[논문리뷰] DepthCrafter: Generating Consistent Long Depth Sequences for Open-world Videos
CVPR 2025 (Highlight). [Paper] [Page] [Github] [Demo]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, Ying Shan
Tencent AI Lab | The Hong Kong University of Science and Technology | ARC Lab, Tencent PCG
3 Sep 2024

Introduction
본 논문에서는 다양한 동영상에 대해 추가 정보 없이도 충실도가 높은 디테일을 가진 시간적으로 일관된 긴 깊이 시퀀스를 생성하는 것을 목표로 한다. 저자들은 다양한 유형의 동영상 생성에 있어 diffusion model의 강력한 성능에서 영감을 받아, 동영상 diffusion model의 다양한 동영상에 대한 일반화 능력을 유지하면서 동영상 깊이 추정에 이를 활용하는 DepthCrafter를 제안하였다.
사전 학습된 image-to-video diffusion model로부터 video-to-depth 모델인 DepthCrafter를 학습하기 위해, 현실 데이터셋은 풍부한 콘텐츠 다양성을 제공하고 합성 데이터셋은 정밀한 깊이 디테일을 제공하기 때문에, 두 가지 스타일로 쌍을 이루는 동영상 깊이 데이터셋을 컴파일하였다. 또한, 시간적 컨텍스트 측면에서, 대부분의 기존 동영상 diffusion model은 한 번에 고정된 적은 수의 프레임만 생성할 수 있다. 예를 들어, Stable Video Diffusion (SVD)에서는 25개의 프레임을 생성할 수 있다. 그러나 이 프레임은 일반적으로 동영상 전체의 깊이 분포를 정확하게 정렬하기에는 너무 짧다.
가변적인 긴 시간적 컨텍스트를 지원하고 두 가지 스타일 데이터셋의 장점을 결합하기 위해, 저자들은 다양한 길이의 서로 다른 데이터셋을 사용하여 diffusion model의 특정 레이어를 점진적으로 학습하는 3단계 학습 전략을 제시하였다. 이를 통해 동영상 diffusion model을 조정하여 최대 110프레임까지 가변 길이의 깊이 시퀀스를 한 번에 생성하고, 정밀한 깊이 정보와 풍부한 콘텐츠 다양성을 모두 확보할 수 있다. 매우 긴 동영상을 더욱 효과적으로 지원하기 위해, 동영상을 중첩된 세그먼트로 처리하고 이를 매끄럽게 연결하는 추론 전략을 적용했다.
Method
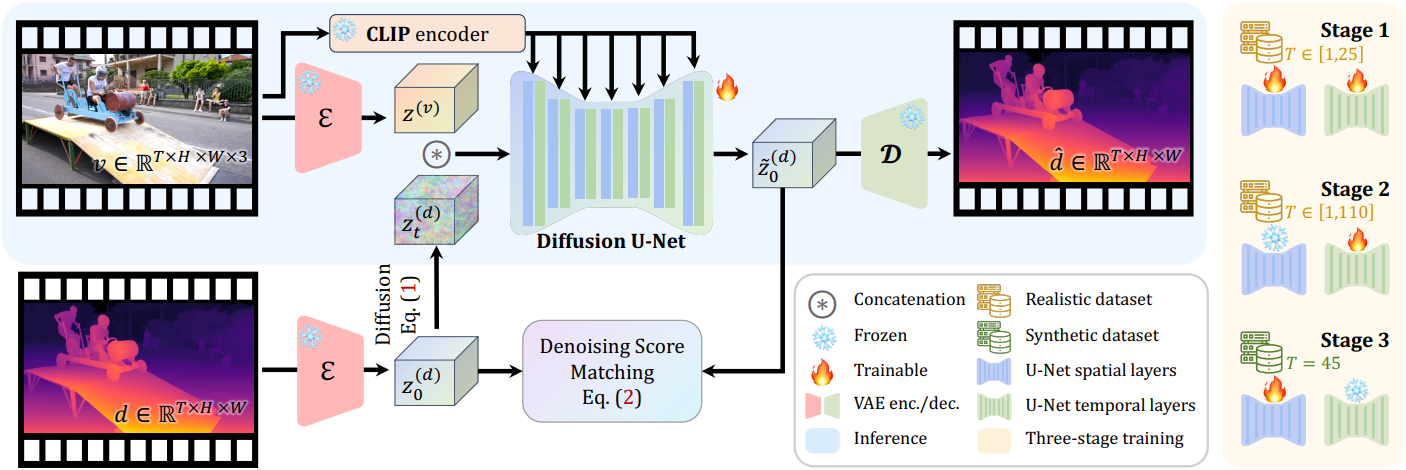
본 논문의 목표는 동영상 $\textbf{v} \in \mathbb{R}^{T \times H \times W \times 3}$이 주어졌을 때, 세밀한 디테일을 가진 시간적으로 일관된 깊이 시퀀스 $\textbf{d} \in \mathbb{R}^{T \times H \times W}$를 추정하는 것이다. 동영상의 외형, 콘텐츠 동작, 카메라 모션, 길이 등 다양한 요소를 고려할 때, 본 논문의 목표를 달성하기 위한 과제는 세 가지이다.
- 일반화 능력을 위한 동영상 콘텐츠에 대한 포괄적인 이해
- 전체 깊이 분포를 정확하게 정렬하고 시간적 일관성을 유지하기 위한 길고 가변적인 시간적 컨텍스트
- 매우 긴 동영상을 처리하는 능력
1. Formulation with Diffusion Models
Latent space 변환
계산 효율을 저하시키지 않고 고해상도 깊이 시퀀스를 생성하기 위해, 저차원 latent space에서 동작하는 latent diffusion model (LDM) 프레임워크를 채택했다. Latent space와 데이터 공간 사이의 변환은 원래 SVD에서 동영상 프레임을 인코딩 및 디코딩하기 위해 설계된 VAE를 통해 이루어졌다. 다행히도, 이 VAE는 깊이 시퀀스에 직접 사용할 수 있다.
\[\begin{equation} \textbf{z}^{(\textbf{x})} = \mathcal{E}(\textbf{x}), \quad \hat{\textbf{x}} = \mathcal{D} (\textbf{z}^{(\textbf{x})}) \end{equation}\]($\textbf{x}$는 동영상 $\textbf{v}$ 또는 깊이 시퀀스 $\textbf{d}$, $\textbf{z}^{(\textbf{x})}$는 데이터의 latent 표현, $\hat{\textbf{x}}$는 재구성된 데이터, $\mathcal{E}$와 $\mathcal{D}$는 각각 VAE의 인코더와 디코더)
깊이 시퀀스의 경우, VAE의 인코더의 3채널 입력 형식을 충족하도록 세 번 복제하고 디코더 출력의 3채널을 평균하여 깊이 시퀀스의 최종 latent 값을 얻는다. 이미지 깊이 추정의 관례에 따라, $[0, 1]$로 정규화된 상대적 깊이, 즉 affine-invariant depth를 채택한다. 그러나 예측된 깊이 시퀀스는 프레임별 정규화가 아닌 프레임 전체에서 동일한 scale과 shift를 공유하며, 이는 시간적 일관성을 유지하는 데 중요하다.
컨디셔닝
SVD는 단일 이미지를 조건으로 동영상을 생성하는 image-to-video diffusion model이다. 조건 이미지는 두 가지 방식으로 U-Net에 입력된다.
- 조건 이미지의 latent를 입력 latent에 concat
- Cross-attention을 통해 CLIP 임베딩을 중간 feature에 주입
그러나 DepthCrafter는 프레임 단위로 동영상 프레임을 조건으로 하는 깊이 시퀀스를 생성한다. 따라서 video-to-depth에 맞춰 컨디셔닝 메커니즘을 조정한다. 깊이 시퀀스의 latent $\textbf{z}^{(\textbf{d})}$와 동영상 latent $\textbf{z}^{(\textbf{v})}$가 주어지면, 동영상 latent를 noise가 더해진 깊이 latent에 프레임 단위로 concat한다. CLIP을 사용하여 동영상 프레임을 임베딩한 후, cross-attention을 통해 frame-to-frame 방식으로 임베딩을 denoiser에 주입한다. 기존의 컨디셔닝 메커니즘과 달리, 이 컨디셔닝 방식은 동영상 프레임의 포괄적인 정보를 denoiser에 제공하여 생성된 깊이 시퀀스와 동영상 콘텐츠 간의 정렬을 보장한다.
2. Training Strategy
DepthCrafter를 학습시키려면 대량의 고품질 동영상-깊이 시퀀스 쌍이 필요하다. KITTI, Scannet, VDW, DynamicReplica, MatrixCity 등 여러 동영상 깊이 데이터셋이 있지만, 이러한 데이터셋은 고품질 깊이 주석이 부족하거나 운전 장면, 실내 장면, 합성 장면 등 특정 영역에만 국한되어 있다.
데이터셋 구축
이를 위해 저자들은 현실 데이터셋과 합성 데이터셋의 두 가지 스타일의 쌍을 구성했다. 현실 데이터셋은 규모가 크고 다양하며, 합성 데이터셋은 작지만 세밀하고 정확하다.
현실 데이터셋은 다양한 장면과 모션을 가진 여러 binocular 동영상으로 구성된다. 장면 변화에 따라 동영상을 자르고, SOTA 동영상 스테레오 매칭 방법인 BiDAStereo를 적용하여 시간적으로 일관된 깊이 시퀀스를 생성한다. 이를 통해 50~200프레임 길이의 약 20만 쌍의 동영상-깊이 시퀀스를 얻었다.
합성 데이터셋은 DynamicReplica와 MatrixCity 데이터셋의 조합으로, 약 3천 개의 세밀한 깊이 주석이 포함되어 있으며, 길이는 150프레임이다.
가변적인 긴 시간적 컨텍스트
단일 프레임에서 상대적인 깊이 분포를 결정할 수 있는 이미지 깊이 추정과 달리, 동영상 깊이 추정은 전체 동영상에 대한 깊이 분포를 정확하게 정렬하고 시간적 일관성을 유지하기 위해 긴 시간적 컨텍스트가 필요하다. 또한, 실제 동영상의 길이가 상당히 다를 수 있으므로 모델은 가변 길이 추정을 지원해야 한다. 그러나 기존의 동영상 diffusion model은 한 번에 고정된 소수의 프레임만 생성할 수 있다. 사전 학습된 모델을 이 요구 사항을 충족하도록 fine-tuning하는 것은 메모리를 많이 소모하기 때문에 간단하지 않다.
3단계 학습
두 가지 스타일의 쌍을 이루는 데이터셋과 긴 시간적 컨텍스트 요구사항을 고려하여, 다양한 동영상 콘텐츠, 정확한 깊이 정보, 그리고 길고 가변적인 시퀀스에 대한 지원을 얻기 위한 3단계 학습 전략을 설계하였다.
첫 번째 단계에서는 모델을 video-to-depth에 적응시키기 위해 대용량의 현실 데이터셋을 사용하여 학습시킨다. 시퀀스 길이는 1~25 프레임에서 무작위로 샘플링하여 모델이 가변 길이의 깊이 시퀀스를 생성하는 방법을 학습할 수 있도록 한다.
두 번째 단계에서는 대용량의 현실 데이터셋을 사용하되, 시퀀스 길이는 1~110 프레임에서 무작위로 샘플링하여 모델의 temporal layer만 fine-tuning한다. Temporal layer만 fine-tuning하는 이유는 temporal layer가 시퀀스 길이에 더 민감하고, spatial layer는 이미 첫 번째 단계에서 video-to-depth 생성에 적응되어 있기 때문이다. 따라서 전체 모델을 fine-tuning하는 것보다 메모리 사용량을 크게 줄일 수 있다. 이 단계에서 긴 시간적 컨텍스트를 활용하면 모델이 길고 가변적인 시퀀스에 대한 전체 깊이 분포를 정확하게 정렬할 수 있다.
세 번째 단계에서는 45프레임의 고정된 시퀀스 길이를 갖는 작은 합성 데이터셋에서 모델의 spatial layer를 fine-tuning한다. 이는 모델이 처음 두 단계에서 이미 가변 길이의 깊이 시퀀스를 생성하는 방법을 학습했고, spatial layer를 조정해도 시간적 컨텍스트에 영향을 미치지 않기 때문이다. 합성 데이터셋의 깊이 주석이 더 정확하고 세밀하기 때문에 모델은 이 단계에서 더욱 정밀한 깊이 정보를 학습할 수 있다.
3. Inference for Extremely Long Videos
이 모델은 학습 후 최대 110프레임 길이의 깊이 시퀀스를 추정할 수 있지만, 수백 또는 수천 개의 프레임을 포함할 수 있는 실제 동영상에는 여전히 충분히 길지 않다. 이를 위해 저자들은 세그먼트별로 매우 긴 깊이 시퀀스를 추론하고 이를 매끄럽게 연결하여 전체 깊이 시퀀스를 형성하는 추론 전략을 설계하였다.
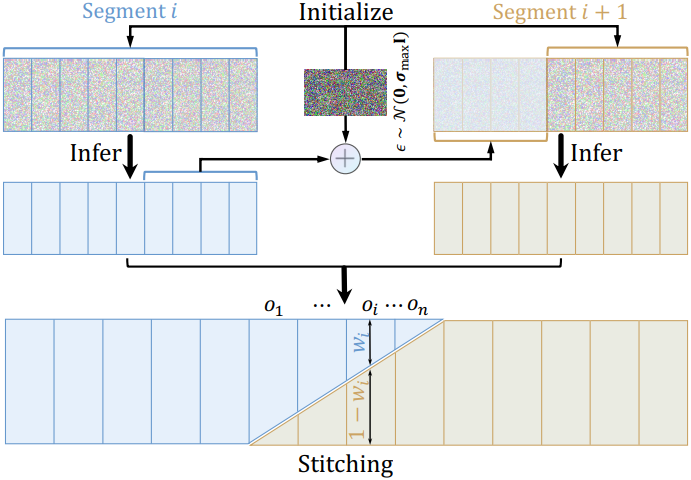
- 동영상을 길이가 최대 110프레임인 중첩된 세그먼트로 나눈다.
- 각 세그먼트에 대한 깊이 시퀀스를 추정한다. 입력 latent를 Gaussian noise \(\epsilon \sim \mathcal{N}(0, \sigma_\textrm{max}^2 I)\)로 초기화하는 대신, 이전 세그먼트의 denoise된 latent에 noise를 추가한 것으로 중첩된 프레임의 latent를 초기화하여 깊이 분포의 scale과 shift를 고정한다.
- 세그먼트 전체의 시간적 부드러움을 더욱 보장하기 위해 연속된 두 세그먼트에서 중첩된 프레임 $o_i$의 latent를 가중치 $w_i$와 $1−w_i$를 사용하여 interpolation한다. 여기서 $w_i$는 1에서 0으로 선형적으로 감소한다. 최종 깊이 시퀀스는 VAE 디코더 $\mathcal{D}$를 사용하여 스티칭된 latent를 디코딩하여 얻는다.
Experiments
- 구현 디테일
- 해상도: 320$\times$640
- optimizer: Adam
- learning rate: $1 \times 10^{-5}$
- batch size: 8
- iteration 수: 각각 8만, 4만, 1만
- GPU: NVIDIA A100 8개, 학습에 약 5일 소요
- inference denoising step: 5
1. Evaluation
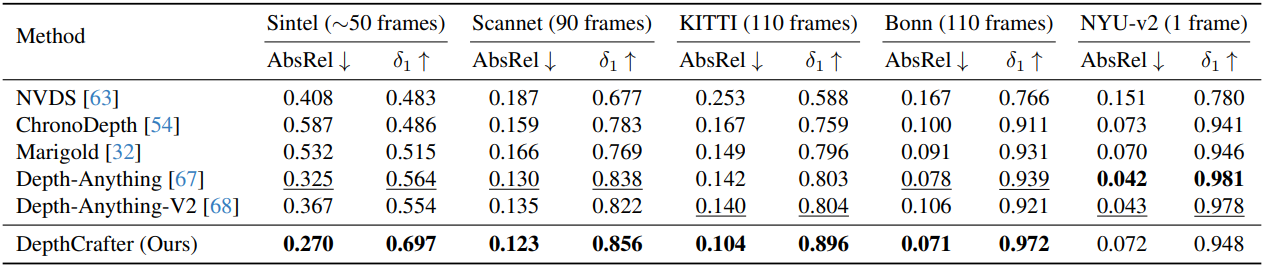
다음은 동영상 깊이 추정 결과를 비교한 것이다.

다음은 이미지 깊이 추정 결과를 Depth Anything V2와 비교한 것이다.

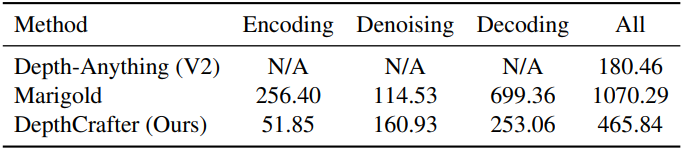
다음은 프레임당 inference 소요 시간을 비교한 표이다.
2. Ablation Studies
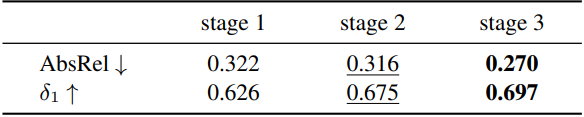
다음은 각 학습 단계에 대한 ablation 결과이다. (Sintel 데이터셋)
다음은 inference 전략에 대한 ablation 결과이다.

3. Applications
다음은 DepthCrafter를 활용한 예시들이다.

Limitations
모델의 계산 및 메모리 소비가 비교적 높다. 1024$\times$576 해상도와 110프레임 길이의 세그먼트를 처리하는 데 약 24GB의 GPU 메모리가 필요하다.