[논문리뷰] Depth-Regularized Optimization for 3D Gaussian Splatting in Few-Shot Images
CVPRW 2024. [Paper] [Page]
Jaeyoung Chung, Jeongtaek Oh, Kyoung Mu Lee
Seoul National University
22 Nov 2023
Introduction
이미지로부터 3차원 공간을 재구성하는 것은 컴퓨터 비전 분야에서 오랫동안 어려운 과제였다. 최근에는 사실적인 novel view synthesis의 타당성을 보여줌으로써 이미지로부터 완전한 3D 공간을 재구성하는 연구를 촉발시켰다. 최근 주목할 만한 개발 중에서 3D Gaussian Splatter (3DGS)는 고품질, 빠른 재구성 속도, 실시간 렌더링 지원의 조합으로 두각을 나타냈다. 3DGS는 장면의 모든 부분을 표현하기 위해 불투명도가 있는 Gaussian spherical harmonic splat들을 기본 요소로 사용한다. 여러 이미지를 동시에 만족시키기 위해 splat에 제약 조건을 부과하여 splat이 일관된 형상을 구성하도록 가이드한다.
장면에 대한 작은 splat을 모으는 접근 방식은 복잡한 디테일을 표현할 수 있지만 로컬한 특성으로 인해 overfitting되기 쉽다. 3DGS는 글로벌 구조 없이 멀티뷰 색상 supervision에 따라 독립적으로 splat들을 최적화한다. 따라서 전체적인 기하학적 단서를 제공할 수 있는 충분한 양의 이미지가 없으면 overfitting에 대한 예방 조치가 없다. 이 문제는 3D 장면 최적화에 사용되는 이미지 수가 적을수록 더욱 두드러진다. 몇 개의 이미지에서 얻은 제한된 기하학적 정보로 인해 로컬 최적을 향한 잘못된 수렴이 발생하여 최적화 실패 또는 floater 아티팩트가 발생한다. 그럼에도 불구하고 제한된 수의 이미지로 3D 장면을 재구성하는 것은 매우 중요하다.
한 가지 직관적인 해결책은 깊이와 같은 추가적인 기하학적 단서를 보완하는 것이다. 수많은 3D 재구성 상황에서 깊이는 직접적인 기하학적 정보를 제공함으로써 3D 장면을 재구성하는 데 매우 귀중한 것으로 입증되었다. 이러한 강력한 기하학적 단서를 얻기 위해 RGB 카메라에 정렬된 깊이 센서가 사용된다. 이러한 장치는 최소한의 오차로 dense한 깊이 맵을 제공하지만 이러한 장비의 필요성은 실제 적용에 장애물이 된다.
따라서 본 논문은 카메라 파라미터와 3D feature point를 동시에 계산하는 Structure-from-Motion (SfM)의 sparse한 깊이 맵을 사용하여 깊이 추정 네트워크의 출력을 조정하여 dense한 깊이 맵을 얻는다. 3DGS는 SfM, 특히 COLMAP을 사용하여 이러한 정보를 얻는다. 그러나 SfM은 이미지 수가 적을 때 사용 가능한 3D feature point들이 눈에 띄게 부족한 현상도 발생한다. 포인트 클라우드의 sparse한 특성으로 인해 모든 Gaussian splat을 정규화하는 것도 비실용적이다. 따라서 dense한 깊이 맵을 추론하는 방법이 필수적이다. 이미지에서 dense한 깊이를 추출하는 방법 중 하나는 monocular depth estimation model을 활용하는 것이다. 이러한 모델은 데이터에서 얻은 prior를 기반으로 개별 이미지에서 dense한 깊이 맵을 추론할 수 있지만 스케일의 모호성으로 인해 상대적인 깊이만 생성한다. 스케일의 모호함은 멀티뷰 이미지에서 심각한 기하학적 충돌을 일으키기 때문에 독립적으로 추론된 깊이 간의 충돌을 방지하기 위해 스케일을 조정해야 한다. COLMAP의 sparse한 깊이를 추정된 dense한 깊이 맵에 피팅함으로써 스케일을 조정할 수 있다.
본 논문에서는 사전 학습된 monocular depth estimation model의 prior와 smoothness 제약 조건을 활용하여 몇 개의 RGB 이미지를 사용하여 3D 장면을 표현하는 방법을 제안하였다. 추정된 깊이의 스케일과 오프셋을 sparse한 COLMAP 포인트에 적용하여 스케일 모호성을 해결한다. 조정된 깊이를 기하학적 가이드로 사용하여 색상 기반 최적화를 지원하고 floater 아티팩트를 줄이고 기하학적 조건을 만족시킨다. 저자들은 수정된 깊이조차도 장면을 기하학적 최적해로 가이드하는 데 도움이 된다는 것을 관찰했다. Depth-guide loss가 증가하기 시작할 때 최적화 프로세스가 중지되는 early stop 전략을 통합하여 overfitting 문제를 방지한다. 또한 안정성을 높이기 위해 smoothness 제약 조건을 적용하여 인접한 3D 포인트가 비슷한 깊이를 갖도록 보장한다.
Method
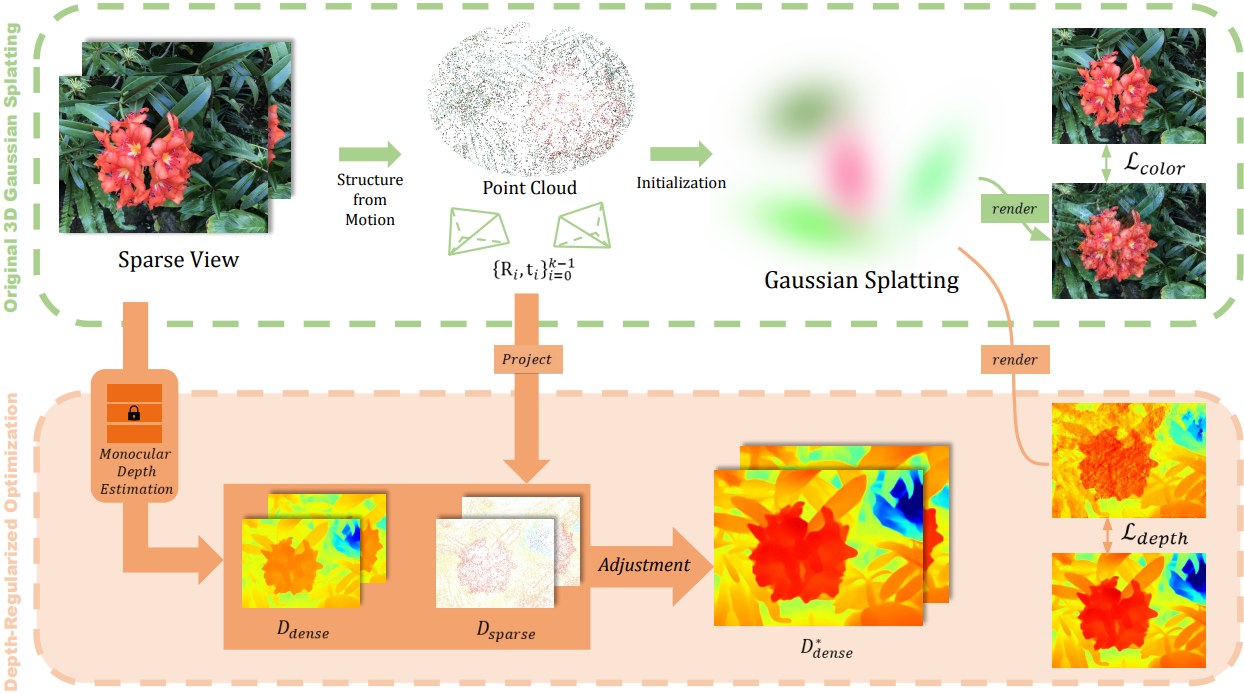
본 논문의 방법은 작은 이미지셋 \(\{I_i\}_{i=0}^{k-1}, I_i \in [0, 1]^{H \times W \times 3}\)에서 최적화를 용이하게 한다. 전처리로 SfM(ex. COLMAP) 파이프라인을 실행하고 카메라 포즈 $R_i \in \mathbb{R}^{3 \times 3}$와 $t_i \in \mathbb{R}^3$, intrinsic parameter $K_i \in \mathbb{R}^{3 \times 3}$, 포인트 클라우드 $P \in \mathbb{R}^{n \times 3}$을 얻는다. 이러한 정보를 사용하면 보이는 모든 점을 픽셀 공간에 투영하여 각 이미지에 대한 sparse한 깊이 맵을 쉽게 얻을 수 있다.
본 논문의 접근 방식은 3DGS를 기반으로 한다. Color loss \(\mathcal{L}_\textrm{color}\)와 D-SSIM loss \(\mathcal{L}_\textrm{D−SSIM}\)을 사용하여 렌더링된 이미지를 기반으로 Gaussian splat을 최적화한다. 3DGS 최적화에 앞서 깊이 추정 네트워크를 사용하여 각 이미지의 깊이 맵을 추정하고 sparse한 깊이 맵을 피팅한다. Color rasterization 프로세스를 활용하여 Gaussian splatting 집합에서 깊이를 렌더링하고 dense한 깊이 prior를 사용하여 깊이 제약 조건을 추가한다. 인접한 픽셀의 깊이 사이의 부드러움을 위해 추가 제약 조건을 추가하고 few-shot 설정에 대한 최적화 옵션을 개선한다.
1. Preparing Dense Depth Prior
Gaussian splat의 locality로 인해 splat을 그럴듯한 형상으로 가이드하려는 목표로 글로벌한 기하학 정보를 제공해야 한다. 밀도 깊이는 유망한 geometry prior 중 하나이지만 이를 구성하는 데 어려움이 있다. SfM 포인트의 밀도는 이미지 수에 따라 달라지므로 유효한 포인트 수가 너무 적어 few-shot 설정에서 dense한 깊이를 직접 추정할 수 없다. 최신 깊이 완성 모델조차도 상당한 정보 격차로 인해 dense한 깊이를 완성하지 못한다.
Depth prior를 설계할 때 coarse한 깊이라도 splat을 가이드하고 잘못된 형상에 갇힌 splat으로 인해 발생하는 아티팩트를 제거하는 데 크게 도움이 된다. 따라서 최적화를 위한 coarse하고 dense한 깊이 가이드를 제공하기 위해 SOTA monocular depth estimation model과 스케일 매칭을 사용한다. Monocular depth estimation model $F_\theta$는 학습 이미지 $I$에서 dense한 깊이 \(D_\textrm{dense}\)를 출력한다.
\[\begin{equation} D_\textrm{dense} = s \cdot F_\theta (I) + t \end{equation}\]추정된 dense한 깊이 $D_\textrm{dense}$의 스케일 모호성을 해결하기 위해 추정된 깊이의 스케일 $s$와 오프셋 $t$를 sparse한 SfM 깊이 $D_\textrm{sparse}$로 조정한다.
\[\begin{equation} s^\ast, t^\ast = \underset{s, t}{\arg \min} \sum_{p \in D_\textrm{sparse}} \| w(p) \cdot D_\textrm{sparse} (p) - D_\textrm{dense} (p; s, t) \|^2 \end{equation}\]여기서 $w \in [0, 1]$는 SfM의 reprojection error의 역수로 계산된 각 feature point의 신뢰도를 나타내는 정규화된 가중치이다. 마지막으로, Gaussian splatting의 최적화 loss를 정규화하기 위해 조정된 dense한 깊이 \(D_\textrm{dense}^\ast = s^\ast \cdot F_\theta (I) + t^\ast\)를 사용한다.
2. Depth Rendering through Rasterization
3DGS는 rasterization 파이프라인을 활용하여 GPU의 병렬 아키텍처에서 활용되는 단절되고 구조화되지 않은 splat을 렌더링한다. 미분 가능한 포인트 기반 렌더링 기술을 기반으로 $\alpha$-blending을 통해 splat을 rasterizing하여 이미지를 렌더링한다. 포인트 기반 접근 방식은 NeRF 스타일의 볼륨 렌더링과 유사한 방정식을 활용하여 해당 픽셀을 덮는 정렬된 포인트로 픽셀 색상을 rasterizing한다.
\[\begin{equation} C = \sum_{i \in N} c_i \alpha_i T_i \\ \textrm{where} \quad T_i = \prod_{j=1}^{i-1} (1 - \alpha_j) \end{equation}\]여기서 $C$는 픽셀 색상, $c$는 splat 색상, $\alpha$는 학습된 불투명도에 2D Gaussian의 공분산을 곱한 값이다. 이 공식은 카메라에 더 가깝게 위치한 불투명한 splat의 색상 $c$를 우선시하여 최종 결과 $C$에 큰 영향을 미친다. Rasterization 파이프라인을 활용하여 Gaussian splat의 깊이 맵을 렌더링한다.
\[\begin{equation} D = \sum_{i \in N} d_i \alpha_i T_i \end{equation}\]여기서 $D$는 렌더링된 깊이이고 $d_i = (R_i p_i + T_i)_z$는 카메라에서 각 splat의 깊이이다. 위 식은 $\alpha_i$와 $T_i$의 직접적인 활용을 가능하게 하며 최소한의 계산 부하로 빠른 깊이 렌더링을 촉진한다. 마지막으로 L1 거리를 이용하여 렌더링된 깊이를 추정된 dense한 깊이로 가이드한다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = \| D - D_\textrm{dense}^\ast \|_1 \end{equation}\]3. Unsupervised Smoothness Constraint
각각의 독립적으로 추정된 깊이가 COLMAP 포인트에 맞춰졌음에도 불구하고 충돌이 자주 발생한다. 저자들은 충돌을 정규화하기 위해 기하학적 부드러움을 위한 unsupervised 제약 조건을 도입했다. 이 제약 조건은 유사한 3D 위치의 포인트가 이미지 평면에서 유사한 깊이를 가짐을 의미한다. 저자들은 Canny edge detector를 마스크로 활용하여 경계를 따라 깊이에 큰 차이가 있는 영역을 정규화하지 않도록 하였다. 깊이 $d_i$와 인접한 깊이 $d_j$에 대해 둘 사이의 차이를 정규화한다.
\[\begin{equation} \mathcal{L}_\textrm{smooth} = \sum_{d_j \in \textrm{adj} (d_i)} \unicode{x1D7D9}_\textrm{ne} (d_i, d_j) \cdot \| d_i - d_j \|^2 \end{equation}\]여기서 \(\unicode{x1D7D9}_\textrm{ne}\)는 두 깊이가 모두 edge에 있지 않은지 여부를 나타내는 indicator function이다.
최종 loss는 다음과 같다.
\[\begin{aligned} \mathcal{L} &= (1 - \lambda_\textrm{ssim}) \mathcal{L}_\textrm{color} + \lambda_\textrm{ssim} \mathcal{L}_\textrm{D-SSIM} \\ & \quad + \lambda_\textrm{depth} \mathcal{L}_\textrm{depth} + \lambda_\textrm{smooth} \mathcal{L}_\textrm{smooth} \end{aligned}\]여기서 앞의 두 loss 항 \(\mathcal{L}_\textrm{color}\)와 \(\mathcal{L}_\textrm{D-SSIM}\)은 원래 3DGS의 loss이다.
4. Modification for Few-Shot Learning
저자들은 제한된 이미지로 3D 장면을 생성하기 위해 원래 논문의 두 가지 최적화 기술을 수정했다. 3DGS에 사용된 기술은 상당한 수의 이미지를 활용한다는 가정 하에 설계되었으므로 few-shot 설정에서 수렴을 방해할 가능성이 있다.
- Spherical harmonics(SH)의 최대 degree를 1로 설정했다. 이는 정보 부족으로 인한 고주파수를 담당하는 SH 계수의 overfitting을 방지한다.
- 깊이 loss를 기반으로 하는 early-stop 정책을 구현하였다. 저자들은 depth loss와 smoothness loss을 가이드로 사용하면서 주로 color loss에 의해 구동되도록 최종 loss를 구성하였다. 따라서 color loss의 주된 영향으로 인해 overfitting이 점차적으로 나타난다. Splat이 깊이 가이드에서 벗어나기 시작할 때 최적화를 중단하기 위해 moving averaged depth loss를 사용한다.
- 주기적 재설정 프로세스를 제거하였다. 저자들은 모든 splat의 불투명도 $\alpha$를 재설정하면 되돌릴 수 없고 해로운 결과를 초래한다는 것을 관찰했다. 제한된 이미지의 정보 부족으로 인해 splat의 불투명도를 복원할 수 없어 모든 splat이 제거되거나 로컬한 최적 상태에 갇혀 예상치 못한 결과와 최적화 실패가 발생하는 시나리오가 발생했다.
Experiment
- 데이터셋: NeRF-LLFF
- 구현 디테일
- 공정한 비교를 위해 COLMAP을 통해 장면의 전체 이미지를 처리하여 일관된 카메라 포즈와 feature point를 추출
- 학습 세트에서 $k$개의 카메라를 선택하고, $k$개의 카메라 중 최소 3개에서 볼 수 있는 feature point를 추출
- 이러한 feature point들을 깊이 가이드와 Gaussian splatting 최적화를 위한 초기 포인트로 사용
- Oracle: 정확한 깊이의 중요성을 확인하기 위해 전체 이미지를 최적화하여 pseudo-GT depth를 생성하고, 추정된 깊이 대신 사용한 결과
- 공정한 비교를 위해 COLMAP을 통해 장면의 전체 이미지를 처리하여 일관된 카메라 포즈와 feature point를 추출
1. Experiment results
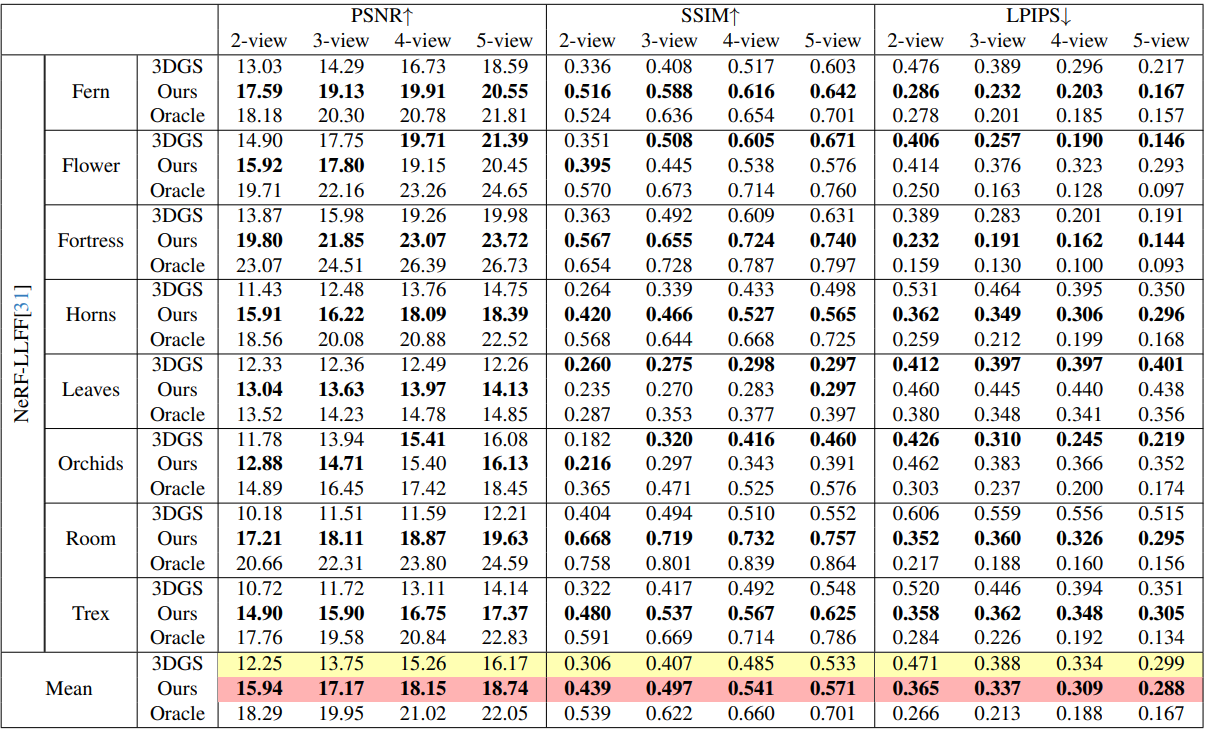
다음은 NeRF-LLFF에서의 비교 결과이다.

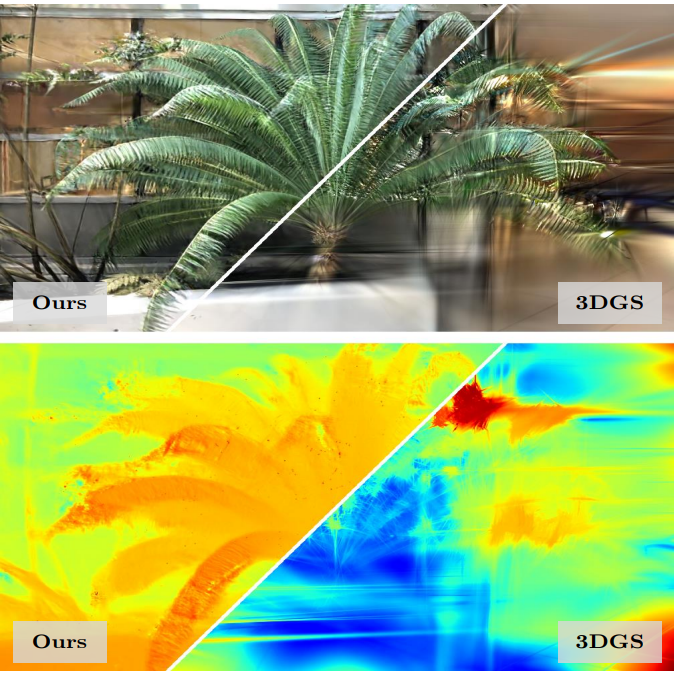
다음은 디테일한 비교이다. (a)는 입력 뷰, (b)는 3DGS, (c)는 본 논문의 방법, (d)는 ground truth이다.

2. Ablations
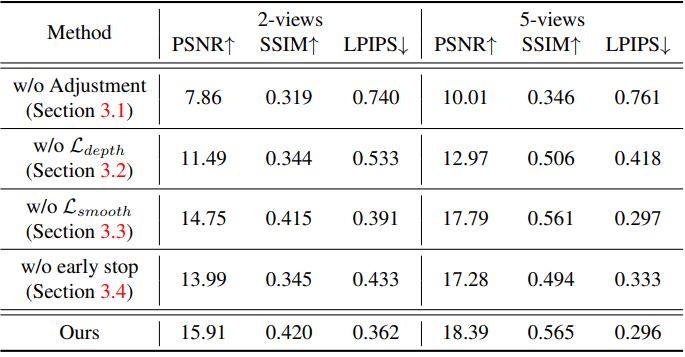
다음은 ablation study 결과이다.
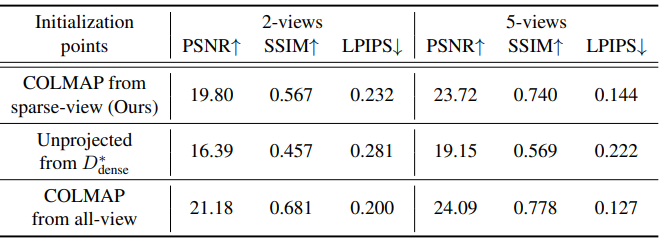
다음은 기존 초기화 방법들과 비교한 표이다.
Limitation
- Monocular depth estimation model의 추정 성능에 크게 의존한다. 또한 이 모델의 깊이 추정 성능은 학습된 데이터 도메인에 따라 달라질 수 있으며 결과적으로 Gaussian splatting 최적화 성능에 영향을 미칠 수 있다.
- 추정된 깊이를 COLMAP 포인트에 맞추는 것은 COLMAP의 성능에 대한 의존성을 의미하므로 COLMAP이 실패할 수 있는 텍스처가 없는 평원이나 까다로운 표면을 처리할 수 없게 된다.