[논문리뷰] Describe Anything: Detailed Localized Image and Video Captioning
ICCV 2025. [Paper] [Page] [Github]
Long Lian, Yifan Ding, Yunhao Ge, Sifei Liu, Hanzi Mao, Boyi Li, Marco Pavone, Ming-Yu Liu, Trevor Darrell, Adam Yala, Yin Cui
NVIDIA | UC Berkeley | UCSF
22 Apr 2025

Introduction
기존 VLM (ex. GPT-4o) 대부분은 정확한 위치 파악(localization)을 위한 메커니즘이 부족하다. VLM이 bounding box와 같은 2D localization 신호를 활용할 수 있도록 하는 최근 방법은 자세한 설명보다는 짧은 문구만 생성하는 경우가 많다. 더 긴 캡션을 생성하는 방법들도 최소한의 디테일만 제공하거나 관련 없는 콘텐츠를 포함한다. Detailed localized captioning (DLC)이 어려운 요인은 다음과 같다.
- 영역 디테일의 손실: 기존 방식에서는 글로벌한 이미지 표현에서 로컬 feature들을 추출하여, 특히 복잡한 장면에서 작은 물체의 경우 세밀한 디테일이 손실되는 경우가 많았다. LLM이 visual feature를 처리할 때쯤이면 정밀한 캡션 생성에 필요한 중요한 디테일은 이미 손실된 상태이다. 관심 영역을 자르면 디테일이 향상될 수 있지만, 필수적인 맥락적 단서를 잃을 수 있다.
- 고품질 데이터셋의 부족: 기존 데이터셋은 일반적으로 짧고 상세한 캡션을 생성하는 모델을 학습시키기에 충분하지 않은 짧은 문구만 제공한다. 합성 데이터 접근법은 bounding box를 기반으로 하므로 관심 영역을 정확하게 표현하지 못하고, 글로벌 캡션에 의존하는 방식은 눈에 띄지 않는 영역을 포착하는 데 어려움을 겪을 수 있다.
- 벤치마크의 한계: 기존의 localized captioning 벤치마크는 언어 기반 이미지 captioning metric 또는 LLM 기반 점수를 사용하여 생성된 캡션을 레퍼런스 캡션과 비교했다. 그러나 벤치마크에 제공된 레퍼런스 캡션에는 해당 영역에 대한 포괄적인 정보가 부족한 경우가 많기 때문에, DLC 모델은 레퍼런스에 명시적으로 언급되지 않은 정확한 정보에 대해 불이익을 받는 경우가 많다.
영역 feature의 디테일 손실을 해결하기 위해, 본 논문은 영역적 디테일과 글로벌 컨텍스트를 모두 보존하는 Describe Anything Model (DAM)을 제안하였다. DAM은 두 가지 핵심 구성 요소를 통해 복잡한 장면 속 작은 물체에 대해서도 상세하고 정확한 캡션을 생성할 수 있다.
- Focal Prompt: 관심 영역을 dense한 토큰으로 인코딩
- Localized Vision Backbone 글로벌 컨텍스트를 통합하면서 정확한 위치 추정을 보장
저자들은 고품질 DLC 데이터셋의 부족을 극복하기 위해, semi-supervised learning (SSL) 기반 데이터 파이프라인인 DLC-SDP를 도입하여 두 단계로 고품질 캡션을 생성하였다.
- 사람이 주석을 단 segmentation 데이터셋에서 고품질 마스크와 키워드를 활용하여 VLM을 쿼리하여, 각 키워드를 각 마스크가 참조하는 영역에 대한 디테일한 캡션으로 확장한다.
- 웹 이미지를 레이블이 없는 데이터셋으로, segmentation 데이터셋을 레이블이 있는 데이터로 하여 self-training을 수행한다.
LLM은 설명을 여러 세부 단위로 요약하여 고품질 캡션이 포함된 다양한 데이터셋을 생성하고, 이를 통해 모델이 우수한 성능을 발휘할 수 있도록 한다.
저자들은 기존 벤치마크의 한계를 완화하기 위해, DLC-Bench를 도입했다. DLC-Bench는 각 영역에 대해 미리 정의된 긍정적 속성과 부정적 속성을 기반으로 DLC를 평가하여 포괄적인 레퍼런스 캡션에 대한 의존성을 제거하였다. DLC-Bench는 더욱 유연하고 정확한 평가를 제공하여 모델이 유익하고 정확한 설명을 생성하도록 지원한다.
DAM: Describe Anything Model
1. Task Formulation
DLC task는 이미지나 동영상 내의 특정 영역에만 초점을 맞춘 포괄적인 텍스트 설명을 생성하는 것이 목표이다. 구체적으로, $N$개의 입력 프레임 $I(i) \in \mathbb{R}^{H \times W \times 3}$외 각 프레임의 관심 영역을 나타내는 해당 바이너리 마스크 \(M(i) \in \{0, 1\}^{H \times W}\)가 주어졌을 때, 캡션 생성 모델을 통해 해당 영역 내 콘텐츠에 대한 상세 설명 $T$를 생성하는 것이 목표이다.
\[\begin{equation} T = \textrm{CaptioningModel} (\{ I^{(i)}, M^{(i)} \}_{i=1}^N) \end{equation}\]다른 형태의 localization은 SAM이나 SAM 2와 같은 segmentation model을 통해 마스크로 변환될 수 있으므로, 바이너리 마스크 $M(i)$를 localization 입력으로 사용하는 데 중점을 두었다.
2. Model Architecture
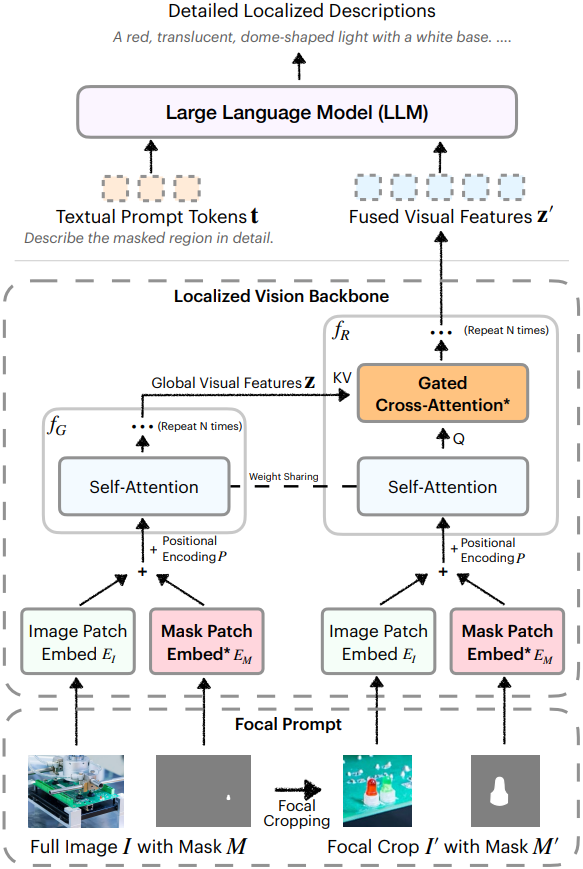
위 그림에서 볼 수 있듯이, DAM은 focal prompt와 localized vision backbone이라는 두 가지 핵심 구성 요소로 이루어져 있다.
Focal Prompt
관심 영역을 해당 컨텍스트 내에서 자세히 표현하기 위해, 전체 이미지와 지정된 영역을 중심으로 한 focal crop, 그리고 해당 마스크를 포함하는 focal prompt를 도입했다.
먼저 마스크 $M$의 bounding box $B$를 추출하고 수평/수직 방향으로 $\alpha$배 확장하여 추가 주변 컨텍스트를 포함한다.
\[\begin{equation} B^\prime = \textrm{ExpandBox}(B, \alpha) \end{equation}\]예를 들어, $\alpha = 3$으로 설정하면 원래 bounding box보다 최대 9배 큰 영역이 생성된다. 확장된 bounding box의 높이 또는 너비가 48픽셀 미만인 경우, 매우 작은 영역에 대한 충분한 컨텍스트를 확보하기 위해 해당 차원의 최소 크기를 48픽셀로 적용한다.
이미지와 마스크의 focal crop은 다음과 같다.
\[\begin{equation} I^\prime = I \vert B^\prime, \quad M^\prime = M \vert B^\prime \end{equation}\]($\vert B^\prime$은 $B^\prime$으로 crop)
따라서 focal prompt는 전체 이미지 $I$와 그 마스크 $M$, focal crop $I^\prime$과 그 마스크 $M^\prime$으로 구성된다. 이를 통해 focal prompt는 전체 컨텍스트와 관심 영역에 대한 자세한 정보를 모두 담게 된다.
Localized Vision Backbone
VLM을 사용하여 focal prompt의 네 가지 구성 요소를 모두 효과적으로 처리하는 것은 쉽지 않다. 단순하게 concat하면 성능 저하가 발생하기 때문이다. 본 논문에서는 마스크를 공간적으로 정렬된 방식으로 인코딩하여, 로컬한 이해를 달성하고, gated cross-attention을 통해 글로벌 컨텍스트를 관심 영역에 통합하는 localized vision backbone을 제안하였다.
Localization 입력 처리
ViT에서 linear patch embedding layer로 이미지를 인코딩하는 방식과 유사하게, 하나의 채널로 2D 입력을 받는 다른 patch embedding layer를 통해 마스크 $M$을 전체 이미지 $I$에 통합한다.
구체적으로, 전체 이미지 $I$와 마스크 $M$은 patch embedding layer를 거쳐 처리된 후, 글로벌 비전 인코더 \(f_\textrm{G}(\cdot)\)를 거쳐 글로벌 visual feature $\textbf{z}$를 얻는다. Focal crop $I^\prime$과 마스크 $M^\prime$은 영역 비전 인코더 \(f_\textrm{R}(\cdot)\)과 유사한 과정을 거치는데, \(f_\textrm{R}(\cdot)\)은 $\textbf{z}$를 컨텍스트로 사용하여 최종 visual feature $\textbf{z}^\prime$을 얻는다.
\[\begin{aligned} \textbf{x} &= E_\textrm{I} (I) + E_\textrm{M} (M) + P \\ \textbf{z} &= f_\textrm{G} (\textbf{x}) \\ \textbf{x}^\prime &= E_\textrm{I} (I^\prime) + E_\textrm{M} (M^\prime) + P \\ \textbf{z}^\prime &= f_\textrm{R} (\textbf{x}^\prime, \textbf{z}) \end{aligned}\](\(E_\textrm{I}\)와 \(E_\textrm{M}\)은 각각 이미지와 마스크의 patch embedding layer, $P$는 위치 인코딩)
새로 추가된 \(E_\textrm{M}\)은 출력 값이 0으로 초기화되어 fine-tuning 전에 VLM의 초기 동작이 영향을 받지 않도록 한다.
Gated cross-attention adapter를 사용한 영역 feature 인코딩
글로벌 컨텍스트를 focal prompt에 통합하기 위해, 영역 비전 인코더 \(f_\textrm{R}\)의 각 transformer block에 gated cross-attention adapter를 삽입한다. Self-attention layer와 feed-forward layer 다음에, 로컬 feature가 글로벌 feature에 attention할 수 있도록 gated cross-attention 메커니즘을 추가한다.
\[\begin{aligned} \textbf{h}^{(l) \prime} &= \textbf{h}^{(l)} + \textrm{tanh} (\gamma^{(l)}) \cdot \textrm{CrossAttn} (\textbf{h}^{(l)}, \textbf{z}) \\ \textbf{h}_\textrm{Adapter}^{(l)} &= \textbf{h}^{(l) \prime} + \textrm{tanh} (\beta^{(l)}) \cdot \textrm{FFN} (\textbf{h}^{(l) \prime}) \end{aligned}\](\(\textbf{h}^{(l)}\)은 \(f_\textrm{R}\)의 $l$번째 self-attention block의 출력, \(\gamma^{(l)}\)과 \(\beta^{(l)}\)는 학습 가능한 스케일링 파라미터, $\textrm{CrossAttn}$은 \(\textbf{h}^{(l)}\)을 query로, $\textbf{z}$를 key와 value로 하는 cross-attention)
다음 transformer block에서는 \(\textbf{h}^{(l)}\) 대신 \(\textbf{h}_\textrm{Adapter}^{(l)}\)가 사용된다. 파라미터 수를 줄이기 위해 \(f_\textrm{R}\)과 \(f_\textrm{G}\)는 self-attention block 가중치를 공유한다.
\(\gamma^{(l)}\)과 \(\beta^{(l)}\)을 0으로 초기화함으로써, 모델의 초기 동작이 fine-tuning 이전의 원래 VLM과 동일하게 유지되도록 한다. 학습 과정에서 모델은 글로벌 컨텍스트를 활용하여 영역 feature 표현을 향상시키고, 이를 통해 상세하고 정확한 설명을 가능하게 한다.
디테일한 localize된 설명 생성
글로벌 비전 인코더와 영역 비전 인코더의 visual feature는 결합되어 LLM에 입력되어 세부적이고 상황에 맞는 설명 $T$를 생성한다.
\[\begin{equation} T = \textrm{LLM} (\textbf{t}, \textbf{z}^\prime) \end{equation}\]($\textbf{t}$는 텍스트 프롬프트 토큰)
특히, 제안된 구성 요소는 비전 토큰의 시퀀스 길이를 증가시키지 않아 DAM의 효율성을 유지한다. 새로운 모듈, 즉 \(E_\textrm{M}\), \(\gamma^{(l)}\), \(\beta^{(l)}\)을 0으로 초기화함으로써, fine-tuning 이전에 VLM의 사전 학습된 성능을 보존하여 사전 학습을 다시 하지 않고도 기존 VLM을 원활하게 적응시킬 수 있다. 이러한 설계 덕분에 VLM 사전 학습을 포함하는 기존 방법보다 훨씬 적은 학습 데이터를 필요로 한다 (약 150만 개).
3. Extension to Videos
이미지는 하나의 프레임을 가진 동영상으로 간주될 수 있으므로, 이 모델은 프레임 시퀀스와 해당 마스크들을 처리하여 동영상 처리로 자연스럽게 확장된다. 모든 프레임의 visual feature는 시퀀스 차원에서 concat된 후 언어 모델에 입력되어 동영상 프레임 전반에 걸쳐 DLC를 생성한다. 이는 VLM이 동영상을 처리하도록 사전 학습된 방식과 호환된다. SAM 2를 활용하여 sparse localization을 각 프레임의 마스크로 변환한다.
DLC-SDP: SSL-based Data Pipeline
DAM의 효과는 DLC를 위한 고품질 학습 데이터에 크게 좌우된다. 이를 위해, 본 논문에서는 대규모의 다양한 고품질 DLC 데이터셋을 구축할 수 있는 2단계 접근법인 semi-supervised learning (SSL) 기반 데이터 파이프라인(DLC-SDP)을 제안하였다.
1. Stage 1: Leveraging Existing Annotations
DLC-SDP의 첫 번째 단계는 데이터 생성 문제를 비전 기반 설명 확장 task로 재구성한다. 현재 VLM은 레퍼런스 마스크가 주어졌을 때 DLC를 생성하는 데 어려움을 겪는 경우가 많지만, 짧은 localized caption을 상세한 설명으로 효과적으로 확장할 수 있다. 따라서, 기존 segmentation 데이터셋에서 사람이 주석 처리한 고품질 마스크와 키워드를 활용하여, 레퍼런스 마스크가 주어졌을 때 각 영역 키워드를 상세한 캡션으로 확장하도록 VLM 쿼리를 재구성했다.
중요한 점은, 본 논문의 모델이 초기 키워드를 입력으로 사용하지 않고도 이러한 고품질 설명을 예측하도록 학습되었다는 것이다. Inference 시점에 클래스 레이블이 제공되지 않고, 기존 VLM은 이러한 레이블 없이는 성능이 저하되기 때문에, distillation을 위한 VLM 프롬프팅 방식보다 우수한 데이터 품질을 보장한다.
2. Stage 2: SSL with Unlabeled Data
고품질 수동 주석에 의존하는 것은 확장성이 낮기 때문에, 두 번째 단계에서는 self-training 기반 SSL 기법을 사용한다. Self-training 방식은 다음 네 단계로 구성된다.
- 마스크 생성: 레이블이 없는 웹 이미지에서 물체 마스크를 추출하기 위해 open-vocabulary segmentation model을 사용한다.
- 설명 생성: 1단계 학습이 끝난 DAM은 해당 영역에 대한 DLC를 생성한다.
- 신뢰도 기반 필터링: 고품질 샘플만 추출하기 위해 CLIP 기반 신뢰도 필터링을 적용한다.
- 데이터 확장: 새롭게 생성된 (이미지, 마스크, 설명) triplet을 학습 데이터셋에 추가한다.
이 SSL 방식은 물체 카테고리의 범위를 획기적으로 확장하고 데이터 다양성을 높인다. 또한, DAM이 여러 세분성으로 캡션을 생성할 수 있도록 하기 위해 LLM을 활용하여 상세 설명을 더 짧은 형태로 요약한다. 이를 통해 DAM은 간결한 구(phrase)부터 여러 문장까지 다양한 캡션을 유연하게 생성할 수 있다.
DLC-SDP로 얻은 데이터로 학습된 모델은 GPT-4o와 o1보다 우수한 성능을 보인다.
DLC-Bench: Benchmark for DLC
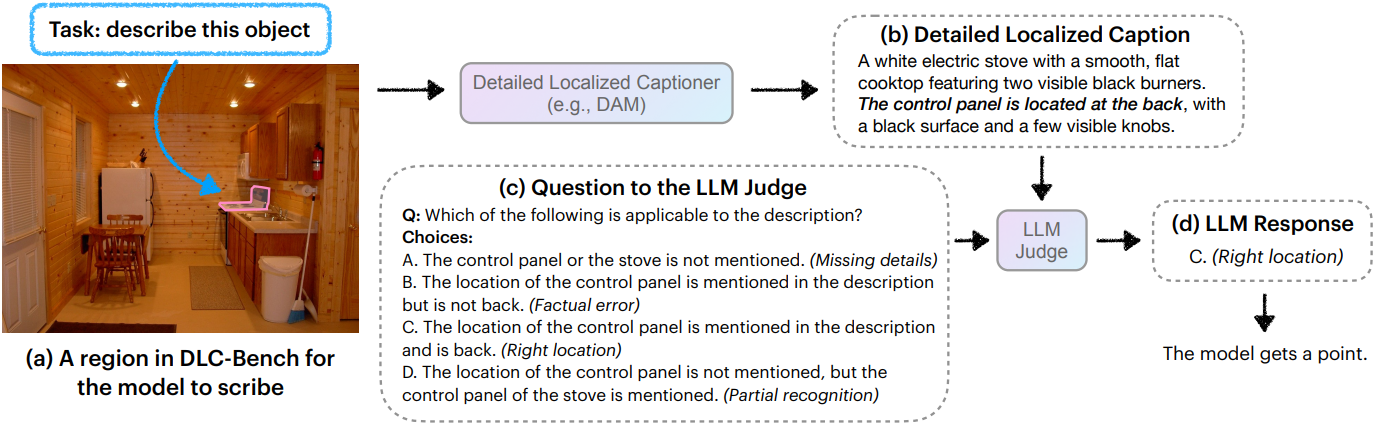
저자들은 DLC를 위해 설계된 벤치마크인 DLC-Bench를 도입하였다. DLC-Bench의 핵심 직관은 이상적인 설명은 관련성 있는 디테일이 풍부해야 하지만, 사실적 오류나 관련 없는 영역에 대한 정보는 엄격히 피해야 한다는 것이다. 따라서 각 영역에 대해 미리 정의된 긍정적 속성과 부정적 속성 집합을 기반으로 예측을 평가한다.
평가 프로세스는 두 단계로 구성된다.
- 모델은 벤치마크 데이터셋에서 마스킹된 각 영역에 대한 자세한 설명을 생성하도록 프롬프팅된다.
- LLM은 심사위원 역할을 하며, 영역 디테일에 대한 수동 큐레이팅된 일련의 긍정적, 부정적 질문에 응답하여 생성된 설명을 평가한다.
DLC-Bench는 주석이 달린 각 인스턴스에 대해 두 가지 카테고리의 질문을 사용한다.
- 긍정적 질문은 설명에 포함되어야 하는 부분의 특정 속성에 초점을 맞춘다. 설명에 명시된 디테일이 정확하게 포함되어 있으면 모델은 점수를 받는다. 누락된 정보는 점수를 받지 못하지만, 사실적 오류는 감점을 받는다.
- 부정적 질문은 포함되어서는 안 되는 디테일, 즉 유사한 대상에 공통적이지만 대상 사례에는 없는 속성이나 명시된 영역과 관련 없는 설명에 초점을 맞춘다. 모델이 이러한 디테일을 정확하게 생략하면 점수를 받는다. 반대로, 포함하면 감점을 받는다. 완전히 어긋나는 캡션으로 인해 높은 점수를 받는 것을 방지하기 위해, 캡션이 대상을 정확하게 인식하는 경우에만 점수를 부여했다.
이러한 접근 방식은 보다 유연하고 정확한 평가를 제공하여 모델이 불완전한 레퍼런스 캡션의 제약 없이 유익하고 정확한 설명을 생성하도록 장려한다. DLC-Bench는 hallucination에 대한 광범위한 속성과 잠재적 케이스들을 다루는 총 892개의 수동으로 검증된 질문으로 구성되어 있다.
Results
1. Quantitative Results
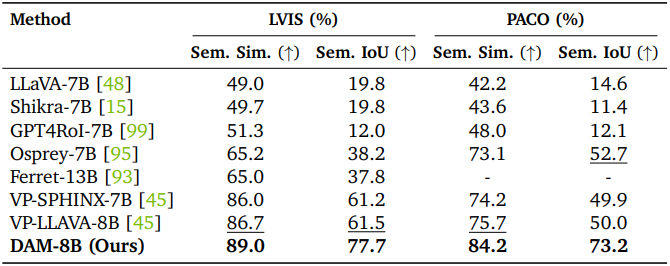
다음은 키워드 수준의 캡션 생성에 대한 평가 결과이다. (LVIS, PACO)
다음은 구(phrase) 수준의 캡션 생성에 대한 평가 결과이다. (Flickr30k Entities)
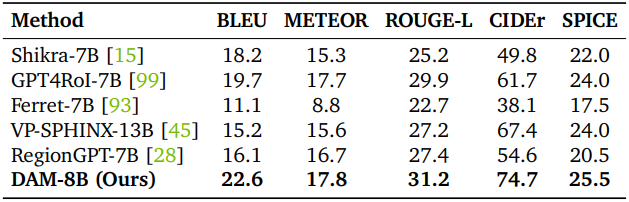
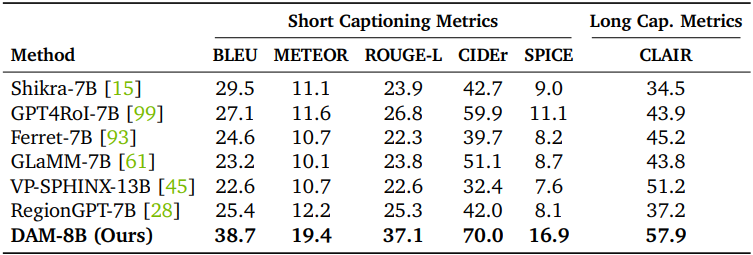
다음은 디테일한 캡션 생성에 대한 평가 결과이다. (Ref-L4)
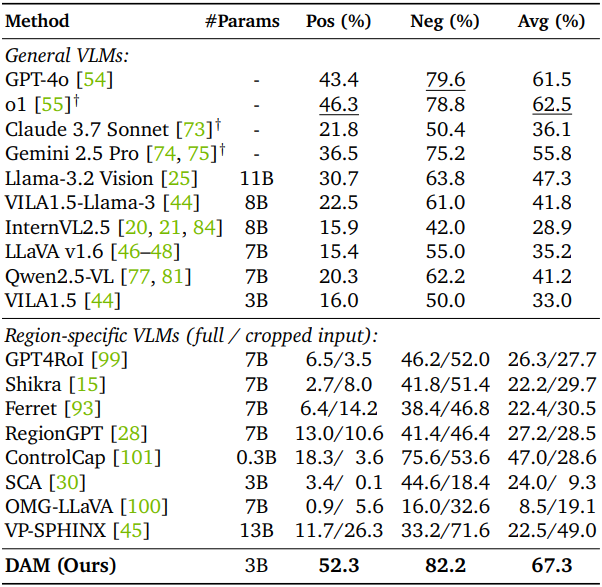
다음은 DLC-Bench에서의 DLC 정확도를 평가한 결과이다.
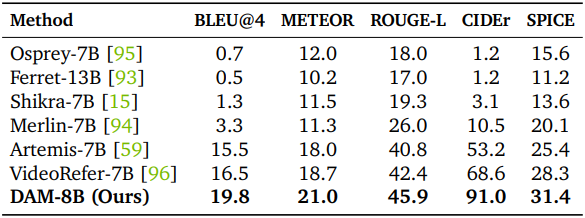
다음은 동영상 캡션 생성에 대한 평가 결과이다. (HC-STVG)
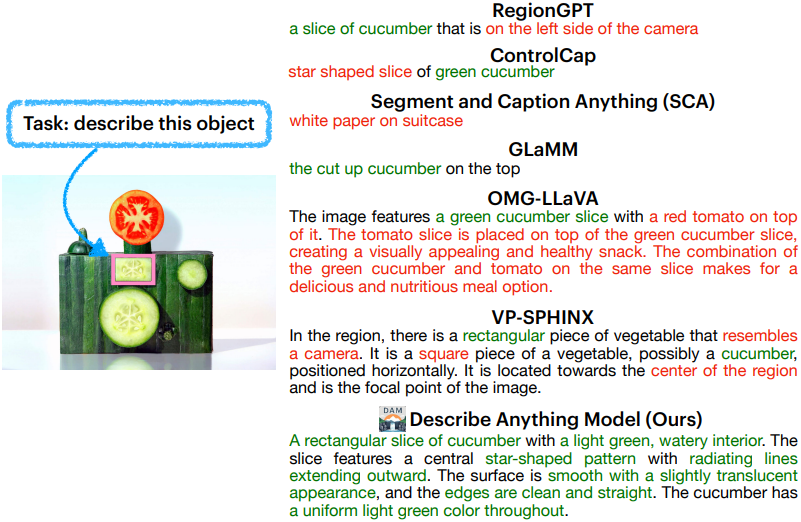
2. Qualitative Results
다음은 DAM을 다른 방법들과 비교한 예시이다.
다음은 동영상 캡션 생성 예시들이다.


다음은 설명의 세분성을 제어한 예시이다.
