[논문리뷰] Depth Anything V2
NeurIPS 2024. [Paper] [Page] [Github]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
HKU | TikTok
13 Jun 2024
Depth Anything의 후속 논문
Introduction
Monocular depth estimation (MDE)은 광범위한 다운스트림 task에서의 근본적인 역할로 인해 점점 더 주목을 받고 있다. 최근에는 오픈월드 이미지를 처리할 수 있는 수많은 MDE 모델이 등장했다.
모델 아키텍처 측면에서 MDE는 두 그룹으로 나눌 수 있다. 한 그룹은 BEiT나 DINOv2와 같은 discriminative model을 기반으로 하고, 다른 그룹은 Stable Diffusion (SD)와 같은 generative model을 기반으로 한다.

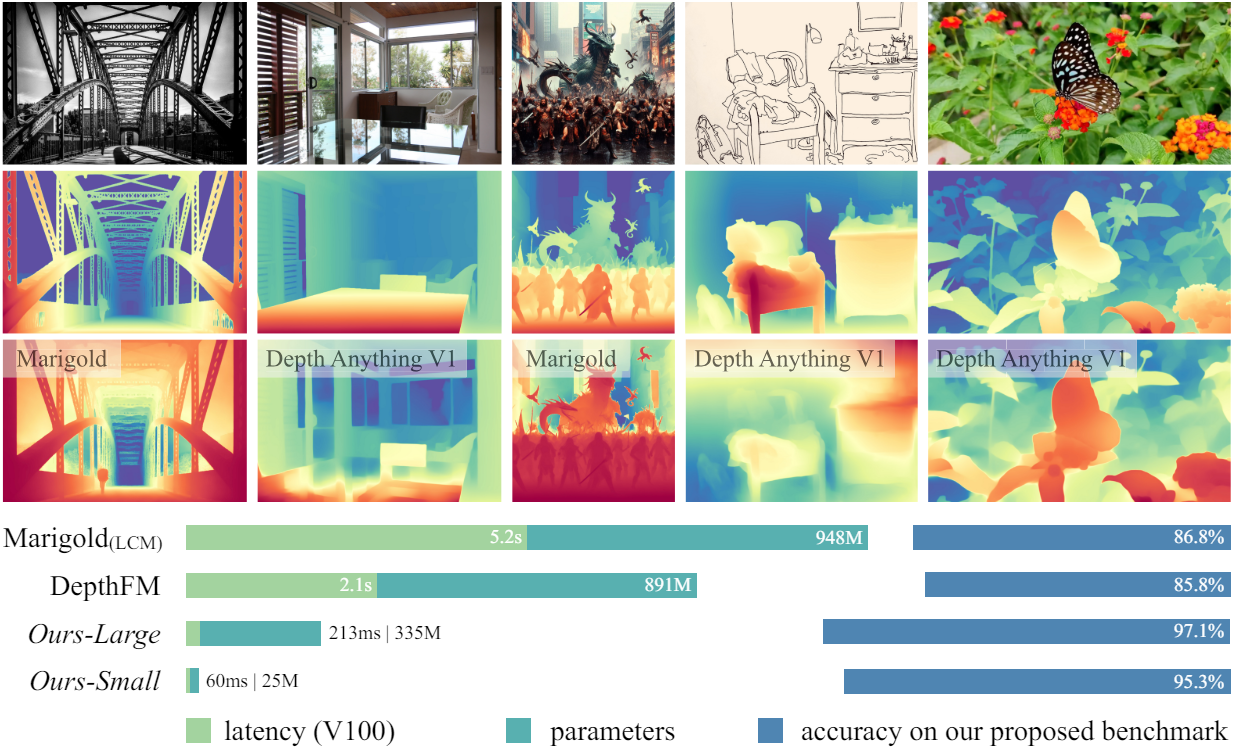
Depth Anything은 discriminative model을 기반으로 하며 Marigold는 생성 모델을 기반으로 한다. 위 그림에서 볼 수 있듯이 Marigold가 세부적인 모델링에 뛰어난 반면 Depth Anything은 복잡한 장면에 대해 더욱 강력한 예측을 생성한다. 또한 Depth Anything은 선택할 수 있는 스케일이 다양하여 Marigold보다 더 효율적이고 가볍다. 그러나 Depth Anything은 Marigold의 장점인 투명한 물체와 반사에 취약하다.

본 논문에서는 이러한 모든 요소를 고려하여 위 표에 나열된 모든 강점을 달성할 수 있는 MDE를 위한 foundation model을 구축하는 것을 목표로 한다.
- 복잡한 장면에 대한 강력한 예측을 생성한다. (복잡한 레이아웃, 투명한 물체, 반사 표면 등)
- 예측 depth map에 미세한 디테일이 포함되어 있다. (얇은 물체, 작은 구멍 등)
- 광범위한 애플리케이션을 지원하기 위해 다양한 모델 스케일과 추론 효율성을 제공한다.
MDE는 discriminative task이므로 본 논문에서는 Depth Anything V1의 강점을 유지하고 약점을 수정하는 것을 목표로 한다. 가장 중요한 부분은 여전히 데이터이다. 레이블이 없는 대규모 데이터를 활용하여 데이터 확장 속도를 높이고 데이터 범위를 늘리는 V1의 데이터 중심 동기와 동일하다.
본 논문은 세 가지 주요 질문에 답을 하였다.
- Q1: MiDaS나 Depth Anything의 coarse한 깊이는 discriminative model 자체에서 나오는 것인지? 디테일을 위해서는 반드시 diffusion 기반의 모델링 방식을 채택해야 하는가?
A1: 효율적인 discriminative model은 매우 미세한 디테일도 생성할 수 있다. 가장 중요한 수정 사항은 레이블이 있는 모든 실제 이미지를 정확한 합성 이미지로 바꾸는 것이다. - Q2: 합성 이미지가 실제 이미지보다 확실히 우월하다면 대부분의 이전 연구들은 왜 여전히 실제 이미지에 집착하는가?
A2: 합성 이미지에는 이전 패러다임에서 해결하기 쉽지 않은 단점이 있다. - Q3: 합성 이미지의 단점을 피하고 장점을 증폭시키는 방법은 무엇인가?
A3: 합성 이미지로만 학습된 teacher model을 확장한 다음, 대규모 pseudo-label이 붙은 실제 이미지를 통해 더 작은 student model을 가르친다.
저자들은 보다 유능한 MDE foundation model을 구축했다. 그러나 현재 테스트셋에는 잡음이 너무 많아 MDE 모델의 진정한 장점을 반영할 수 없다. 따라서 저자들은 정확한 주석과 다양한 장면을 갖춘 다목적 평가 벤치마크를 추가로 구축하였다.
Revisiting the Labeled Data Design of Depth Anything V1
최근 연구에서는 MDE 성능을 향상시키기 위한 노력으로 대규모 학습 데이터셋을 구성하는 경향이 있다. 그러나 이러한 경향을 비판적으로 조사한 연구는 거의 없다. 이렇게 엄청난 양의 레이블이 붙은 이미지가 정말 유리할까?

레이블이 있는 실제 데이터에는 두 가지 단점이 있다.
- 부정확한 레이블: 다양한 수집 절차에 내재된 한계로 인해 레이블이 있는 실제 데이터에는 필연적으로 부정확한 추정값이 포함된다. 이는 다양한 요인으로 인해 발생할 수 있다. 깊이 센서는 투명한 물체의 깊이를 정확하게 캡처할 수 없고, 스테레오 매칭 알고리즘은 텍스처가 없거나 반복적인 패턴에 대하여 취약하며, SfM은 동적 물체나 outlier를 처리할 때 취약하다.
- 무시된 디테일: 실제 데이터는 depth map의 특정 디테일을 간과하는 경우가 많다. 실제 데이터는 물체 경계나 얇은 구멍에 대한 상세한 supervision을 제공하는 데 어려움을 겪으며 깊이 예측이 지나치게 평탄해진다. 따라서 이러한 레이블은 신뢰할 수 없으므로 학습된 모델도 유사한 실수를 범한다.
위의 문제를 극복하기 위해 저자들은 학습 데이터를 변경하고 훨씬 더 나은 주석이 포함된 이미지를 찾기로 결정했다. 학습을 위해 완전한 깊이 정보가 포함된 합성 이미지만을 활용하는 최근의 여러 Stable Diffusion 기반 연구에서 영감을 받아 합성 이미지의 레이블 품질을 광범위하게 확인하고 위에서 설명한 단점을 완화할 수 있는 잠재력에 주목하였다.
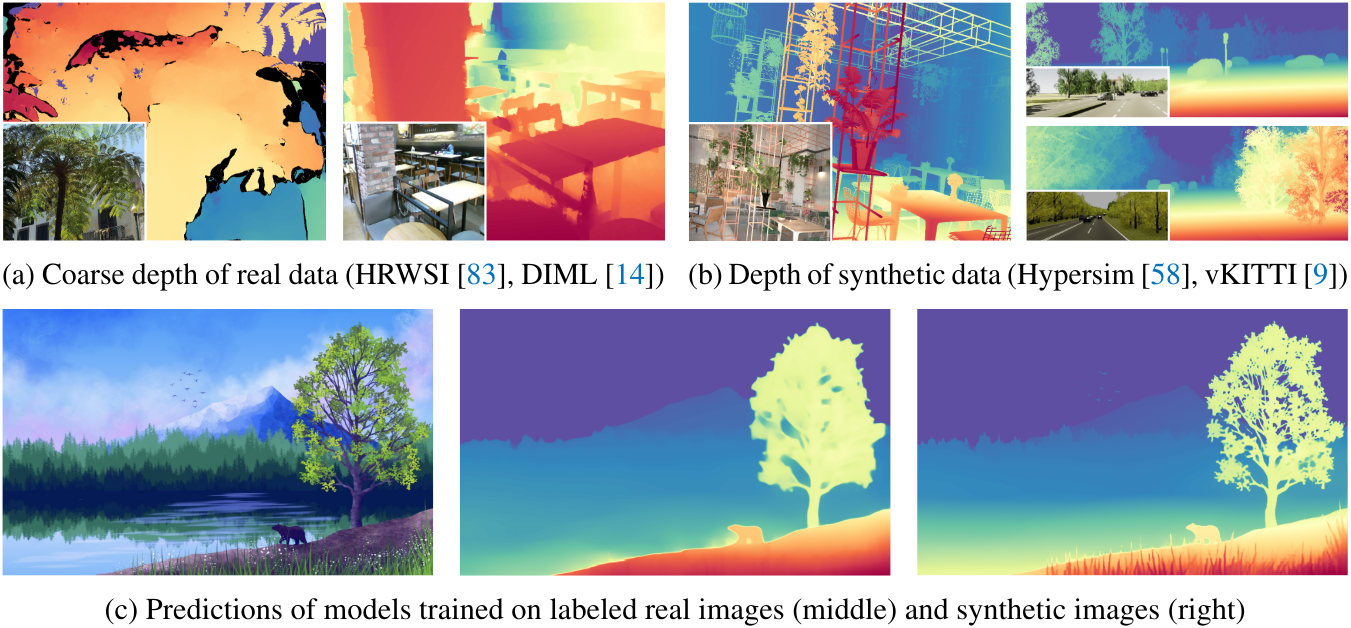
합성 이미지의 장점은 다음과 같다.
- 모든 미세한 디테일, 즉 물체 경계, 얇은 구멍, 작은 물체 등에 올바르게 레이블이 존재한다.
- 투명한 물체와 반사 표면의 실제 깊이를 얻을 수 있다.
- 개인 정보 보호나 윤리적 문제를 일으키지 않는 그래픽 엔진에서 수집되므로 합성 이미지를 빠르게 얻을 수 있다.
Challenges in Using Synthetic Data
합성 데이터가 그렇게 유리하다면 왜 실제 데이터가 여전히 MDE에 사용될까? 이는 합성 이미지가 현실에서 쉽게 활용되기 어려운 두 가지 한계점이 있기 때문이다.
- 합성 이미지와 실제 이미지 사이에는 분포 차이가 있다. 그래픽 엔진의 스타일과 색상 분포는 여전히 실제 이미지와 분명히 다르다. 합성 이미지는 색상이 너무 깨끗하고 레이아웃이 정렬되어 있는 반면, 실제 이미지에는 랜덤성이 더 많이 포함되어 있다. 이러한 분포 차이로 인해 두 데이터 소스가 유사한 레이아웃을 공유하더라도 모델이 합성 이미지에서 실제 이미지로 전환하는 데 어려움을 겪게 된다.
- 합성 이미지에는 장면 커버리지가 제한되어 있다. 그래픽 엔진은 미리 정의된 고정된 장면 유형을 사용하여 데이터를 반복적으로 샘플링한다. 결과적으로 놀라운 정밀도에도 불구하고 이러한 데이터로 학습된 모델이 “붐비는 사람들”과 같은 실제 장면에서 잘 일반화될 것이라고 기대할 수 없다. 이와 대조적으로 실제 데이터셋은 광범위한 실제 장면을 다룰 수 있다.
따라서 합성 이미지로 학습한 모델을 실제 이미지에 사용하는 것은 간단하지 않다. 저자들은 이를 검증하기 위해 BEiT, SAM, SynCLR, DINOv2를 포함하여 4개의 널리 사용되는 사전 학습된 인코더를 사용하여 합성 이미지에서만 MDE 모델을 학습하는 파일럿 연구를 수행하였다.

위 그림에서 볼 수 있듯이 DINOv2-G만이 만족스러운 결과를 얻었다. 다른 모든 모델 시리즈와 소형 DINOv2 모델은 심각한 일반화 문제를 겪고 있다.

DINOv2-G는 두 가지 문제에 직면해 있다. 먼저, DINOv2-G는 합성 학습 이미지에 실제 테스트 이미지의 패턴이 거의 표현되지 않아 실패 사례가 자주 발생한다. 위 그림에서는 하늘과 사람의 머리에 대한 잘못된 깊이 예측을 명확하게 볼 수 있다. 합성 데이터셋에는 다양한 하늘 패턴이나 인간이 포함되어 있지 않기 때문에 이러한 실패가 예상될 수 있다.
또한 대부분의 애플리케이션은 저장 및 추론 효율성 측면에서 리소스 집약적인 DINOv2-G 모델(1.3B)을 수용할 수 없다. 실제로 Depth Anything V1의 가장 작은 모델은 실시간 속도로 인해 널리 사용된다.
일반화 문제를 완화하기 위해 일부 연구에서는 실제 이미지와 합성 이미지를 결합한 학습 데이터셋을 사용하였다. 불행하게도 실제 이미지의 coarse한 depth map은 세밀한 예측에 해를 끼친다. 또 다른 잠재적인 해결책은 더 많은 합성 이미지를 수집하는 것인데, 이는 모든 실제 시나리오를 모방하는 그래픽 엔진을 만드는 것이 어렵기 때문에 지속 불가능하다. 따라서 합성 데이터를 사용하여 MDE 모델을 구축하려면 신뢰할 수 있는 해결책이 필요하다.
Key Role of Large-Scale Unlabeled Real Images
본 논문의 해결책은 간단하다. 레이블이 없는 실제 이미지를 통합하는 것이다. DINOv2-G를 기반으로 하는 MDE 모델은 처음에는 고품질 합성 이미지로만 학습된다. 그런 다음 레이블이 없는 실제 이미지에 pseudo depth label을 할당한다. 마지막으로, 대규모의 정확한 pseudo label이 있는 이미지로만 학습된다. 대규모의 레이블이 없는 실제 이미지의 필수적인 역할은 다음 세 가지 관점에서 설명할 수 있다.
- 도메인 격차 해소: 분포 차이로 인해 합성 학습 이미지로 학습한 모델을 실제 테스트 이미지에 적용하는 것은 어렵다. 그러나 추가 실제 이미지를 중간 학습 대상으로 활용할 수 있다면 프로세스의 신뢰성이 더욱 높아질 것이다. 직관적으로 pseudo label이 있는 실제 이미지를 명시적으로 학습한 후 모델은 실제 데이터 분포에 더 익숙해질 수 있다.
- 장면 커버리지 향상: 실제 장면을 충분히 포함하지 않으면 합성 이미지의 다양성이 제한된다. 공개 데이터셋의 레이블이 없는 대규모 이미지를 통합하여 다양한 장면을 쉽게 다룰 수 있다. 또한 합성 이미지는 미리 정의된 동영상에서 반복적으로 샘플링되기 때문에 실제로 매우 중복된다. 이에 비해 레이블이 없는 실제 이미지는 명확하게 구별되며 매우 유익하다.
- 유능한 모델의 지식을 더 작은 모델로 이전: 레이블이 없는 대규모 실제 이미지를 사용하면 knowledge distillation과 유사하게 유능한 모델의 고품질 예측을 모방하는 방법을 학습할 수 있다. 일반적인 knowledge distillation과 다른 점은 feature나 logit 수준이 아닌 레이블 수준에서 distillation이 시행된다는 것이다. 레이블이 없는 이미지는 작은 모델의 견고성(robustness)을 엄청나게 향상시킨다.
Depth Anything V2
1. 전체 프레임워크
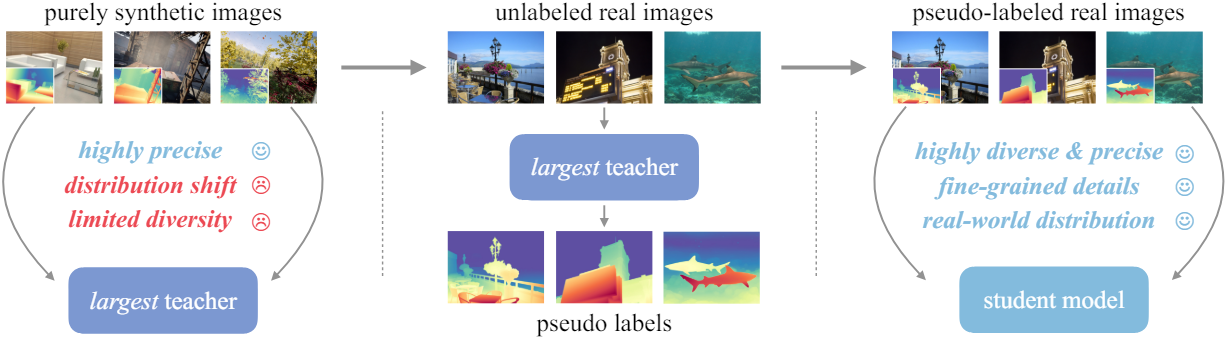
Depth Anything V2를 학습시키기 위한 최종 파이프라인은 세 단계로 구성된다.
- 고품질 합성 이미지만으로 DINOv2-G를 기반의 teacher model을 학습시킨다.
- 레이블이 없는 대규모 실제 이미지에 정확한 pseudo depth를 생성한다.
- 강력한 일반화를 위해 pseudo label이 있는 실제 이미지로 최종 student model을 학습시킨다. 이 단계에서는 합성 이미지가 필요하지 않다.
2. 디테일
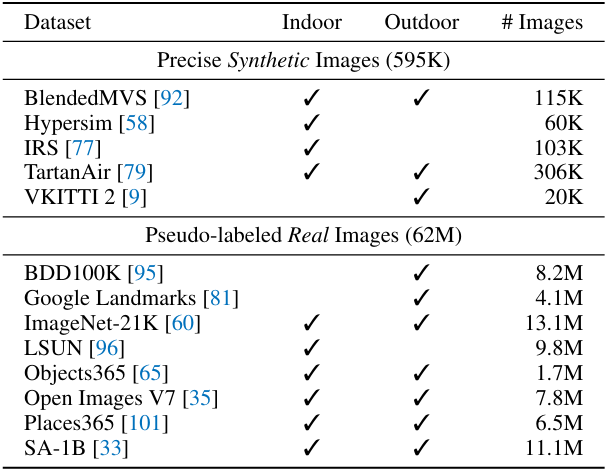
위 표에 나열된 것처럼 학습을 위해 5개의 합성 데이터셋과 8개의 pseudo-label이 있는 대규모의 실제 데이터셋을 사용힌다.
Depth Anything V1과 동일하게, pseudo-label이 있는 각 샘플에 대해 loss가 높은 상위 10%의 영역을 무시한다. 모델은 affine-invariant inverse depth를 생성한다.
최적화를 위해 scale 및 shift-invariant loss \(\mathcal{L}_\textrm{ssi}\)와 gradient matching loss \(\mathcal{L}_\textrm{gm}\)를 사용한다. 이 두 가지 loss는 MiDaS에서 제안되었다. 특히 합성 이미지를 사용할 때 \(\mathcal{L}_\textrm{gm}\)이 깊이 선명도에 매우 유익하였다고 한다. Pseudo-label이 있는 이미지에서 사전 학습된 DINOv2 인코더의 유용한 semantic을 보존하기 위해 V1을 따라 feature alignment loss를 추가한다.
A New Evaluation Benchmark: DA-2K
1. 기존 벤치마크들의 한계점

- 부정확한 레이블: NYU-D는 특수 깊이 센서를 사용함에도 불구하고 거울과 얇은 구조물에 대하여 잘못된 레이블을 가진다. 이러한 레이블 잡음으로 인해 강력한 MDE 모델에 대한 metric은 더 이상 신뢰할 수 없다.
- 제한된 다양성: 대부분은 원래 단일 장면을 위해 제안되었다. 예를 들어 NYU-D는 몇 개의 실내 공간에 초점을 맞춘 반면 KITTI는 여러 개의 거리 장면만 포함한다. 이러한 벤치마크의 성능은 실제 신뢰성을 반영하지 않을 수 있다.
- 낮은 해상도: 대부분 벤치마크는 약 500$\times$500 해상도의 이미지를 제공한다. 그러나 최신 카메라에서는 일반적으로 고해상도 이미지에 대해 정확한 깊이 추정이 필요하다. 이러한 저해상도 벤치마크에서 도출된 결론이 고해상도 벤치마크로 안전하게 전환될 수 있는지 여부는 여전히 불분명하다.
2. DA-2K
위의 세 가지 한계점을 고려하여 저자들은 정확한 깊이 관계를 제공하고, 광범위한 장면을 포괄하고, 고해상도 이미지를 포함할 수 있는 상대적 깊이를 추정하는 다목적 평가 벤치마크를 구축하였다. 실제로 직접 인간이 각 픽셀에 깊이 주석을 다는 것은 비실용적이다. 따라서 각 이미지에 대해 sparse한 깊이 쌍에 주석을 추가하였다. 일반적으로 주어진 이미지에서 두 개의 픽셀을 선택하고 두 픽셀 사이의 상대적 깊이, 즉 어느 픽셀이 더 가까운지를 결정할 수 있다.
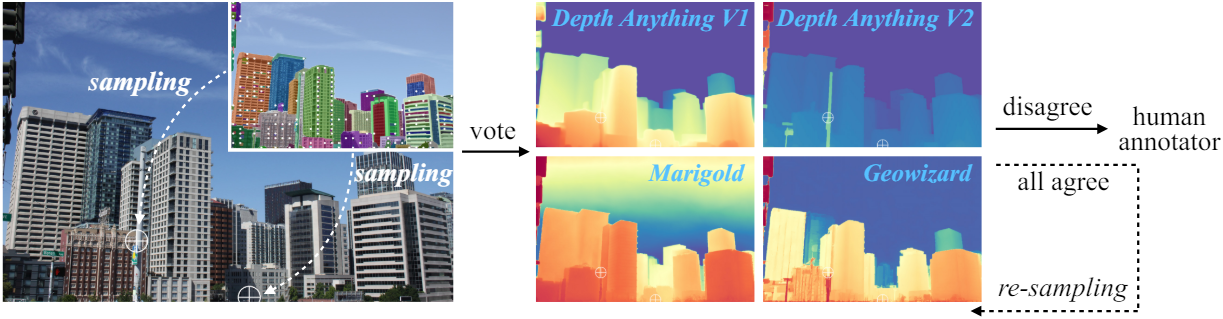
구체적으로 픽셀 쌍을 선택하기 위해 두 개의 서로 다른 파이프라인을 사용한다. 첫 번째 파이프라인에서는 SAM을 사용하여 물체 마스크를 자동으로 예측한다. 마스크를 사용하는 대신 마스크를 나타내는 핵심 픽셀을 활용한다. 두 개의 핵심 픽셀을 무작위로 샘플링하고 네 개의 전문가 모델을 쿼리하여 상대적인 깊이에 투표한다. 불일치가 있는 경우 해당 쌍은 사람이 직접 판단한다. 판단이 모호한 경우 주석자는 해당 쌍을 건너뛸 수 있다. 그러나 모든 모델이 잘못된 예측을 할 수도 있다. 이 문제를 해결하기 위해 이미지를 주의 깊게 분석하고 까다로운 쌍을 수동으로 식별하는 두 번째 파이프라인을 도입한다.

정확성을 보장하기 위해 모든 주석은 다른 두 사람이 추가로 확인하여 총 세 번씩 확인한다. 다양성을 보장하기 위해 먼저 MDE의 8가지 중요한 시나리오를 요약하고 GPT4에 각 시나리오와 관련된 다양한 키워드를 생성하도록 요청한다. 그런 다음 이러한 키워드를 사용하여 Flickr에서 이미지를 다운로드한다. 마지막으로 총 2천 픽셀 쌍으로 1천 개의 이미지에 주석을 추가한다.
DA-2K의 여러 장점에도 불구하고 현재 벤치마크를 대체할 것으로 기대되지는 않는다. Sparse한 깊이는 dense한 깊이와는 여전히 거리가 멀다. 그러나 DA-2K는 dense한 깊이를 위한 전제 조건으로 간주될 수 있다. 따라서 DA-2K는 광범위한 장면 범위와 정밀도로 인해 기존 벤치마크에 대한 보완책 역할을 할 수 있다. 또한 모델을 선택하는 사용자를 위한 빠른 사전 검증 역할을 할 수도 있다.
Experiment
- 모델 아키텍처
- 학습 디테일
- 해상도: 518$\times$518 (이미지의 짧은 쪽이 518이 되도록 resize 후 랜덤 crop)
- teacher model
- batch size: 64
- iteration: 16만
- student model
- batch size: 192
- iteration: 48만
- optimizer: Adam
- learning rate: 인코더는 $5 \times 10^{-5}$, 디코더는 $5 \times 10^{-6}$
- \(\mathcal{L}_\textrm{ssi}\)와 \(\mathcal{L}_\textrm{gm}\)의 가중치 비율은 1:2
1. Zero-Shot Relative Depth Estimation
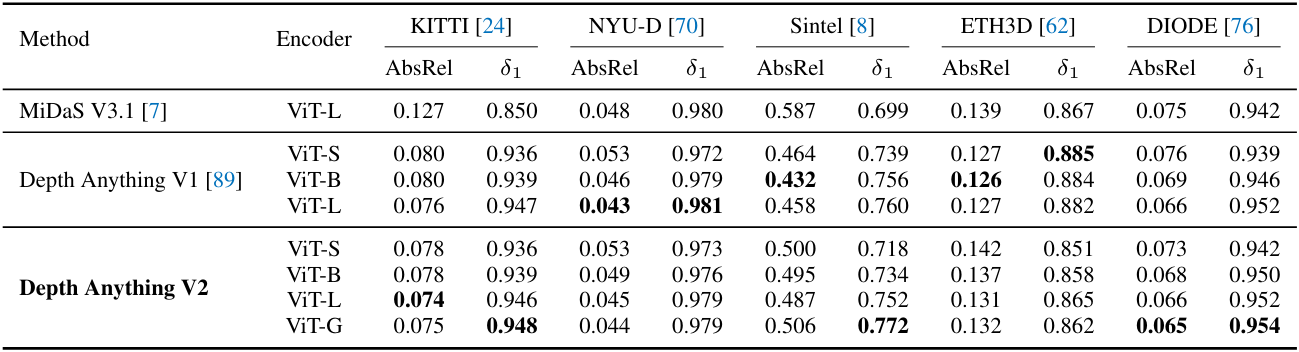
아래 표는 기존 벤치마크에서 zero-shot 상대적 깊이를 추정한 결과이다.
아래 표는 DA-2K에서의 성능을 비교한 것이다.

2. Fine-tuned to Metric Depth Estimation
아래 표는 Depth Anything V2를 fine-tuning하여 metric depth를 추정한 결과이다.

3. Ablation Study
다음은 pseudo-label이 있는 실제 이미지 $\mathcal{D}^u$에 대한 ablation 결과이다. $\mathcal{D}^l$은 레이블이 있는 합성 이미지를 뜻한다.

다음은 DIML 데이터셋에서 제공하는 수동으로 붙인 원래 레이블과 저자들이 생성한 pseudo-label을 비교한 표이다.
