[논문리뷰] DFormer: Diffusion-guided Transformer for Universal Image Segmentation
arXiv 2023. [Paper] [Github]
Hefeng Wang, Jiale Cao, Rao Muhammad Anwer, Jin Xie, Fahad Shahbaz Khan, Yanwei Pang
Tianjin University | Mohamed bin Zayed University of Artificial Intelligence | Chongqing University | Shanghai Artificial Intelligence Laboratory
6 Jun 2023

Introduction
이미지 분할 (Image segmentation)은 이미지 내의 픽셀을 다른 유닛으로 그룹화하는 것을 목표로 한다. Semantic 카테고리 또는 인스턴스와 같이 그룹화에 대한 여러 방법이 있다. 따라서 semantic segmentation, instance segmentation, panoptic segmentation 등 다양한 이미지 분할 task가 제안되었다. Semantic segmentation은 픽셀을 다른 의미론적 범주로 그룹화하는 반면, instance segmentation은 픽셀을 다른 인스턴스로 그룹화한다. 한편, panoptic segmentation은 사물의 픽셀을 서로 다른 인스턴스로 그룹화할 뿐만 아니라 사물을 서로 다른 semantic 카테고리로 분할하는데, 이는 semantic segmentation과 instance segmentation의 공동 task로 볼 수 있다.
지난 몇 년 동안 다양한 이미지 분할 task를 위한 특수 아키텍처들이 제안되었다. 이러한 전문화된 방법은 각각의 개별 segmentation task에서 큰 성공을 거두었지만 일반적으로 다양한 이미지 분할 task로 효과적으로 일반화하는 데 어려움을 겪고 있다.
이 문제를 해결하기 위해 통합 프레임워크를 통해 다양한 이미지 분할 task를 수행하는 범용 아키텍처를 개발하려는 기존 작업은 거의 없다. Transformer 기반 물체 감지기 DETR에서 영감을 얻은 이러한 방법은 이미지 분할을 end-to-end 세트 예측 문제로 본다. 최근에는 이미지 분할을 위해 diffusion model 기반 방법도 탐색되었다. 그러나 diffusion model 기반 방법은 기존의 범용 이미지 분할 방법에 비해 여전히 뒤처져 있다. 본 논문에서는 경쟁력 있는 범용 이미지 분할 성능을 달성할 수 있는 효과적인 diffusion model 기반 transformer 접근 방식을 설계하는 문제를 조사하였다.
본 논문은 범용 이미지 분할을 위해 DFormer라는 diffusion-guided transformer 프레임워크를 제안하였다. DFormer는 이미지 분할을 noisy mask의 생성 task로 본다. 학습하는 동안 다양한 레벨의 Gaussian noise를 ground-truth 마스크에 추가하여 noisy mask를 얻는다. 그런 다음 binary threshold로 attention mask를 생성하고 noisy mask와 깊은 픽셀 레벨 feature를 집계하여 mask feature를 생성한다. 그런 다음 transformer 디코더에 공급하여 마스킹된 attention으로 각 mask feature에 대한 ground-truth 마스크를 예측한다. Inference할 때 먼저 noisy mask 집합을 생성한 다음 diffusion 기반 디코더를 사용하여 마스크와 해당 객체의 카테고리를 예측한다.
Method
1. Preliminaries
Diffusion model
Diffusion model은 일련의 state transition을 학습하여 noise에서 고품질 샘플을 생성한다. 학습 시 먼저 샘플 데이터에 Gaussian noise를 점진적으로 추가하여 forward diffusion process를 수행한 다음 noisy한 샘플 데이터에서 원본 샘플 데이터를 예측하는 모델을 학습한다. 구체적으로, diffusion process는 다음과 같이 임의의 timestep $t$에서 noisy한 샘플 데이터 $x_t$를 생성한다.
\[\begin{equation} q(x_t \vert x_0) = \mathcal{N} (x_t; \sqrt{\vphantom{1} \bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) I) \end{equation}\]여기서 timestep $t$는 균일하게 1에서 $T$까지이고, \(\bar{\alpha}_t\)는 $t$가 증가함에 따라 1에서 0까지 단조롭게 감소하는 함수이다. Timestep $t$가 $T$일 때 \(\bar{\alpha}_T\)는 0에 가깝고 noisy한 데이터 $x_T$는 $I$에 가깝다. 노이즈 $I$는 표준 정규 분포로 샘플링된다. 그 후 임의의 timestep $t$에서 네트워크 모델은 $x_t$에서 샘플 데이터 $x_0$를 예측하도록 학습되며 여기서 denoising loss는 다음과 같이 쓸 수 있다.
\[\begin{equation} L_\textrm{diff} = \frac{1}{2} \| f(x_t, t) - x_0 \|^2 \end{equation}\]여기서 $f$는 학습된 모델을 나타낸다. Inference하는 동안 샘플 데이터 $x_0$는 학습된 모델이 반복적으로 사용되는 일련의 state transition $x_T \rightarrow x_{T - \Delta} \rightarrow \cdots \rightarrow x_0$를 사용하여 $x_T$에서 점진적으로 복구된다.
Universal image segmentation
이미지 분할은 이미지 $x$에 있는 기존 개체를 개체의 마스크와 해당 카테고리를 예측하는 마스크 분류 task로 간주하며,
\[\begin{equation} \mathcal{M}, \mathcal{C} = f(x) \end{equation}\]로 쓸 수 있다. 최근 transformer 기반 이미지 분할은
\[\begin{equation} \mathcal{M}, \mathcal{C} = f_\textrm{trans}(f_\textrm{pixel} (x), \mathcal{Q}) \end{equation}\]로 표현될 수 있는 유망한 결과를 얻었다. 여기서 \(f_\textrm{pixel}\)은 픽셀 레벨 feature 추출을 위한 픽셀 레벨 모듈을 나타내고 \(f_\textrm{trans}\)는 transformer 모듈이고 $\mathcal{Q}$는 학습 가능한 query의 고정된 크기를 나타낸다. 본 논문에서는 diffusion model을 통해 denoising process로 이미지 분할을 재구성하는 것을 목표로 한다. 학습 가능한 query 집합을 사용하는 대신 noisy mask에서 이미지를
\[\begin{equation} \mathcal{M}, \mathcal{C} = f_d (f_\textrm{pixel} (x), I) \end{equation}\]로 직접 분할한다. 여기서 I는 noise 데이터를 나타내고 $f_d$는 diffusion 기반 디코더를 나타낸다.
2. Architecture
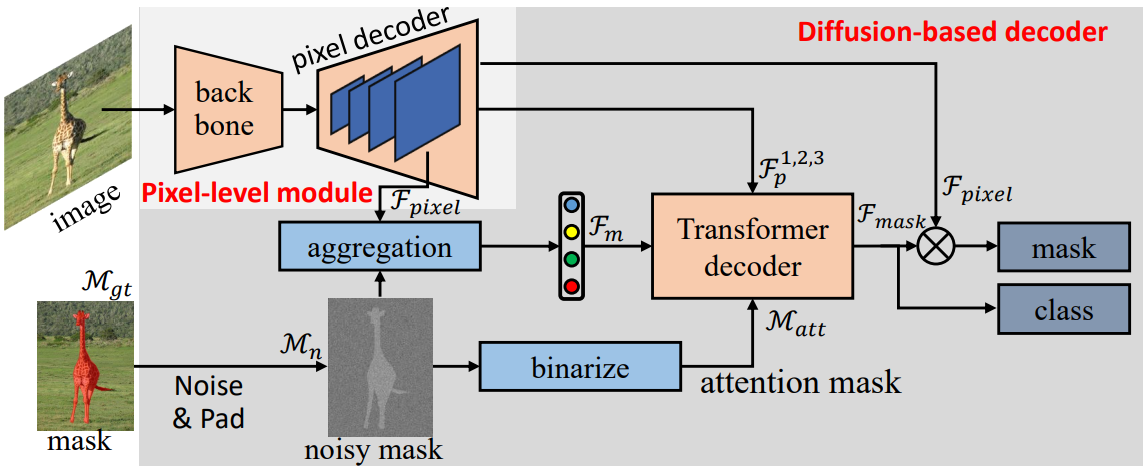
위 그림은 범용 이미지 분할을 위한 확산 모델을 통합한 DFormer라는 diffusion-guided transformer의 전체 아키텍처를 보여준다. DFormer는 픽셀 레벨의 모듈로 구성되며 표준 디코더를 제안된 diffusion 기반 디코더로 대체한다. 픽셀 레벨 모듈은 pyramid feature \(\mathcal{F}_p^i, i = 1, 2, 3\)와 픽셀 레벨 임베딩 \(\mathcal{F}_\textrm{pixel}\)을 생성하는 반면 diffusion 기반 디코더는 noisy mask \(\mathcal{M}_n\), pyramid feature \(\mathcal{F}_p^i\), 픽셀 레벨 임베딩은 \(\mathcal{F}_\textrm{pixel}\)을 입력으로 사용하고 마스크 임베딩 \(\mathcal{F}_\textrm{mask}\)를 예측한다. 마지막으로 픽셀 레벨 임베딩 \(\mathcal{F}_\textrm{pixel}\)과 마스크 임베딩 \(\mathcal{F}_\textrm{mask}\)의 내적을 통해 마스크를 생성하고 마스크 임베딩을 MLP 레이어에 공급하여 마스크 카테고리를 예측한다.
Pixel-level module
입력 이미지 $x \in \mathbb{R}^{H \times W \times 3}$이 주어지면, 픽셀 레벨 모듈은 pyramid feature
\[\begin{equation} \mathcal{F}_p^i \in \mathbb{R}^{\frac{H}{S_i} \times \frac{H}{S_i} \times C}, \quad i = 1, 2, 3, 4 \end{equation}\]를 추출한다. 여기서 $S_i$는 입력 이미지에 대한 feature map의 stride이며, $C$는 feature 채널 수이다. 픽셀 레벨 모듈은 backbone과 픽셀 디코더를 가지고 있다. 구체적으로, 먼저 ResNet이나 Swin Transformer와 같은 backbone으로 저해상도의 깊은 feature
\[\begin{equation} \mathcal{F}_\textrm{low} \in \mathbb{R}^{\frac{H}{64} \times \frac{W}{64} \times C} \end{equation}\]를 추출한다. 그런 다음, 픽셀 디코더를 사용하여 점진적으로 feature를 업샘플링하여 다양한 해상도의 pyramid feature를 생성한다. 처음 3개의 pyramid feature \(\mathcal{F}_p^i, i = 1, 2, 3\)는 이어지는 transformer 디코더 레이어에 공급되어 마스크 임베딩을 생성하며, 마지막 pyramid feature \(\mathcal{F}_p^4\)는 픽셀 레벨 임베딩 \(\mathcal{F}_\textrm{pixel}\)로 사용된다.
Diffusion-based decoder
생성된 pyramid feature \(\mathcal{F}_p^i, i = 1, 2, 3\)와 noisy mask \(\mathcal{M}_n\)을 기반으로 diffusion 기반 디코더는 마스크 임베딩 \(\mathcal{F}_\textrm{mask}\)를 예측한다. Diffusion 기반 디코더는 $L$개의 transformer 디코더가 쌓인 구조이며, 각 디코더 레이어는 masked-attention layer, self-attention layer, FFN layer를 포함한다. 각 디코더 레이어에는 attention mask \(\mathcal{M}_\textrm{att}\), pyramid feature들 중 하나 \(\mathcal{F}_p^i\), mask feature \(\mathcal{F}_m\)이 입력된다. 첫 번째 디코더 레이어의 경우, \(\mathcal{M}_\textrm{att}\)는 noisy mask를
\[\begin{equation} \mathcal{M}_\textrm{att} = \mathcal{M}_n > 0 \end{equation}\]으로 thresholding하여 생성되며, \(\mathcal{F}_m\)은 다음과 같이 생성된다.
\[\begin{equation} \mathcal{F}_m = f_\textrm{avg} (\mathcal{F}_\textrm{pixel} \times f_\textrm{norm} (\mathcal{M}_n)) \end{equation}\]여기서 \(f_\textrm{avg}\)는 글로벌 평균 풀링 연산을 나타내고 \(f_\textrm{norm}\)은 정규화 연산을 나타낸다. 첫 번째 디코더 레이어를 제외하고 현재 디코더 레이어의 출력 마스크 임베딩 \(\mathcal{F}_\textrm{mask}\)는 다음 디코더 레이어의 입력 mask feature \(\mathcal{F}_m\)으로 사용되고 현재 디코더 레이어의 예측 마스크는 다음 디코더 레이어의 입력 attention 마스크 \(\mathcal{M}_\textrm{att}\)로 사용된다. Pyramid feature \(\mathcal{F}_\textrm{p}^i, i = 1, 2, 3\)은 효율적인 학습을 위해 연속적인 디코더 레이어의 입력 이미지 feature로 번갈아 사용된다. MLP 레이어를 사용하여 출력 마스크 임베딩 \(\mathcal{F}_\textrm{mask}\)로 마스크 분류 점수를 예측하고 픽셀 레벨 임베딩과 내적하여 예측 마스크를 생성한다.
3. Training
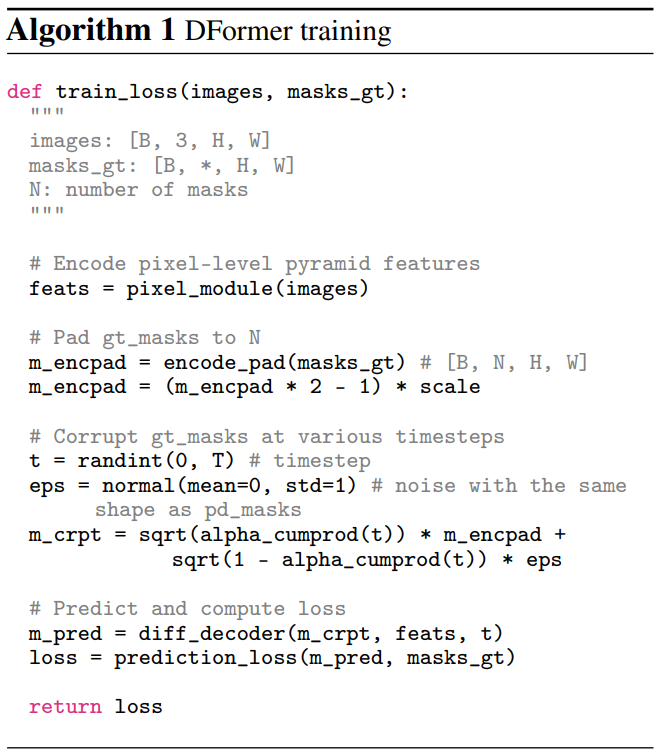
Algorithm 1은 DFormer의 학습 디테일을 제공한다.
Mask padding and encoding
서로 다른 이미지의 개체 수가 다르기 때문에 먼저 마스크 패딩을 수행한다. 고정된 수의 패딩된 마스크 \(\mathcal{M}_\textrm{pad}\)에 ground-truth 마스크 \(\mathcal{M}_\textrm{gt}\)를 패딩한다. 구체적으로, 랜덤 이진 마스크 \(\mathcal{M}_\textrm{rand}\)를 생성하고
\[\begin{equation} \mathcal{M}_\textrm{pad} = \textrm{cat} (\mathcal{M}_\textrm{gt}, \mathcal{M}_\textrm{rand}) \in \mathbb{R}^{N \times H \times W} \end{equation}\]와 같이 원래 ground-truth 마스크와 concat한다.
그런 다음, noise를 추가하기 전에 패딩 마스크를 인코딩하는 두 가지 다른 전략인 바이너리 인코딩 전략과 랜덤 셔플 기반 인코딩 전략을 살펴본다. 바이너리 전략은 패딩 마스크를 바이너리 입력 (0 또는 1)으로 직접 인코딩하는 반면, 랜덤 셔플링 기반 전략은 패딩 마스크를 0에서 1 사이로 인코딩한다. 여기서 객체 마스크 픽셀은 0.5에서 1로 랜덤하게 샘플링하고 객체가 아닌 픽셀은 0에서 0.5까지 랜덤하게 샘플링한다.
Mask corruption
마스크 손상은 인코딩된 마스크 Menc에 가우시안 잡음을 추가하여 임의의 timestep $t$에서 noisy mask \(\mathcal{M}_n\)을 생성하는 것을 목표로 한다. 먼저 인코딩된 마스크의 배율을 $[0, 1]$에서 $[-b, b]$로 다시 조정한다. 여기서 $b$는 scale factor이다. 그런 인코딩된 마스크에 Gaussian noise를 추가한다. 추가된 noise의 스케일 $1 - \bar{\alpha}_t$는 timestep $t$에 따라 달라지며, 여기서 큰 $t$는 noise의 큰 스케일에 해당한다. Noise를 추가한 후 noisy mask를 $[-b, b]$ 범위로 고정한다.
Loss formulation
$N$개의 패딩된 noisy mask를 사용하여 $N$개의 마스크와 해당 분류 점수를 예측할 수 있다. 그런 다음 마스크와 분류 매칭 비용을 모두 고려한 Hungarian 기반 알고리즘을 통해 예측과 ground-truth 간의 이분 매칭 (bipartite matching)을 수행한다. 그런 다음 전체 학습 loss를 다음과 같이 계산할 수 있다.
\[\begin{equation} L = \lambda_1 L_\textrm{cls} + \lambda_2 L_\textrm{ce} + \lambda_3 L_\textrm{dice} \end{equation}\]여기서 $L_\textrm{cls}$는 분류를 위한 cross entropy loss이고, $L_\textrm{ce}$와 $L_\textrm{mask}$는 마스크 예측을 위한 binary cross-entropy loss와 dice loss이다. $\lambda_1$, $\lambda_2$, $\lambda_3$은 loss 가중치를 나타내며 2.0, 5.0, 5.0이다.
4. Inference
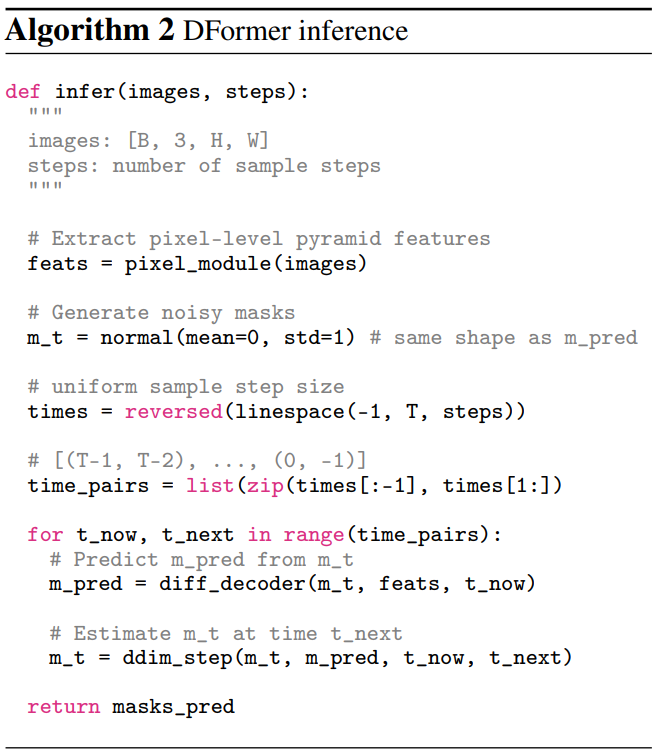
Algorithm 2는 DFormer의 inference 디테일을 제공한다. 먼저 가우시안 분포로 noisy mask \(\mathcal{M}_n\)을 생성한 다음 여러 샘플링 단계로 인스턴스 마스크를 예측한다. 각 샘플링 단계에서 먼저 이전 timestep의 noisy mask에 따라 인스턴스 마스크를 예측한 다음 예측된 인스턴스 마스크에 noise를 추가하여 현재 timestep의 noisy mask를 생성한다.
Experiments
- 데이터셋: MS COCO, ADE20k
- 구현 디테일
- Backbone: ImageNet에서 사전 학습된 ResNet이나 Swin-T를 적용
- \(\mathcal{F}_p^{1,2,3,4}\): stride = 32, 16, 8, 4, feature 채널 = 256
- Diffusion 기반 디코더: $L = 9$ cascaded decoder layer
- Instance and panoptic segmentation
- NVIDIA RTX3090 GPU 4개
- Optimizer: AdamW
- Batch size: 12
- Epochs: 50
- 초기 learning rate: $1 \times 10^{-4}$
- Weight decay: 0.05
- Semantic segmentation
- NVIDIA RTX3090 GPU 4개
- Optimizer: AdamW
- Batch size: 16
- Iteration: 16만
- 초기 learning rate: $1 \times 10^{-4}$
- Weight decay: $1 \times 10^{-4}$
1. State-of-the-art comparison
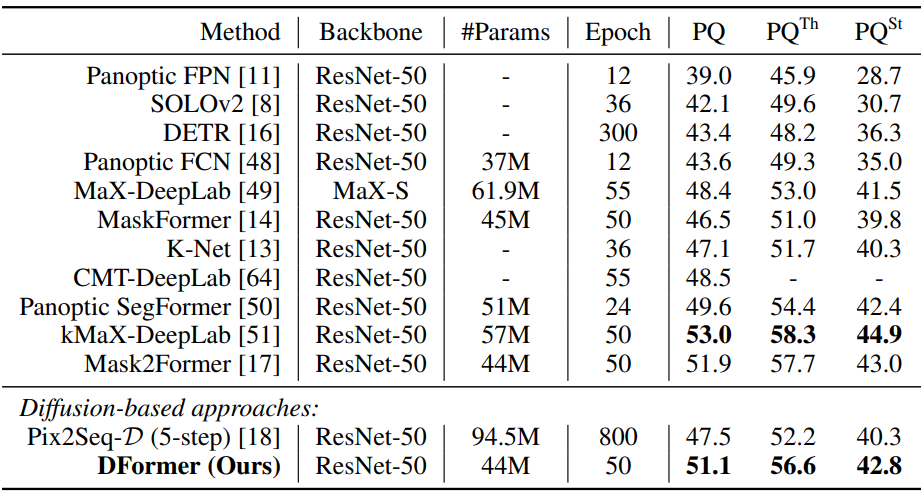
Panoptic segmentation
다음은 MS-COCO val2017 set에서의 panoptic segmentation 비교 결과이다.
Instance segmentation
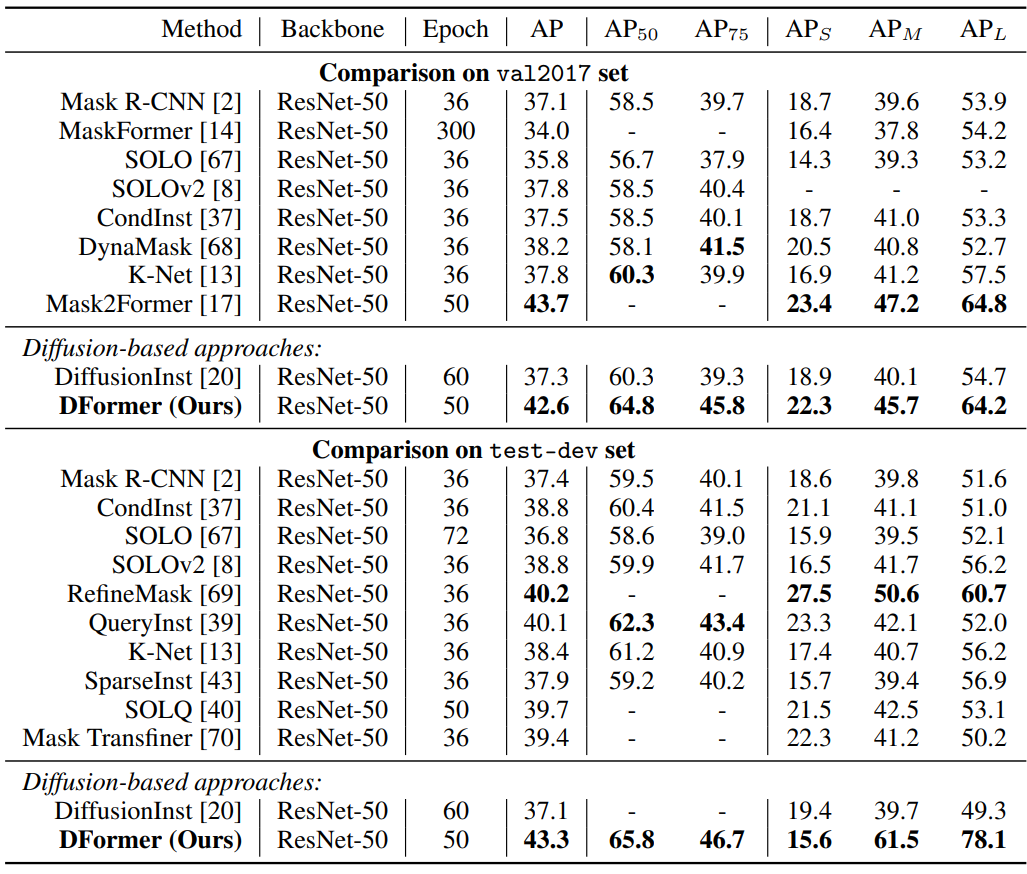
다음은 MS-COCO val2017 set과 test-dev set에서의 instance segmentation 비교 결과이다.
Semantic segmentation
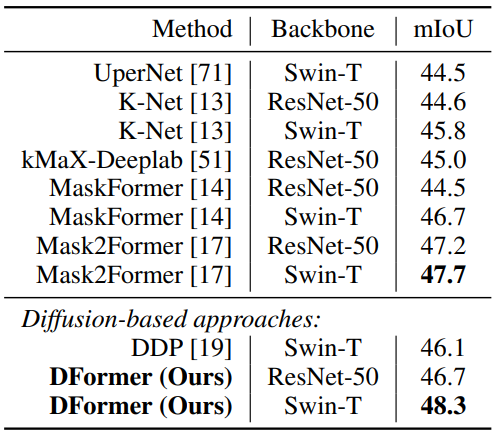
다음은 ADE20k val set에서의 semantic segmentation 비교 결과이다.
2. Ablation study
다음은 MS-COCO val2017 set에서 instance segmentation에 대하여 ablation study를 수행한 결과이다.

3. Qualitative results
다음은 3가지 이미지 분할 task에 대한 시각적 예시이다.

4. Limitations
DFormer는 instance segmentation에서 작은 객체에 대한 SOTA 방법보다 약간 성능이 떨어진다.