[논문리뷰] Diff-Font: Diffusion Model for Robust One-Shot Font Generation
arXiv 2022. [Paper] [Github]
Haibin He, Xinyuan Chen, Chaoyue Wang, Juhua Liu, Bo Du, Dacheng Tao, Yu Qiao
Wuhan University | Shanghai AI Laboratory | JD Explore Academy | The University of Sydney | Chinese Academy of Sciences
9 Jul 2023
Introduction
단어는 우리 일상에 편재하기 때문에 폰트 생성은 상당한 상업적 가치와 응용 가능성을 가지고 있다. 그러나 폰트 라이브러리를 디자인하는 것은 특히 중국어 (60,000개 이상의 glyph 포함)와 한국어 (11,000개 이상의 glyph 포함)와 같이 복잡한 구조를 가진 glyph가 풍부한 언어의 경우 매우 어려운 task가 될 수 있다. 최근 고품질 이미지를 생성하는 능력으로 알려진 심층 생성 모델의 발전으로 다양한 폰트 라이브러리를 자동으로 생성할 수 있는 가능성이 나타났다.
Zi2zi는 한 스타일 폰트에서 다른 스타일 폰트로의 매핑을 학습하여 자동으로 중국어 폰트 라이브러리를 생성하기 위해 GAN을 채택한 최초의 모델이다. 새로운 폰트의 자동 합성을 쉽게 하기 위해 수많은 few-shot (또는 one-shot) 폰트 생성 (FFG) 방법이 제안되었습다. 이러한 방법들은 문자 이미지를 콘텐츠로 사용하고 몇 개(또는 하나)의 타겟 문자를 사용하여 폰트 스타일을 제공한 다음 타겟 폰트 스타일로 콘텐츠 캐릭터의 이미지를 생성하도록 모델을 학습시킨다. 대부분의 기존 FFG 방법은 GAN 기반 image-to-image translation 프레임워크를 기반으로 구축된다. 일부 연구들은 unsupervised 방법을 따라 콘텐츠와 스타일 feature를 별도로 얻은 다음 generator에서 융합하여 새로운 문자를 생성한다. 한편, 다른 연구들은 보조 주석 (ex. 획, 자모)을 활용하여 모델이 glyph에 대한 특정 구조 및 디테일을 인식하도록 한다.
GAN 기반 방법이 상당한 발전을 이루고 인상적인 시각적 품질을 달성했지만 폰트 생성은 복잡한 디테일에 대한 엄격한 요구로 인해 악명 높은 long-tail task로 남아 있다. 대부분의 기존 방법은 여전히 세 가지 유형의 문제와 씨름하고 있다.
- GAN 기반 방법은 특히 대규모 데이터셋에서 불안정한 학습과 및 수렴 문제를 경험할 수 있다.
- 일반적으로 폰트 생성을 소스 이미지 도메인과 타겟 이미지 도메인 간의 style transfer 문제로 취급하므로 콘텐츠와 문자의 폰트 스타일을 별도로 모델링하지 못하는 경우가 많다. 결과적으로 중요한 폰트 스타일 변경이 만족스러운 결과를 가져오거나 두 개의 유사한 폰트 간의 미묘한 변형이 적절하게 모델링되지 않는다.
- 마지막으로 소스 문자가 복잡해지면 생성된 문자 구조의 무결성을 보장하는 데 어려움을 겪을 수 있다.

본 논문은 앞서 언급한 문제를 해결하기 위해 one-shot 폰트 생성을 위한 Diff-Font라는 새로운 diffusion model 기반 프레임워크를 도입한다. 폰트 생성을 소스 폰트 도메인과 타겟 폰트 도메인 간의 style transfer로 처리하는 대신 Diff-Font는 폰트 생성을 조건부 생성 task로 간주한다. 특히 유사한 glyph에서 혼동을 일으킬 수 있는 이전 연구들에서 사용된 이미지 입력과 달리 서로 다른 문자 콘텐츠가 고유한 토큰으로 사전 처리된다. 폰트 스타일과 관련하여 사전 학습된 스타일 인코더를 사용하여 스타일 feature를 조건부 입력으로 추출한다.
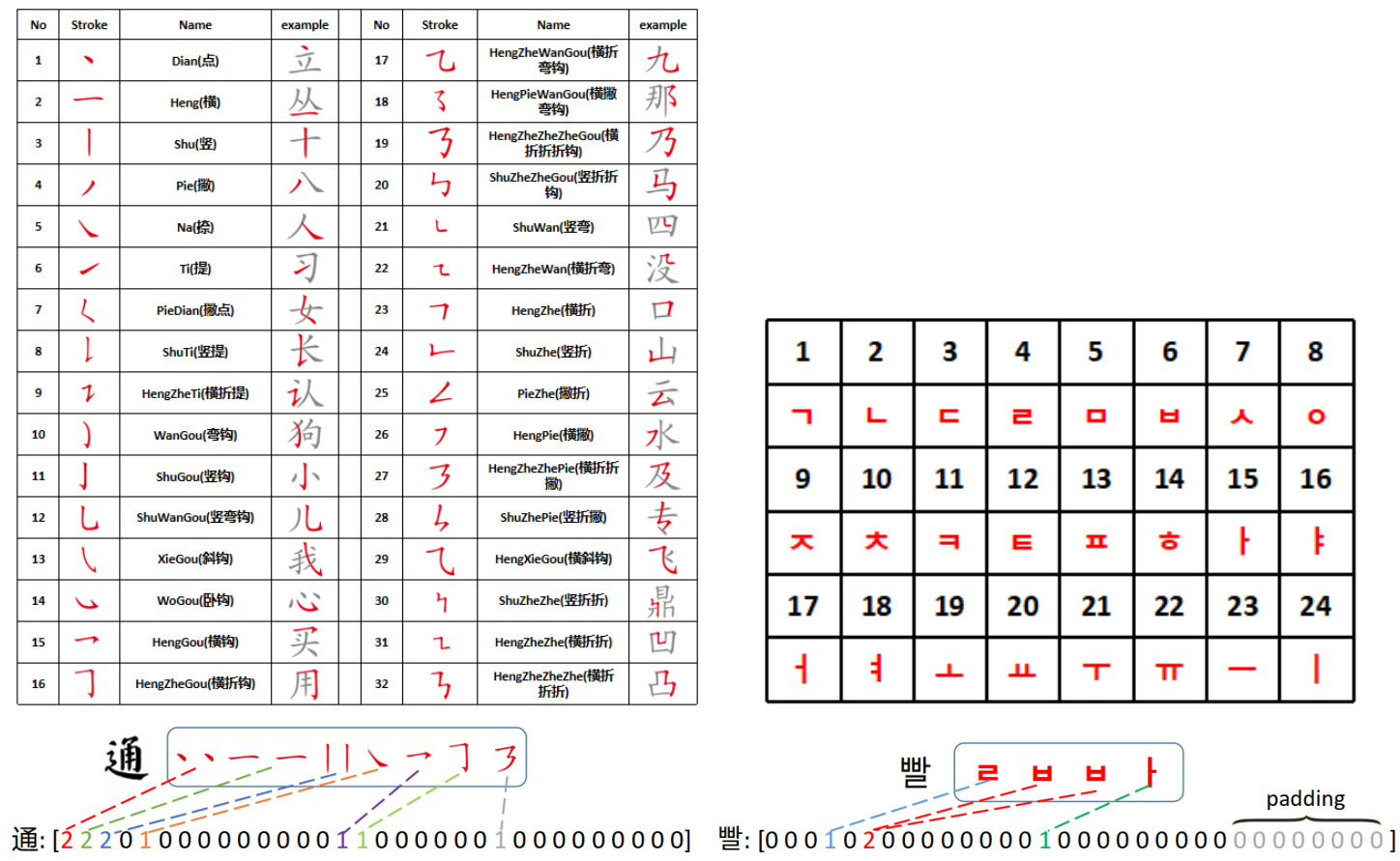
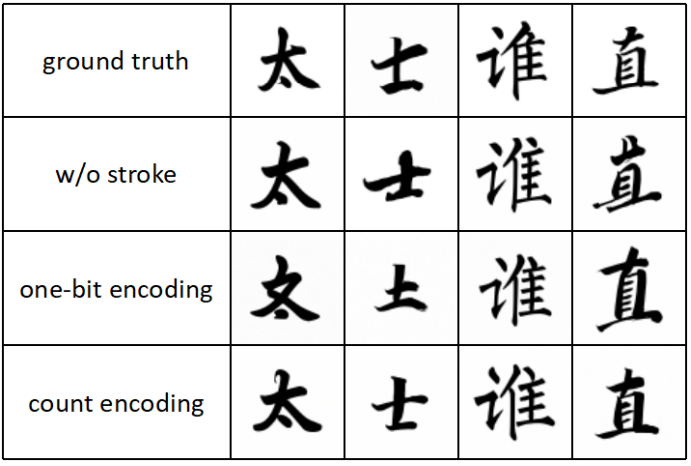
또한 glyph가 풍부한 문자와 관련된 부정확한 생성 문제를 완화하기 위해 DiffFont가 문자 구조를 더 잘 모델링할 수 있도록 더 세분화된 조건 신호를 통합한다. 중국어 폰트의 경우 획은 한자를 구성하는 가장 작은 단위를 나타내므로 획 조건을 사용한다. 마찬가지로 한글의 자모는 한글 폰트 생성을 위한 추가 조건 입력 역할을 한다. 1비트 인코딩을 사용하는 대신 획(자모) 속성을 나타내는 카운트 인코딩을 사용하여 캐릭터의 획(자모) 속성을 보다 정확하게 반영한다.
결과적으로 Diff-Font는 문자의 콘텐츠와 스타일을 효과적으로 분리하여 복잡한 문자에 대한 고품질 생성 결과를 생성한다. 동시에 조건부 생성 파이프라인과 diffusion process 덕분에 DiffFont는 이전 GAN 기반 방법에 비해 향상된 학습 안정성을 나타내면서 대규모 데이터셋에서 학습할 수 있다. 마지막으로 중국어 폰트 생성을 위한 획 데이터셋과 한국어 폰트 생성을 위한 자모 데이터셋을 조합한다.
Methodology
1. The Framework of Diff-Font
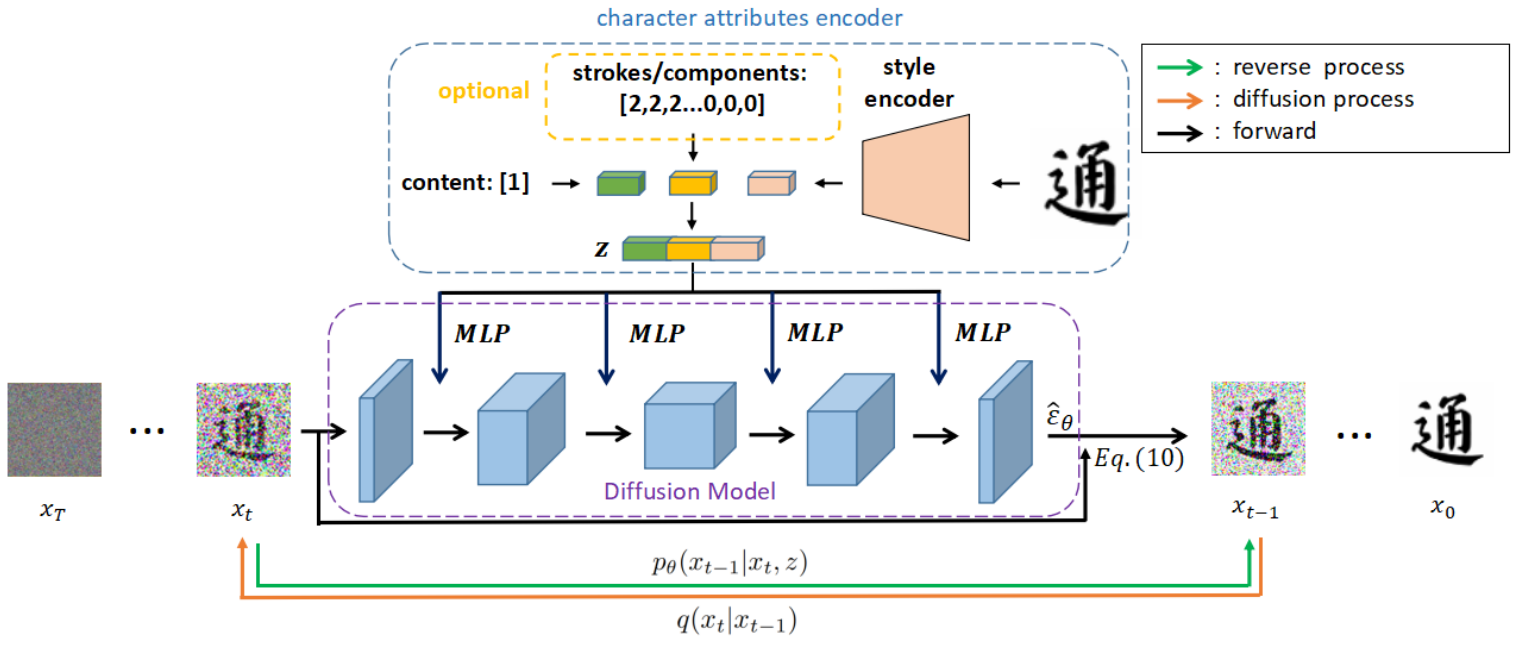
Diff-Font의 프레임워크는 위 그림에 설명되어 있다. Diff-Font는 두 개의 모듈로 구성된다. Latent 변수와 diffusion model은 latent 변수를 조건으로 사용하여 Gaussian noise에서 문자 이미지를 생성한다. 문자 속성 인코더는 문자 이미지의 속성 (콘텐츠, 스타일, 획, 자모)을 별도로 처리하도록 설계되었다.
문자 속성 인코더 $f$에서 콘텐츠 $c$, 스타일 $s$, 선택적 조건 (획 또는 자모) $op$는 latent 변수로 인코딩된다.
\[\begin{equation} z = f(c, s) \end{equation}\]선택적 조건을 사용하는 경우
\[\begin{equation} z = f(c, s, op) \end{equation}\]이다. 콘텐츠 표현을 얻기 위해 소스 도메인의 이미지를 사용하는 image-to-image translation을 기반으로 하는 이전 폰트 생성 방법과 달리 콘텐츠 문자를 서로 다른 토큰으로 간주한다. NLP의 단어 임베딩과 유사하게 임베딩 레이어를 채택하여 다양한 문자 토큰을 다양한 콘텐츠 표현으로 변환한다.
스타일 표현은 사전 학습된 스타일 인코더에 의해 추출된다. DG-Font의 학습된 스타일 인코더는 사전 학습된 스타일 인코더로 사용되며 해당 파라미터는 diffusion model 학습에서 고정된다. 획(자모)의 경우 각 문자를 32차원 벡터로 인코딩한다. 벡터의 각 차원은 포함된 해당 기본 획(자모)의 수를 나타낸다 (아래 그림 참조). 이 카운트 인코딩은 1비트 인코딩보다 문자의 획(자모) 속성을 더 잘 나타낼 수 있다. 그 후, 획(자모) 벡터는 포함된 콘텐츠의 차원과 일치하는 벡터로 확장될 수 있다. 이 방법을 사용하여 문자 이미지의 속성 표현을 얻은 다음 나중에 조건부 diffusion model 학습을 위해 조건 $z$로 concat할 수 있다.
Diffusion process에서 실제 이미지 $x_0$에서 noise $x_T$까지의 긴 Markov chain을 얻기 위해 랜덤 Gaussian noise를 실제 이미지 $x_0$에 천천히 추가한다. UNet 아키텍처를 diffusion model로 채택하고 ADM을 따라 reverse process를 학습한다. Reverse process는 다중 속성 조건 latent 변수 $z$를 사용하여 Gaussian noise에서 문자 이미지를 생성한다. 이 조건부 생성은 폰트 스타일 차이의 영향을 완화하도록 설계되었다.
2. Multi-Attributes Conditional Diffusion Model
콘텐츠 속성 $c$, 스타일 속성 $s$에 의해 결정되는 문자의 각 이미지를 전체 학습 데이터 분포의 샘플로 간주하고 샘플을
\[\begin{equation} x_0 \sim q(x_0 \vert f(c, s)) \end{equation}\]로 표시한다. 선택적 조건 $op$를 사용하면
\[\begin{equation} x_0 \sim q(x_0 \vert f(c, s, op)) \end{equation}\]이다. 이미지에 랜덤 Gaussian noise를 수천 번 추가하여 안정 상태에서 혼돈 상태로 점진적으로 변환한다. 이 과정을 diffusion process라고 하며 다음과 같이 정의할 수 있다.
\[\begin{equation} q(x_{1:T} \vert x_0) = \prod_{t=1}^T q(x_t \vert x_{t-1}) \\ q(x_t \vert x_{t-1}) = \mathcal{N} (x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) \end{equation}\]여기서 $\beta_1 < \cdots < \beta_T$는 분산 schedule이다. $x_t$는 다음과 같이 다시 쓸 수 있다.
\[\begin{equation} x_t \sim \mathcal{N} (x_t; \sqrt{\vphantom{1} \bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) I) \\ \alpha_t = 1 - \beta_t, \quad \bar{\alpha}_t = \prod_{i=1}^t \alpha_i, \quad \epsilon \sim \mathcal{N} (0,I) \end{equation}\]$T \rightarrow \infty$이면 \(\bar{\alpha}_t\)가 0에 가까워지고 $x_T$가 $\mathcal{N}(0,I)$에 가까워진다. 따라서 reverse process에서 가우시안 분포에서 noise 이미지 $x_T$를 샘플링하고 다중 속성 조건 $z = f(c, s)$를 사용하여 긴 Markov chain에서 $x_T$를 denosing하여 지정된 semantic 의미를 포함하는 문자 이미지를 생성할 수 있다. 사후 확률 분포 $q(x_{t-1} \vert x_t)$는 추정하기 어렵기 때문에 $p_\theta$를 사용하여 다음과 같은 사후 확률 분포를 근사화한다.
\[\begin{equation} p_\theta (x_{0:T} \vert z) = p(x_T) \prod_{t=1}^T p_\theta (x_{t-1} \vert x_t, z) \\ p_\theta (x_{t-1} \vert x_t, z) = \mathcal{N} (\mu_\theta (x_t, t, z), \Sigma_\theta (x_t, t, z)) \end{equation}\]DDPM을 따라 $\Sigma_\theta (x_t, t, z)$를 상수로 설정하고 diffusion model $\epsilon_\theta (x_t, t, z)$는 더 쉬운 학습을 위해 $x_t$와 조건 $z$에서 diffusion process에서 $x_0$에 추가되는 noise를 예측하는 방법을 학습한다. 이러한 간소화된 연산을 통해 표준 MSE loss를 채택하여 다중 속성 조건부 diffusion model을 학습할 수 있다.
\[\begin{equation} L_\textrm{simple} = \mathbb{E}_{x_0 \sim q (x_0), \epsilon \sim \mathcal{N} (0,I), z} [\| \epsilon - \epsilon_\theta (x_t, t, z) \|^2] \end{equation}\]3. Attribute-wise Diffusion Guidance Strategy
Glyph가 풍부한 스크립트 (ex. 중국어, 한국어)의 경우 생성 효과를 개선하기 위해 2단계 학습 전략을 채택한다. 다중 속성 조건부 학습 (즉, 첫 번째 학습 단계)을 기반으로 콘텐츠 속성 또는 획(또는 자모) 속성 벡터를 30% 확률로 랜덤으로 제거하는 fine-tuning 전략 (두 번째 학습 단계)도 설계한다. 콘텐츠와 획(또는 자모)가 동시에 제거되면 스타일 속성 벡터도 제거된다. 이러한 전략에는 두 가지 장점이 있다.
- 모델이 이 세 가지 속성에 더 민감하게 반응할 수 있다.
- 3개가 아닌 2개의 guidance scale만 필요하므로 hyperparameter의 수를 줄일 수 있다.
본 논문의 경우, 제거된 속성 벡터를 대체하기 위해 0 벡터 $\textbf{0}$를 사용한다. 샘플링할 때 예측 noise를 \(\hat{\epsilon}_\theta\)로 수정한다.
\[\begin{aligned} \hat{\epsilon}_\theta (x_t, t, f(c, s, op)) &= \epsilon_\theta (x_t, t, \textbf{0}) \\ &+ s_1 \cdot (\epsilon_\theta (x_t, t, f(c, s, \textbf{0})) - \epsilon_\theta (x_t, t, \textbf{0})) \\ &+ s_2 \cdot (\epsilon_\theta (x_t, t, f(\textbf{0}, s, op)) - \epsilon_\theta (x_t, t, \textbf{0})) \end{aligned}\]여기서 $s_1$과 $s_2$는 콘텐츠와 획의 guidance scale이다. 그런 다음 diffusion step \(\{\tau_1, \cdots, \tau_S\}\)의 부분 집합에서 샘플링하기 위해 DDIM을 채택하고 생성 프로세스 속도를 높이기 위해 분산 가중치 파라미터 $\eta = 0$을 설정한다. 따라서 다음 방정식으로 $x_{\tau_i}$에서 $x_{\tau_{i-1}}$을 얻을 수 있다.
\[\begin{equation} x_{\tau_{i-1}} = \sqrt{\vphantom{1} \bar{\alpha}_{\tau_{i-1}}} \bigg( \frac{x_{\tau_i} - \sqrt{1 - \bar{\alpha}_{\tau_i}} \hat{\epsilon}_\theta}{\sqrt{\vphantom{1} \bar{\alpha}_{\tau_i}}} \bigg) + \sqrt{1 - \bar{\alpha}_{\tau_{i-1}}} \hat{\epsilon}_\theta \end{equation}\]위의 식을 반복하여 최종 문자 이미지 $x_0$를 얻을 수 있다.
Experiments
- 구현 디테일
- 문자 속성 인코더
- 스타일 인코더는 DG-Font와 동일
- 출력 feature map의 차원은 128
- 콘텐츠 속성과 선택적 속성의 경우 임베딩 레이어 사용, 스타일 속성은 MLP 사용
- 선택적 속성을 사용하는 경우 콘텐츠, 스타일, 선택적 속성 벡터의 차원은 각각 128, 128, 256
- 선택적 속성을 사용하지 않는 경우 콘텐츠, 스타일 속성 벡터의 차원은 각각 256, 256
- 속성 벡터들은 concat되어 512차원의 조건부 latent 벡터 $z$로 사용
- 다중 속성 조건부 diffusion model
- DDPM 아키텍처
- 샘플링의 경우 25 step
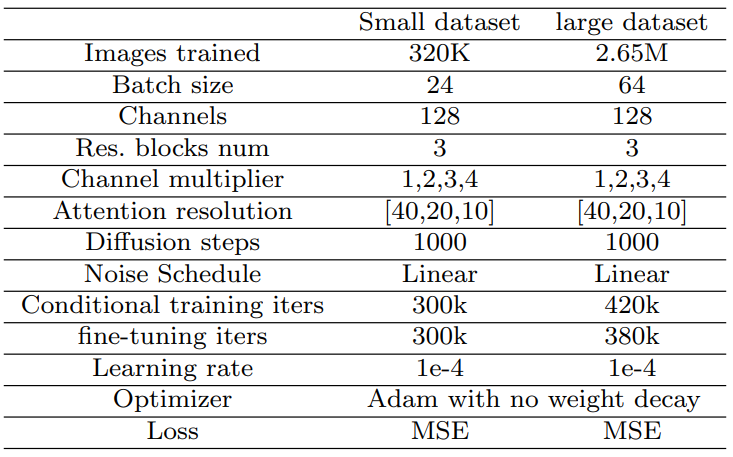
- hyperparameter는 아래 표 참조
- 문자 속성 인코더
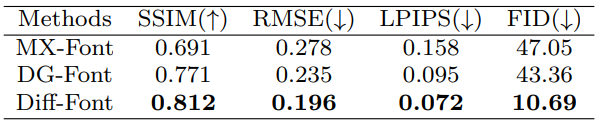
1. Comparison with state-of-the-art methods
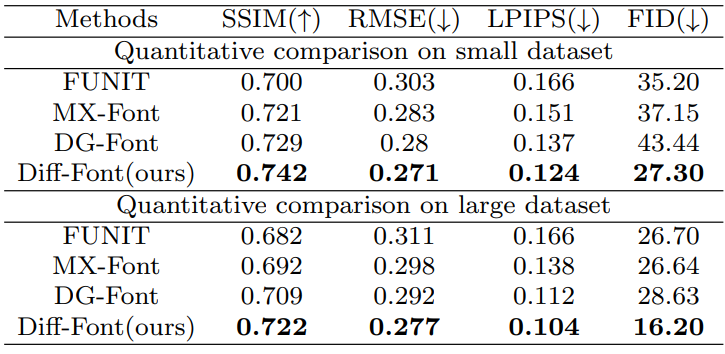
다음은 스케일이 다른 데이터셋에서의 정량적 성능 비교 결과이다.
다음은 대규모 테스트 데이터셋에 대한 생성 결과이다.

다음은 MX-Font, DG-Font와 아트 폰트에 대한 생성 결과를 비교한 것이다.

다음은 human testing의 예시이다.

다음은 human testing의 결과이다.

2. Ablation Studies
다음은 획 조건에 대한 ablation study 결과이다.

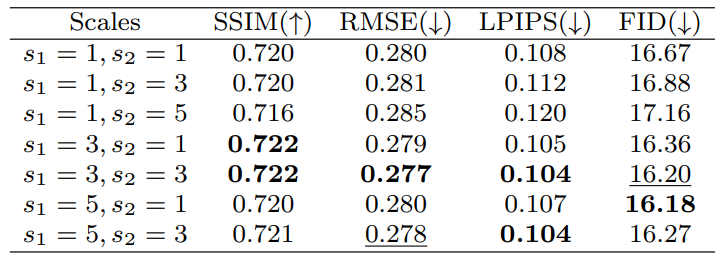
다음은 guidance scale의 영향을 비교한 표이다.
3. Korean Script Generation
다음은 한국어 스크립트에 대한 결과이다.

4. Other Script Generation
다음은 라틴 문자와 그리스 문자에 대한 예시이다.

5. Limitations
Diff-Font는 DDPM을 기반으로 하므로 inference 효율이 낮은 대부분의 기존 diffusion model과 동일한 문제가 있다. 또한 폰트 생성을 위해 획/자모 조건을 갖추면 생성 오류를 줄일 수 있지만 완전히 제거할 수는 없다. 학습 세트에서 드물게 접하게 되는 극도로 복잡한 구조 또는 흔하지 않은 스타일을 가진 일부 문자는 여전히 생성 실패를 겪고 있다. 일부 실패 사례는 아래 그림에 나와 있다.
