[논문리뷰] DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling
NeurIPS 2025 (Spotlight). [Paper] [Github]
Yuang Ai, Qihang Fan, Xuefeng Hu, Zhenheng Yang, Ran He, Huaibo Huang
CASIA | UCAS | ByteDance
16 May 2025

Introduction
Diffusion model에서 self-attention의 2차적인 계산 복잡도는 특히 고해상도 이미지 합성에서 상당한 어려움을 야기한다. Recognition task에서 ViT의 성공은 self-attention 메커니즘이 long-range dependency를 포착하는 능력 덕분으로 여겨진다. 그러나 generative task에서는 다른 양상이 관찰된다. 사전 학습된 클래스 조건부(DiT-XL/2) 및 텍스트-이미지(PixArt-α 및 FLUX) DiT 모델 모두에서 앵커 토큰으로 쿼리했을 때 attention은 주로 가까운 spatial token에 집중되고 멀리 있는 토큰은 대부분 무시된다. 이러한 결과는 global attention 메커니즘을 계산하는 것이 generative task에서는 불필요할 수 있음을 시사하며, 로컬한 공간적 모델링의 중요성을 강조한다. 장거리 상호작용이 글로벌한 semantic 추론에 중요한 recognition task와 달리, generative task는 세밀한 텍스처와 로컬한 구조적 충실도를 강조하는 것으로 보인다. 이러한 관찰 결과는 DiT에서 attention 메커니즘이 본질적으로 localize되어 있음을 보여주고, 보다 효율적인 아키텍처를 개발해야 할 필요성을 제기한다.
본 논문에서는 convolutional neural network (ConvNet)을 재조명하고 diffusion model에 최적화된 간단하면서도 매우 효율적인 convolutional backbone인 Diffusion ConvNet (DiCo)을 제안하였다. Self-attention과 비교했을 때, convolution 연산은 하드웨어 친화성이 뛰어나 대규모 및 자원 제약적인 환경에서의 배포에 상당한 이점을 제공한다. Self-attention을 convolution으로 대체하면 효율성은 크게 향상되지만, 일반적으로 성능 저하를 초래한다. 이러한 단순한 대체는 채널 중복성을 심화시켜 생성 프로세스에서 많은 채널이 비활성화 상태로 남게 된다. 이는 convolution에 비해 self-attention이 본질적으로 더 강력한 표현 능력을 가지고 있기 때문이다.
이러한 문제를 해결하기 위해, 본 논문에서는 가벼운 linear projection을 통해 유용한 채널을 동적으로 활성화하는 compact channel attention (CCA) 메커니즘을 제안하였다. 채널별 글로벌 모델링 접근 방식인 CCA는 낮은 계산 오버헤드를 유지하면서 모델의 표현 능력과 feature 다양성을 향상시킨다. DiCo는 효율적인 1$\times$1 pointwise convolution과 3$times3 depth-wise convolution을 기반으로 하는 간소화된 디자인을 채택했다. 이러한 단순한 구조에도 불구하고 DiCo는 강력한 생성 성능을 제공한다.
Method
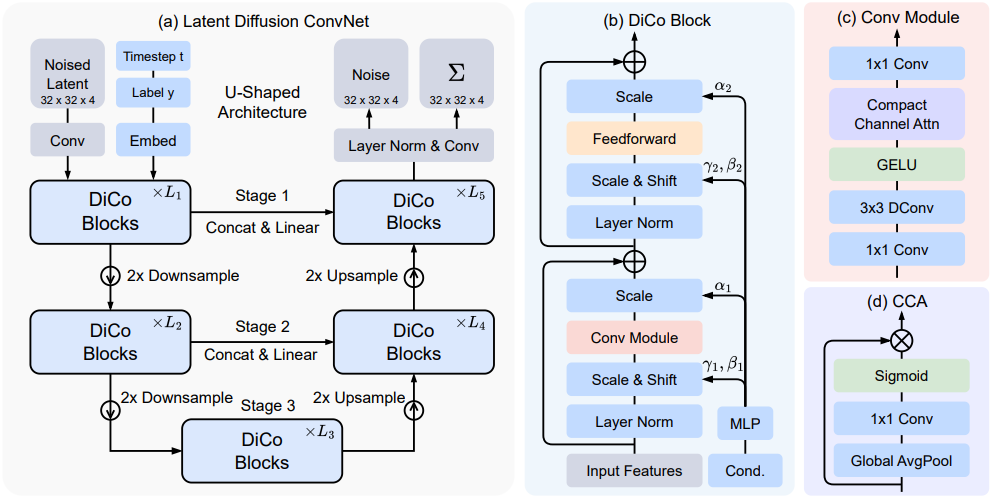
1. Network Architecture
현재 diffusion model은 크게 세 가지 아키텍처 유형으로 분류된다.
- Downsampling layer가 없는 등방성 아키텍처 (ex. DiT)
- 긴 skip connection들을 갖는 등방성 아키텍처 (ex. U-ViT)
- U자형 아키텍처 (ex. U-DiT)
이미지 denoising에서 멀티스케일 feature의 중요한 역할에 착안하여, 본 논문에서는 계층적 모델을 구축하기 위해 U자형 디자인을 채택했다.
DiCo는 적층된 DiCo block으로 구성된 3-stage U자형 아키텍처를 사용한다. 이 모델은 VAE 인코더에서 생성된 공간 표현 $z$를 입력으로 받는다. 256$\times$256$\times$3 크기의 이미지의 경우, $z$의 차원은 32$\times$32$\times$4이다. 이 입력을 처리하기 위해 DiCo는 3$\times$3 convolution을 적용하여 $z$를 $D$개의 채널을 가진 초기 feature map $z_0$으로 변환한다. 조건 정보, 즉 timestep $t$와 클래스 레이블 $y$의 경우, MLP와 embedding layer를 사용한다. DiCo 내의 각 block $l$에서 feature map $z_{l-1}$은 $l$번째 DiCo block을 통과하여 출력 $z_l$을 생성한다.
각 stage 내에서 인코더와 디코더 사이의 skip connection은 중간 feature 간의 효율적인 정보 흐름을 가능하게 한다. 연결 후, 채널 차원을 축소하기 위해 1$\times$1 convolution이 적용된다. 여러 stage에 걸쳐 멀티스케일 처리를 가능하게 하기 위해 다운샘플링에는 pixel-unshuffle 연산을, 업샘플링에는 pixel-shuffle 연산을 사용한다. 마지막으로, 출력 feature $z_L$은 정규화되고 3$\times$3 convolution head를 통과하여 noise와 공분산을 예측한다.
2. DiCo Block
동기
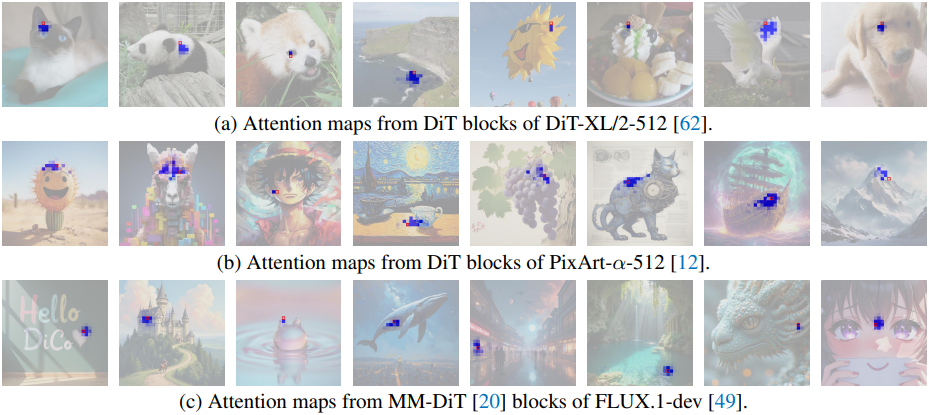
위 그림에서 볼 수 있듯이, DiT 모델의 self-attention 연산은 클래스 조건부 생성이든 text-to-image 생성이든 간에 뚜렷한 로컬 구조와 상당한 중복성을 나타낸다. 저자들은 이러한 관찰을 바탕으로 DiT의 global self-attention을 하드웨어 효율이 더 높은 연산으로 대체하고자 했다. 자연스러운 대안은 로컬 패턴을 효율적으로 모델링하는 능력으로 잘 알려진 convolution이다. 먼저 self-attention을 1$\times$1 포인트별 컨볼루션과 3$\times$3 depth-wise convolution의 조합으로 대체하는 것을 시도하였다.

그러나 직접적인 대체 방식은 생성 성능 저하를 초래한다. 위 그림은 채널 activation을 비교한 그래프이다. 위 그림에서 볼 수 있듯이, DiT와 비교했을 때 수정된 모델에서는 많은 채널이 비활성화된 상태로 남아 있어 상당한 채널 중복성을 나타낸다. 이러한 성능 저하는 동적이며 콘텐츠에 따라 달라지는 self-attention이 정적 가중치에 의존하는 convolution보다 더 큰 표현력을 제공하기 때문이다. 이러한 한계를 해결하기 위해, 유용한 채널을 동적으로 활성화하는 compact channel attention (CCA) 메커니즘을 도입했다.
Block 설계
DiCo의 핵심 설계는 Conv Module을 중심으로 이루어진다. 먼저 1$\times$1 convolution을 적용하여 픽셀 단위의 채널 간 정보를 통합하고, 이어서 3$times3 depth-wise convolution을 적용하여 채널별 공간적 컨텍스트를 포착한다. 비선형 변환에는 GELU activation function이 사용된다. 채널 중복 문제를 더욱 해결하기 위해, 더 많은 정보를 담고 있는 채널을 활성화하는 compact channel attention (CCA) 메커니즘을 도입했다. CCA는 먼저 global average pooling (GAP)을 통해 공간 차원에 걸쳐 feature를 통합한 다음, 학습 가능한 1$\times$1 convolution과 sigmoid activation function을 적용하여 채널별 attention 가중치를 생성한다. 일반적으로 Conv Module의 전체 과정은 다음과 같다.
\[\begin{equation} Y = W_{p_2} \textrm{CCA} (\textrm{GELU} (W_d W_{p_1} X)), \quad \textrm{CCA}(X) = X \odot \textrm{Sigmoid}(W_p \textrm{GAP}(X)) \end{equation}\]($W_p (\cdot)$는 1$\times$1 pointwise convolution, $W_d$는 depth-wise convolution, $\odot$은 채널별 곱셈)
이 간단하고 효율적인 설계는 feature 중복을 효과적으로 줄이고 모델의 표현 능력을 향상시킨다. Timestep과 레이블의 조건부 정보를 통합하기 위해, DiT를 따라 입력 timestep 임베딩 $t$와 레이블 임베딩 $y$를 더하고, 이를 사용하여 scale 파라미터 $\alpha$, $\gamma$와 shift 파라미터 $\beta$를 예측한다.
Text-to-image를 위한 수정 사항
본 논문에서는 텍스트 feature를 DiCo에 통합하는 두 가지 접근 방식을 조사하였다.
- 널리 사용되는 cross-attention 메커니즘을 DiCo 아키텍처에 통합하여 텍스트 feature와 비전 feature를 융합
- CLIP 텍스트 임베딩을 dynamic depthwise convolution (DWC) 커널로 변환
텍스트 임베딩의 길이를 81로 padding하고, 학습 가능한 MLP를 통과시킨 후, 출력을 9$\times$9 커널로 reshape한다. 이 커널은 depth-wise convolution을 통해 DiCo의 feature를 동적으로 변조한다. 이러한 방식으로, self-attention이나 cross-attention 연산에 의존하지 않고 완전한 convolution 기반의 text-to-image DiCo 모델을 구축할 수 있다. 두 feature 융합 모듈은 각 DiCo block 내의 Conv Module 뒤에 삽입된다.
3. Architecture Variants
저자들은 DiT-S/2, DiT-B/2, DiT-L/2, DiT-XL/2와 각각 파라미터 개수가 일치하는 DiCo-S, DiCo-B, DiCo-L, DiCo-XL의 네 가지 모델을 개발했다. DiT 모델과 비교했을 때, DiCo 모델은 계산 비용을 크게 절감하여 Gflops는 DiT의 70.1%에서 74.6% 수준에 그쳤다. 또한, 저자들은 DiCo 모델을 1B 파라미터로 scaling한 DiCo-H 모델을 구축했다.
Experiments
- 구현 디테일
1. Main Results
다음은 ImageNet 256$\times$256에서의 비교 결과이다.
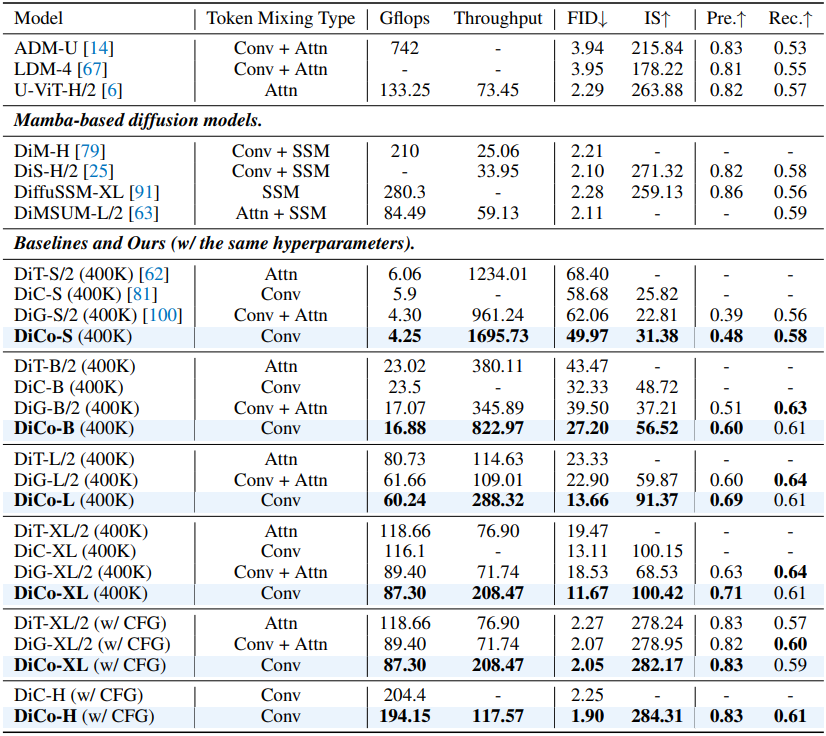
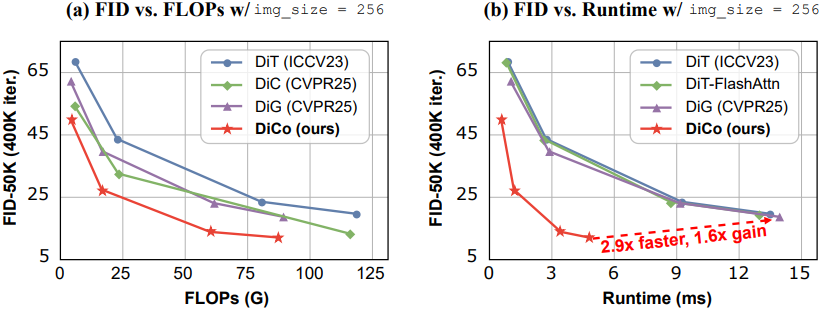
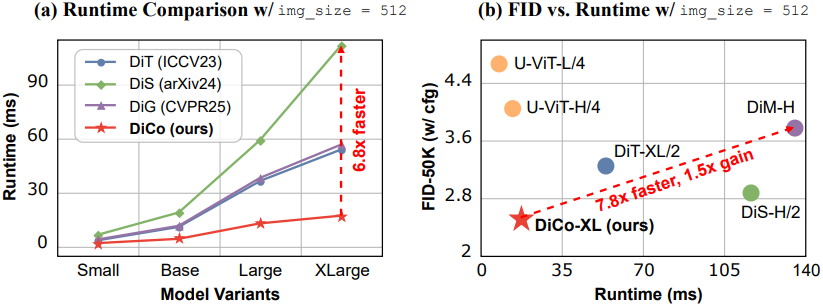
다음은 ImageNet 512$\times$512에서의 비교 결과이다.

다음은 MS-COCO에서 text-to-image 성능을 비교한 결과이다.

2. Ablation Study
다음은 아키텍처 디자인에 대한 ablation study 결과이다.
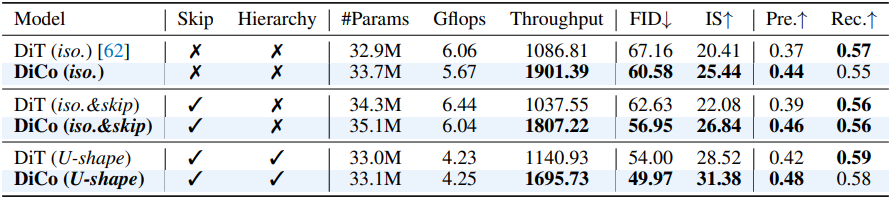
다음은 DiCo 구성 요소에 대한 ablation study 결과이다.

다음은 CCA 유무에 따른 첫 번쨰 stage의 feature를 시각화한 것이다. (왼쪽: CCA 없음, 오른쪽: CCA 있음)
