[논문리뷰] DemoFusion: Democratising High-Resolution Image Generation With No $$$
CVPR 2024. [Paper] [Page] [Github]
Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, Zhanyu Ma
Beihang University | Macquarie University | RIKEN AIP | The University of Tokyo
24 Nov 2023

Introduction
생성형 AI 모델을 사용한 고해상도 이미지를 생성은 놀라운 잠재력을 보여주었다. 그러나 이러한 능력은 점점 더 중앙 집중화되고 있다. 고해상도 이미지 생성 모델을 학습시키려면 개인과 교육 기관이 감당할 수 없는 하드웨어, 데이터, 에너지에 대한 상당한 자본 투자가 필요하다. 예를 들어, $512^2$ 해상도에서 Stable Diffusion 1.5를 학습시키려면 256개의 A100 GPU에서 20일 이상의 학습이 필요하다. 이미지 해상도에 따라 이미지 생성 모델을 학습시키는 데 필요한 투자가 급격히 증가하기 때문에 모델의 이미지 합성 품질이 향상됨에 따라 중앙 집중화 추세가 가속화되고 있다.
본 논문에서는 SDXL, Midjourney, DALL-E 등의 고해상도 이미지 합성의 한계를 $1024^2$에서 $4096^2$ 이상으로 확장하는 DemoFusion을 도입하여 이러한 추세를 뒤집었다. DemoFusion은 추가 학습이 필요하지 않으며 RTX 3090 GPU 1개에서 실행된다.

구체적으로 $1024^2$의 이미지를 생성할 수 있는 SDXL 모델부터 시작하였다. DemoFusion은 생성 해상도를 4배, 16배, 또는 그 이상 증가시킬 수 있는 SDXL의 plug-and-play extension이며, 추가 학습 없이 몇 줄의 간단한 코드만으로 가능하다. 위 그림의 (a)와 같이 SDXL에 더 높은 해상도의 이미지를 생성하라는 프롬프트를 직접 사용하면 좋은 생성에 실패한다. 그러나 저자들은 text-to-image LDM이 학습 과정에서 crop된 사진을 많이 접한다는 것을 관찰했다. 이렇게 crop된 사진은 학습 세트에 본질적으로 존재하거나 data augmentation을 위해 의도적으로 crop된 것이다. 결과적으로 (b)에서 볼 수 있듯이 SDXL과 같은 모델은 물체의 로컬한 부분에 초점을 맞춘 출력을 생성하는 경우가 있다. 즉, 기존 LDM에는 이미 고해상도 이미지를 생성할 수 있는 충분한 prior가 포함되어 있으며, 여러 개의 고해상도 패치를 완전한 장면에 융합할 수만 있다면 그 능력을 사용할 수 있다.
그러나 일관된 패치 방식의 고해상도 생성을 달성하는 것은 쉽지 않다. 최근 연구인 MultiDiffusion에서는 중첩된 여러 denoising 경로를 융합하여 파노라마 이미지를 생성할 수 있는 가능성을 보여주었다. 그러나 특정 고해상도 물체 중심 이미지를 생성하기 위해 MultiDiffusion을 직접 적용하면 (c)와 같이 글로벌한 semantic 일관성 없이 결과가 반복적이고 왜곡된다. 근본적인 이유는 중첩된 패치 denoising이 semantic 일관성에 필요한 글로벌 컨텍스트에 대한 광범위한 인식 없이 이음새를 자연스럽게 만들기 때문이다.
DemoFusion은 고해상도 생성을 달성하기 위해 사전 학습된 SDXL 모델의 여러 denoising 경로를 융합하는 것과 동일한 아이디어를 기반으로 구축되었다. 풍부한 로컬 디테일과 함께 글로벌 semantic 일관성을 달성하기 위한 세 가지 주요 메커니즘을 도입하였다
- Progressive Upscaling: 고해상도 이미지를 생성하기 위한 더 나은 초기화로 noise-inverse된 저해상도 이미지를 사용하는 “upsample-diffuse-denoise” 루프를 통해 이미지를 반복적으로 향상시킨다.
- Skip Residual: 동일한 iteration 내에서 중간 noise-inverse된 표현을 skip residual로 추가로 활용하여 고해상도 이미지와 저해상도 이미지 간의 전체적인 일관성을 유지한다.
- Dilated Sampling: 글로벌 semantic 일관성을 높이기 위해 denoising 경로의 dilated sampling을 사용하여 MultiDiffusion을 확장한다.
Inference를 수정하는 이 세 가지 기술은 사전 학습된 SDXL에서 구현하기가 간단하며 고해상도 이미지 생성 품질과 일관성을 크게 향상시킨다.
주의할 점은 고해상도 이미지를 생성하려면 더 많은 런타임이 필요하다는 것이다. 이는 부분적으로 progressive upscaling 때문이며, 필요한 시간이 해상도에 지수적으로 증가하므로 가장 높은 해상도가 비용을 지배한다. 그럼에도 불구하고, 메모리 소비는 소비자급 GPU에 비해 충분히 낮으며, 점진적인 생성을 통해 사용자는 저해상도 결과를 빠르게 미리 볼 수 있으므로 전체 레이아웃과 스타일이 만족스러울 때까지 프롬프트를 수정한 후 최대 해상도 생성을 기다리게 된다.
Method
1. Progressive Upscaling
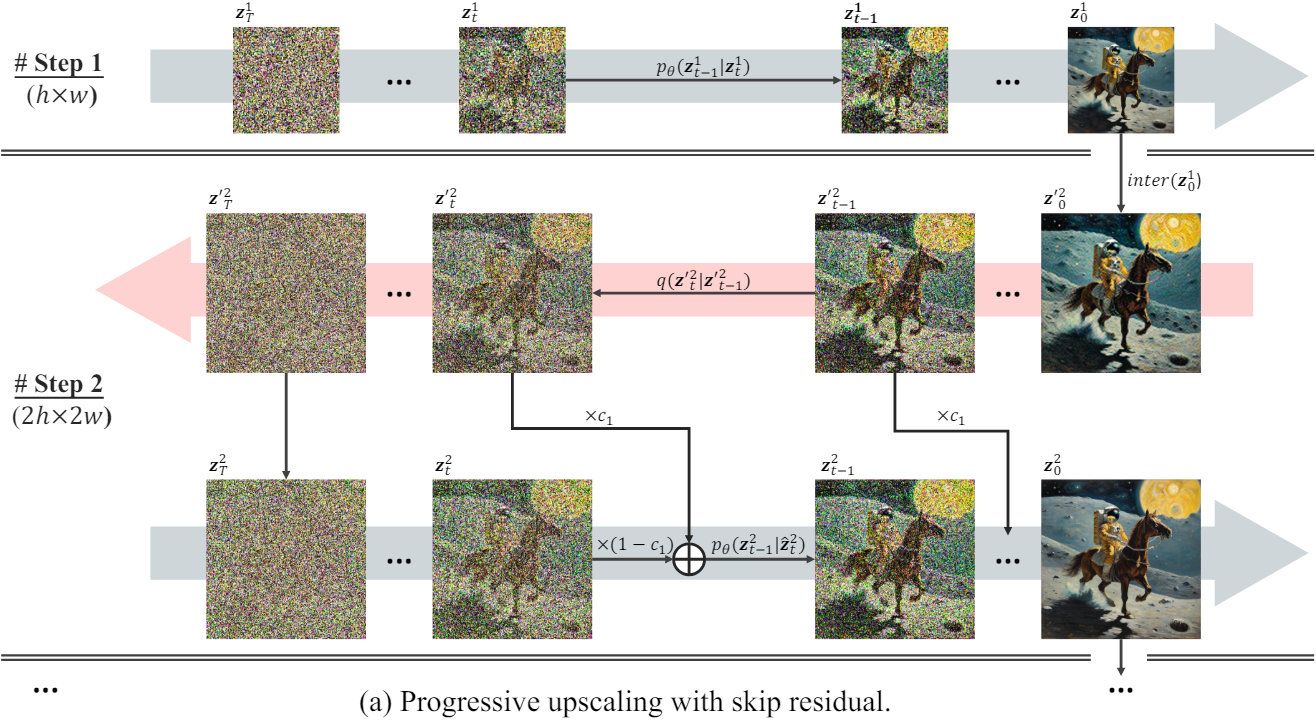
낮은 해상도에서 높은 해상도까지 이미지를 점진적으로 생성하는 것은 잘 정립된 개념이다. 처음에는 낮은 해상도에서 semantic하게 일관된 전체 구조를 합성한 다음, 로컬한 디테일을 추가하기 위해 해상도를 높이면 모델은 일관적이면서도 풍부한 이미지를 생성할 수 있다. 본 논문에서는 LDM에 맞춘 새로운 progressive upscaling 생성 프로세스를 제시하였다.
$K$배로 확대된 해상도의 이미지를 생성하기 위해 latent space $\mathbb{R}^{c \times h \times w}$에서 작동하는 사전 학습된 LDM을 생각해보자. 높이와 너비에 대한 scaling factor는 $S = \sqrt{K}$여야 하며, 목표 latent space는 $\mathbb{R}^{c \times Sh \times Sw}$이다. $z_t \in \mathbb{R}^{c \times Sh \times Sw}$를 직접 합성하는 대신 생성 프로세스를 $S$개의 개별 단계로 나눈다. 각 단계는 “initialise-denoise” 방식을 따르는 첫 번째 단계를 제외하고 “upsample-diffuse-denoise” 루프로 구성된다. 주어진 diffusion process와 denoising process를 각각
\[\begin{equation} q(\mathbf{z}_T \vert \mathbf{z}_0) = \prod_{t=1}^T q (\mathbf{z}_t \vert \mathbf{z}_{t-1}), \quad p_\theta (\mathbf{z}_0 \vert \mathbf{z}_T) = \prod_{t=T}^1 p_\theta (\mathbf{z}_{t-1} \vert \mathbf{z}_t) \end{equation}\]라고 하면, progressive upscaling 생성 프로세스를 다음과 같다.
\[\begin{equation} p_\theta (\mathbf{z}_0^S \vert \mathbf{z}_T^1) = p_\theta (\mathbf{z}_0^1 \vert \mathbf{z}_T^1) \prod_{s=2}^S (q({\mathbf{z}^\prime}_T^s \vert {\mathbf{z}^\prime}_0^s) p_\theta (\mathbf{z}_0^s \vert {\mathbf{z}^\prime}_T^s)) \\ \textrm{where} \quad {\mathbf{z}^\prime}_0^s = \textrm{inter}(\mathbf{z}_0^{s-1}) \end{equation}\]여기서 \({\mathbf{z}^\prime}_0^s\)는 명시적인 업샘플링 interpolation $\textrm{inter}$을 통해 얻어진다.
먼저 SDXL과 같은 일반 LDM을 \(p_\theta (\mathbf{z}_0^1 \vert \mathbf{z}_T^1)\)로 실행한다. 그런 다음 각 scale $s$에 대해 반복적으로
- 저해상도 이미지 \(\mathbf{z}_0^{s-1}\)을 \({\mathbf{z}^\prime}_0^s\)으로 업스케일링하고
- diffusion process를 통해 noise를 다시 도입하여 \({\mathbf{z}^\prime}_T^s\)를 얻고
- Denoising하여 $\mathbf{z}_0^s$를 얻는다.
이 과정을 반복함으로써 인위적인 interpolation 기반 업샘플링을 보상하고 점차적으로 더 많은 로컬 디테일을 채울 수 있다.
2. Skip Residual
“diffuse-denoise” 프로세스는 일부 이미지 편집 방법과 유사하다. 이러한 방법들은 전문화된 noise inversion 기술을 사용하여 이미지의 초기 noise를 찾으려고 시도하며, denoising process 중에 편집되지 않은 부분이 원본 이미지와 일관되게 유지되도록 한다. 그러나 이러한 inversion 기술은 DemoFusion의 denoising process에는 덜 실용적이다. 따라서 대신 랜덤 Gaussian noise를 추가하여 기존 diffusion process를 사용한다.
그러나 초기화로 \(\mathbf{z}_0^s\)을 \({\mathbf{z}^\prime}_T^s\)로 직접 diffuse하면 대부분의 정보가 손실된다. 그 대신 중간 timestep $t$로 diffuse한 다음 \({\mathbf{z}^\prime}_t^s\)에서 denoising을 시작하는 것이 더 나을 수 있다. 그러나 “upsamplediffuse-denoise” 루프에 대한 최적의 $t$를 결정하는 것은 어렵다. $t$가 클수록 더 많은 정보가 손실되어 전체적인 인식이 약화된다. $t$가 작을수록 업샘플링으로 인해 발생하는 noise가 더 강해진다. 이는 어려운 trade-off이며 예시별로 다를 수 있다.
따라서 저자들은 skip residual을 일반적인 솔루션으로 도입하였다. 이는 일련의 서로 다른 $t$를 갖는 여러 “upsample-diffusedenoise” 루프의 가중 융합으로 간주될 수 있다.
각 생성 단계 $s$에 대해 이미 $t \in [1,T]$를 사용하여 \({\mathbf{z}^\prime}_0^s\)의 \({\mathbf{z}^\prime}_t^s\)로의 일련의 noise-inverse된 버전을 얻었다. Denoising process에서 해당 noise-inverse된 버전을 skip residual로 도입한다. 즉, \(p_\theta (\mathbf{z}_{t−1} \vert \mathbf{z}_t)\)를 \(p_\theta (\mathbf{z}_{t−1} \vert \hat{\mathbf{z}}_t)\)로 수정한다.
\[\begin{equation} \hat{\mathbf{z}}_t^s = c_1 {\mathbf{z}^\prime}_t^s + (1 - c_1) \mathbf{z}_t^s \\ \textrm{where} \quad c_1 = \bigg( \frac{1 + \cos ( \frac{T-t}{T} \pi )}{2} \bigg)^{\alpha_1} \end{equation}\]기본적으로 이전 단계의 결과를 활용하여 denoising process의 초기 단계에서 생성된 이미지의 글로벌 구조를 가이드한다. 또한 noise residual의 영향을 점진적으로 줄여 로컬한 denoising 경로들을 통해 이후 단계에서 더 세밀한 디테일을 보다 효과적으로 최적화할 수 있다.
3. Dilated Sampling
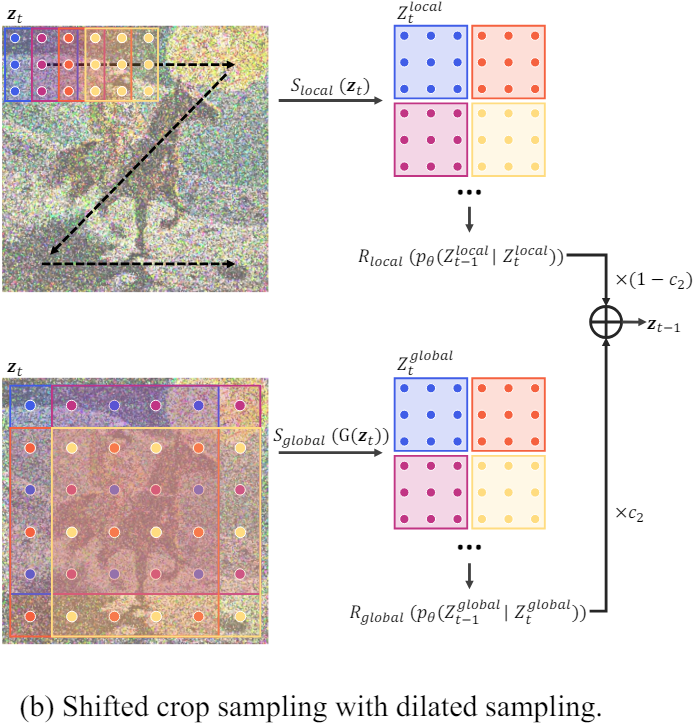
추가로 dilated sampling을 도입하여 각 denoising 경로에 더 많은 글로벌 컨텍스트를 제공한다. Receptive field를 확장하기 위해 convolutional kernel을 확장하는 기술은 다양한 dense prediction task에서 일반적이다. 본 논문에서는 convolutional kernel을 확장하는 대신 latent 표현 내에서 샘플링을 직접 확장한다. 그 후 dilated sampling을 통해 파생된 글로벌 denoising 경로는 MultiDiffusion의 로컬 denoising 경로와 유사하게 처리된다.
일련의 글로벌 latent 표현, 즉
\[\begin{equation} Z_t^\textrm{global} = [\mathbf{z}_{0,t}, \cdots, \mathbf{z}_{m,t}, \cdots, \mathbf{z}_{s^2, t}] = \mathcal{S}_\textrm{global} (\mathbf{z}_t) \end{equation}\]를 얻기 위해 shifted dilated sampling을 적용한다. 여기서 $s$는 전체 latent 표현에서 샘플링하기 위한 dilation factor이다. 마찬가지로, 글로벌 latent 표현에 대한 일반적인 denoising process를 \(p_\theta (\mathbf{z}_{m, t-1} \vert z_{m, t})\)로 적용한다. 그런 다음 재구성된 글로벌 표현은 재구성된 로컬 표현과 융합되어 최종 latent 표현을 형성한다.
\[\begin{equation} \mathbf{z}_{t-1} = c_2 \mathcal{R}_\textrm{global} (Z_{t-1}^\textrm{global}) + (1 - c_2) \mathcal{R}_\textrm{local} (Z_{t-1}^\textrm{local}) \\ \textrm{where} \quad c_2 = \bigg( \frac{1 + \cos ( \frac{T-t}{T} \pi )}{2} \bigg)^{\alpha_2} \end{equation}\]Dilated sampling을 직접 사용하면 이미지가 거칠어질 수 있다. 이는 중첩되는 로컬 denoising 경로와 달리 글로벌 denoising 경로가 서로 독립적으로 작동하기 때문이다. 이 문제를 해결하기 위해 dilated sampling을 수행하기 전에 latent 표현에 Gaussian filter $\mathcal{G}(\cdot)$를 적용한다.
\[\begin{equation} Z_t^\textrm{global} = \mathcal{S}_\textrm{global} (\mathcal{G} (\mathbf{z}_t)) \end{equation}\]Gaussian filter의 커널 크기는 $4s-3$으로 설정된다. 또한, 필터의 표준 편차 $\sigma$는
\[\begin{equation} \sigma = c_3 \sigma_1 + (1 - c_3) \sigma_2 \\ \textrm{where} \quad c_3 = \bigg( \frac{1 + \cos ( \frac{T-t}{T} \pi )}{2} \bigg)^{\alpha_3} \end{equation}\]에 따라 $\sigma_1$에서 $\sigma_2$로 감소한다. 이를 통해 글로벌 denoising 경로의 방향이 일관됨에 따라 필터 효과가 점차 감소하여 최종 이미지가 흐려지는 것을 방지할 수 있다.
Experiments
1. Comparison
다음은 다른 방법들과 결과를 비교한 것이다.


2. Ablation Study
다음은 Progressive Upscaling (PU), Skip Residual (SR), Dilated Upsampling (DS)에 대한 ablation 결과이다.

Limitations

- MultiDiffusion 스타일의 inference 특성상 denoising 경로가 겹쳐서 높은 계산량이 필요하며, progressive upscaling으로 인해 inference 시간이 더 길어진다.
- DemoFusion의 성능은 기본 LDM과 직접적인 상관관계가 있다.
- DemoFusion은 crop된 이미지에 대한 LDM의 prior에 전적으로 의존하므로 선명한 클로즈업 이미지를 생성할 때 로컬하게 비합리적인 콘텐츠가 나타날 수 있다.
- 배경 영역에서 작은 반복 콘텐츠가 발생할 가능성은 여전히 남아 있다.