생성되는 얽힌 방식과 더 유사할 뿐만 아니라 제스처-동작 합성과 음성-합성 음향 모델링이 수학적으로 매우 유사한 문제이기 때문에 설득력이 있다. 둘 다 텍스트를 입력으로 받아들이고 일련의 연속 값 벡터를 출력으로 생성할 수 있다. 따라서 유사한 접근 방식을 사용하여 모델링할 수 있다. ISG는 또한 중복을 제거하여 더 빠르게 실행할 수 있는 더 작은 시스템을 가능하게 한다.
그러나 TTS가 녹음된 사람의 음성과 유사한 자연스러움 점수에 도달할 수 있는 텍스트에서 소리낸 음성을 합성하는 것과는 달리 자발적인 음성 합성과 제스처 동작의 합성은 둘 다 더 어려운 모델링 문제를 나타낸다. 두 가지 문제를 동시에 해결하는 방법을 배우는 접근 방식은 아직 초기 단계에 있으며 흥미로운 연구 대상이다. 문제는 고품질 데이터의 부족 (ex. 제어된 조건에서 자발적인 음성이 거의 캡처되지 않음, 정확한 3D 모션 데이터에는 마커 기반 모션 캡처가 필요함)과 이러한 데이터의 다양한 동작과 표현으로 인해 발생한다. 따라서 인간의 의사소통 행동의 전체 스펙트럼에 대한 정확한 설명은 강력한 심층 생성 모델을 기반으로 한 확률론적 접근 방식을 요구한다.
본 논문에서는 텍스트로부터 음성 오디오와 신체 제스처를 함께 합성하는 학습을 위한 첫 번째 diffusion model을 제안하였다. 이전 ISG SOTA와 달리 본 논문의 접근 방식은 확률적이고 non-autoregressive하며 중요한 것은 처음부터 작은 데이터셋에 대해 학습할 수 있다는 것이다. 이렇게 하면 대규모 음성 데이터셋에 대한 사전 학습과 네트워크 일부가 고정된 다단계 학습에 대한 이전 요구 사항이 제거된다. 저자들은 uni-modal 및 multi-modal 주관적 테스트를 모두 사용하여 서로 다른 modality에 대한 적합성에서 서로의 합성 품질을 분리하였다.
Method
본 논문의 task는 TTS 프런트엔드에서 추출한 음소와 같은 일련의 텍스트 파생 feature $s_{1:P}$가 입력으로 주어졌을 때 말하고 몸짓을 하는 캐릭터에 대해 일치하는 3D 포즈 $g_{1:T’}$의 동기화된 시퀀스와 함께 $T$개의 acoustic feature 벡터 시퀀스 $x_{1:T}$를 생성하는 것이다. 음향 및 모션 데이터는 실제로 다른 프레임 속도를 가질 수 있지만 (종종 음향의 경우 약 80fps, 모션의 경우 30/60fps), 모션이 원하는 fps로 리샘플링된 모델 출력과 함께 모델링 목적을 위해 오디오 프레임 속도와 일치하도록 모션이 업샘플링 또는 보간되었다고 가정한다 (따라서 $T’ = T$).
1. Grad-TTS
Grad-TTS는 diffusion model을 사용하여 출력 음향, 특히 mel-spectrogram을 샘플링하는 TTS 시스템이다. $P$개의 기호 (ex. 음소 또는 하위 음소)의 시퀀스 $s_{1:P}$를 입력으로 할 때 세 부분으로 구성된다.
- 인코더: 모든 입력 기호에 대한 평균 mel-spectrogram \(\tilde{\mu}_{1:P} = \textrm{Enc} (s_{1:P})\)을 예측
- Duration predictor: \(\tilde{\mu}_{1:P}\)를 사용하여 로그 스케일의 duration \(\log \hat{d}_{1:P} = \textrm{DP} (\tilde{\mu}_{1:P})\)를 예측
- U-Net 디코더: \(\hat{x}_{1:T} = \textrm{Dec} (\tilde{y}_{1:T}, \mu_{1:T}, n)\), noisy한 mel-spectrogram \(\tilde{y}_{1:T}\)를 denoise하도록 학습 (Diffusion model)
인코더는 입력 시퀀스의 각 기호 (일반적으로 음소당 두 개의 기호)에 대해 하나씩 평균 벡터 시퀀스 \(\tilde{\mu}_{1:P}\)를 예측한다. 각 벡터 \(\tilde{\mu}_p\)를 각 음소의 duration에 해당하는 가변 횟수로 복제함으로써 \(\tilde{\mu}_{1:P}\)가 업샘플링되어 타겟 mel-spectrogram $y_{1:T}$의 대략적인 근사 $\tilde{\mu}_{1:T}$를 얻는다.
학습 중에 정렬하는 방법을 배우기 위해 Grad-TTS는 HMM 학습의 Viterbi 알고리즘과 유사한 동적 프로그래밍 알고리즘인 monotonic alignment search를 사용한다. 이 절차는 $\mu_{1:T}$와 $y_{1:T}$ 사이의 제곱 오차를 최소화하는 최적의 duration (업샘플링 수) $d_{1:P}$를 식별한다. 그런 다음 duration 예측자는 이러한 최적 duration의 로그 ($\log d_{1:P}$)를 예측할 때 평균 제곱 오차를 최소화하도록 학습된다. 합성 중에 \(\tilde{\mu}_{1:P}\)는 $\mu_{1:T}$를 얻기 위해 duration predictor의 출력을 기반으로 업샘플링된다.
Grad-TTS는 Glow-TTS와 동일한 인코더와 duration predictor를 사용했다. GlowTTS와의 주요 차이점은 Grad-TTS의 U-Net 디코더로, 데이터 분포에서 샘플을 생성하는 데 사용되는 $\mu_{1:T}$로 컨디셔닝된 diffusion model을 정의한다. 이 네트워크는 score matching 프레임워크를 사용하여 학습된다. 본질적으로 noisy한 mel-spectrogram \(\tilde{y}_{1:T}\)는 타겟 mel-spectrogram $y_{1:T}$와 $\mathcal{N} (\mu_{1:T}, I)$에서의 샘플 사이를 보간하여 생성된다. $\textrm{Dec}$는 이러한 noisy한 예시에서 원래 $y_{1:T}$를 예측할 때 평균 제곱 오차를 최소화하도록 학습된다. 이러한 방식으로 학습된 $\textrm{Dec}$는 $\mathcal{N} (\mu_{1:T}, I)$에서의 샘플을 mel-spectrogram의 자연 분포 샘플로 변환하는 SDE를 정의하는 것으로 볼 수 있다.
U-Net은 이미지 모델과 동일한 기본 아키텍처 (2D CNN 포함)를 사용하여 mel-spectrogram을 2D 이미지로 효과적으로 처리한다. \(\tilde{y}_{1:T}\) 외에도 U-Net은 $\mu_{1:T}$와 추가된 noise의 양 (SDE의 “시간 차원” $n$을 나타냄)으로 컨디셔닝된다. 또한 noise 소스에 $\mathcal{N} (\mu_{1:T}, I)$을 사용하면 보다 일반적인 선택 $\mathcal{N}(0,I)$과 동일한 분포를 학습할 수 있지만 실제로는 더 나은 결과를 제공한다는 것을 보여준다.
학습된 diffusion model로부터의 합성은 예를 들어 1차 오일러 방식을 사용하여 $\textrm{Dec}$에 의해 정의된 SDE를 수치적으로 해결하는 것과 같다. 이를 위해서는 많은 discretization step이 필요하므로 시간이 많이 소요될 수 있다. 이러한 이유로 Grad-TTS는 샘플을 추출할 때 발생하는 SDE denoising process의 상미분 방정식(ODE) 재구성을 사용한다. ODE는 학습된 SDE와 동일한 목적 함수 분포를 설명하지만 샘플을 더 빠르게 생성하기 위해 대략적인 discretization을 사용하여 해결했을 때 수치적 속성이 더 우수하고 우수한 출력 품질을 제공한다.
2. Modelling speech and motion with Diff-TTSG
수학적으로 모션은 3D 캐릭터에 대한 포즈 $g_t$의 시퀀스 $g_{1:T}$로 표현된다. 벡터 $g_t$의 숫자는 3D 공간에서 캐릭터의 “루트 노드” (일반적으로 엉덩이 뼈)의 평행 이동과 회전과 같은 양을 나타내며 캐릭터의 골격에 있는 여러 관절의 회전을 나타낸다. 이러한 회전은 예를 들어 오일러 각도 또는 exponential map을 사용하여 parameterize될 수 있다. $g_t$에 지정된 회전에 따라 3D 캐릭터 모델의 관절을 구부려서 특정 포즈를 얻는다. 이는 예술가가 관절을 구부려 나무 마네킹의 자세를 취하는 것과 유사하다.
원칙적으로 스택/concat된 자세와 음향 벡터 $[g_t^\top, x_t^\top]^\top$에서 TTS 모델을 학습할 수 있지만 실제로는 Glow-TTS나 Grad-TTS를 사용하지 않고 잘 작동하지 않는다. 예를 들어 Grad-TTS에서 사용하는 U-Net 아키텍처는 feature 벡터 차원을 4로 나눌 수 있다고 가정한다. 이는 포즈 표현에서는 거의 발생하지 않는다. 벡터 차원이 4로 나눌 수 있을 때까지 결합된 feature를 추가 값으로 채우기만 하면 불안하고 품질이 낮은 제스처가 생성된다.
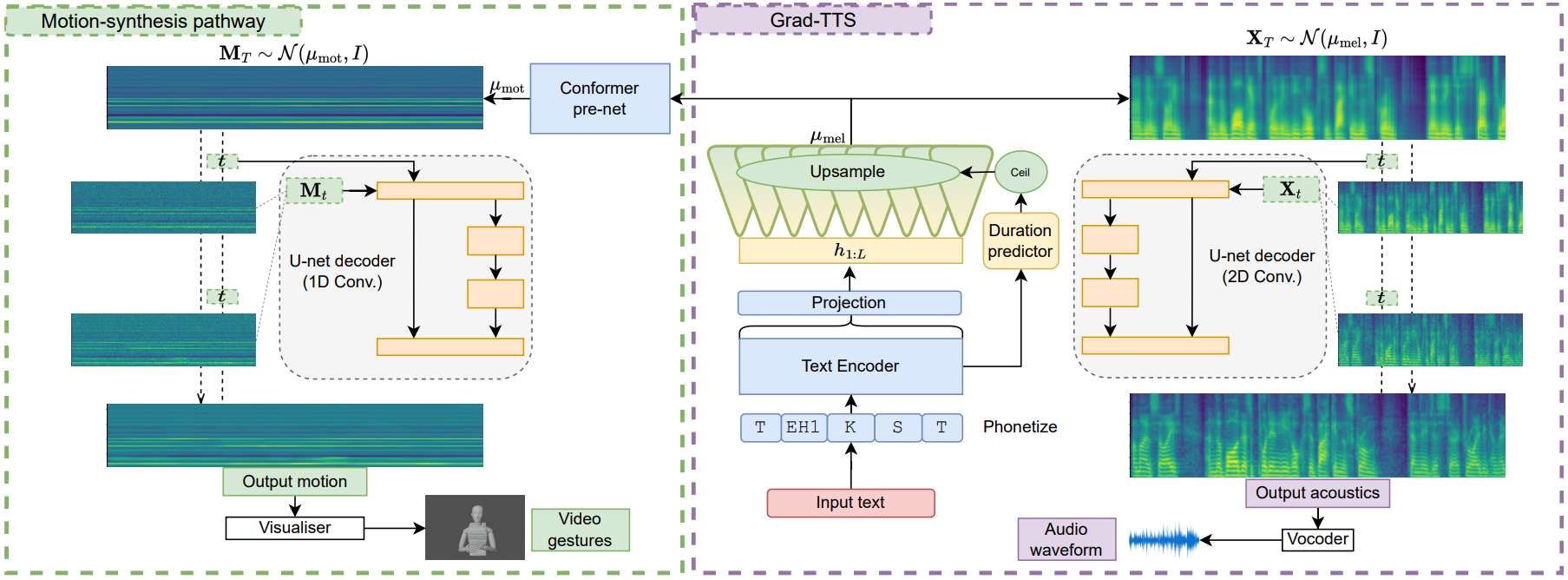
저자들은 우수한 음성 및 제스처 모델을 함께 얻기 위해 Grad-TTS 아키텍처를 여러 번 변경하여 위 그림에 표시된 아키텍처를 만들었다. 구체적으로 Conformer “pre-net”을 통합하여 업샘플링된 디코더 출력 $\mu_{1:T}$를 포즈 feature에 대한 해당 평균 예측 \(\mu'_{1:T}\)에 매핑했다. 또한 \(\mathcal{N} (\mu'_{1:T}, I)\)에서 샘플링된 noise를 설득력 있는 포즈 시퀀스 $g_{1:T}$로 바꾸는 역할을 하는 별도의 dneoising 경로(그림의 왼쪽)를 추가했다.
이 모델을 Diff-TTSG (diffusion-based text-to-speech-and-gesture)라고 부른다. 새 구성요소와 기존 구성요소는 Grad-TTS와 정확히 동일한 방식으로 함께 학습할 수 있으며 음향 및 제스처 diffusion 경로 모두에 대한 loss 항을 합산한다.
실험을 위해 저자들은 시간 차원 $t$에 따라 모든 2D convolution을 1D convolution으로 대체한 것을 제외하고는 음향 합성 (즉, Grad-TTS의 것)에 사용된 것과 동일한 포즈 합성 경로에서 동일한 U-Net 아키텍처를 채택했다. 이는 mel 스케일의 인근 주파수 bin과 달리 포즈 표현 $g_t$의 개별 feature가 단순한 공간 관계가 없기 때문에 convolution을 이미지와 mel-spectrogram에 적합하게 만드는 근사적 변환 불변성을 가지지 않기 때문에 중요하다. 위 그림의 포즈 벡터 (얇은 가로 줄무늬)는 이를 반영한다. 1D convolution으로 변경하면 $g_t$의 차원이 더 이상 4로 균등하게 나누어지지 않아도 된다.
또한 저자들은 제스처 U-Net에서 WaveGrad의 대체 U-Net 아키텍처를 사용하여 실험했다. 그러나 이로 인해 관절 회전 공간의 기원인 T-포즈와 같이 팔을 뻗은 덜 자연스러운 제스처가 발생했다.
Experiments
- 데이터셋: Trinity Speech-Gesture Dataset II (TSGD2)
- 6시간의 44kHz 음성 + 120fps 마커 기반 모션캡처 영상
- 6시간 중 4.5시간을 학습에 사용하고 1.5시간은 validation과 테스트에 사용
- 오디오는 숨소리를 기준으로 구분
- Whisper ASR로 전사
- acoustic feature는 HiFi-GAN과 동일하게 80차원
- 모션 데이터 (45차원)는 cubic interpolation을 사용하여 86.13fps로 다운샘플링됨
- 손가락 모션캡처는 신뢰할 수 없는 것으로 악명 높고 부자연스럽게 보이는 아티팩트가 나오기 쉽기 때문에 무시
평가에 사용된 인터페이스는 아래와 같다.
다음은 세 가지 평가에 대한 MOS 점수이다. 각 평가의 스케일은 Speech only와 Gesture only는 1~5, Speech and gesture는 -2~2이다.