[논문리뷰] DEXTER: Diffusion-Guided EXplanations with TExtual Reasoning for Vision Models
NeurIPS 2025 (Spotlight). [Paper] [Github]
Simone Carnemolla, Matteo Pennisi, Sarinda Samarasinghe, Giovanni Bellitto, Simone Palazzo, Daniela Giordano, Mubarak Shah, Concetto Spampinato
University of Catania | University of Central Florida
16 Oct 2025
Introduction
본 논문에서는 visual classifier의 전반적인 추론 패턴과 편향을 밝혀내고, 사람이 이해할 수 있는 텍스트 설명을 생성하는 프레임워크인 DEXTER를 제안하였다. DEXTER는 diffusion model의 생성 능력과 LLM의 추론 능력을 활용하여 데이터 없이도 작동한다. DEXTER의 핵심은 diffusion 기반 이미지 생성 프로세스를 가이드하기 위해, discrete hard prompt에 매핑되는 soft prompt를 최적화하는 것이다. 이를 통해 생성된 이미지는 타겟 classifier의 출력과 일치하여 모델이 우선시하는 feature와 개념을 포착한다. 생성된 이미지는 LLM에 의해 분석되어, classifier의 의사 결정 과정에 대한 텍스트 설명을 제공한다. 이미지 생성과 텍스트 추론을 결합함으로써, DEXTER는 시각적 설명의 해석 가능성 문제를 해결할 뿐만 아니라, 학습 데이터나 GT 레이블에 접근하지 않고도 허위 상관관계와 편향을 식별하는 등 모델 동작에 대한 전반적인 이해를 제공한다.
Method
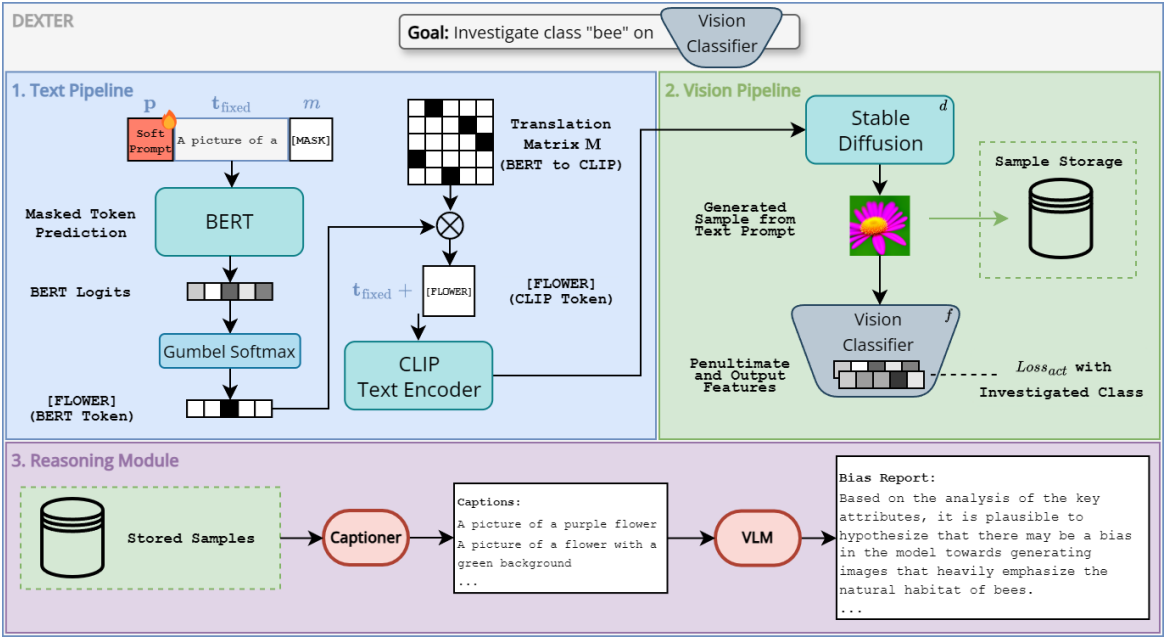
DEXTER 프레임워크는 세 가지 핵심 구성 요소를 통합한다.
- 프롬프트 최적화를 위한 텍스트 파이프라인
- 이미지 생성 프로세스를 위한 비전 파이프라인
- VLM을 사용하는 추론 모듈
DEXTER는 먼저 BERT 모델이 미리 정의된 문장에서 마스킹된 토큰을 채우도록 하는 soft prompt를 최적화한다. 이렇게 생성된 프롬프트는 Stable Diffusion을 가이드하여 주어진 visual classifier에서 특정 목표 뉴런들(ex. classifier head)의 activation을 최대화하는 이미지를 생성한다. 생성된 이미지는 VLM에 의해 분석되며, VLM은 여러 이미지를 기반으로 추론하여 모델의 의사 결정 과정을 일관되고 사람이 읽기 쉬운 텍스트로 설명한다.
1. Text pipeline
텍스트 파이프라인의 목표는 diffusion model을 적절하게 컨디셔닝하도록 텍스트 프롬프트를 최적화하는 것이다. 프롬프트 생성을 masked language modeling task로 간주하고, 이를 위해 사전 학습되고 고정된 BERT 모델을 사용한다. 생성될 텍스트 프롬프트의 구조는 완전히 커스텀 가능하며, 고정된 텍스트 부분과 마스크 토큰 집합을 조합하여 제어할 수 있다.
텍스트 프롬프트가 시퀀스 \(\textbf{t} = [\textbf{t}_\textrm{fixed}, m_1, m_2, \ldots, m_N]\)의 구조를 가진다고 가정하자. 여기서 \(\textbf{t}_\textrm{fixed}\)는 고정된 텍스트 부분이고 모든 $m_i$는 BERT [MASK] 토큰으로 설정된다. \(\textbf{t}_\textrm{emb}\)를 위치 인코딩을 포함한 $\textbf{t}$의 임베딩이라 하자. BERT의 동작은 사전 학습을 기반으로 $m_i$를 가장 가능성이 높은 토큰으로 대체하는 경향이 있으므로, 이를 변경하기 위해 입력 시퀀스 앞에 학습 가능한 소프트 프롬프트 $\textbf{p} \in \mathbb{R}^{P \times d}$를 추가한다. $\textbf{p}$는 $P$개의 벡터 시퀀스로 구성되며, $d$는 BERT 임베딩 공간의 차원이다. 따라서 BERT에 대한 전체 입력 시퀀스는 $[\textbf{p}, \textbf{t}_\textrm{emb}]$이다.
마스킹된 토큰에 해당하는 logit \([\textbf{l}_1, \ldots, \textbf{l}_N]\)을 읽어낸다. 여기서 각 \(\textbf{l}_i \in \mathbb{R}^V\)이고 $V$는 BERT의 vocabulary 크기이다. 각 logit 벡터 \(\textbf{l}_i\)는 Gumbel-softmax (temperature $\tau = 1$)를 통해 미분 가능한 one-hot 벡터 \(\textbf{o}_i \in \{0, 1\}^V\)로 매핑되고, 여기서 해당 예측 토큰 \(\hat{t}_i \in \{1, \ldots, V\}\)가 추출된다. 결과 텍스트 프롬프트는 \([\textbf{t}_\textrm{fixed}, \hat{t}_1, \ldots, \hat{t}_N]\)로 복원할 수 있다.
이 시점에서 실질적인 문제가 발생하는데, diffusion model의 표준 구현에서 CLIP의 텍스트 인코더를 사용하여 텍스트 프롬프트를 컨디셔닝 벡터에 임베딩한다는 점이다. 불행히도 BERT와 CLIP의 vocabulary는 부분적으로만 겹친다. 이 문제를 해결하기 위해, 각 one-hot 벡터 \(\textbf{o}_i\)를 CLIP vocabulary의 해당 표현으로 매핑하는 변환 행렬 \(\textbf{M} \in \{0, 1\}^{V \times W}\)를 사용한다. $\textbf{M}$의 각 행에는 CLIP vocabulary에서 해당 토큰의 인덱스를 나타내는 1이 하나씩 포함된다.
BERT에서 제공하는 원래 one-hot 벡터 \(\textbf{o}_i\)가 주어지면, \(\textbf{o}_i^{(C)} = \textbf{o}_i \textbf{M}\)을 통해 CLIP vocabulary의 토큰 \(\hat{t}_i^{(C)}\)를 인덱싱하여 해당 CLIP 표현으로 변환할 수 있다. 할당되지 않은 BERT 토큰의 경우, $M$의 해당 행은 모두 0이다. 이러한 설계 덕분에, 모델은 CLIP에서 유효한 매핑이 없는 BERT 토큰을 예측하지 않도록 학습한다. 이러한 토큰은 $\textbf{M}$과 곱했을 때 인덱싱 벡터 \(\textbf{o}_i^{(C)}\)가 0이 되어 의미 없는 표현을 제공하기 때문이다.
따라서 diffusion model을 컨디셔닝하는 데 사용되는 텍스트 프롬프트는 \([\textbf{t}_\textrm{fixed}, \hat{t}_1^{(C)}, \ldots, \hat{t}_N^{(C)}]\)이다. Gumbel-Softmax와 vocabulary의 선형 매핑 덕분에 전체 프로세스는 완전히 미분 가능하므로 backpropagation을 통해 유일하게 학습 가능한 파라미터인 soft prompt $\textbf{p}$를 최적화할 수 있다.
2. Vision pipeline
비전 파이프라인의 목표는 visual classifier의 뉴런 집합 activation을 최대화하는 사실적이고 해석 가능한 이미지를 합성하는 것이다. 예측된 텍스트 프롬프트 \([\textbf{t}_\textrm{fixed}, \hat{t}_1^{(C)}, \ldots, \hat{t}_N^{(C)}]\)가 주어지면, 이를 CLIP의 텍스트 인코더에 입력하여 임베딩 벡터 $\textbf{e}$를 얻는다. 이 벡터는 사전 학습되고 고정된 Stable Diffusion 모델 $d$를 컨디셔닝하는 데 사용된다. 고정된 타겟 visual classifier \(f : \mathcal{I} \rightarrow \mathbb{R}^K\)가 $C$개의 클래스 집합에 대해 사전 학습되었으며, 출력으로 $K$개의 선택된 뉴런의 부분집합의 response를 제공한다고 하자. 이 뉴런들의 activation을 최대화하는 것이 목표이다. 선택된 activation 벡터는 $\textbf{n} = f (d (\textbf{e}))$로 얻을 수 있다.
전체 비전 파이프라인은 미분 가능하므로 $\textbf{n}$에 대한 최적화 objective를 정의할 수 있으며, 이는 텍스트 파이프라인에서 학습 가능한 soft prompt $\textbf{p}$에 직접적인 영향을 미친다.
Visual classifier의 동작을 설명하는 생성 프로세스를 가이드하기 위해, 선택된 뉴런 $\textbf{n}$의 response를 최대화하는 텍스트 프롬프트와 합성 이미지를 학습하도록 가이드하는 뉴런 activation 최대화 loss function \(\mathcal{L}_\textrm{act}\)를 도입한다.
\[\begin{equation} \mathcal{L}_\textrm{act} = \sum_{i=1}^K l_\textrm{act} (n_i) \end{equation}\]($n_i$는 $\textbf{n}$의 $i$번째 element)
\(l_\textrm{act}\)는 $n_i$가 feature 뉴런인지 클래스 뉴런인지에 따라 다음과 같이 정의된다.
\[\begin{equation} l_\textrm{act} (n_i) = \begin{cases} -n_i, & \textrm{if} \; n_i \; \textrm{is a feature neuron} \\ -\log n_i, & \textrm{if} \; n_i \; \textrm{is a class neuron} \end{cases} \end{equation}\]3. Masked pseudo-labels prediction
Activation 최대화 loss만 사용했을 때 텍스트 파이프라인에서 학습 가능한 soft prompt $\textbf{p}$로 전달되는 gradient가 너무 작아 수렴 속도가 느려지거나 심지어 수렴이 불가능하다. 이 문제를 해결하기 위해 텍스트 파이프라인에 보조 마스크 예측 task를 도입하여 더 짧은 $\textbf{p}$까지의 backpropagation 경로를 제공한다. 이 보조 task의 설계는 마스킹된 토큰을 목표 뉴런의 부분집합과 연결함으로써 뉴런 activation과 텍스트 프롬프트의 특정 부분 간의 매핑을 유도하는 또 다른 설명 가능성 feature를 추가할 수 있도록 해준다.
이를 위해 각 마스크 토큰 위치 $m_1, \ldots, m_N$에 대해 하나의 pseudo-label $y_1, \ldots, y_N$을 초기화한다. 각 pseudo-label \(y_i \in \{1, \ldots, V\}\)는 $+\infty$로 초기화된 reference loss $L_i$와 레퍼런스 뉴런 집합 \(\mathcal{N}_i \subseteq \{1, \ldots, K\}\)와 연결된다. 각 최적화 단계에서 각 마스크 토큰 $m_i$에 대해 BERT는 logit \(\textbf{l}_i\)를 예측하고, 이를 통해 softmax 벡터 \(\textbf{s}_i\)와 해당 예측 토큰 \(\hat{t}_i\)를 계산한다. 연결된 레퍼런스 뉴런 집합에 대한 activation loss \(\mathcal{L}_{\textrm{agg}, i}\)를 다음과 같이 정의한다.
\[\begin{equation} \mathcal{L}_{\textrm{agg}, i} = \sum_{j \in \mathcal{N}_i} l_\textrm{act} (n_j) \end{equation}\]그런 다음, \(\mathcal{L}_{\textrm{agg}, i}\)가 해당 reference loss $L_i$보다 작으면 pseudo-label $y_i$와 reference loss $L_i$를 각각 \(\hat{t}_i\)와 \(\mathcal{L}_{\textrm{agg}, i}\)로 업데이트한다. Pseudo-label $y_i$가 $m_i$에 대해 설정되었다면, softmax 벡터 \(\textbf{s}_i\)의 $j$번째 element인 $s_{i,j}$에 대해 cross-entropy loss 항 \(\mathcal{L}_{\textrm{mask}, i} = -\log s_{i, y_i}\)를 추가한다. 이 접근 방식을 통해 학습이 진행됨에 따라 pseudo-label이 목표 뉴런의 activation 패턴과 더 잘 일치하도록 지속적으로 개선되는 동시에 모델의 파라미터가 의미 있고 해석 가능한 구성에 해당하는 파라미터 공간 영역 내에 유지되도록 제한한다. 모든 $y_i$가 설정된 첫 번째 iteration 후 전체 손실 함수 $\mathcal{L}$은 다음과 같다.
\[\begin{equation} \mathcal{L} = \sum_{k=1}^K l_\textrm{act} (n_k) - \sum_{i=1}^N \log s_{i, y_i} \end{equation}\]발생할 수 있는 문제점 중 하나는 activation loss를 무작위로 감소시킬 수 있는 outlier 토큰의 예측으로 인해 pseudo-label이 잘못된 값으로 업데이트될 수 있다는 것이다. 이를 방지하기 위해 마스킹된 토큰 위치 $m_i$마다 최적화 과정에서 예측된 각 단어에 대한 activation loss 기록을 유지하고, 이 기록의 평균을 reference loss $L_i$와 비교한다. $L_i$를 가장 최근의 activation loss \(\mathcal{L}_{\textrm{agg}, i}^{(T)}\)와 비교하는 대신, 다음 조건을 확인하고 이 경우에만 $L_i$를 업데이트한다.
\[\begin{equation} \frac{1}{T} \sum_{j=1}^T \mathcal{L}_{\textrm{agg}, i}^{(j)} < L_i \end{equation}\]이 접근 방식은 과거 activation loss가 낮은 단어의 예측을 우선시하여, 무작위 loss 변동을 유발하는 outlier 단어가 타겟으로 선택되는 것을 방지한다.
Performance analysis
1. Visual Explanations
다음은 SalientImageNet에 대한 user study 결과이다.
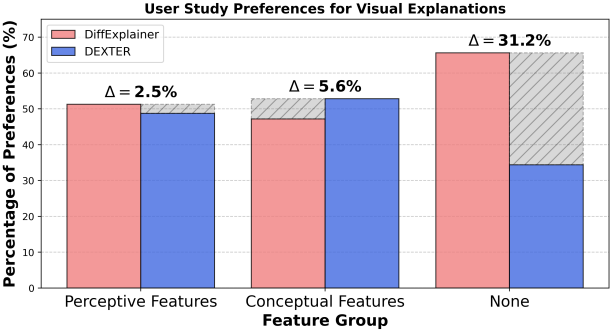
다음은 RobustResNet50에서 DEXTER와 DiffExplainer의 설명을 비교한 것이다.

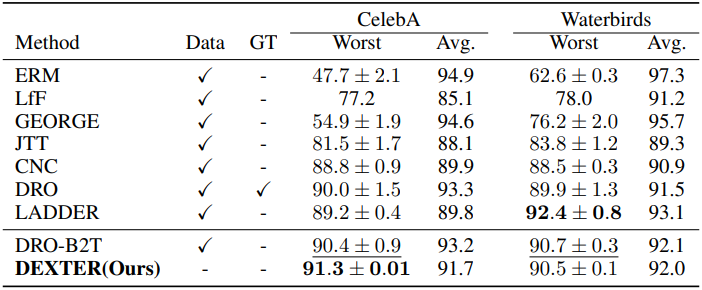
2. Slice discovery and debiasing
다음은 slice discovery (모델이 성능이 떨어지는 데이터 하위 그룹을 식별)와 편향 제거에 대한 성능을 비교한 결과이다.
3. Bias explanation
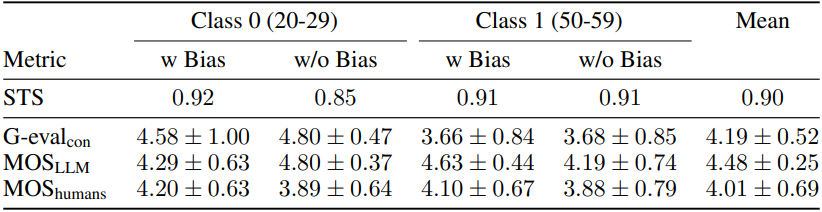
다음은 DEXTER 편향 보고서의 예시들이다. Report 1은 클래스 1에 남성이 과도하게 포함된 FairFaces 변형 데이터셋으로 학습된 classifier를 분석하고, Report 2는 균형 잡힌 데이터셋에 해당한다.

다음은 DEXTER 편향 보고서에 대한 평가 결과이다.
4. Ablation Study
다음은 텍스트 프롬프팅 전략에 대한 비교 결과이다.

다음은 single-word prompt와 multi-word prompt 최적화 및 보조 task 사용 여부에 대한 ablation 결과이다.

Limitations
- 계산량이 많다. 최적화에는 클래스당 약 10분이 소요되지만, 100개의 이미지를 생성하고 최종 편향 보고서를 생성하는 데는 backpropagation을 제외하면 약 15초밖에 걸리지 않아 오프라인 사용에 적합하다.
- Stable Diffusion에 기반하므로 부적절한 이미지가 생성될 위험이 있다.