[논문리뷰] DF-GAN: A Simple and Effective Baseline for Text-to-Image Synthesis
CVPR 2022 (Oral). [Paper] [Github]
Ming Tao, Hao Tang, Fei Wu, Xiao-Yuan Jing, Bing-Kun Bao, Changsheng Xu
13 Aug 2020
Introduction
GAN의 text-to-image 합성 분야의 2가지 주요 challenge는
- 생성 이미지의 authenticity
- 주어진 text와 생성된 이미지 간의 semantic consistency
이다. GAN의 불안정성으로 인해 대부분의 기존 모델은 고해상도의 이미지 생성을 위해 backbone으로 stack 구조를 사용하였고 (ex. StackGAN), text와 image 간의 연관성을 위해 text와 image feature간의 cross-model attention을 사용하였다.
그럼에도 기존 sota 모델들에는 여전히 3가지 문제가 있으며, 논문에서 저자는 각각의 해결방법을 제시하였다.
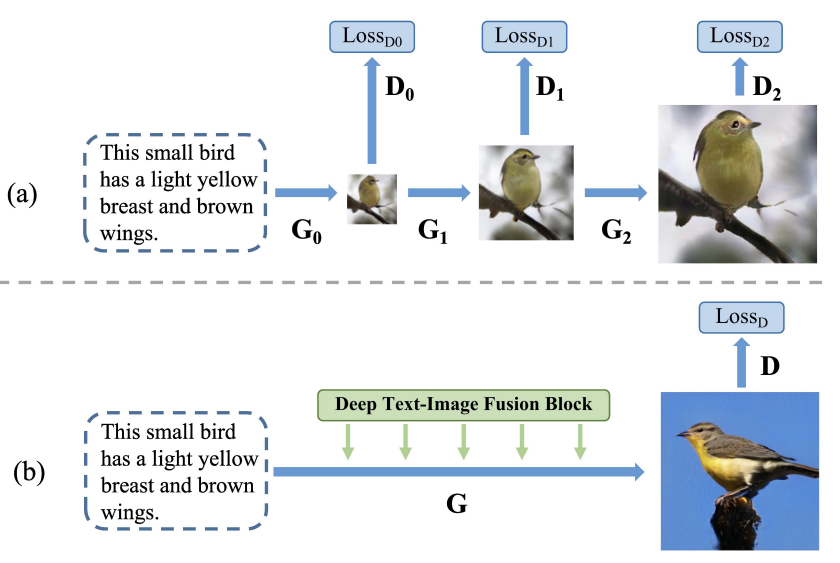
-
Stack 구조는 generator 사이의 entanglement를 만들기 때문에 최종 이미지는 흐릿한 모양과 디테일의 단순한 합으로 표현된다. (각 generator가 서로 다른 image scale에서 특징을 만든다.)
→ one-stage backbone으로 해결 (generator 1개) -
학습 과정에서 다른 network를 고정하는데, 고정된 network를 generator가 너무 쉽게 속일 수 있게 되고 이는 semantic consistency를 약하게 만든다.
→ Matching-Aware Gradient Penalty (MA-GP)와 One-Way Output을 사용하는 Target-Aware Discriminator 사용하여 semantic consistency를 증가시킨다. -
Cross-modal attention은 computational cost가 높아 모든 stage에서 사용하지 못하고, 이로 인해 text 정보를 모두 활용하지 못하게 된다.
→ Deep text-image Fusion Block (DFBlock)으로 text 정보를 image feature에 더 효과적이고 깊게 결합하여 해결한다.
DF-GAN 구조
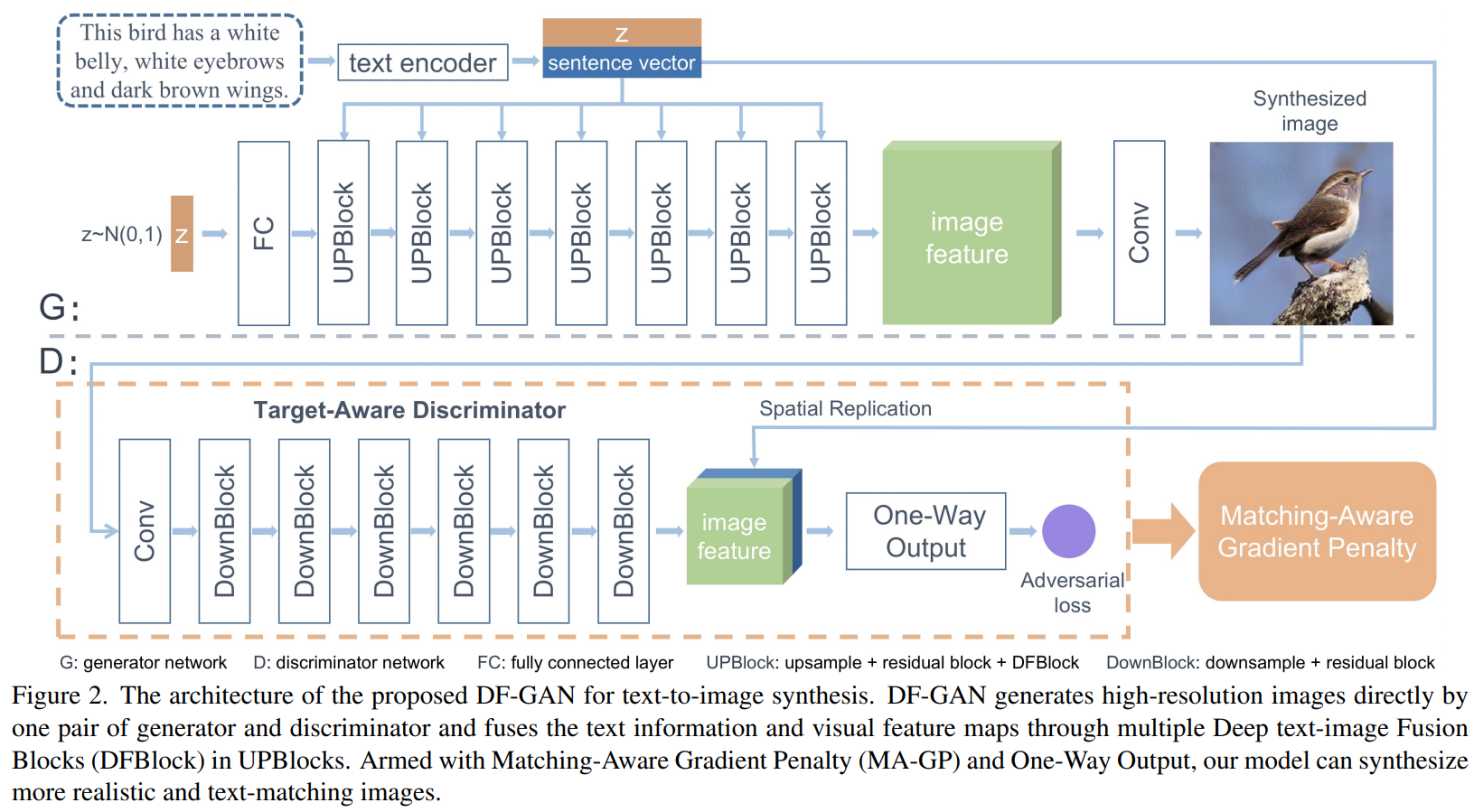
각 해결 방법을 자세히 살펴보면 다음과 같다.
1. One-Stage Text-to-Image Backbone
- noise로 부터 고해상도 이미지 생성을 해야 하기 때문에 layer가 많이 필요
→ 모델이 deep하기 때문에 안정적인 학습을 위해 residual network로 구성 - 안정적인 학습을 위해 hinge loss 사용
- 아래 식은 hinge loss를 적용한 loss function
($z$는 noise vector, $e$는 sentence vector, $\mathbb{P_g}$, $\mathbb{P_r}$, $\mathbb{P_{mis}}$는 생성된 데이터, 실제 데이터, mismatch 데이터의 분포)
2. Matching-Aware Gradient Penalty (MA-GP)
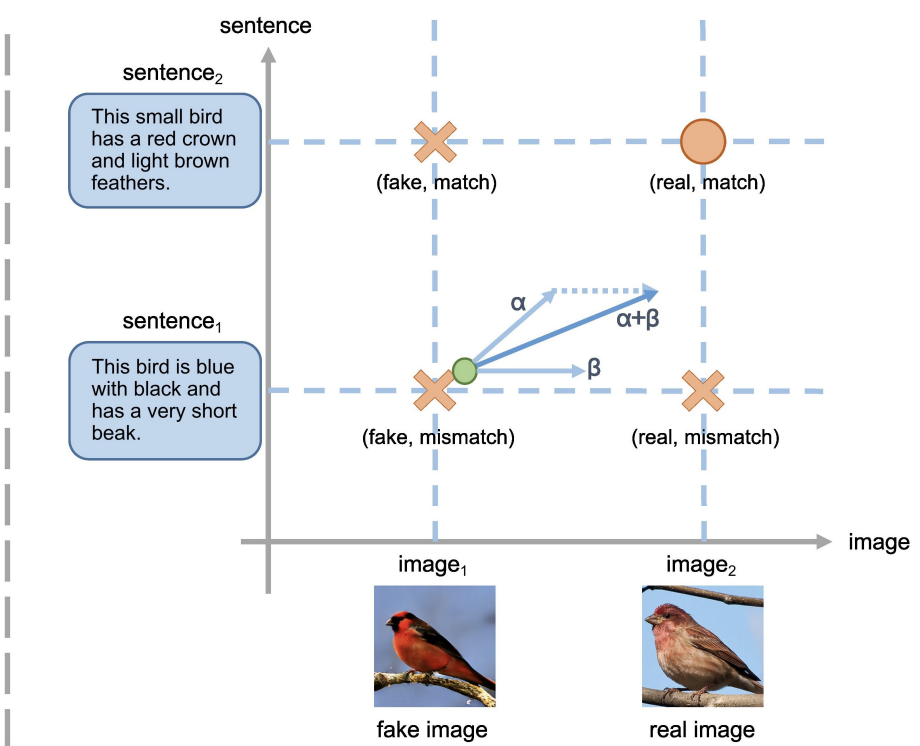
- real data에 대하여 gradient penalty를 사용하면 real data 주변에서 loss function이 smooth해지고 이는 합성 data가 real data에 수렴하도록 만든다. 즉, target data에 대한 gradient penalty는 generator의 수렴을 돕는다.
- text-to-image generation에서는 4가지 경우 존재:
(fake image, real image) x (match text, mismatch text) - semantic consistency를 위해서는 (real image, match text)에 대한 gradient penalty를 사용해야 한다.
- 아래 식은 MA-GP를 적용한 loss function
($k$와 $p$는 gradient penalty의 효과를 조절하기 위한 hyper-parameter)
3. One-Way Output
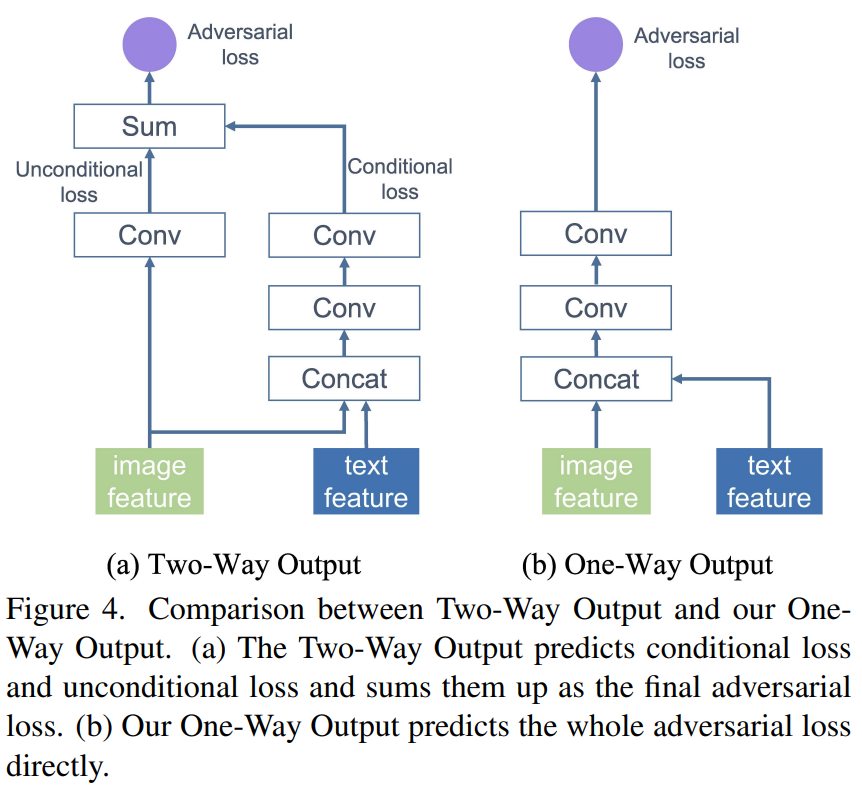
- 기존 model은 discriminator의 image feature가 real/fake 구분 (unconditional loss)과 text-image semantic consistency 평가(conditional loss)의 2가지로 사용되었다.
- 이러한 Two-Way Output은 MA-GP의 효과를 떨어뜨리고 generator의 수렴을 늦춘다.
- 이는 conditional loss는 (real image, match text) 방향으로 수렴하고 unconditional loss는 real image 방향으로만 수렴하기 때문이다.
- 그렇기 때문에 One-Way Output을 사용해서 (real image, match text) 방향으로만 수렴하도록 해야한다.
4. Deep Text-Image Fusion Block (DFBlock)
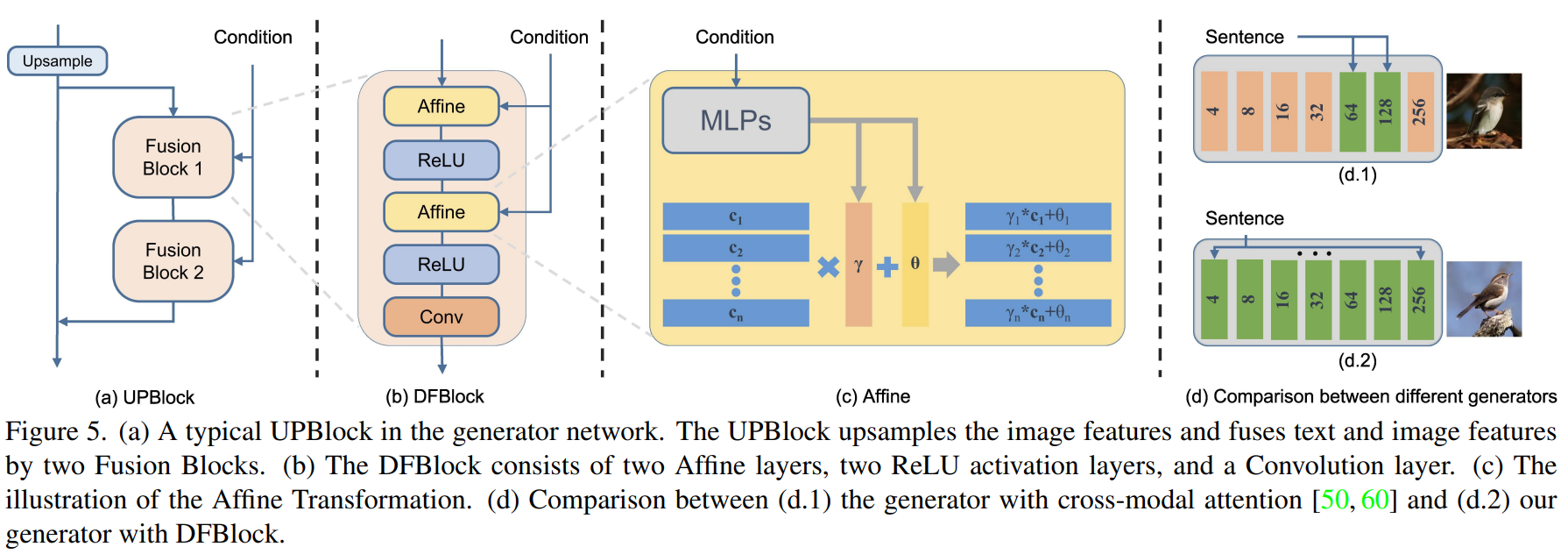
- Affine layer는 generator의 conditional representation space를 확장시키는 역할을 한다.
- Affine transformation: 2개의 MLP로 scaling parameter와 shifting parameter를 계산
→ linear transformation이므로 ReLU로 nonlinearity 추가 - 장점
(1) Generator가 text 정보를 더 많이 사용하게 됨
(2) Representation space가 확장됨에 따라 다양한 text에 높은 semantic consistency를 가진 이미지를 생성하게 된다.
(3) 기존 model의 cross-modal attention은 이미지 크기가 커지면 computational cost가 급격하게 증가하지만 affine transformation은 그렇지 않다.
Experiments
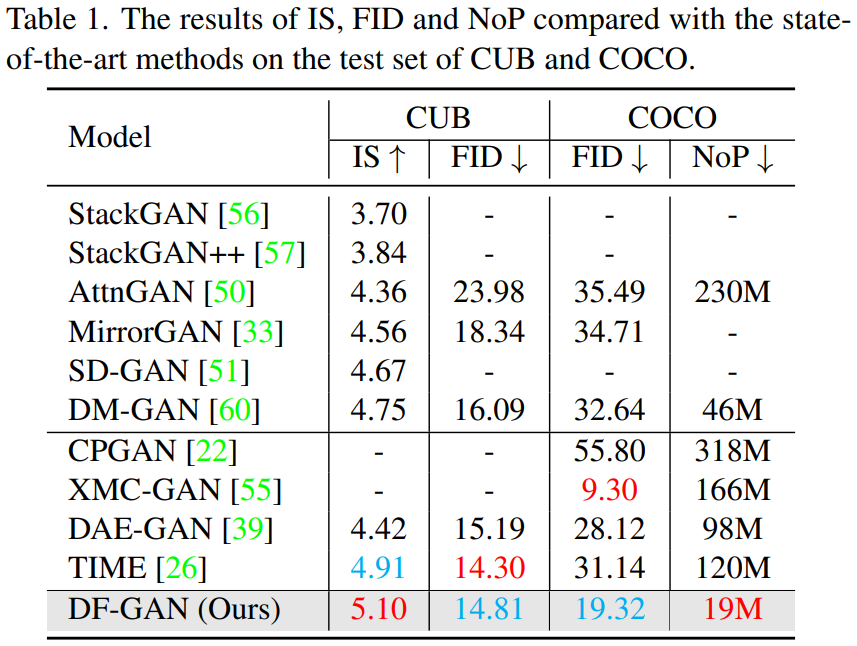
- Dataset: CUB bird (11,788 이미지, 200종), COCO (80k training / 40k testing)
- Adam ($\beta _1 = 0, \beta _2 = 0.9$), $lr_g$ = 1e-4, $lr_d$ = 4e-4, TTUR
- Evaluation: 256x256 이미지 30,000장 (text는 랜덤)에 대한 IS, FID
- COCO dataset은 IS가 평가지표로 부적절하여 제외
- NoP (number of parameters)도 평가
Examples

Results
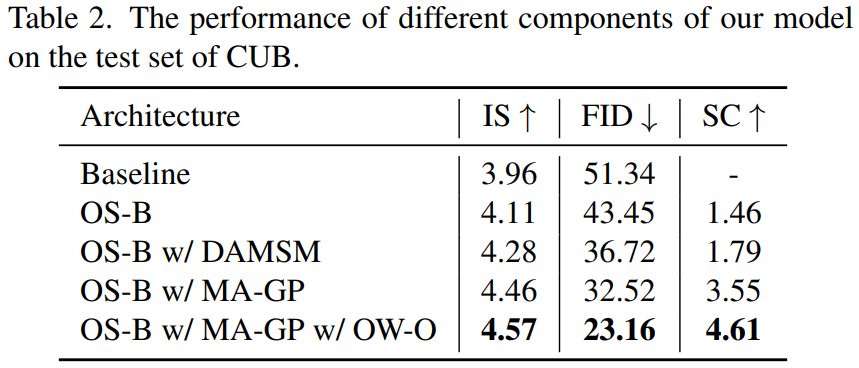
Ablation study
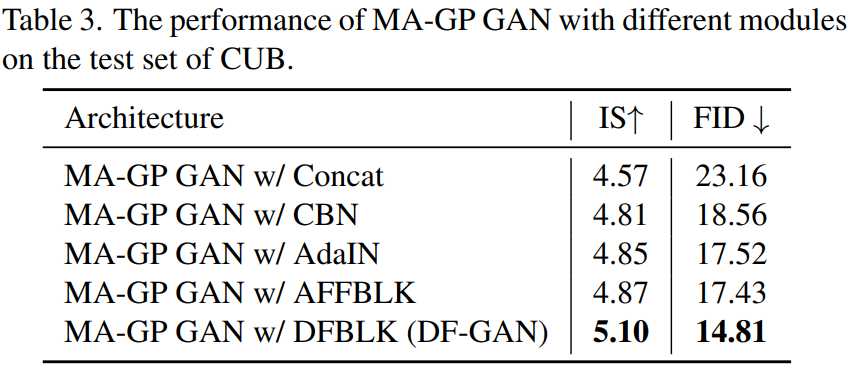
Limitation
- 문장 수준의 text 정보만 다룸. (fine-grained visual feature 합성 능력은 미지수)
- pre-trained large language model을 사용한 것이 성능 향상에 영향을 주었을 수 있음
개인적인 생각
- 최근에 나오고 있는 diffusion 기반의 모델들보다는 성능이 많이 떨어진다. 하지만 이 논문이 나온 당시에는 state-of-the-art를 찍을 정도로 좋은 성능을 보였으며, 특히 모델의 파라미터 개수(NoP)가 19M 밖에 되지 않기 때문에 굉장히 빠르다.
- 아쉬운 점은 text encoder에 대한 설명이 너무 부족하다는 것이다. Text encoder가 얼마나 텍스트 정보를 잘 표현하는 지가 text-image semantic consistency에서 중요한 부분이기 때문에 이에 대한 설명이 없다는 것이 아쉽다.
- 실제 implementation code를 보면 text encoder로 Transformer 기반의 모델이 아닌 RNN을 사용한 것으로 보아 모델의 크기를 줄이려는 의도가 아닐까 싶다. 아니면 저자들이 애초에 pre-trained RNN의 성능이 충분하다고 생각했을 수도 있다. 추후 pre-trained transformer을 text encoder로 사용하였을 때 성능의 향상을 보이는 지 확인해 보아야 겠다.
- 한가지 더 아쉬운 점은 256x256보다 큰 이미지 생성에 대하서는 다루지 않았다는 점이다. 기존 모델들의 경우 256x256보다 큰 이미지를 생성할 때 좋지 못한 결과를 보인다. DF-GAN이 기존 모델들이 가진 한계점을 해결하기 위하여 다양한 방법을 사용하였는데, 이러한 방법들이 256x256보다 큰 이미지를 생성하는 데에도 좋은 영향을 주는지 실험이 있었으면 좋았을 것이라 생각이 든다.