[논문리뷰] Depth Any Video with Scalable Synthetic Data
ICLR 2025. [Paper] [Page] [Github]
Honghui Yang, Di Huang, Wei Yin, Chunhua Shen, Haifeng Liu, Xiaofei He, Binbin Lin, Wanli Ouyang, Tong He
Shanghai AI Laboratory | Zhejiang University | The University of Sydney
14 Oct 2024

Introduction
기존 동영상 깊이 추정의 주요 한계점은 실제 환경의 복잡성을 포착하는 다양하고 대규모의 동영상 깊이 데이터가 부족하다는 것이다. 기존 데이터셋은 종종 규모, 다양성, 장면 변화 측면에서 제한되어 모델이 다양한 시나리오에서 효과적으로 일반화하기 어렵다.
하드웨어 관점에서 볼 때 여러 깊이 센서들은 정확한 깊이를 제공할 수 있지만 종종 비용이 많이 들고 범위나 해상도가 제한적이며 특정 조명 조건에서 또는 반사 표면을 처리할 때 어려움을 겪는다. 또 다른 접근 방식은 스테레오 동영상 데이터셋과 스테레오 매칭 방법에 의존하는 것이다. 그러나 이러한 방법은 복잡하고 계산 집약적이며 텍스처가 약한 영역에서는 종종 실패한다. 이러한 제한은 동적 장면에서 공간적 정밀도와 시간적 일관성을 모두 보장할 수 있는 robust한 모델의 개발을 방해한다.
이러한 과제를 해결하기 위해 본 논문에서는 두 가지 보완적인 관점에서 솔루션을 제안하였다.
대규모 합성 동영상 깊이 데이터셋 구축
최신 게임들은 매우 사실적인 그래픽을 제공하고 다양한 현실 세계 시나리오를 시뮬레이션한다. 최신 렌더링 파이프라인에는 깊이 버퍼가 포함되므로 합성 환경에서 대규모의 고정밀 동영상 깊이 데이터를 추출할 수 있으며, 확장 가능하고 비용 효율적이다.
저자들은 40,000개의 동영상 클립으로 구성된 합성 데이터셋인 DA-V를 구성하였다. DA-V는 다양한 조명 조건, 동적 카메라 움직임, 실내 및 실외 환경 모두에서 복잡한 물체 상호 작용을 포함하는 광범위한 시나리오를 캡처하여 모델이 실제 환경으로 효과적으로 일반화할 수 있는 기회를 제공한다.
생성 모델의 강력한 시각적 prior를 활용하여 다양한 실제 동영상을 효과적으로 처리하는 새로운 프레임워크 설계
본 논문은 데이터셋을 보완하기 위해 동영상 생성 모델에 내장된 풍부한 prior를 활용하는 동영상 깊이 추정을 위한 새로운 프레임워크를 제안하였다. Stable Video Diffusion (SVD)를 기반으로 모델을 구축하고 일반화와 효율성을 향상시키는 두 가지 주요 혁신을 도입하였다.
- 혼합 길이 학습 전략: 프레임을 무작위로 삭제하여 다양한 프레임 속도와 길이의 동영상을 시뮬레이션한다. 길이가 다른 동영상을 처리하기 위해 동일한 길이의 동영상을 동일한 batch로 그룹화하고 batch size를 적절히 조정하여 메모리 사용을 최적화하고 학습 효율성을 개선하였다.
- 깊이 보간 모듈: 키프레임에서 얻은 글로벌하게 일관된 깊이 추정치들을 조건으로 중간 프레임을 생성함으로써 제한된 계산 제약 하에서 긴 동영상을 고해상도로 일관되게 생성한다. 또한 inference 효율성과 유연성을 더욱 개선하기 위해 flow-matching과 rotary position encoding (RoPE)을 도입하여 파이프라인을 개선하였다.
Synthetic Data Workflow
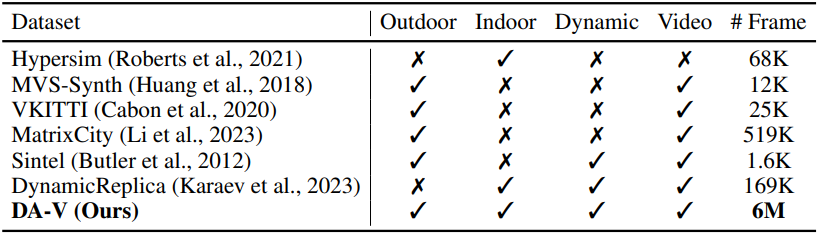
실시간 데이터 수집
깊이 데이터의 한계점을 해결하기 위해, 저자들은 약 40,000개의 동영상 클립으로 구성된 대규모 합성 데이터셋 DA-V를 수집하였다. 이 데이터셋의 상당 부분은 최신 합성 엔진에서 만들어졌으며, 정확한 깊이 정보로 사실적인 환경을 생성하는 합성 엔진의 능력을 활용하였다. 저자들은 다양한 장면 조건을 포함하도록 신중하게 선택된 다양한 가상 환경에서 깊이 데이터를 추출하였다. DA-V는 광범위한 사실적인 장면을 포함하는 가장 큰 합성 동영상 데이터셋이다.
데이터 필터링
합성 동영상 데이터 수집 시, 이미지와 깊이 사이의 오정렬이 가끔씩 관찰된다. 이러한 프레임을 필터링하기 위해, 먼저 PySceneDetect를 사용하여 상당한 색상 변화에 따라 장면 전환을 감지한다. 그런 다음, 수작업으로 선정한 데이터들로 학습된 깊이 모델을 사용하여 깊이 metric score가 낮은 동영상 시퀀스들을 필터링한다. 그러나 이 간단한 접근 방식은 처음 보는 데이터에 대한 과도한 필터링으로 이어질 수 있다. 따라서 CLIP 모델을 추가로 사용하여 실제 깊이와 예측 깊이 사이의 semantic 유사도를 계산한다. 마지막으로, 각 동영상 세그먼트에서 프레임 10개를 균일하게 샘플링한다. Semantic score의 중앙값과 깊이 metric score가 모두 미리 정의된 threshold 아래로 떨어지면 세그먼트가 제거된다.
Generative Video Depth Model
1. Model Design
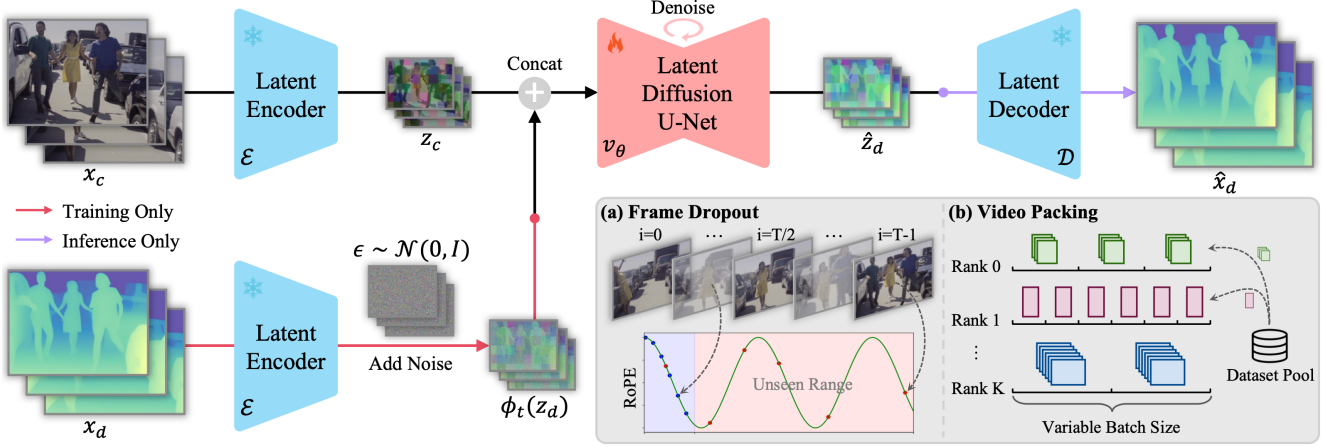
Depth Any Video는 video foundation model인 Stable Video Diffusion (SVD)을 기반으로 하며 monocular video depth estimation을 generative denoising process로 재구성하였다.
- Forward process: Gaussian noise $\epsilon \sim \mathcal{N}(0, I)$을 추가하여 GT 동영상 깊이 $x_d$를 점진적으로 손상시킨다.
- Denoising process: Noise를 제거하기 위해 입력 동영상 $x_c$로 컨디셔닝된 denoising model $v_\theta$를 사용한다.
- Inference: 순수한 noise $\epsilon$에서 시작하여 점진적으로 noise을 제거하여 각 step마다 더 깨끗한 결과를 향해 나아간다.
Latent Video Condition
Latent diffusion model을 따라 생성 프로세스는 사전 학습된 VAE의 latent space 내에서 작동하여 모델이 계산 효율성을 희생하지 않고 고해상도 입력을 처리할 수 있도록 한다. 구체적으로, 동영상 깊이 $x_d$가 주어지면 먼저 Marigold에서와 같이 정규화를 적용하여 깊이 값이 주로 VAE의 입력 범위인 $[-1, 1]$ 내에 있도록 한다.
\[\begin{equation} \tilde{x}_d = \bigg( \frac{x_d - d_2}{d_{98} - d_2} - 0.5 \bigg) \times 2 \end{equation}\]($d_2$와 $d_{98}$는 각각 $x_d$의 2%와 98% 백분위수)
그런 다음, \(\tilde{x}_d\)의 latent code는 인코더 $\mathcal{E}$를 사용하여 얻을 수 있으며, 디코더 $\mathcal{D}$에 의해 latent code에서 정규화된 동영상 깊이를 복구할 수 있다.
\[\begin{equation} z_d = \mathcal{E} (\tilde{x}_d), \quad \hat{x}_d = \mathcal{D} (z_d) \end{equation}\]시공간 차원 모두에서 입력을 latent code로 압축하는 CogVideoX나 OpenAI Sora와 달리, Align Your Latents에서와 같이 공간 차원만 압축하는 데 중점을 둔다. 이는 시간 압축이 latent depth code를 디코딩할 때, 특히 빠른 동작이 있는 동영상에서 모션 블러 아티팩트를 일으킬 가능성이 있기 때문이다.
입력 동영상에서 denoiser $v_\theta$를 컨디셔닝하기 위해, 먼저 동영상 $x_c$를 $z_c = \mathcal{E}(x_c)$로 latent space로 변환한다. 그런 다음, $z_c$를 latent depth code $z_d$와 프레임별로 concat하여 denoiser의 입력을 형성한다. SVD와 달리, 성능에 미치는 영향이 거의 없으므로 CLIP 임베딩 조건을 제거하고 zero embedding으로 대체한다.
Conditional Flow Matching
Denoising process를 가속화하기 위해 SVD의 원래 EDM 프레임워크를 conditional flow matching으로 대체하여 원래의 25 step에서 단 1 step으로 만족스러운 결과를 얻는다. 구체적으로, 프레임워크의 데이터 손상은 Gaussian noise $\epsilon \sim \mathcal{N}(0,I)$와 데이터 $x \sim p(x)$ 사이의 linear interpolation이다.
\[\begin{equation} \phi_t (x) = tx + (1-t) \epsilon, \quad \textrm{where} \; t \in [0, 1] \end{equation}\]이 공식은 데이터와 noise 사이에 일정한 속도를 가진 균일한 변환을 의미한다. Noise에서 데이터로 이동하는 time-dependent velocity field는 다음과 같다.
\[\begin{equation} v_t (x) = x - \epsilon \end{equation}\]이 velocity field $v_t : [0, 1] \times \mathbb{R}^d \rightarrow \mathbb{R}^d$는 상미분 방정식(ODE)을 정의한다.
\[\begin{equation} d \phi_t (x) = v_t (\phi_t (x)) dt \end{equation}\]이 ODE를 $t = 0$에서 $t = 1$까지 풀면 $v_\theta$를 사용하여 noise를 데이터 샘플로 변환할 수 있다. 학습하는 동안 flow matching 목적 함수는 목표 속도를 직접 예측하여 원하는 확률 궤적을 생성한다.
\[\begin{equation} \mathcal{L}_\theta = \mathbb{E}_t [\| v_\theta (\phi_t (z_d), z_c, t) - v_t (z_d) \|^2] \end{equation}\]($z_d$는 latent depth code, $z_c$는 latent video code)
2. Mixed-duration Training Strategy
실제 애플리케이션은 종종 이미지와 다양한 길이의 동영상을 포함한 다양한 형식의 데이터를 접한다. 저자들은 모델의 일반화를 강화하고 다양한 입력에서 robustness를 보장하기 위해 혼합 길이 학습 전략을 구현하였다. 이 전략에는 긴 동영상 시퀀스를 처리할 때 학습 효율성을 유지하는 frame dropout augmentation과 가변 길이 동영상에 대한 메모리 사용을 최적화하는 video packing 기술이 포함되어 있어 모델이 다양한 입력 형식에서 효율적으로 확장할 수 있다.
Frame Dropout
긴 프레임 동영상을 직접 학습하는 것은 컴퓨팅 측면에서 비용이 많이 들고, 상당한 학습 시간과 GPU 리소스가 필요하다. 긴 동영상에 대한 적응성을 유지하면서 학습 효율성을 높이기 위해 rotary position encoding (RoPE)을 사용한 frame dropout augmentation을 사용한다. 구체적으로, SVD에 사용된 3D UNet의 각 temporal transformer block에서 고정된 프레임에서 작동하는 sinusoidal absolute position encoding을 RoPE로 대체하여 가변 프레임을 지원한다.
그러나 RoPE로 짧은 동영상을 학습해도 학습되지 않은 프레임 위치가 있는 긴 동영상으로 일반화하는 데 여전히 어려움이 있다. 이를 완화하기 위해 $T$개의 프레임이 있는 긴 동영상의 원래 프레임 위치 인덱스 $i = [0, \cdots, T-1]$를 유지하고, $K$ 프레임을 무작위로 샘플링하여 학습시킨다. 이 간단한 전략은 temporal layer가 가변 프레임 길이에서 효과적으로 일반화하는 데 도움이 된다.
Video Packing
다양한 길이의 동영상을 학습하기 위해 직관적인 방법은 batch당 하나의 샘플만 사용하는 것이다. Batch 내의 모든 데이터는 일관된 모양을 유지해야 하기 때문이다. 그러나 이렇게 하면 짧은 동영상의 경우 메모리 사용이 비효율적으로 발생한다. 이를 해결하기 위해 먼저 유사한 해상도로 동영상을 그룹화하고 고정된 크기로 자른다. 그런 다음 각 batch에 대해 동일한 그룹에서 예시들을 샘플링하고 동일한 frame dropout 파라미터 $K$를 적용한다. Video packing은 저해상도 및 짧은 길이의 동영상에 대한 batch size를 늘려 학습 효율성을 개선한다.
3. Long Video Inference
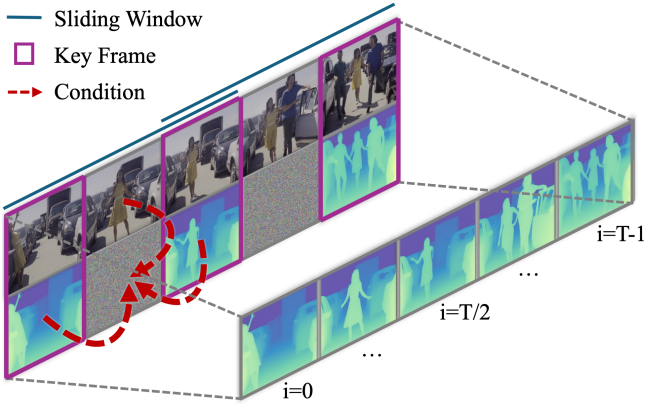
학습된 모델을 사용하면 하나의 80GB A100 GPU에서 한 번의 forward pass로 960$\times$540 해상도에서 최대 32개의 프레임을 처리할 수 있다. 더 긴 고해상도 동영상을 처리하기 위해 NVDS는 sliding window를 적용하여 짧은 세그먼트를 독립적으로 처리하고 결과를 concat하였다. 그러나 이렇게 하면 window 간에 시간적 불일치와 깜빡임 아티팩트가 발생한다.
따라서 먼저 일관된 키프레임을 예측한 다음 각 window는 이러한 키프레임을 조건으로 하는 프레임 보간 네트워크를 사용하여 깊이 분포의 scale과 shift를 정렬하여 중간 프레임을 생성한다. 구체적으로 보간 네트워크는 동영상 깊이 모델 $v_\theta$에서 fine-tuning된다. 동영상으로만 컨디셔닝하는 대신 각 window의 첫 번째와 마지막 키프레임도 사용되며 masking map은 어떤 프레임을 알고 있는지 나타낸다.
\[\begin{equation} \tilde{z}_d = v_\theta (\phi_t (z_d), z_c, \hat{z}_d, m, t) \end{equation}\]여기서 \(\hat{z}_d\)는 예측된 키프레임을 나타내며, 키프레임이 아닌 프레임들은 0으로 패딩된다. Masking map $m$은 키프레임을 나타내는 데 사용되며, 키프레임은 1로 설정되고 다른 프레임은 0으로 설정된다. Masking map은 latent feature 차원에 맞게 4번 복제된다. 사전 학습된 구조를 보존하고 확장된 입력을 수용하기 위해 $v_\theta$의 입력 채널들을 복제하고 입력 레이어의 가중치 텐서를 반으로 줄여서 초기화한다.
Experiments
- 데이터셋: DA-V, Hypersim, Virtual KITTI
- 구현 디테일
- 학습
- 동영상 길이: 1 ~ 6 프레임 사이에서 샘플링
- 해상도: 512$\times$512, 480$\times$640, 707$\times$707, 352$\times$1216, 1024$\times$1024
- batch size: 각 해상도마다 384, 256, 192, 128, 64
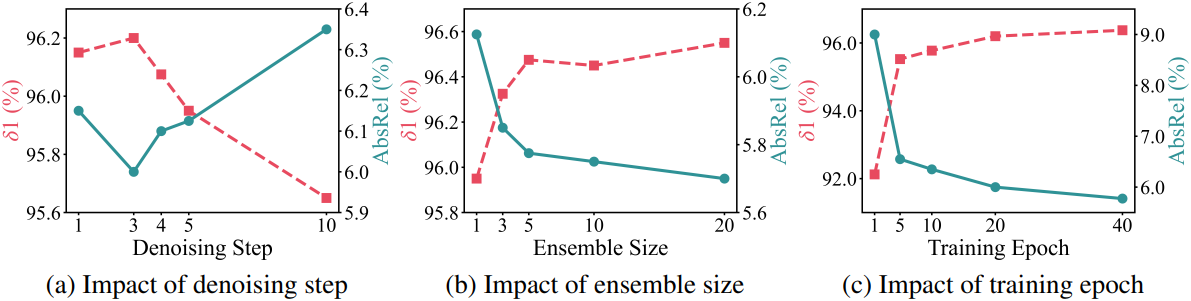
- epoch: 20
- NVIDIA A100 GPU 32개에서 1일 소요
- inference
- denoising step: 3
- ensemble size: 20
- 실행 시간은 NVIDIA A100 GPU 1개로 평가
- 학습
저자들은 동영상 깊이의 시간적 일관성을 평가하기 위해 temporal alignment error를 추가로 도입하였다.
\[\begin{equation} \textrm{TAE} = \frac{1}{2 (T-2)} \sum_{k=0}^{T-1} \textrm{AbsRel} (f (\hat{x}_d^k, p^k), \hat{x}_d^{k+1}) + \textrm{AbsRel} (f (\hat{x}_d^{k+1}, p_{-}^{k+1}), \hat{x}_d^k) \\ \end{equation}\]($T$는 프레임 수, $f$는 transformation matrix $p^k$를 사용하여 깊이 \(\hat{x}_d^k\)를 $k$번째 프레임에서 $(k + 1)$번째 프레임으로 매핑하는 projection function, \(p_{-}^{k+1}\)는 역방향으로 projection하기 위한 역행렬, $\textrm{AbsRel}$은 absolute relative error)
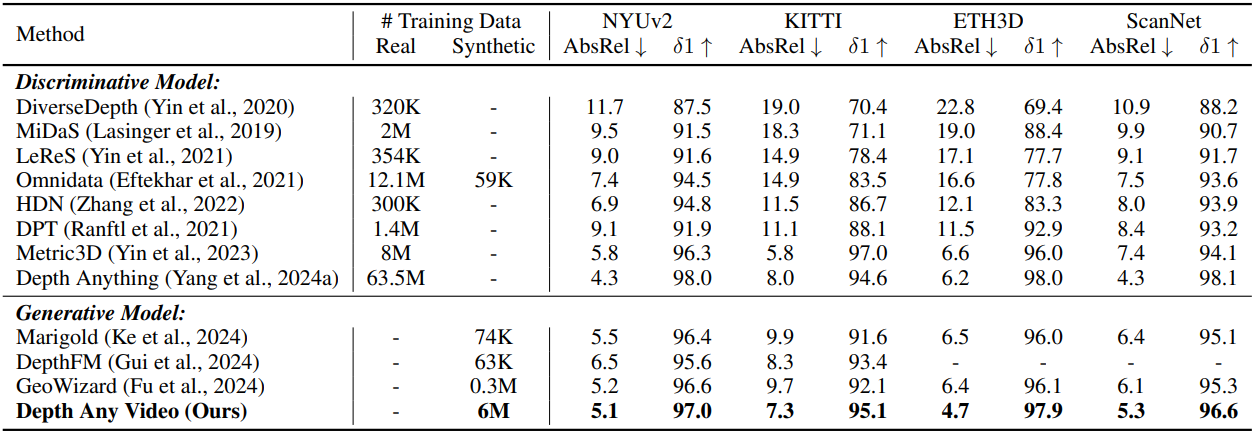
1. Zero-shot Depth Estimation
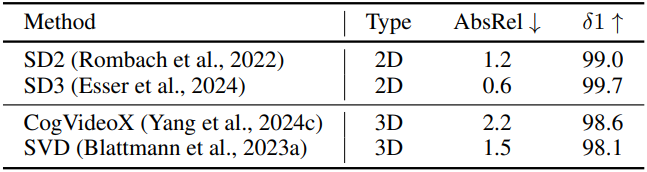
다음은 단일 프레임, 즉 이미지에 대한 깊이 추정 성능을 비교한 결과이다.

다음은 ScanNet++ 데이터셋에서 시간적 일관성과 공간적 정확도를 비교한 결과이다.
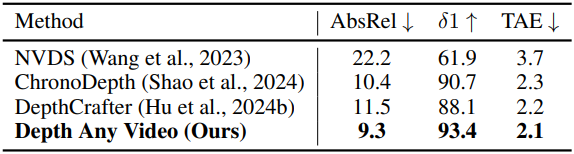
다음은 ScanNet 데이터셋에서 성능과 inference 효율성을 비교한 결과이다.
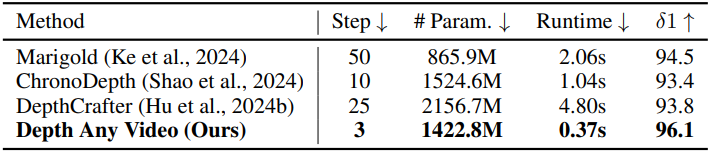
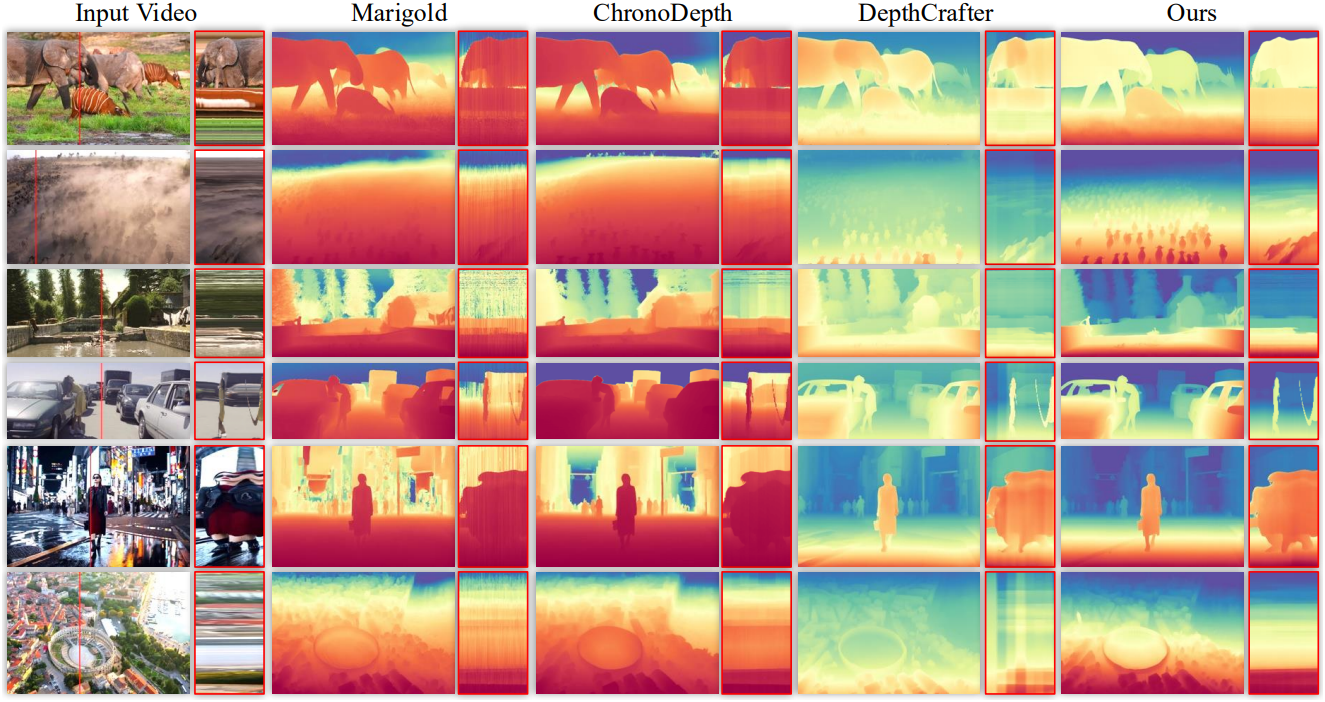
다음은 실제 동영상에서의 깊이 추정 결과를 비교한 것이다.
2. Ablation Studies
다음은 각 구성 요소에 대한 ablation study 결과이다.

다음은 hyper-parameter들에 대한 ablation study 결과이다.
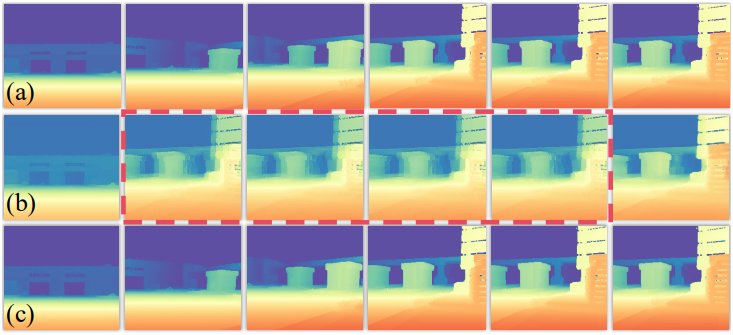
다음은 VAE에 대한 ablation study 결과이다. (a)는 GT 깊이이고, (b)와 (c)는 각각 CogVideoX와 SVD를 사용한 결과이다.
Limitations
- 거울과 같은 반사에 대한 깊이 추정에 어려움을 겪는다.
- 매우 긴 동영상에 어려움을 겪는다.