[논문리뷰] Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
CVPR 2024. [Paper] [Page] [Github]
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
HKU | TikTok | CUHK | ZJU
19 Jan 2024

Introduction
본 논문의 목표는 어떤 상황에서도 모든 이미지에 대해 고품질 깊이 정보를 생성할 수 있는 monocular depth estimation (MDE)를 위한 foundation model을 구축하는 것이다. 저자들은 데이터셋 확장의 관점에서 이 목표에 접근하였다. 일반적으로 깊이 데이터셋은 주로 센서, 스테레오 매칭, SfM에서 깊이 데이터를 획득하여 생성되는데, 이는 비용이 많이 들고 시간이 많이 걸리며 특정 상황에서는 다루기 어렵다.
대신 저자들은 처음으로 레이블이 없는 대규모 데이터에 주의를 기울였다. 레이블이 없는 monocular 이미지는 세 가지 장점을 가진다.
- 얻기 간단하고 저렴함: 특수 장치 없이도 쉽게 수집할 수 있다.
- 다양성: 모델 일반화 능력과 확장성에 중요한 더 넓은 범위의 장면을 다룰 수 있다.
- 주석을 달기 쉬움: 사전 학습된 MDE 모델을 사용하여 레이블이 없는 이미지에 깊이 레이블을 할당할 수 있다. 이는 효율적일 뿐만 아니라 LiDAR보다 dense한 depth map을 생성하고 계산 집약적인 스테레오 매칭이 필요 없다.
저자들은 레이블이 없는 이미지에 대한 깊이 주석을 자동으로 생성하여 데이터를 임의의 규모로 확장할 수 있도록 데이터 엔진을 설계하였다. 먼저 SA-1B, Open Images, BDD100K와 같은 8개의 공개 데이터셋에서 6,200만 개의 다양하고 유익한 이미지를 수집한다. 그런 다음 신뢰할 수 있는 주석을 위해 6개의 공개 데이터셋에서 150만 개의 레이블이 있는 이미지를 수집하여 초기 MDE 모델을 학습시킨다. 레이블이 없는 이미지에는 자동으로 주석이 추가되고 레이블이 있는 이미지와 결합되어 공동으로 학습된다.
하지만 이러한 대규모의 레이블이 없는 이미지를 긍정적으로 사용하는 것은 실제로 쉬운 일이 아니다. 저자들은 예비 실험에서 레이블이 있는 이미지와 pseudo-label이 있는 이미지를 직접 결합하여 사용하였지만 레이블이 있는 이미지만 사용하는 모델을 개선하는 데 실패했다. 저자들은 그러한 단순한 self-teaching 방식으로 획득한 추가 지식이 다소 제한적이라고 추측하였다.
본 논문에서는 이 딜레마를 해결하기 위해 pseudo-label을 학습할 때 더 어려운 최적화 목적 함수를 사용하여 student model을 학습시킬 것을 제안하였다. Student model은 처음 보는 이미지를 더 잘 처리하기 위해 다양하고 강한 perturbation에서 추가적인 지식을 찾고 robust한 표현을 학습하도록 강제된다.
또한 일부 연구들에서는 MDE를 위한 보조 semantic segmentation task의 이점을 보여주었다. 그러나 저자들은 MDE 모델이 이미 충분히 강력할 때 이러한 보조 task로 더 많은 이점을 가져오기가 어렵다는 것을 관찰했다. 이는 이미지를 개별 클래스 공간으로 디코딩할 때 semantic 정보의 심각한 손실이 발생하기 때문이다. 따라서 semantic 관련 task에서 DINOv2의 뛰어난 성능을 고려하여 간단한 feature alignment loss를 통해 풍부한 semantic prior를 유지할 것을 제안하였다. 이는 MDE 성능을 향상시킬 뿐만 아니라 multi-task encoder를 생성한다.
Method
본 논문은 더 나은 MDE를 위해 레이블이 있는 이미지와 레이블이 없는 이미지를 모두 활용한다. 먼저 레이블이 있는 데이터셋 \(\mathcal{D}^l = \{(x_i, d_i)\}_{i=1}^M\)으로부터 teacher model $T$를 학습시킨다. 그런 다음 $T$를 활용하여 레이블이 없는 데이터셋 \(\mathcal{D}^u = \{u_i\}_{i=1}^N\)에 pseudo depth label을 할당한다. 마지막으로, 두 데이터셋을 결합하여 student model $S$를 학습시킨다.
1. Learning Labeled Images
깊이 값은 먼저 $d = 1/t$에 의해 disparity로 변환된 후 각 depth map에서 0∼1로 정규화된다. 여러 데이터셋에서 공동으로 학습시키기 위해 affine-invariant loss을 채택하였다.
\[\begin{equation} \mathcal{L}_l = \frac{1}{HW} \sum_{i=1}^{HW} \rho (d_i^\ast, d_i) = \frac{1}{HW} \sum_{i=1}^{HW} \vert \hat{d}_i^\ast - \hat{d}_i \vert \\ \textrm{where} \quad \hat{d}_i = \frac{d_i - t(d)}{s(d)} \end{equation}\]여기서 $d_i^\ast$는 예측값이고 $d_i$는 GT이다. $\rho$는 affine-invariant mean absolute error loss이며, $t(d)$와 $s(d)$는 translation과 scale이다.
\[\begin{equation} t(d) = \textrm{median}, \quad s(d) = \frac{1}{HW} \sum_{i=1}^{HW} \vert d_i - t(d) \vert \end{equation}\]저자들은 강력한 MDE 모델을 얻기 위해 6개의 공개 데이터셋에서 150만 개의 레이블이 있는 이미지를 수집하였다.
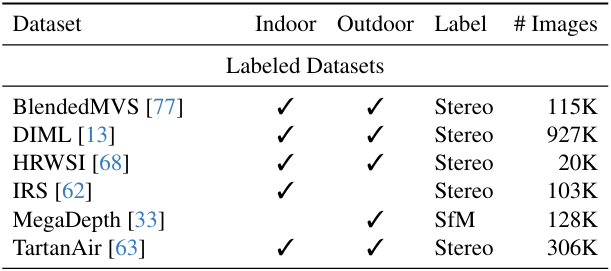
획득하기 쉽고 다양한 레이블이 없는 이미지는 데이터 범위를 이해하고 모델 일반화 능력과 견고성(robustness)을 크게 향상시킨다.
또한 이러한 레이블이 있는 이미지에서 학습한 teacher model $T$를 강화하기 위해 사전 학습된 DINOv2 가중치를 채택하여 인코더를 초기화한다. 사전 학습된 semantic segmentation 모델을 사용하여 하늘 영역을 감지하고 disparity 값을 0으로 설정한다.
2. Unleashing the Power of Unlabeled Images
저자들은 데이터 범위를 향상시키는 데 레이블이 없는 이미지의 가치를 강조하였다. 인터넷이나 다양한 task의 공개 데이터셋을 통해 다양하고 대규모의 레이블이 없는 이미지들을 얻을 수 있다. 또한 사전 학습된 MDE 모델에 이미지를 전달하기만 하면 레이블이 없는 이미지의 dense한 depth map을 손쉽게 얻을 수 있다. 이는 스테레오 매칭이나 SfM 재구성을 수행하는 것보다 훨씬 편리하고 효율적이다.
저자들은 8개의 대규모 공개 데이터셋을 선택하였다. 여기에는 총 6,200만 개 이상의 이미지가 포함되어 있다.
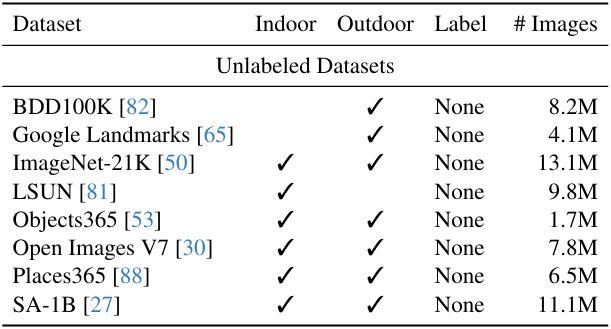
MDE teacher model $T$가 주어지면 레이블이 없는 \(\mathcal{D}^u\)에 대해 깊이를 예측하여 pseudo-label이 있는 \(\hat{\mathcal{D}^u}\)를 얻는다.
\(\mathcal{D}^l \cup \hat{\mathcal{D}^u}\)를 사용하여 student model $S$를 학습시킨다. $T$에서 시작하여 $S$를 fine-tuning하는 대신 더 나은 성능을 위해 $S$를 처음부터 학습시킨다.
안타깝게도 저자들의 예비 실험에서는 이러한 학습 파이프라인을 통해 개선점을 얻지 못했다. 저자들은 이미 충분한 레이블이 있는 이미지가 있으므로 레이블이 없는 추가 이미지에서 얻은 추가 지식은 다소 제한적이라고 추측하였다. 특히 teacher와 student가 동일한 사전 학습 및 아키텍처를 공유한다는 점을 고려하면 \(\mathcal{D}^u\)에 대해 유사한 정확하거나 잘못된 예측을 하는 경향이 있다.
본 논문에서는 이 딜레마를 해결하기 위해 레이블이 없는 이미지에 대한 추가적인 지식을 얻기 위해 더 어려운 최적화 목적 함수로 student model을 학습시킬 것을 제안하였다. 학습 중에 레이블이 없는 이미지에 강한 perturbation을 주입한다. 이는 student model이 추가적인 지식을 적극적으로 찾고 레이블이 없는 이미지로부터 robust한 표현을 얻도록 강요한다.
저자들은 두 가지 형태의 perturbation을 도입하였다. 하나는 color jittering과 Gaussian blurring 등을 포함하는 강력한 색상 왜곡이고, 다른 하나는 CutMix를 통한 강력한 공간 왜곡이다. 두 가지 수정을 통해 레이블이 없는 대규모 이미지가 레이블이 있는 이미지만을 사용한 baseline을 크게 향상시킨다.
CutMix는 원래 이미지 분류를 위해 제안되었으며 MDE에서는 거의 연구되지 않았다. 먼저 레이블이 없는 임의의 이미지 $u_a$와 $u_b$를 공간적으로 interpolate한다.
\[\begin{equation} u_{ab} = u_a \odot M + u_b \odot (1 - M) \end{equation}\]$M$은 직사각형 영역이 1로 설정된 바이너리 마스크이다.
Unlabeled loss \(\mathcal{L}_u\)는 각각 $M$과 $1 − M$으로 정의된 유효 영역에서 affine-invariant loss를 계산하여 얻는다.
\[\begin{aligned} \mathcal{L}_u^M &= \frac{1}{HW} \sum_{i=1}^{HW} \rho (S (u_{ab}) \odot M, T(u_a) \odot M) \\ \mathcal{L}_u^{1-M} &= \frac{1}{HW} \sum_{i=1}^{HW} \rho (S (u_{ab}) \odot (1-M), T(u_b) \odot (1-M)) \\ \end{aligned}\]그런 다음 가중 평균을 통해 두 loss를 집계한다.
\[\begin{equation} \mathcal{L}_u = \frac{\sum M}{HW} \mathcal{L}_u^M + \frac{\sum (1-M)}{HW} \mathcal{L}_u^{1-M} \end{equation}\]저자들은 50% 확률로 CutMix를 사용하였다.
3. Semantic-Assisted Perception
일부 연구들에서는 보조 semantic segmentation task를 통해 깊이 추정을 개선하려고 시도하였다. 저자들은 높은 수준의 semantic 관련 정보로 깊이 추정 모델을 무장시키는 것이 유익하다고 생각하였다. 또한 레이블이 없는 이미지를 활용하는 특정 상황에서 이러한 다른 task의 보조 supervision은 pseudo-label의 잠재적인 잡음에 대처할 수도 있다.
저자들은 RAM + GroundingDINO + HQ-SAM의 조합을 사용하여 레이블이 없는 이미지에 semantic segmentation 레이블을 할당하는 시도를 했다. 후처리 후에는 약 4천 개의 클래스를 가지는 클래스 공간이 생성된다. 공동 학습 단계에서는 공유 인코더와 두 개의 개별 디코더를 사용하여 깊이와 segmentation 예측을 모두 생성하도록 학습된다.
안타깝게도 이러한 시도에도 원래 MDE 모델의 성능을 향상시킬 수 없었다. 저자들은 이미지를 개별 클래스 공간으로 디코딩하면 너무 많은 semantic 정보가 손실된다고 추측했다. Semantic mask의 제한된 정보는 깊이 모델을 더욱 강화하기 어렵다. 특히 깊이 모델이 매우 좋은 결과를 얻은 경우 더욱 그렇다.
따라서 저자들은 깊이 추정 task에 대한 보조 supervision 역할을 할 수 있는 보다 유익한 semantic 신호를 찾는 것을 목표로 하였다. 저자들은 feature alignment loss를 사용하여 DINOv2의 강력한 semantic feature를 깊이 모델로 이전할 것을 제안하였다. Feature space는 고차원적이고 연속적이므로 개별 마스크보다 더 풍부한 semantic 정보를 포함한다. Feature alignment loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{feat} = 1 - \frac{1}{HW} \sum_{i=1}^{HW} \cos (f_i, f_i^\prime) \end{equation}\]$\cos (\cdot, \cdot)$는 cosine similarity이다. $f$는 깊이 모델 $S$에 의해 추출된 feature이며 $f^\prime$은 고정된 DINOv2 인코더의 feature이다. 다른 연구들처럼 feature $f$를 projector를 통해 새로운 공간에 정렬시키면 학습 초기에 \(\mathcal{L}_\textrm{feat}\)가 전체 loss를 지배하게 되므로 projector를 사용하지 않는다.
Feature alignment의 또 다른 핵심 포인트는 DINOv2와 같은 semantic 인코더가 자동차 전면/후면과 같은 물체의 다양한 부분에 대해 유사한 feature를 생성하는 경향이 있다는 것이다. 그러나 깊이 추정에서는 서로 다른 부분이나 심지어 동일한 부분 내의 픽셀도 다양한 깊이를 가질 수 있다. 따라서 고정 인코더와 정확히 동일한 feature를 생성하도록 깊이 모델을 강제하는 것은 유익하지 않다.
이 문제를 해결하기 위해 $f_i$와 $f_i^\prime$의 cosine similarity가 $\alpha$를 초과하면 이 픽셀은 \(\mathcal{L}_\textrm{feat}\)에서 고려되지 않도록 한다. 이렇게 학습된 인코더는 다운스트림 MDE 데이터셋에서 잘 작동할 뿐만 아니라 semantic segmentation에서도 강력한 결과를 얻는다.
전체 loss는 \(\mathcal{L}_l\), \(\mathcal{L}_u\), \(\mathcal{L}_\textrm{feat}\)의 평균 결합이다.
Experiment
- 아키텍처
- 학습 디테일
- 1단계: \(\mathcal{D}^l\)로 teacher model 학습
- epoch: 20
- 2단계: \(\mathcal{D}^l \cup \hat{\mathcal{D}^u}\)로 student model 학습
- 모든 레이블이 없는 이미지를 한 번씩 학습
- 각 batch의 레이블이 있는 이미지와 없는 이미지의 비율은 1:2
- optimizer: AdamW
- learning rate: 인코더는 $5 \times 10^{-6}$, 디코더는 $5 \times 10^{-5}$
- data augmentation: horizontal flipping
- $\alpha = 0.85$
- 1단계: \(\mathcal{D}^l\)로 teacher model 학습
1. Zero-Shot Relative Depth Estimation
다음은 zero-shot relative depth 추정 결과를 MiDaS v3.1과 비교한 표이다.

2. Fine-tuned to Metric Depth Estimation
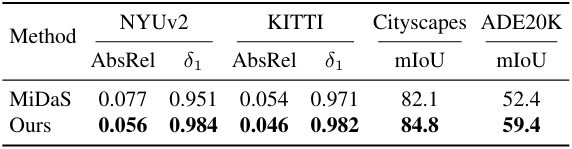
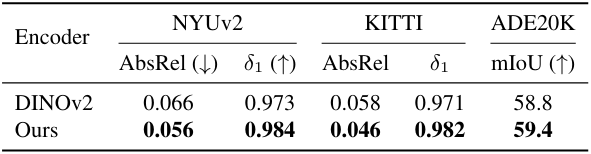
다음은 (왼쪽) NYUv2와 (오른쪽) KITTI애서 fine-tuning 후 평가한 표이다.
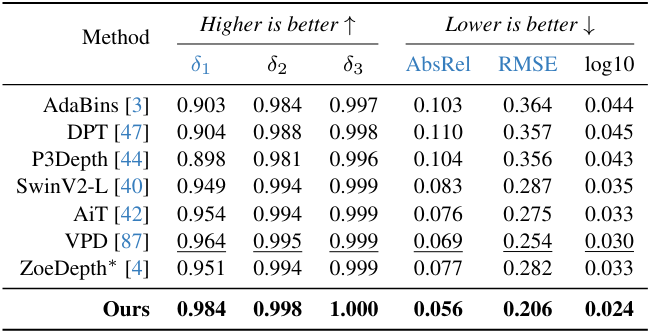
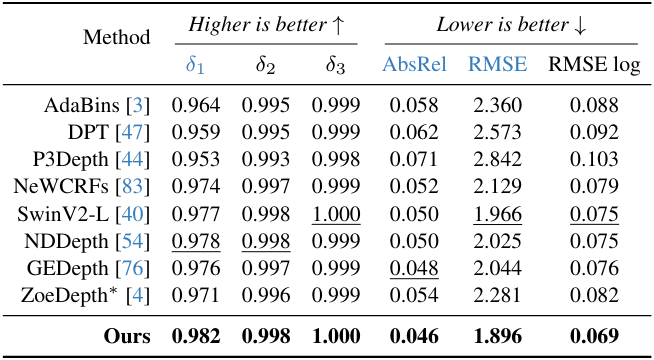
다음은 zero-shot metric depth 추정 결과를 ZoeDepth와 비교한 표이다.

3. Fine-tuned to Semantic Segmentation
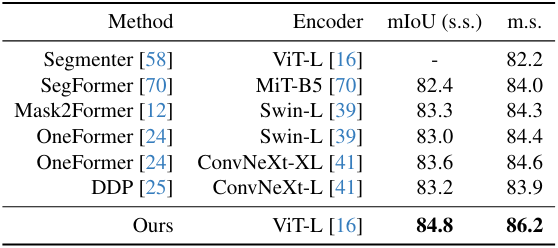
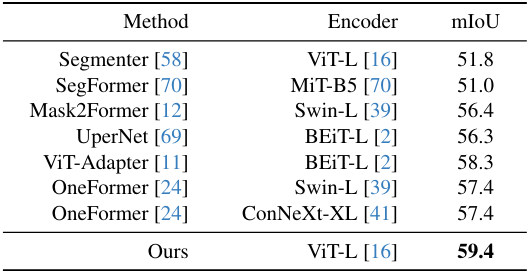
다음은 사전 학습된 MDE 인코더를 semantic segmentation을 위해 (왼쪽) Cityscapes와 (오른쪽) ADE20K로 전송한 결과이다.
4. Ablation Studies
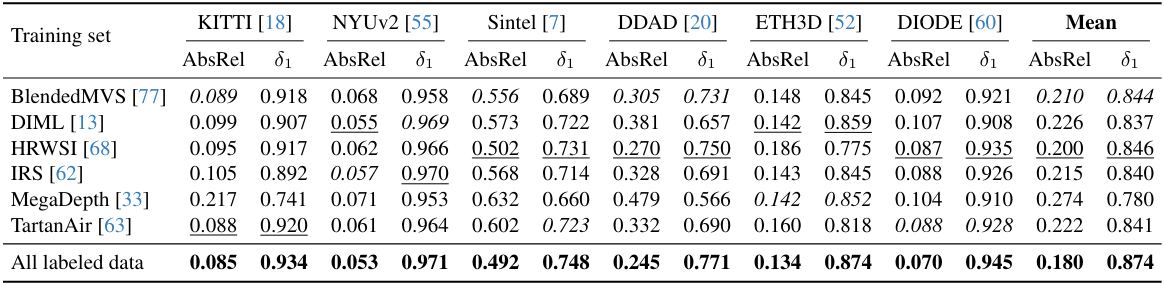
다음은 학습에 사용한 레이블이 있는 데이터셋에 따른 처음 보는 데이터셋에 대한 zero-shot transfer 성능을 비교한 표이다.
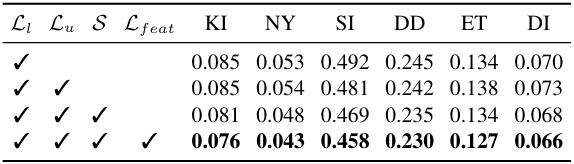
다음은 ablation 결과이다 (AbsRel). $\mathcal{S}$는 student model 학습 시 강한 perturbation을 사용하는 것을 뜻한다.
다음은 본 논문의 인코더를 (왼쪽) MiDaS, (오른쪽) DINOv2와 downstream fine-tuning 성능으로 비교한 결과이다.
5. Qualitative Results
다음은 처음 보는 데이터에 대한 깊이 예측 결과이다.

다음은 MiDaS와 깊이 예측 결과를 비교한 것이다. 또한 ControlNet을 사용하여 예측된 깊이로부터 새로운 이미지를 합성한 결과이다.
